阿里云ESC服务器CPU一直处于100%该如何排查?
问题背景
使用 docker 容器化部署整个项目,然后服务器的CPU一直处于100%,此时就出现了问题:此时如果重新开启一个窗口去连接,或者访问宝塔面板、Navicat连接MySQL就连接不上了,问题很严重
问题分析
-
服务器CPU飙升至100%常见原因?
- 程序或应用负载过重:如果你在服务器上运行的程序或应用负载很重,会导致CPU使用率飙升。这可能是因为程序设计不合理、代码有bug、数据库查询频繁等原因导致的。
- 访问量激增:如果你的网站或服务突然遭受大量访问,服务器会面临巨大的压力,导致CPU使用率飙升。这可能是由于广告宣传、流量攻击或媒体报道等原因引起的。
- 恶意软件或病毒感染:如果服务器中存在恶意软件或病毒,它们可能会消耗大量的CPU资源。这些恶意软件可以通过漏洞利用、下载非法软件、点击恶意链接等方式进入服务器。
- 资源不足:如果服务器配置不足,例如内存不足或硬盘IO性能较差,会导致CPU负载过高。这种情况下,服务器无法及时处理任务,从而导致CPU使用率飙升。
- 崩溃或错误日志:服务器出现崩溃或错误可能会导致CPU使用率飙升。你可以检查服务器的日志文件,查找错误信息以确定问题所在。
-
如何排查?
这里提供一下我的排查思路吧,主要分为两种情况,恰巧这两种情况我都遇到了🤣
-
方案一:针对CPU100%,同时能够正常执行指令的
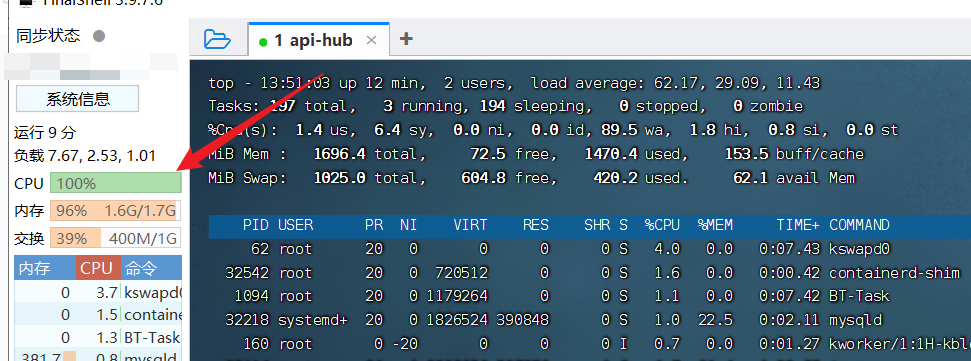
- 定位凶手。使用
top -c查看CPU 占用情况 ,按P(大写)可以倒序查看占CPU占用率 - 分析原因。针对CPU超高的,如果这个进程我们明确知道,它并不是一个特别重要的进程,我们可以先直接通过
kill -9 pid杀死它,然后仔细 程序是否存在问题,比如死循环,循环依赖等等问题;如果是一个很重要的进程,我们可以通过jstack -l pid > pid.stack将这个进程的堆栈信息重定向到pid.stack,然后将这个进程对应的 tid 转换为16进制数(这个转换我们可以直接搜索在线进制转换即可,网上一大把),最后cat pid.stack | grep '16tid' -C 20查看该线程打印出来的堆栈信息
备注:pid是进程id,tid是线程id,16tid是tid转成16进制后的结果,注意区分,jvm的进程快照中线程显示是16进制的所以需要转成16进制
上面那个方法是比较通用且常见的方法, 而我之前遇到过因为启动Nacos容器出现CPU飙升100%(感兴趣的可以参考这篇文章:Docker运行Nacos容器,过一会就报错
UnsatisfiedDependencyException_知识汲取者的博客-CSDN博客),我是直接通过docker logs --tail 500 nacos查看日志,然后发现是 堆内存不够导致的,最终通过配置 jvm 堆内存参数,最终成功启动 nacos - 定位凶手。使用
-
方案二:针对CPU100%,但是不能够正常执行指令的,也就是窗口直接卡的动都不动了
这种情况没有其它办法,只能通过重启服务器了
恰巧我也遇到过,之前在使用
docker build -t指令为三个后端 jar 包构建程一个容器的过程中,一下启动导致CPU直接飙升100%结果终端页面卡的动都动不了了,重启服务器后,我经过不断排查,最终定位到是由于我的服务器内存太小了,由于我有之前 Nacos 的bug解决经验了,所以这一次我就直接给每一个 jar 包的启动过程中都限制最大堆内存,最终就成功解决了
-
PS:相信过不了多久,我这段时间的项目就要上线了,到时候应该还会发一篇文章用于介绍我的新项目,尽情期待吧(●’◡’●)
参考文章:
- 排查Linux实例CPU资源使用率高达100%的异常问题-阿里云帮助中心 (aliyun.com)
- 【CPU100%排查】CPU100%问题排查方案 - 听风是雨 - 博客园 (cnblogs.com)
- 论线上如何排查一次CPU100%的情况 - 知乎 (zhihu.com)






![[技术讨论]讨论问题的两个基本原则——17年前的文字仍然有效](https://img-blog.csdnimg.cn/img_convert/361fd577ce98ed2bcf38f3c92d2f24b7.jpeg)