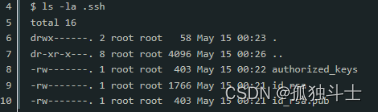
文章目录
- 任务定义
- 任务难点
- 数据集
- 任务现状
- 评估指标
- 可以思考的创新的角度
不错的博客,还有框架推荐
南京大学开源MultiSports:面向体育运动场景的细粒度多人时空动作检测数据集…
论文阅读推荐、Video Understanding(3)Spatio-Temporal Action Localization时空动作定位
任务定义
时空动作检测 (spatio-temporal action detection) : 输入一段未剪辑(untrimmed)视频,不仅需要识别视频中动作的起止时序和对应的类别,还要在空间范围内用一个包围框 (bounding box)标记出人物的空间位置。
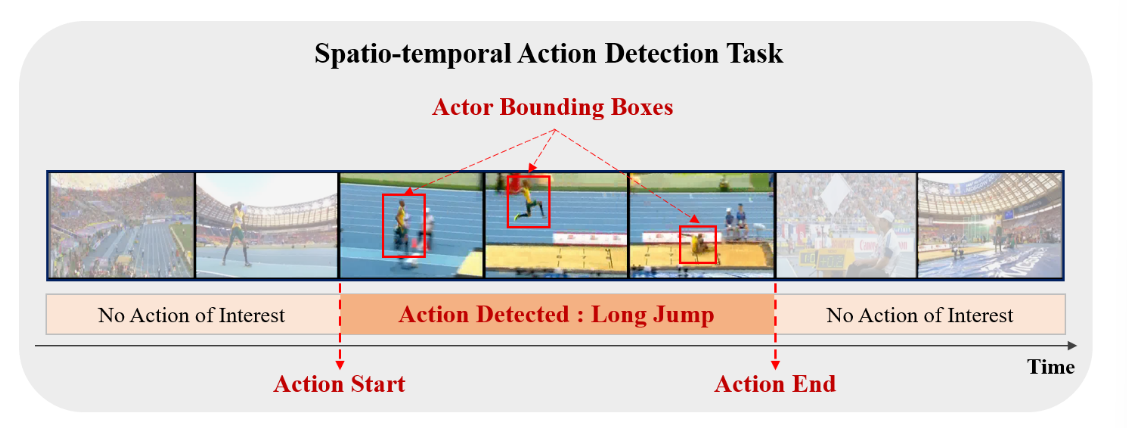
Spatio-temporal action detection aims to localize action instances in both space and time, and recognize the action labels.In the fully-supervised setting of this task, the temporal boundary of action instances at the video-level, the spatial bounding box of actions at the frame-level, and action labels are provided during training and must be detected during inference. The start and end of action “long jump” are detected in temporal domain. Also, bounding box of the actor performing the action is detected in each frame in spatial domain.
时空动作检测的目的是在空间和时间上定位动作实例,并识别动作标签。在本任务的全监督设置中,视频级动作实例的时间边界、帧级动作的空间边界框和动作标签在训练期间提供,并且必须在推理期间检测到。“跳远”动作的开始和结束在时间域中被检测到。并且,在空间域中的每一帧中检测执行动作的参与者的边界框。
任务难点
时空建模: 这一领域的关键挑战之一是如何建模视频中的时空信息。通常,时空建模包括对视频中的运动、姿态和场景进行建模,以便准确地捕捉动作的时空特征。
数据集
视频理解领域内的数据集(包括S-TAL)
现有数据集主要分为两大类:
-
以UCF101-24和JHMDB为代表的密集标注数据集 (25FPS),这类数据集每个视频只有一种动作,大部分视频是单人在做一些语义简单的重复动作,动作类别与背景高度相关。
-
以AVA为代表的稀疏标注数据集 (1FPS),由于稀疏标注,他们没有给出明确的动作边界,现有的方法更像是instance级别的动作识别,弱化时序定位;同时动作类别是日常的原子动作,运动速度慢、形变小,跟踪难度较低,分类不需要复杂的人与物与环境的建模和推理。
Atomic Visual Actions(原子视觉行为):“原子动作” 指的是动作数据集中的基本、最小单位的动作。这些动作通常是在动作识别任务中的最小可识别单位。
“原子动作” 是指动作数据集中的基本、日常生活中常见、持续时间短暂、形变小、速度慢、跟踪难度较低的动作片段。这些原子动作通常用于弱标注数据集,因为它们相对容易识别和分类,不需要复杂的人、物体和环境建模和推理。
- AVA is designed for spatio-temporal action detection and consists of 437 videos where each video is a 15 minute segment taken from a movie. Each person appearing in a test video must be detected in each frame and the multi-label actions of the detected person must be predicted correctly. The action label space contains 80 atomic action classes but often the results are reported on the most frequent 60 classes.AVA 是为时空动作检测而设计的,由 437 个视频组成,每个视频是取自电影的 15 分钟片段。必须在每一帧中检测到测试视频中出现的每个人,并且必须正确预测检测到的人的多标签动作。操作标签空间包含 80 个原子操作类,但结果通常报告最常见的 60 个类。
任务现状
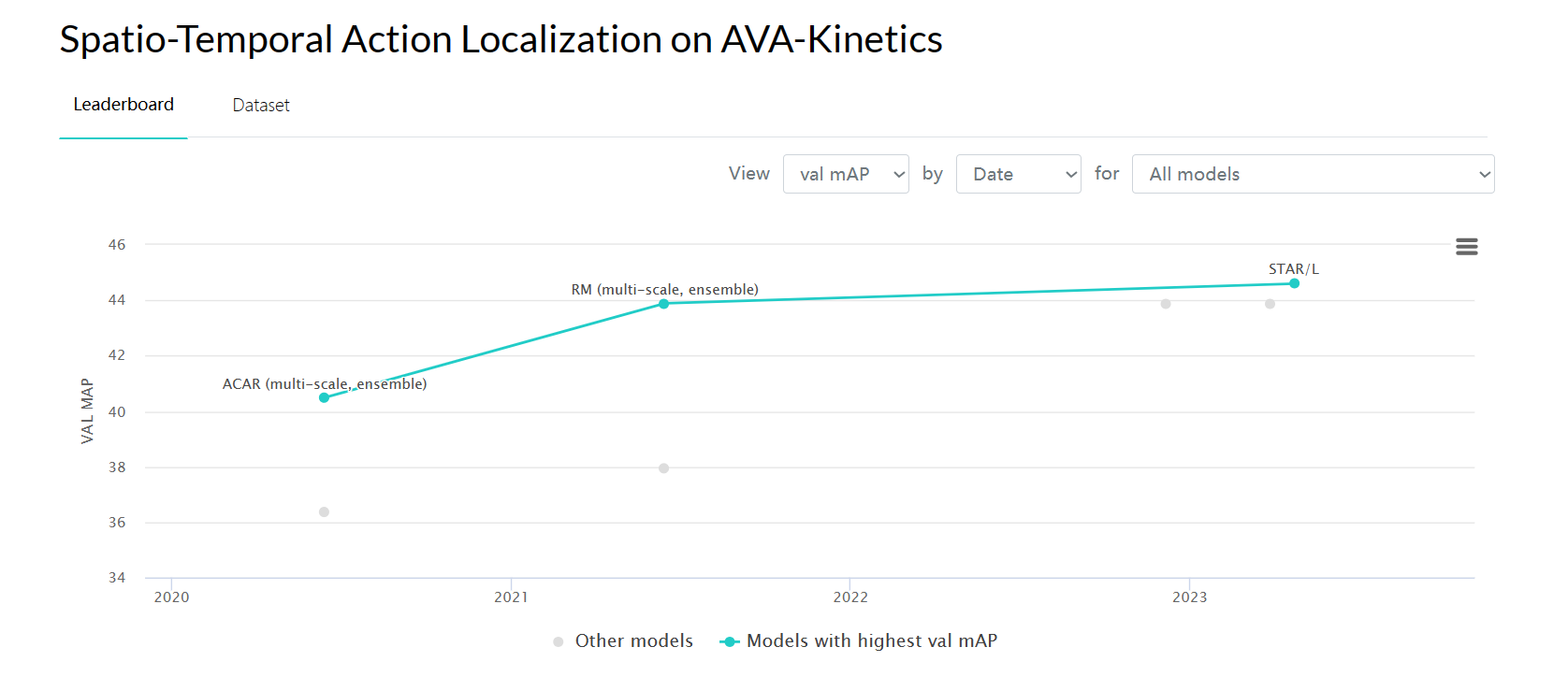
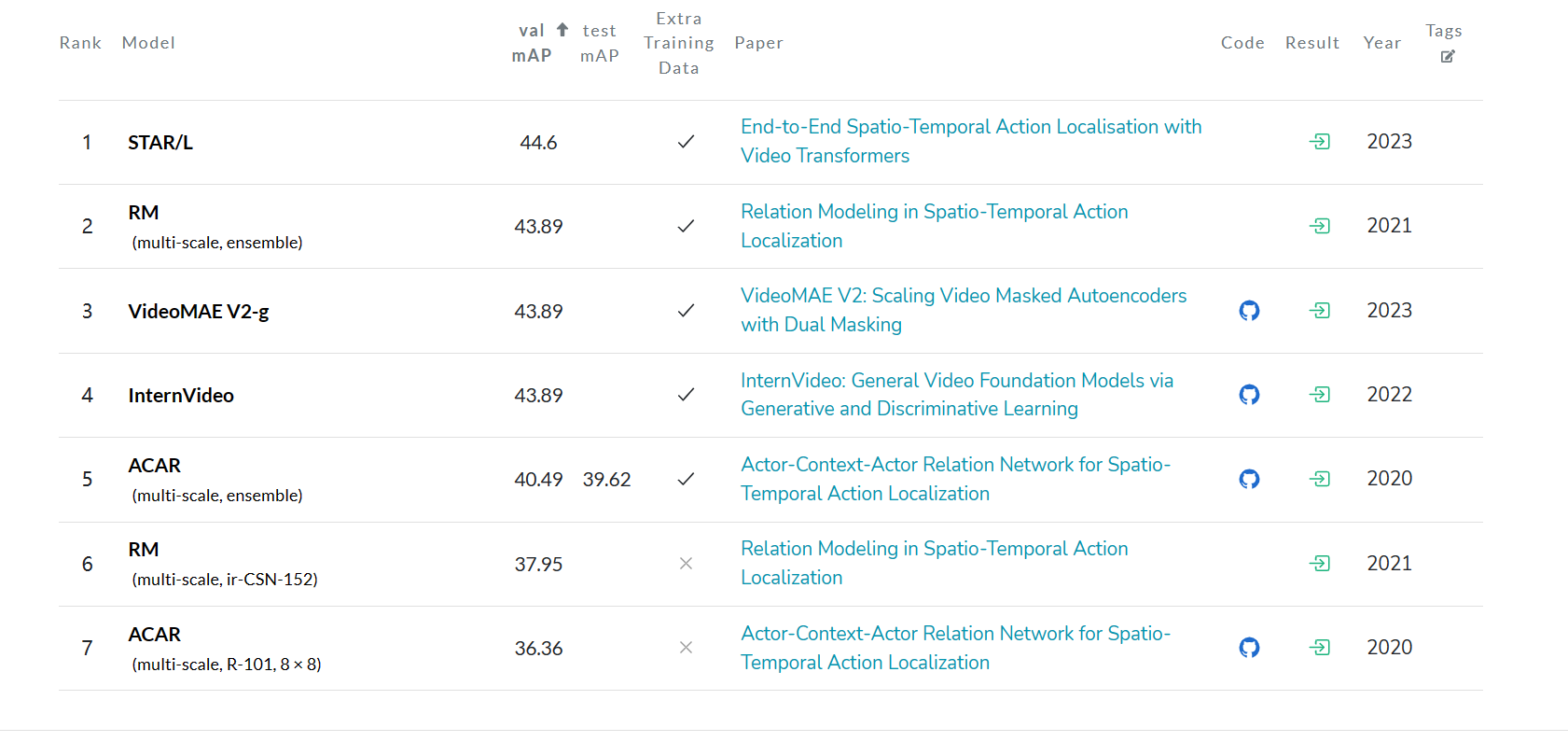
评估指标
- frame-AP: frame-AP measures the area under the precision-recall curve of the detections for each frame.测量每帧检测的精确召回率曲线下的面积。A detection is correct if the intersection-overunion with the ground truth at that frame is greater than a threshold and the action label is correctly predicted.如果在该帧与基础真值的交集过并大于阈值,并且正确预测动作标签,则检测是正确的。
- video-AP: video-AP measures the area under the precision-recall curve of the action tubes predictions. A tube is correct if the mean per frame intersection-over-union with the ground truth across the frames of the video is greater than a threshold and the action label is correctly predicted.
"action tubes predictions"是指在视频中检测到的动作实例被连成的一系列时间和空间上的区域。该区域表示了动作的开始和结束时间以及动作发生的空间位置。"video-AP measures the area under the precision-recall curve of the action tubes predictions"是指通过计算视频中所有动作实例的预测区域与实际区域之间的交叉比例,来评估模型的性能。
在视频的每一帧上,预测出的动作区域与真实动作区域的交并比的平均值需要大于一个设定的阈值,才被认为是正确的动作区域。
可以思考的创新的角度
-
多模态信息: 除了视频帧外,还可以利用音频、文本描述等多模态信息来提高动作检测的性能。这种方法可以更全面地理解视频内容。
-
注意力机制: 在时空动作检测中,注意力机制常常被引入,以帮助模型关注视频中与动作相关的关键时刻和空间区域。