数据任务概述
任务目标:利用异烟酸生产过程中的各参数,预测最终异烟酸的收率
数据集包括生产工程中10个步骤的参数,样本id、A1-A28、B1-B14包括原料、辅料、时间、温度、压强等以及收率
- 本项目为回归预测任务
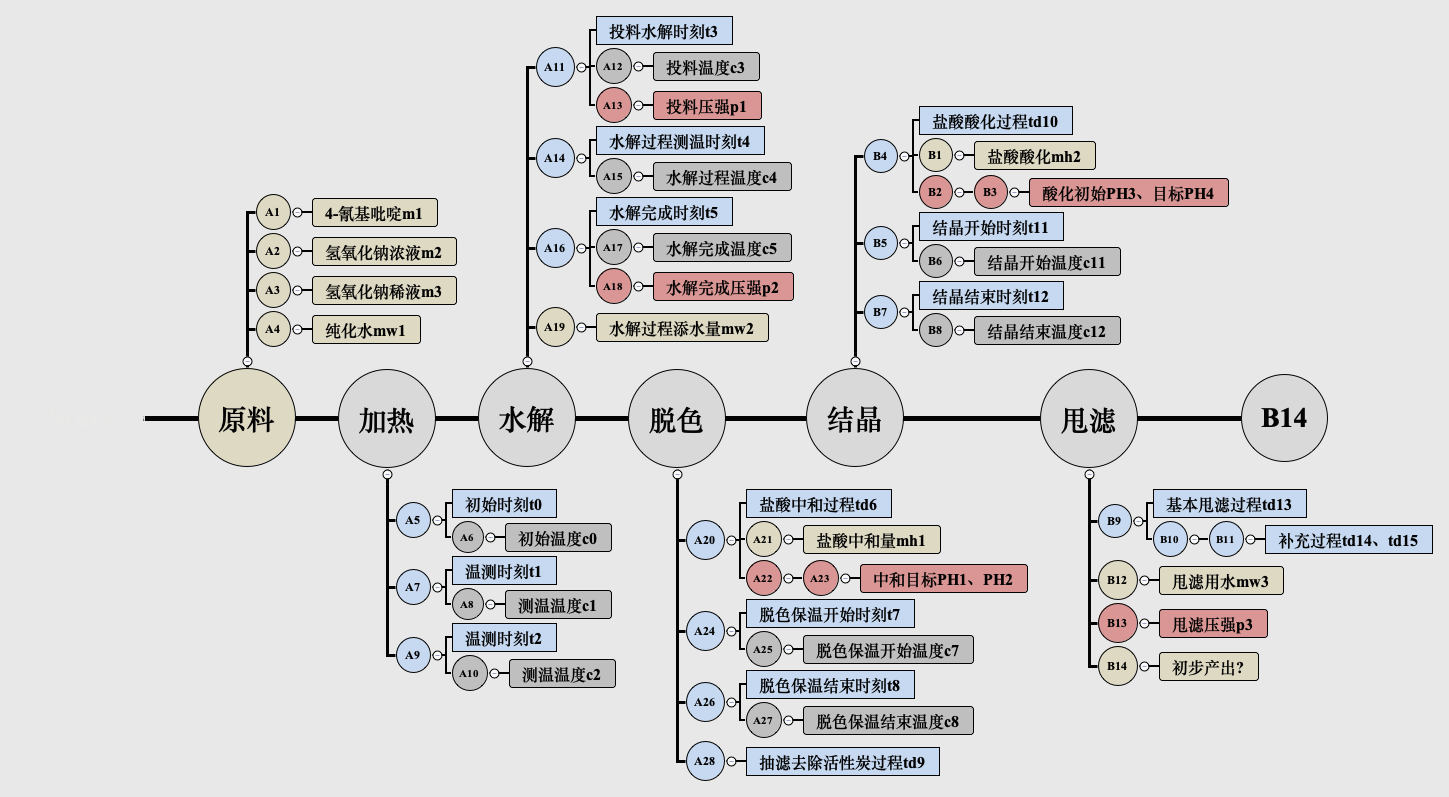
生产各个环节的特征以及相关时间
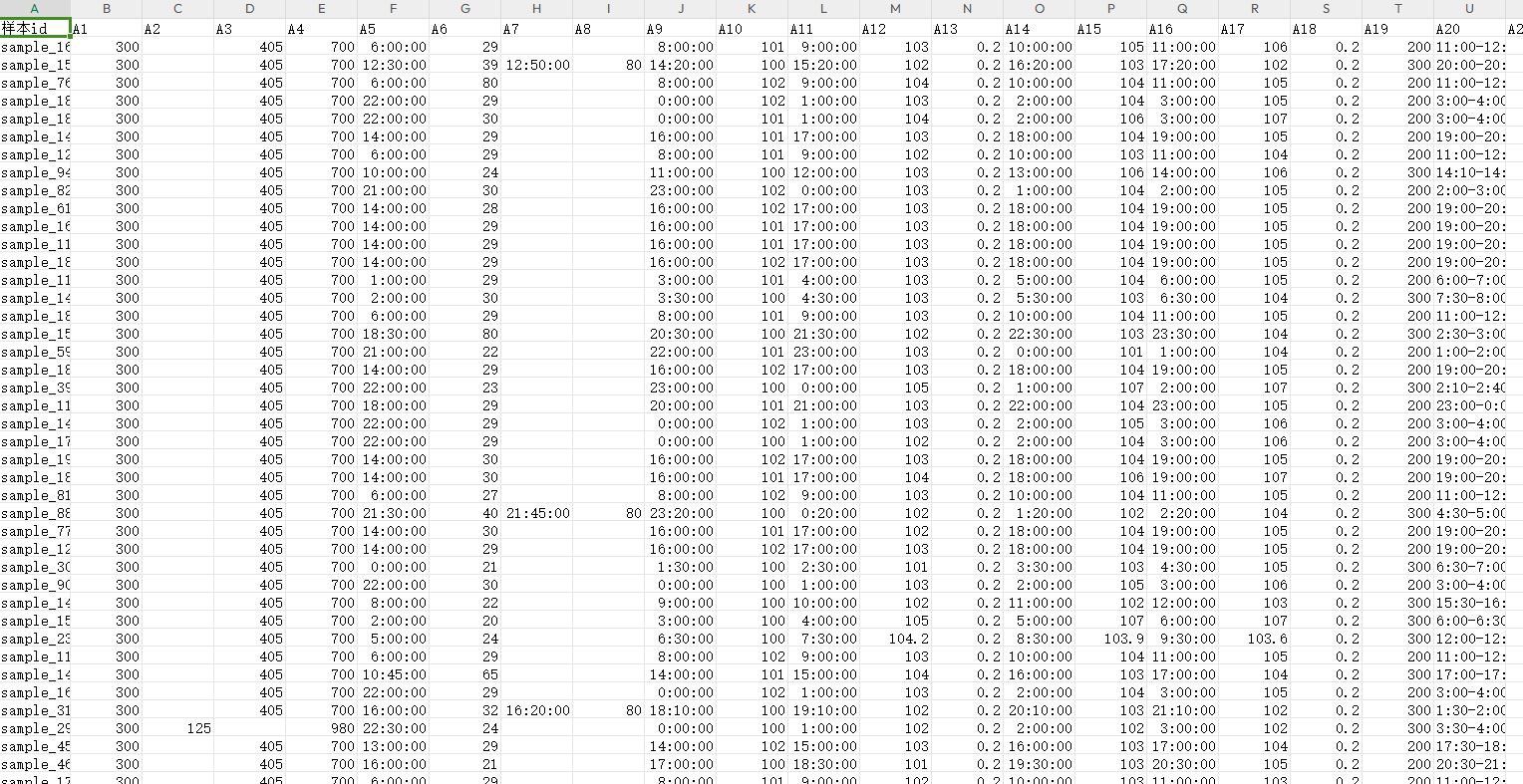
部分数据:
特征处理关键: 时间数据如何处理?
数据异常检查
导入工具包
import pandas as pd
import numpy as np
import warnings
import xgboost as xgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error as mse
warnings.simplefilter('ignore')
读取数据
一个训练集和两个测试集
df_trn = pd.read_csv(
'data/jinnan_round1_train_20181227.csv', encoding='GB2312')
df_tst_a = pd.read_csv(
'data/jinnan_round1_testA_20181227.csv', encoding='GB2312')
df_tst_b = pd.read_csv(
'data/jinnan_round1_testB_20190121.csv', encoding='GB2312')
df_trn.head()
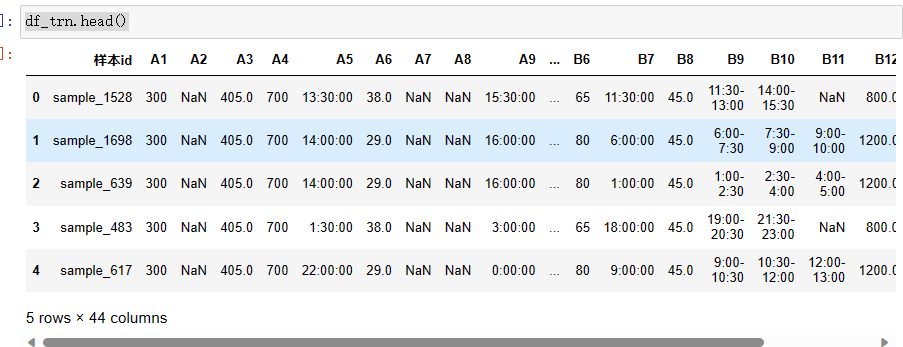
df_trn.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1396 entries, 0 to 1395
Data columns (total 44 columns):
样本id 1396 non-null object
A1 1396 non-null int64
A2 42 non-null float64
A3 1354 non-null float64
A4 1396 non-null int64
A5 1396 non-null object
A6 1396 non-null float64
A7 149 non-null object
A8 149 non-null float64
A9 1396 non-null object
A10 1396 non-null int64
A11 1396 non-null object
A12 1396 non-null int64
A13 1396 non-null float64
A14 1396 non-null object
A15 1396 non-null float64
A16 1396 non-null object
A17 1396 non-null float64
A18 1396 non-null float64
A19 1396 non-null int64
A20 1396 non-null object
A21 1393 non-null float64
A22 1396 non-null float64
A23 1393 non-null float64
A24 1395 non-null object
A25 1396 non-null object
A26 1394 non-null object
A27 1396 non-null int64
A28 1396 non-null object
B1 1386 non-null float64
B2 1394 non-null float64
B3 1394 non-null float64
B4 1396 non-null object
B5 1395 non-null object
B6 1396 non-null int64
B7 1396 non-null object
B8 1395 non-null float64
B9 1396 non-null object
B10 1152 non-null object
B11 547 non-null object
B12 1395 non-null float64
B13 1395 non-null float64
B14 1396 non-null int64
收率 1396 non-null float64
dtypes: float64(18), int64(8), object(18)
memory usage: 480.0+ KB
数据量不多,如果觉得数据不够,可做适当的数据增强
数据检查与问题修正
- 分析是否有离群点、缺失值等
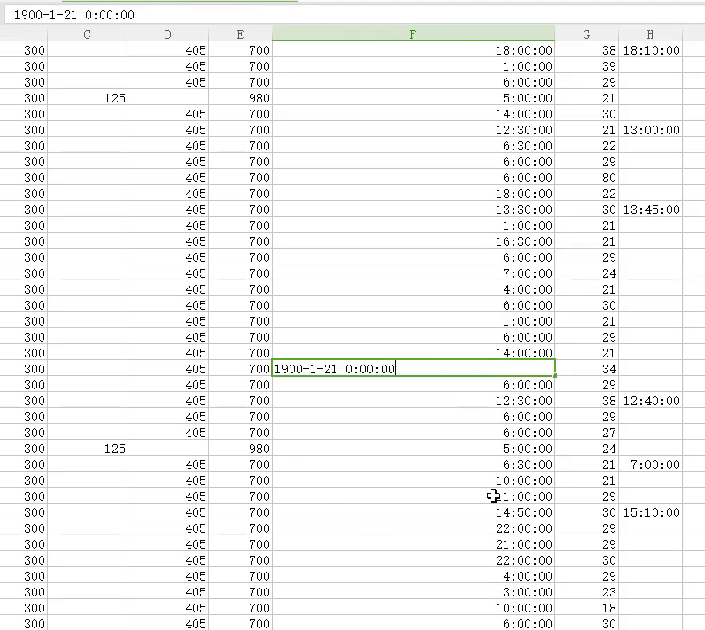
可以手动查看数据excel表,分析是否存在问题,比如A5 A9存在部分数据不统一的问题
也可写脚本判断
def train_abnormal_revise(data):
df_trn = data.copy() #复制一份
df_trn.loc[(df_trn['A1'] == 200) & (df_trn['A3'] == 405), 'A1'] = 300
df_trn['A5'] = df_trn['A5'].replace('1900/1/21 0:00', '21:00:00')
df_trn['A5'] = df_trn['A5'].replace('1900/1/29 0:00', '14:00:00')
df_trn['A9'] = df_trn['A9'].replace('1900/1/9 7:00', '23:00:00')
df_trn['A9'] = df_trn['A9'].replace('700', '7:00:00')
df_trn['A11'] = df_trn['A11'].replace(':30:00', '00:30:00')
df_trn['A11'] = df_trn['A11'].replace('1900/1/1 2:30', '21:30:00')
df_trn['A16'] = df_trn['A16'].replace('1900/1/12 0:00', '12:00:00')
df_trn['A20'] = df_trn['A20'].replace('6:00-6:30分', '6:00-6:30')
df_trn['A20'] = df_trn['A20'].replace('18:30-15:00', '18:30-19:00')
df_trn['A22'] = df_trn['A22'].replace(3.5, np.nan)
df_trn['A25'] = df_trn['A25'].replace('1900/3/10 0:00', 70).astype(int)
df_trn['A26'] = df_trn['A26'].replace('1900/3/13 0:00', '13:00:00')
df_trn['B1'] = df_trn['B1'].replace(3.5, np.nan)
df_trn['B4'] = df_trn['B4'].replace('15:00-1600', '15:00-16:00')
df_trn['B4'] = df_trn['B4'].replace('18:00-17:00', '16:00-17:00')
df_trn['B4'] = df_trn['B4'].replace('19:-20:05', '19:05-20:05')
df_trn['B9'] = df_trn['B9'].replace('23:00-7:30', '23:00-00:30')
df_trn['B14'] = df_trn['B14'].replace(40, 400)
return df_trn
def test_a_abnormal_revise(data):
df_tst = data.copy()
df_tst['A5'] = df_tst['A5'].replace('1900/1/22 0:00', '22:00:00')
df_tst['A7'] = df_tst['A7'].replace('0:50:00', '21:50:00')
df_tst['B14'] = df_tst['B14'].replace(785, 385)
return df_tst
def train_abnormal_adjust(data):
df_trn = data.copy()
df_trn.loc[df_trn['样本id'] == 'sample_1894', 'A5'] = '14:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_1234', 'A9'] = '0:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_1020', 'A9'] = '18:30:00'
df_trn.loc[df_trn['样本id'] == 'sample_1380', 'A11'] = '15:30:00'
df_trn.loc[df_trn['样本id'] == 'sample_844', 'A11'] = '10:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_1348', 'A11'] = '17:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_25', 'A11'] = '00:30:00'
df_trn.loc[df_trn['样本id'] == 'sample_1105', 'A11'] = '4:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_313', 'A11'] = '15:30:00'
df_trn.loc[df_trn['样本id'] == 'sample_291', 'A14'] = '19:30:00'
df_trn.loc[df_trn['样本id'] == 'sample_1398', 'A16'] = '11:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_1177', 'A20'] = '19:00-20:00'
df_trn.loc[df_trn['样本id'] == 'sample_71', 'A20'] = '16:20-16:50'
df_trn.loc[df_trn['样本id'] == 'sample_14', 'A20'] = '18:00-18:30'
df_trn.loc[df_trn['样本id'] == 'sample_69', 'A20'] = '6:10-6:50'
df_trn.loc[df_trn['样本id'] == 'sample_1500', 'A20'] = '23:00-23:30'
df_trn.loc[df_trn['样本id'] == 'sample_1524', 'A24'] = '15:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_1524', 'A26'] = '15:30:00'
df_trn.loc[df_trn['样本id'] == 'sample_1046', 'A28'] = '18:00-18:30'
df_trn.loc[df_trn['样本id'] == 'sample_1230', 'B5'] = '17:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_97', 'B7'] = '1:00:00'
df_trn.loc[df_trn['样本id'] == 'sample_752', 'B9'] = '11:00-14:00'
df_trn.loc[df_trn['样本id'] == 'sample_609', 'B11'] = '11:00-12:00'
df_trn.loc[df_trn['样本id'] == 'sample_643', 'B11'] = '12:00-13:00'
df_trn.loc[df_trn['样本id'] == 'sample_1164', 'B11'] = '5:00-6:00'
return df_trn
def test_a_abnormal_adjust(data):
df_tst = data.copy()
df_tst.loc[df_tst['样本id'] == 'sample_919', 'A9'] = '19:50:00'
return df_tst
def test_b_abnormal_adjust(data):
df_tst = data.copy()
df_tst.loc[df_tst['样本id'] == 'sample_566', 'A5'] = '18:00:00'
df_tst.loc[df_tst['样本id'] == 'sample_40', 'A20'] = '5:00-5:30'
df_tst.loc[df_tst['样本id'] == 'sample_531', 'B5'] = '1:00'
return df_tst
df_trn = train_abnormal_revise(df_trn).pipe(train_abnormal_adjust)
df_tst_a = test_a_abnormal_revise(df_tst_a).pipe(test_a_abnormal_adjust)
df_tst_b = test_b_abnormal_adjust(df_tst_b)
标签与数据集整合
df_trn, df_tst = df_trn.copy(), df_tst_a.copy()
df_target = df_trn['收率']
del df_trn['收率']
df_trn_tst = df_trn.append(df_tst, ignore_index=False).reset_index(
drop=True)
由于训练集和测试集要进行相同的数据预处理,所以先合并在一起,再分开。
for _df in [df_trn, df_tst, df_trn_tst]:
_df['A3'] = _df['A3'].fillna(405) # 众数填充
时间特征提取
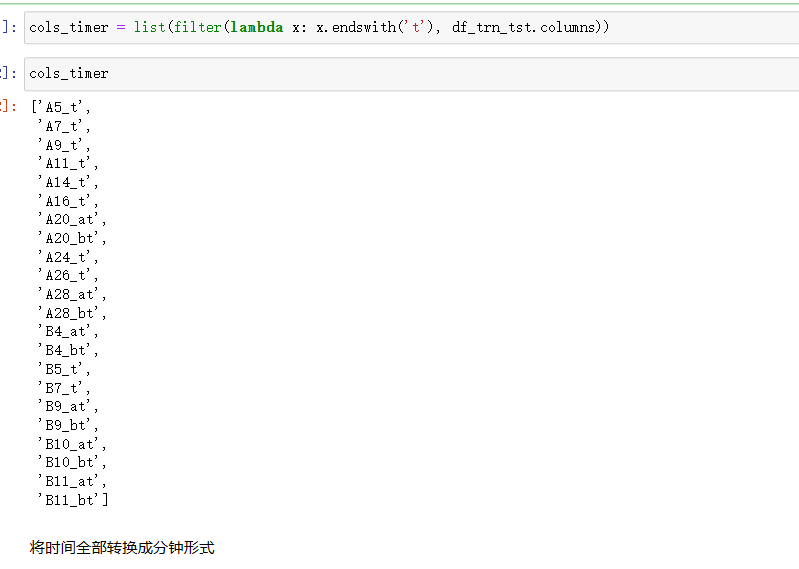
# 所有时间相关列
cols_timer = ['A5', 'A7', 'A9', 'A11', 'A14', 'A16', 'A24', 'A26', 'B5', 'B7']
# 同时对训练和测试集进行相同处理
for _df in [df_trn_tst, df_trn, df_tst]:
# 添加列名标记
_df.rename(columns={_col: _col + '_t' for _col in cols_timer},
inplace=True)
# 遍历所有持续时间相关列例如21:00-21:30
for _col in ['A20', 'A28', 'B4', 'B9', 'B10', 'B11']:
# 取到当前列的索引
_idx_col = _df.columns.tolist().index(_col)
# 添加新的一列,表示起始时间,split表示分别取开始和结束时间,用索引来指定
_df.insert(_idx_col + 1, _col + '_at',
_df[_col].str.split('-').str[0])
# 添加新的一列,表示终止时间
_df.insert(_idx_col + 2, _col + '_bt',
_df[_col].str.split('-').str[1])
# 删除持续时间
del _df[_col]
cols_timer = cols_timer + [_col + '_at', _col + '_bt']
如将A20转成多个特征,分解成起始时间 结束时间 时间段
将时间点转换为数值,如转换为分钟单位
将时间全部转换成分钟形式:
def time_to_min(x):
if x is np.nan:
return np.nan
else:
x = x.replace(';', ':').replace(';', ':')
x = x.replace('::', ':').replace('"', ':')
h, m = x.split(':')[:2]
h = 0 if not h else h
m = 0 if not m else m
return int(h)*60 + int(m)
对所有列执行上面的操作
for _df in [df_trn_tst, df_trn, df_tst]:
for _col in cols_timer:
_df[_col] = _df[_col].map(time_to_min)
各道工序特征构建
创建一个id特征来准备添加特征
raw = df_trn_tst.copy()
df = pd.DataFrame(raw['样本id'])
df.head()
温度相关特征
# 加热过程
df['P1_S1_A6_0C'] = raw['A6'] # 容器初始温度
df['P1_S2_A8_1C'] = raw['A8'] # 首次测温温度
df['P1_S3_A10_2C'] = raw['A10'] # 准备水解温度
df['P1_C1_C0_D'] = raw['A8'] - raw['A6'] # 测温温差
df['P1_C2_C0_D'] = raw['A10'] - raw['A6'] # 初次沸腾温差
# 水解过程
df['P2_S1_A12_3C'] = raw['A12'] # 水解开始温度
df['P2_S2_A15_4C'] = raw['A15'] # 水解过程测温温度
df['P2_S3_A17_5C'] = raw['A17'] # 水解结束温度
df['P2_C3_C0_D'] = raw['A12'] - raw['A6'] # 水解开始与初始温度温差
df['P2_C3_C2_D'] = raw['A12'] - raw['A10'] # 水解开始前恒温温差
df['P2_C4_C3_D'] = raw['A15'] - raw['A12'] # 水解过程中途温差
df['P2_C5_C4_D'] = raw['A17'] - raw['A15'] # 水解结束中途温差
df['P2_C5_C3_KD'] = raw['A17'] - raw['A12'] # 水解起止温差
# 脱色过程
df['P3_S2_A25_7C'] = raw['A25'] # 脱色保温开始温度
df['P3_S3_A27_8C'] = raw['A27'] # 脱色保温结束温度
df['P3_C7_C5_D'] = raw['A25'] - raw['A17'] # 降温温差
df['P3_C8_C7_KD'] = raw['A27'] - raw['A25'] # 保温温差
# 结晶过程
df['P4_S2_B6_11C'] = raw['B6'] # 结晶开始温度
df['P4_S3_B8_12C'] = raw['B8'] # 结晶结束温度
df['P4_C11_C8_D'] = raw['B6'] - raw['A27'] # 脱色结束到结晶温差
df['P4_C12_C11_KD'] = raw['B8'] - raw['B6'] # 结晶温差
温度相关统计特征
_funcs = ['mean', 'std', 'sum']
# 遍历每一种统计指标
for _func in _funcs:
# 对每一个样本计算各项指标
df[f'P2_C2-C5_{_func}'] = raw[['A10', 'A12', 'A15', 'A17']].\
agg(_func, axis=1) # 沸腾过程温度
df[f'P2_D3-D5_{_func}'] = \
df[[f'P2_C{i}_C{i-1}_D' for i in range(3, 6)]].\
abs().agg(_func, axis=1) # 沸腾过程绝对温差
df[f'P2_C1-C12_KD_ABS_{_func}'] = \
df[[_f for _f in df.columns if _f.endswith('KD')]].\
abs().agg(_func, axis=1) # 关键过程绝对温差
df[f'P2_C1-C12_D_{_func}'] = \
df[[_f for _f in df.columns if _f.endswith('D')]].\
abs().agg(_func, axis=1) # 所有过程绝对温差
df[f'P2_LARGE_KD_{_func}'] = \
df[['P2_C3_C0_D', 'P3_C7_C5_D', 'P4_C12_C11_KD']].\
abs().agg(_func, axis=1) # 大温差绝对温差
设置索引,便于各种特征类别合并
df_temperature = df.set_index('样本id')
时间相关特征
水耗相关特征
合并所有特征
df_feature = pd.concat([df_materials, df_duration, df_temperature, df_interact], axis=1).reset_index()
df_trn = df_feature.iloc[:len(df_trn)].reset_index(drop=True)
df_trn['收率'] = df_target
df_tst = df_feature.iloc[len(df_trn):].reset_index(drop=True)
df_tst['收率'] = np.nan
准备训练数据
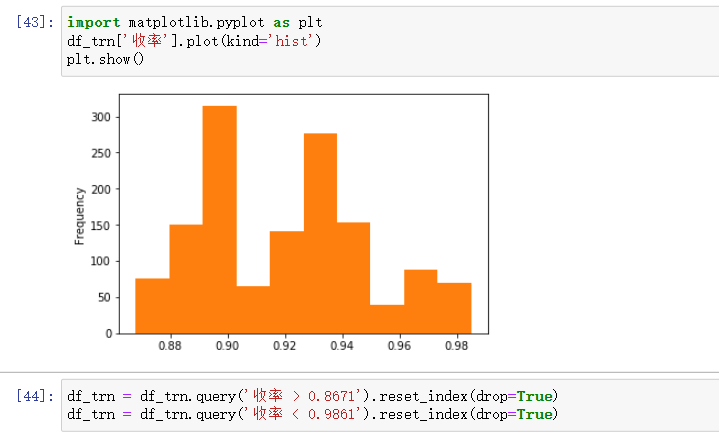
筛选常规数据
根据分布,将一些离群点的数据筛掉
训练xgboost模型
def xgb_cv(train, test, params, fit_params, feature_names, nfold, seed):
# 创建结果df
train_pred = pd.DataFrame({
'id': train['样本id'],
'true': train['收率'],
'pred': np.zeros(len(train))})
# 测试提交结果
test_pred = pd.DataFrame({'id': test['样本id'], 'pred': np.zeros(len(test))})
# 交叉验证
kfolder = KFold(n_splits=nfold, shuffle=True, random_state=seed)
# 构造测试DMatrix
xgb_tst = xgb.DMatrix(data=test[feature_names])
print('\n')
# 遍历cv中每一折数据,通过索引来指定
for fold_id, (trn_idx, val_idx) in enumerate(kfolder.split(train['收率'])):
# 构造当前训练的DMatrix
xgb_trn = xgb.DMatrix(
train.iloc[trn_idx][feature_names],
train.iloc[trn_idx]['收率'])
# 构造当前验证的DMatrix
xgb_val = xgb.DMatrix(
train.iloc[val_idx][feature_names],
train.iloc[val_idx]['收率'])
# 训练回归模型
xgb_reg = xgb.train(params=params, dtrain=xgb_trn, **fit_params,
evals=[(xgb_trn, 'train'), (xgb_val, 'valid')])
# 得到验证结果
val_pred = xgb_reg.predict(
xgb.DMatrix(train.iloc[val_idx][feature_names]),
ntree_limit=xgb_reg.best_ntree_limit)
train_pred.loc[val_idx, 'pred'] = val_pred
# print(f'Fold_{fold_id}', mse(train.iloc[val_idx]['收率'], val_pred))
test_pred['pred'] += xgb_reg.predict(
xgb_tst, ntree_limit=xgb_reg.best_ntree_limit) / nfold
print('\nCV LOSS:', mse(train_pred['true'], train_pred['pred']), '\n')
return test_pred
设置训练参数
fit_params = {'num_boost_round': 10800, #
'verbose_eval': 300, # 打印参数
'early_stopping_rounds': 360} # 提前停止策略
params_xgb = {'eta': 0.01, 'max_depth': 7, 'subsample': 0.8,
'booster': 'gbtree', 'colsample_bytree': 0.8,
'objective': 'reg:linear', 'silent': True, 'nthread': 4}
一般情况下,树的数量越多,学习率稍微大点。
TIPS
- 先尽可能的将特征列出来,最后再做筛选
- 特征本身 和 特征相关的统计特征
- 使用xgboost 或者 lightgbm 等会自动填充缺失值,可不提前填充。 (最好提前填充,方便做对比实验)
- 使用xgboost时,数据转换成Dmatrix, 速度会提升,特别是针对大数据