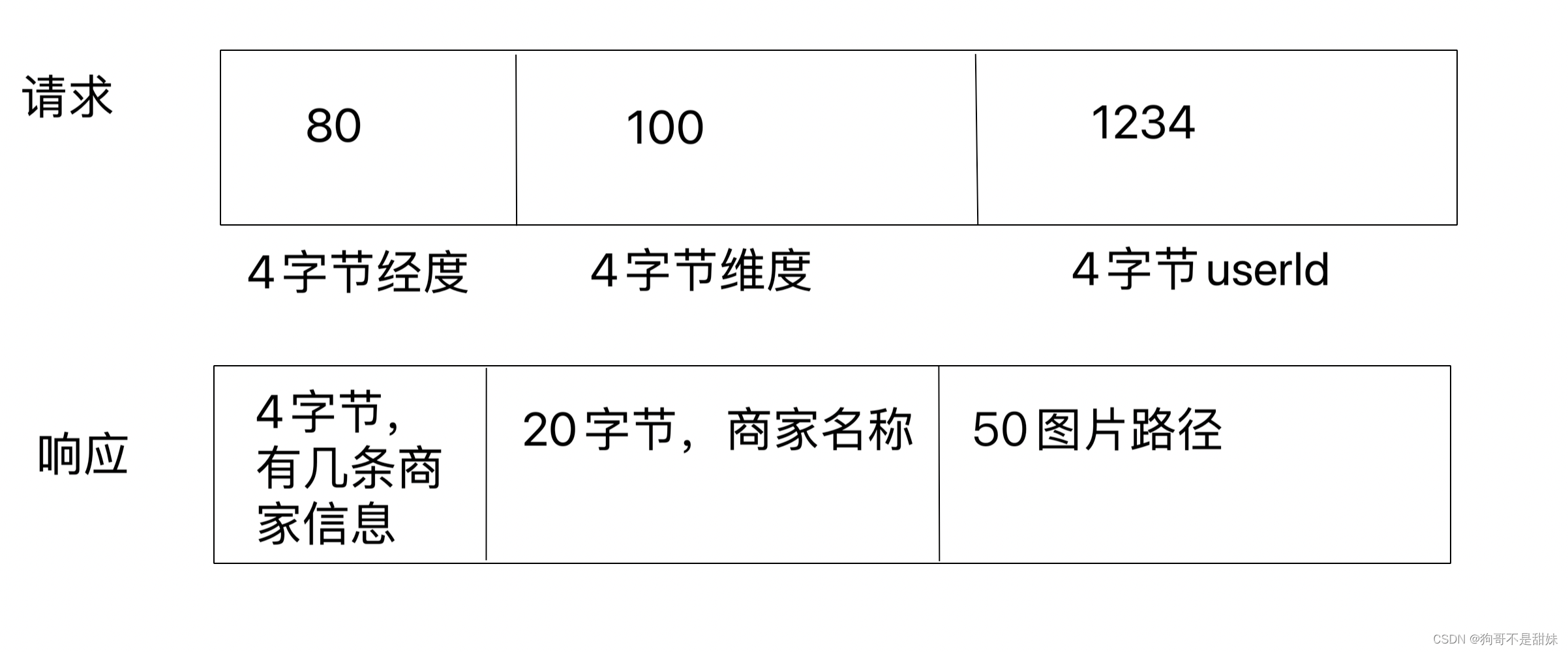
CLEAN-SC 波束形成声源识别方法计算速度快、成像干净清晰、结果准确度高,但当传统延迟求和算法在各声源处输出的主瓣严重融合时,亦无法准确分辨声源。造成该缺陷的原因为: 主瓣严重融合时,CLEAN-SC 所基于的延迟求和输出峰值所在聚焦点即为声源点的假设不成立。从源相干性角度,若某聚焦点处的延迟求和输出主要由某声源贡献时,该聚焦点可标示该声源,即基于该聚焦点的位置及强度信息可重构该声源在各传声器处产生声压的互谱矩阵。鉴于此,以CLEAN-SC 识别的声源为初值迭代寻找正确的声源位置及强度,每次迭代中,最小化其余声源与某一声源的波束形成贡献的比值为每个声源选择标示点,根据标示点更新声源。仿真及试验均证明: 所给方法比传统CLEAN-SC 具有更高分辨率,使近距离低频率声源的准确识别变得可行。
基本理论
DAS
图1 为波束形成声源识别的布局示意图,其利用一组传声器( 符号“◆”所示) 测量声压信号,假设聚焦声源面并离散为一组聚焦点( 符号“★”所示) ,基于DAS 进行后处理时,按聚焦点对各传声器测量的声压信号进行“相位对齐”和“求和运算”,使真实声源所在聚焦点的输出量被加强,其它聚焦点的输出量被衰减,从而识别声源。
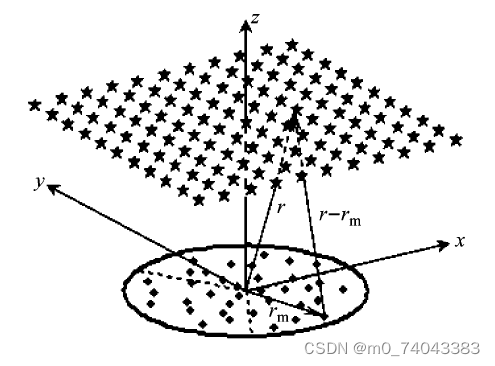
图1. 波束形成声源识别布局示意图
记
p
p
p为各传声器测量的声压信号组成的列向量,
C
=
p
p
H
C = pp^H
C=ppH为各传声器测量的声压信号的互谱矩阵,上标“H”表示转置共轭,
r
r
r 为聚焦点位置坐标,
μ
(
r
)
\mu(r)
μ(r) 为
r
r
r 聚焦点的聚焦向量,则
r
r
r 聚焦点的DAS 输出
b
(
r
)
b(r)
b(r) 为:
b
(
r
)
=
μ
H
(
r
)
C
μ
(
r
)
(1)
b(\bm{r}) = \bm{\mu}^H(\bm{r})\bm{C}\bm{\mu}(\bm{r}) \tag{1}
b(r)=μH(r)Cμ(r)(1)
μ
(
r
)
=
v
(
r
)
∣
∣
v
(
r
)
∣
∣
2
2
(2)
\bm{\mu}(\bm{r})=\frac{\bm{v}(\bm{r})}{||\bm{v}(\bm{r})||_2^2}\tag{2}
μ(r)=∣∣v(r)∣∣22v(r)(2)
式中,
∣
∣
⋅
∣
∣
2
||\cdot||_2
∣∣⋅∣∣2表示2范数,
v
(
r
)
=
[
v
1
(
r
)
,
v
2
(
r
)
,
⋯
,
v
m
(
r
)
,
⋯
,
v
M
(
r
)
]
T
\bm{v}(\bm{r}) = [v_1(\bm{r}),v_2(\bm{r}),\cdots, v_m(\bm{r}),\cdots,v_M(\bm{r})]^T
v(r)=[v1(r),v2(r),⋯,vm(r),⋯,vM(r)]T为
r
r
r聚焦点处声源的声波传播列向量,上标
T
T
T 表示转置,
m
=
1
,
2
,
⋯
,
M
m=1,2,\cdots,M
m=1,2,⋯,M为传声器索引,
M
M
M为传声器总数,元素
v
m
(
r
)
v_m(r)
vm(r)表示
r
r
r聚焦点处的单位强度点声源在
m
m
m 传声器处产生的声压,表达式为:
v
m
(
r
)
=
e
x
p
(
−
j
k
∣
r
−
r
m
∣
)
r
−
r
m
(3)
v_m(\bm{r})=\frac{exp(-jk|\bm{r}-\bm{r}_m|)}{\bm{r}-\bm{r}_m}\tag{3}
vm(r)=r−rmexp(−jk∣r−rm∣)(3)
式中
j
j
j 为虚数单位,
k
=
2
π
f
/
c
k=2\pi f/c
k=2πf/c为波数,
f
f
f为频率,
c
c
c 为声速,
r
m
r_m
rm为m传声器的坐标位置。
记
r
0
\bm{r}_0
r0为声源位置坐标,
q
(
r
0
)
q(\bm{r}_0)
q(r0)为
r
0
\bm{r}_0
r0处声源的强度,式(1)可写为:
{
b
(
r
)
=
∑
r
0
q
(
r
0
)
p
s
f
(
r
∣
r
0
)
p
s
f
(
r
∣
r
0
)
=
μ
H
(
r
)
v
(
r
0
)
v
H
(
r
0
)
μ
(
r
)
(4)
\left\{ \begin{aligned} b(\bm{r}) & = \sum_{r_0}q(\bm{r}_0) psf (\bm{r}|\bm{r}_0)\\ psf (\bm{r}|\bm{r}_0) & = \bm{\mu}^H(\bm{r}) \bm{v}(\bm{r_0}) \bm{v}^H(\bm{r_0})\bm{\mu}(\bm{r}) \end{aligned} \right. \tag{4}
⎩
⎨
⎧b(r)psf(r∣r0)=r0∑q(r0)psf(r∣r0)=μH(r)v(r0)vH(r0)μ(r)(4)
式中
p
s
f
(
r
∣
r
0
)
psf (\bm{r}|\bm{r}_0)
psf(r∣r0) 为 PSF,表示
r
0
\bm{r}_0
r0处的单位强度点声源在r 聚焦点的DAS 贡献量,显然,
r
\bm{r}
r 聚焦点的DAS 输出等于各声源强度与对应PSF 的乘积的和。若PSF 等于理想的
δ
\delta
δ 函数,DAS 将仅在声源所在聚焦点输出幅值等于声源强度的峰值,而在其它聚焦点输出0,声源识别准确。然而,实际应用中,传声器离散采样等因素使PSF 无法等于理想的
δ
\delta
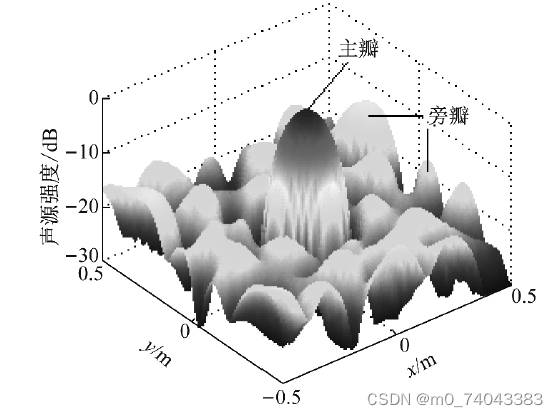
δ函数,图2 给出了聚焦声源面中心聚焦点处声源的PSF,其不仅在声源位置输出宽“主瓣”,还在非声源位置输出高“旁瓣”,主瓣宽度影响分辨率,旁瓣污染成像图,使识别结果的分析具有不确定性。因此,有必要对DAS 结果进行清晰化。
CLEAN-SC
CLEAN-SC 是提高分辨率、衰减旁瓣的有效方法,其基于同一声源产生的主瓣与旁瓣相干的事实,通过反复在DAS 结果中移除与主瓣峰值指示的源相干的成分来清晰化声源识别结果。初始化传声器测量的声压信号的互谱矩阵 D ( 0 ) = C D^{(0)} = C D(0)=C,声源强度分布 Q ( 0 ) = 0 Q^{(0)} = 0 Q(0)=0,由第 n n n 次迭代到第 n + 1 n + 1 n+1 次迭代的步骤为:
- 计算完成
n
n
n次迭代后的 DAS 输出:
b ( n ) ( r ) = μ H ( r ) D ( n ) μ ( r ) b^{(n)}(\bm{r})=\bm{\mu}^H(\bm{r})\bm{D}^{(n)}\bm{\mu}(\bm{r}) b(n)(r)=μH(r)D(n)μ(r) - 搜索主瓣峰值: b m a x ( n ) = m a x ( b ( n ) ) b_{max}^{(n)}=max(\bm{b}^{(n)}) bmax(n)=max(b(n)),这里 b ( n ) = [ b ( n ) ( r ) ] \bm{b}^{(n)} = [b^{(n)}(\bm{r})] b(n)=[b(n)(r)] 为所有聚焦点的DAS 输出组成的向量,并确定该峰值对应的聚焦点位置 r m a x ( n + 1 ) \bm{r}_{max}^{(n+1)} rmax(n+1);
- 计算声源强度分布:
Q ( n + 1 ) ( r m a x ( n + 1 ) ) = Q ( n ) ( r m a x ( n ) ) + b m a x ( n ) (5) Q^{(n+1)}(\bm{r}_{max}^{(n+1)}) = Q^{(n)}(\bm{r}_{max}^{(n)}) + b_{max}^{(n)}\tag{5} Q(n+1)(rmax(n+1))=Q(n)(rmax(n))+bmax(n)(5)
其中, Q ( ⋅ ) Q(·) Q(⋅)为矩阵 Q Q Q的元素,所在位置由括号内坐标向量指示。 - 重构
n
+
1
n+1
n+1次迭代的互谱矩阵
D
(
n
+
1
)
\bm{D}^{(n+1)}
D(n+1) :
{ D ( n + 1 ) = D ( n ) − G ( n + 1 ) G ( n + 1 ) = b m a x ( n ) s ( r m a x ( n + 1 ) ) s H ( r m a x ( n + 1 ) ) (6) \left\{ \begin{aligned} \bm{D}^{(n+1)} & = \bm{D}^{(n)} - \bm{G}^{(n+1)} \\ \bm{G}^{(n+1)} & = b_{max}^{(n)} \bm{s}(\bm{r}_{max}^{(n+1)})\bm{s}^H(\bm{r}_{max}^{(n+1)}) \end{aligned} \right. \tag{6} {D(n+1)G(n+1)=D(n)−G(n+1)=bmax(n)s(rmax(n+1))sH(rmax(n+1))(6)
式中, G ( n + 1 ) \bm{G}^{(n+1)} G(n+1)为分析主瓣峰值与其它聚焦点DAS 输出间的相干性而获得的互谱矩阵, s ( r m a x ( n + 1 ) ) \bm{s}(\bm{r}_{max}^{(n+1)}) s(rmax(n+1))为相应的源成分向量。对于任意 r \bm{r} r 聚焦点, G ( n + 1 ) \bm{G}^{(n+1)} G(n+1)满足 μ H ( r ) D ( n ) μ ( r m a x ( n + 1 ) ) = μ H ( r ) G ( n + 1 ) μ ( r m a x ( n + 1 ) ) \bm{\mu}^H(\bm{r})\bm{D}^{(n)}\bm{\mu}(\bm{r_{max}^{(n+1)}})=\bm{\mu}^H(\bm{r})\bm{G}^{(n+1)}\bm{\mu}(\bm{r}_{max}^{(n+1)}) μH(r)D(n)μ(rmax(n+1))=μH(r)G(n+1)μ(rmax(n+1)),即, D ( n ) μ ( r m a x ( n + 1 ) ) = G ( n + 1 ) μ ( r m a x ( n + 1 ) ) \bm{D}^{(n)}\bm{\mu}(\bm{r_{max}^{(n+1)}})=\bm{G}^{(n+1)}\bm{\mu}(\bm{r}_{max}^{(n+1)}) D(n)μ(rmax(n+1))=G(n+1)μ(rmax(n+1))成立,该式与式(6)联立得:
s ( r m a x ( n + 1 ) ) = D ( n ) μ ( r m a x ( n + 1 ) ) b m a x ( n ) (7) \bm{s}(\bm{r}_{max}^{(n+1)})=\frac{\bm{D}^{(n)}\bm{\mu}(\bm{r_{max}^{(n+1)}})}{b^{(n)}_{max}}\tag{7} s(rmax(n+1))=bmax(n)D(n)μ(rmax(n+1))(7)
重构出 D ( n + 1 ) \bm{D}^{(n+1)} D(n+1) 后,返回第1 步重复循环,直至完成规定的迭代数 N 1 N_1 N1, Q ( N 1 ) \bm{Q}^{(N_1)} Q(N1) 便是最终声源强度分布 Q \bm{Q} Q。
HR-CLEAN-SC
称重构声源在各传声器处产生声压信号的互谱矩阵
G
\bm{G}
G 时所基于的聚焦点为声源标示点,声源标示点所指示的声源为标示声源。传统CLEAN-SC采用的声源标示点为DAS 输出峰值所在的聚焦点,其指示的声源位于峰值位置,强度等于峰值。当DAS输出的主瓣轻微融合或未融合时,峰值中标示声源的贡献成分远大于其它声源,互谱矩阵重构准确,
CLEAN-SC 的声源识别正确; 当DAS 输出的主瓣严重融合时,峰值中各声源的贡献成分均较大,CLEAN-SC将无法正确识别声源。事实上,只要DAS 在声源标示点处的输出主要由标示声源贡献时,便可基于标示点
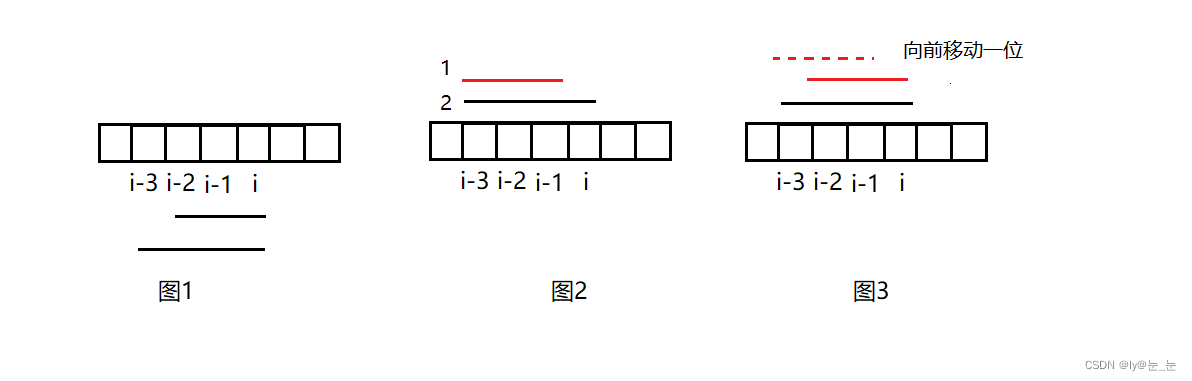
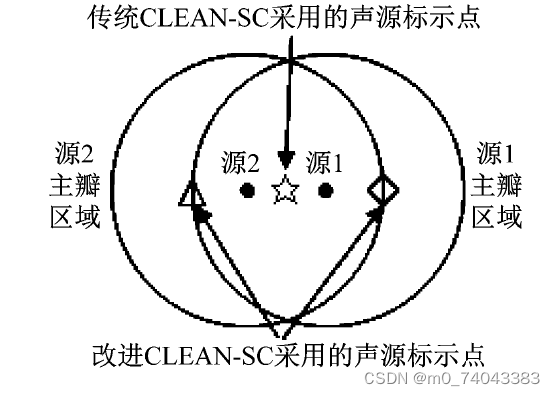
准确重构标示声源在各传声器处产生声压信号的互谱矩阵,进而准确识别声源。基于该事实,通过重新选择声源标示点重新确定标示声源来提高DAS 输出的主瓣严重融合时的声源识别准确度。图3 为声源标示点的选择示意图,“·”表示声源,DAS 在各声源处输出的主瓣落在以各声源为圆心的圆内,符号“☆”为传统CLEAN-SC 采用的声源标示点( 峰值点) ,符号“◇”和“△”为改进CLEAN-SC 分别为源1 和2 重新选择的标示点,源1 的标示点( ◇) 落在源1 的主瓣内、源2 的主瓣边界上,源1 在该位置的贡献显著大于源2,源2 的标示点( △) 落在源2 的主瓣内、源1 的主瓣边界上,源2 在该位置的贡献显著大于源1。
改进CLEAN-SC(HR-CLEAN-SC) 的具体流程如下。首先,根据传统 CLEAN-SC 重构的声源强度分布
Q
\bm{Q}
Q确定声源总数
I
I
I、初始化声源位置
r
0
i
(
0
)
r_{0i}^{(0)}
r0i(0)和声源强度
Q
(
0
)
(
r
0
i
(
0
)
)
\bm{Q}^{(0)}(r_{0i}^{(0)})
Q(0)(r0i(0)),其中,
i
=
1
,
2
,
⋯
,
I
i=1,2,\cdots,I
i=1,2,⋯,I为声源索引,
Q
(
0
)
(
r
01
(
0
)
)
>
Q
(
0
)
(
r
02
(
0
)
)
>
⋯
>
Q
(
0
)
(
r
0
I
(
0
)
)
\bm{Q}^{(0)}(r_{01}^{(0)}) > \bm{Q}^{(0)}(r_{02}^{(0)}) >\cdots>\bm{Q}^{(0)}(r_{0I}^{(0)})
Q(0)(r01(0))>Q(0)(r02(0))>⋯>Q(0)(r0I(0))。然后,迭代寻找正确的声源位置和声源强度,每次迭代包含声源标示点确定、声源位置及强度确定、源排序三步,由第
n
n
n次迭代到第n + 1 次迭代的步骤为:
步骤1 依次确定每个声源的标示点:
r
m
a
i
(
n
+
1
)
=
r
m
a
(
n
+
1
)
(
r
0
i
(
n
)
)
=
a
r
g
r
min
F
(
r
0
i
(
n
)
,
r
)
\bm{r}_{mai}^{(n+1)}=\bm{r}_{ma}^{(n+1)}(\bm{r}_{0i}^{(n)}) = arg_{r} \min F(\bm{r}_{0i}^{(n)},\bm{r})
rmai(n+1)=rma(n+1)(r0i(n))=argrminF(r0i(n),r)
式中
r
m
a
i
(
n
+
1
)
=
r
m
a
(
n
+
1
)
(
r
0
i
(
n
)
)
\bm{r}_{mai}^{(n+1)}=\bm{r}_{ma}^{(n+1)}(\bm{r}_{0i}^{(n)})
rmai(n+1)=rma(n+1)(r0i(n))为第
n
n
n次迭代确定的第
i
i
i 号声源的标示点,
F
(
r
0
i
(
n
)
,
r
)
F(\bm{r}_{0i}^{(n)},\bm{r})
F(r0i(n),r)为成本函数,表达式为:
F
(
r
0
i
(
n
)
,
r
)
=
{
∣
∣
∑
k
=
1
,
k
≠
i
l
v
H
(
r
0
k
(
n
)
)
μ
(
r
)
v
(
r
0
k
(
n
)
)
∣
∣
2
2
∣
v
H
(
r
0
i
(
n
)
)
μ
(
r
)
∣
2
∣
∣
v
(
r
0
i
(
n
)
)
∣
∣
2
2
,
∣
v
H
(
r
0
i
(
n
)
)
μ
(
r
)
∣
2
≥
0.25
+
∞
,
∣
v
H
(
r
0
i
(
n
)
)
μ
(
r
)
∣
2
<
0.25
(9)
F(\bm{r}_{0i}^{(n)},\bm{r}) = \left\{ \begin{aligned} \frac{||\sum_{k=1,k\neq i}^l \bm{v}^H(\bm{r}_{0k}^{(n)})\bm{\mu}(\bm{r})\bm{v}(\bm{r}_{0k}^{(n)})||_2^2}{|\bm{v}^H(\bm{r}_{0i}^{(n)})\bm{\mu}(\bm{r})|^2||\bm{v}(\bm{r}_{0i}^{(n)})||_2^2} ,& &|\bm{v}^H(\bm{r}_{0i}^{(n)})\bm{\mu}(\bm{r})|^2 \geq 0.25 \\ +\infty, && |\bm{v}^H(\bm{r}_{0i}^{(n)})\bm{\mu}(\bm{r})|^2< 0.25 \end{aligned} \right. \tag{9}
F(r0i(n),r)=⎩
⎨
⎧∣vH(r0i(n))μ(r)∣2∣∣v(r0i(n))∣∣22∣∣∑k=1,k=ilvH(r0k(n))μ(r)v(r0k(n))∣∣22,+∞,∣vH(r0i(n))μ(r)∣2≥0.25∣vH(r0i(n))μ(r)∣2<0.25(9)
式中
k
k
k 为声源索引,
∣
v
H
(
r
0
i
(
n
)
)
μ
(
r
)
∣
2
<
0.25
|\bm{v}^H(\bm{r}_{0i}^{(n)})\bm{\mu}(\bm{r})|^2< 0.25
∣vH(r0i(n))μ(r)∣2<0.25 时,
F
(
r
0
i
(
n
)
,
r
)
=
+
∞
F(\bm{r}_{0i}^{(n)},\bm{r}) = +\infty
F(r0i(n),r)=+∞ 是为了保证DAS 在确定的声源标示点位置的输出比DAS 在声源位置的输出小不超过6dB,即确定的声源标示点落在主瓣内,
∣
v
H
(
r
0
i
(
n
)
)
μ
(
r
)
∣
2
≥
0.25
|\bm{v}^H(\bm{r}_{0i}^{(n)})\bm{\mu}(\bm{r})|^2 \geq 0.25
∣vH(r0i(n))μ(r)∣2≥0.25 时,
F
(
r
0
i
(
n
)
,
r
)
F(\bm{r}_{0i}^{(n)},\bm{r})
F(r0i(n),r)的表达式可理解为
I
I
I 个单位强度声源中,除i 号声源外的其它声源在
r
\bm{r}
r聚焦点处的波束形成贡献与
i
i
i号声源在
r
\bm{r}
r聚焦点处的波束形成贡献的比值。
步骤2 基于确定的声源标示点,确定新的声源位置和声源强度。采用与传统CLEAN-SC 类同的相干性分析得声源标示点
r
m
a
i
(
n
+
1
)
\bm{r}_{mai}^{(n+1)}
rmai(n+1)所标示的声源在各传声器处产生声压信号的互谱矩阵为:
G
i
(
n
+
1
)
=
λ
(
r
m
a
i
(
n
+
1
)
)
s
(
r
m
a
i
(
n
+
1
)
)
s
H
(
r
m
a
i
(
n
+
1
)
)
(10)
\bm{G}_i^{(n+1)} = \lambda(\bm{r}_{mai}^{(n+1)})\bm{s}(\bm{r}_{mai}^{(n+1)})\bm{s}^H(\bm{r}_{mai}^{(n+1)})\tag{10}
Gi(n+1)=λ(rmai(n+1))s(rmai(n+1))sH(rmai(n+1))(10)
λ
(
r
m
a
i
(
n
+
1
)
)
=
μ
H
(
r
m
a
i
(
n
+
1
)
)
(
C
−
∑
k
=
1
i
−
1
G
k
(
n
+
1
)
)
μ
(
r
m
a
i
(
n
+
1
)
)
(11)
\lambda(\bm{r}_{mai}^{(n+1)})=\bm{\mu}^H(\bm{r}_{mai}^{(n+1)})(\bm{C}-\sum_{k=1}^{i-1}\bm{G}_k^{(n+1)})\bm{\mu}(\bm{r}_{mai}^{(n+1)})\tag{11}
λ(rmai(n+1))=μH(rmai(n+1))(C−k=1∑i−1Gk(n+1))μ(rmai(n+1))(11)
s
(
r
m
a
i
(
n
+
1
)
)
=
(
C
−
∑
k
=
1
i
−
1
G
k
(
n
+
1
)
)
μ
(
r
m
a
i
(
n
+
1
)
)
λ
(
r
m
a
i
(
n
+
1
)
)
(12)
\bm{s}(\bm{r}_{mai}^{(n+1)})=\frac{(\bm{C}-\sum_{k=1}^{i-1}\bm{G}_k^{(n+1)})\bm{\mu}(\bm{r}_{mai}^{(n+1)})}{\lambda(\bm{r}_{mai}^{(n+1)})}\tag{12}
s(rmai(n+1))=λ(rmai(n+1))(C−∑k=1i−1Gk(n+1))μ(rmai(n+1))(12)
式中,
λ
(
r
m
a
i
(
n
+
1
)
)
\lambda(\bm{r}_{mai}^{(n+1)})
λ(rmai(n+1)) 和
s
(
r
m
a
i
(
n
+
1
)
)
\bm{s}(\bm{r}_{mai}^{(n+1)})
s(rmai(n+1))分别为标示声源的成分系数和成分向量。计算 DAS 输出
b
i
(
n
+
1
)
(
r
)
=
μ
H
(
r
)
×
G
i
(
n
+
1
)
μ
(
r
)
b_i^{(n+1)}(\bm{r})=\bm{\mu}^H(\bm{r})\times \bm{G}_i^{(n+1)}\bm{\mu}(\bm{r})
bi(n+1)(r)=μH(r)×Gi(n+1)μ(r),搜索主瓣峰值所在位置得新的声源位置
r
0
i
(
n
+
1
)
\bm{r}_{0i}^{(n+1)}
r0i(n+1),,主瓣峰值为相应声源强度
Q
(
n
+
1
)
(
r
0
i
(
n
+
1
)
)
\bm{Q}^{(n+1)}(\bm{r}_{0i}^{(n+1)})
Q(n+1)(r0i(n+1)).对
i
=
1
,
2
,
⋯
,
I
i=1,2,\cdots, I
i=1,2,⋯,I,依次进行上述分析。
步骤3 对第2 步获得的
I
I
I个声源按声源强度降序排列,返回第1 步重复循环,直至完成规定的迭代次数
N
2
N_2
N2。最后,获得声源强度分布
Q
\bm{Q}
Q
Q
(
r
)
=
{
Q
(
N
2
)
(
r
0
i
(
N
2
)
)
,
r
=
r
0
i
(
N
2
)
0
,
r
≠
r
0
i
(
N
2
)
(13)
\bm{Q}(\bm{r}) = \left\{ \begin{aligned} \bm{Q}^{(N_2)} (\bm{r}_{0i}^{(N_2)}), && \bm{r}=\bm{r}_{0i}^{(N_2)}\\ 0, && \bm{r}\neq\bm{r}_{0i}^{(N_2)} \end{aligned} \right.\tag{13}
Q(r)=⎩
⎨
⎧Q(N2)(r0i(N2)),0,r=r0i(N2)r=r0i(N2)(13)
CLEAN-SC-CG
为了减少CLEAN - SC 的计算时间及提升CLEAN-SC 的空间分辨率,提出了CLEAN-SC-CG算法。CLEAN-SC-CG 算法利用 FB 算法对声源进行初始定位,将获得初始定位结果作为CLEAN-SC 的初始值,然后通过设置阈值对初始值进行筛选,大于阈值的初始值及其相对应的网格信息被保留下来,其他初始值则不参与迭代运算,并另赋它值。
FB 算法是在CBF 算法的基础上将CSM 进行特征值分解
C
=
U
Σ
U
∗
(14)
\bm{C} = \bm{U}\Sigma \bm{U}^*\tag{14}
C=UΣU∗(14)
式中,
U
\bm{U}
U为酉矩阵,
U
=
(
u
1
,
⋯
,
u
N
)
\bm{U}=(u_1,\cdots,u_N)
U=(u1,⋯,uN),
u
1
,
⋯
,
u
N
u_1,\cdots,u_N
u1,⋯,uN为
C
\bm{C}
C的特征向量;
Σ
\Sigma
Σ为对角矩阵,
Σ
=
d
i
a
g
(
α
1
,
⋯
,
α
N
)
\Sigma = diag(\alpha_1,\cdots,\alpha_N)
Σ=diag(α1,⋯,αN),其中,
α
1
,
⋯
,
α
N
\alpha_1,\cdots,\alpha_N
α1,⋯,αN为
C
\bm{C}
C的特征值。
FB算法的计算表达式
A
v
(
ξ
)
=
[
w
∗
C
1
v
w
]
v
=
[
w
∗
U
Σ
1
v
U
∗
w
]
v
(15)
A_v(\xi) = [\bm{w}^*\bm{C}^{\frac{1}{v}}\bm{w}]^v = [\bm{w}^*\bm{U} \Sigma^{\frac{1}{v}} \bm{U}^*\bm{w}]^v\tag{15}
Av(ξ)=[w∗Cv1w]v=[w∗UΣv1U∗w]v(15)
式中,
ν
ν
ν 为一个需要根据具体数据集确定的指数。与CBF 相比,FB 算法通过指数
ν
ν
ν 衰减与旁瓣相关的PSF值,达到抑制旁瓣、提升空间分辨率的目的,本文指数
ν
ν
ν取值为16。
在CLEAN-SC-CG 中,仅保留满足下式的聚焦网格点
A
v
(
ξ
)
>
β
v
(16)
A_v(\xi)>\beta_v\tag{16}
Av(ξ)>βv(16)
式中,
β
v
\beta_v
βv为阈值。阈值并非一个确定值,本文依据两个原则确定阈值的取值范围。原则一为背景噪声,一般低于背景噪声的声源不被关注,试验环境中背景噪声的声压级可以作为阈值的最小值; 原则二为声压级低于峰值 20 dB 的噪声,低于峰值20 dB 的噪声源对声场中目标声源的识别影响较小,所以,此噪声源的声压级可以作为阈值的最大值。阈值影响CLEAN-SC-CG压缩聚焦网格点的数量以及声像图中旁瓣的干扰程度,可根据试验环境和试验目的确定阈值的取值。
步骤1:由式 (15) 计算函数波束形成输出
A
v
(
ξ
)
A_v(\xi)
Av(ξ)
步骤2:根据式
A
v
(
ξ
)
>
β
v
A_v(\xi)>\beta_v
Av(ξ)>βv,压缩聚焦网格点;
步骤3:保留符合筛选条件的
A
~
v
(
ξ
)
\widetilde{A}_v(\xi)
A
v(ξ)及相应的网格点位置信息
A
~
v
(
ξ
)
=
A
(
0
)
\widetilde{A}_v(\xi) = A^{(0)}
A
v(ξ)=A(0),否则
A
v
(
ξ
)
=
α
,
(
α
<
<
β
v
)
A_v(\xi)=\alpha,(\alpha << \beta_v)
Av(ξ)=α,(α<<βv)。
步骤4: 对满足条件的网格点信息进行反卷积( CLEAN-SC) 计算,得出“干净”声像图。
MATLAB 仿真
matlab代码实现见CLEAN-SC
CLEAN_SC.m: 完成CLEAN-SC算法,并画出CLEAN-SC仿真定位图,并输出完成主体算法的运行时间
CLEAN_SC_CG.m:完成CLEAN-SC-CG算法,且画出CLEAN-SC-CG仿真定位图,以及加入CG算法之后的压缩比,和输出完成主体算法的运行时间
HR_CLEAN_SC.m : 完成HR-CLEAN-SC算法,且画出CLEAN-SC 和HR-CLEAN-SC的仿真定位图对比,HR_CLEAN_SC三维图,并输出完成主体算法的运行时间
HR_CLEAN_SC_CG.m:完成HR-CLEAN-SC-CG算法,且画出CLEAN-SC-CG 和HR-CLEAN-SC-CG的仿真定位图对比,HR_CLEAN_SC_CG。以及加入CG之后的压缩比和运行时间
CLEAN_SC_1.m :完成CLEAN-SC算法,并参照王月论文的输出声源强度分布图。
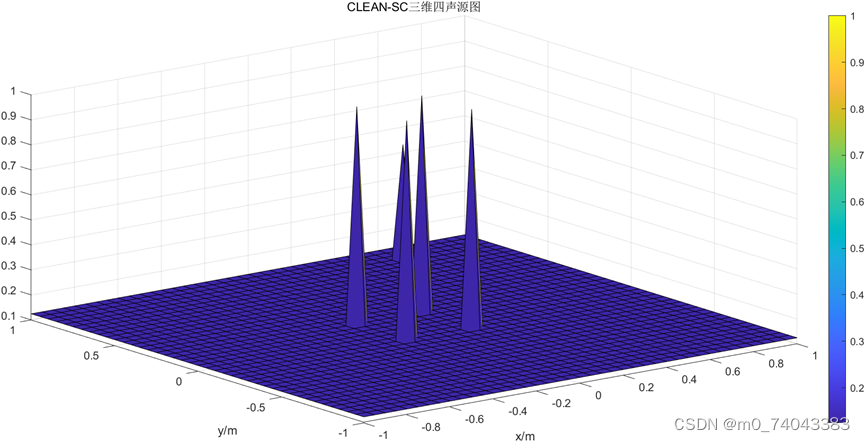
CLEAN_SC_CG_1.m:完成 CLEAN-SC-CG,完成CLEAN-SC-CG算法,输出CBF三维四声源强度分布图、BF三维四声源强度分布图、CLEAN-SC-CG三维四声源强度分布图。
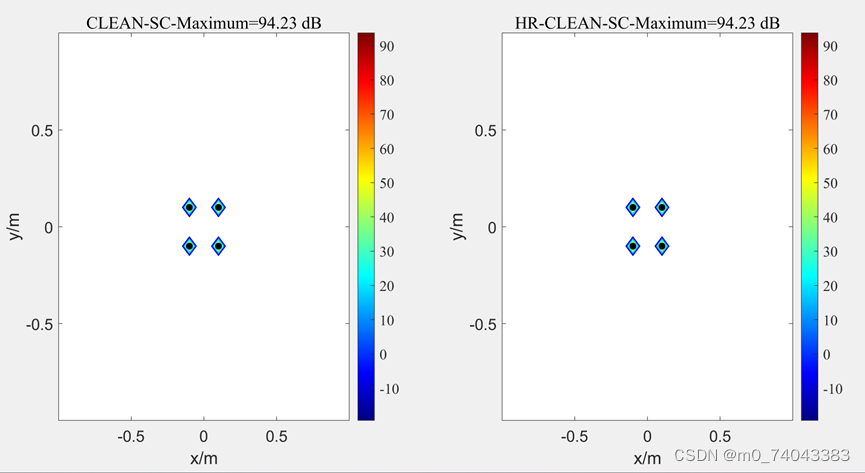
HR-CLEAN-SC 定位准确性提升比较
① f = 1000 时
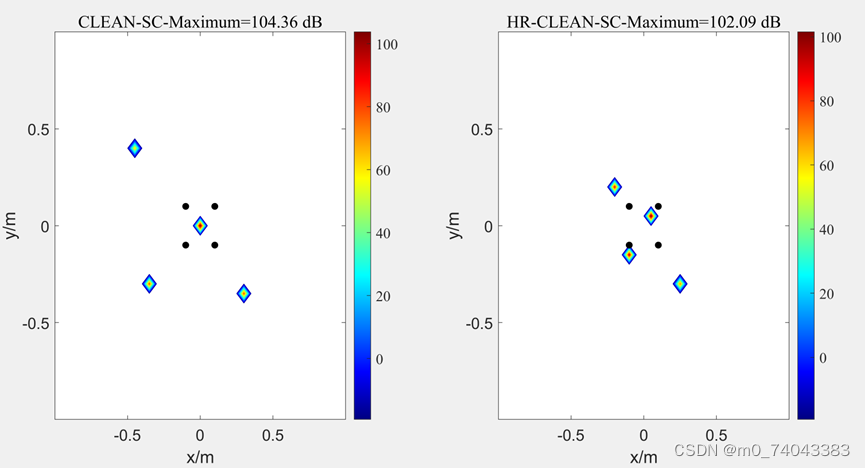
② f = 2000
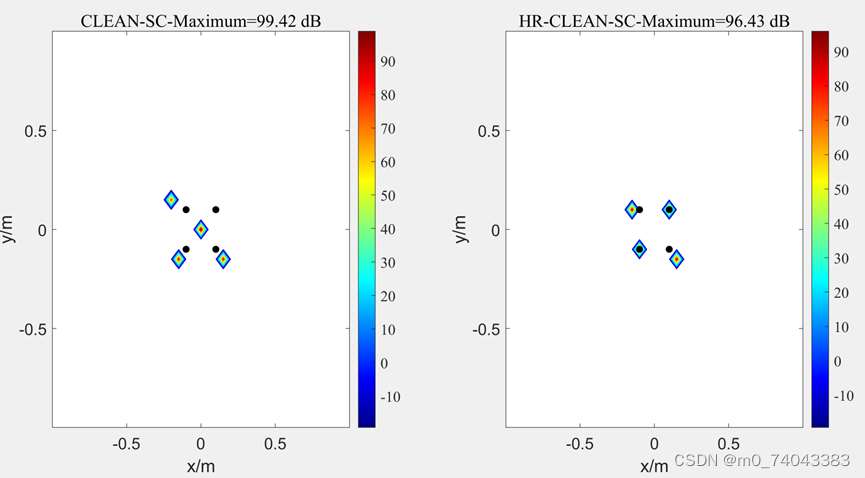 ③ f = 3000
③ f = 3000
CG算法的压缩率
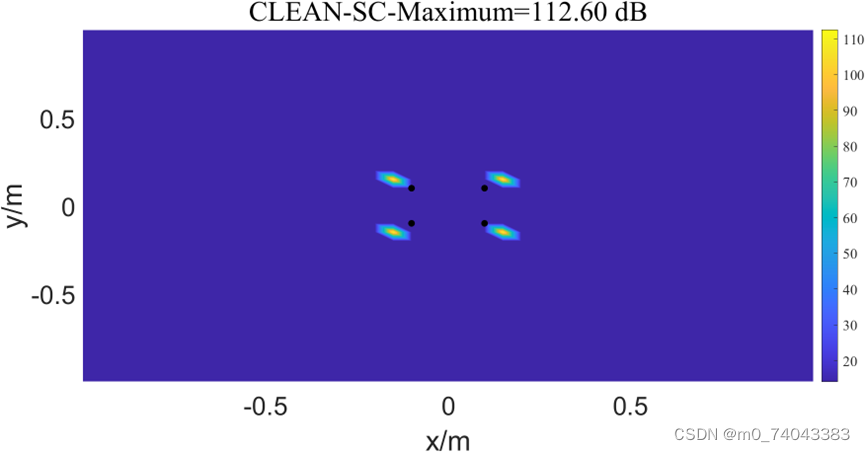
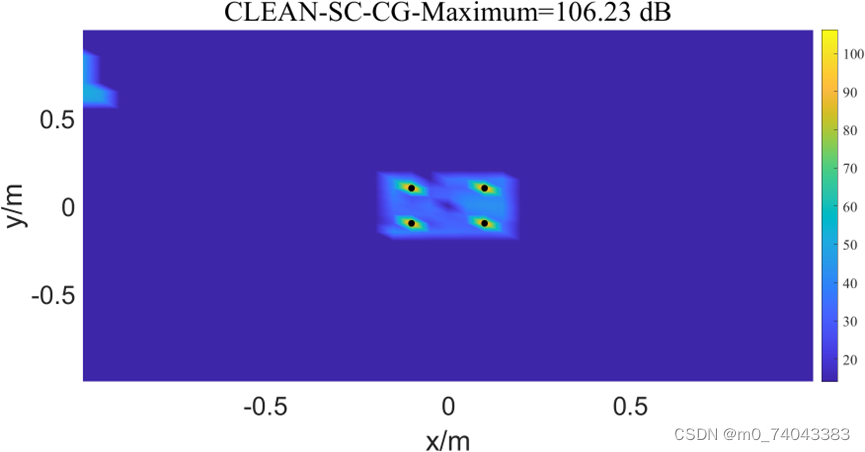
四声源的PSF图
① CBF 三维图
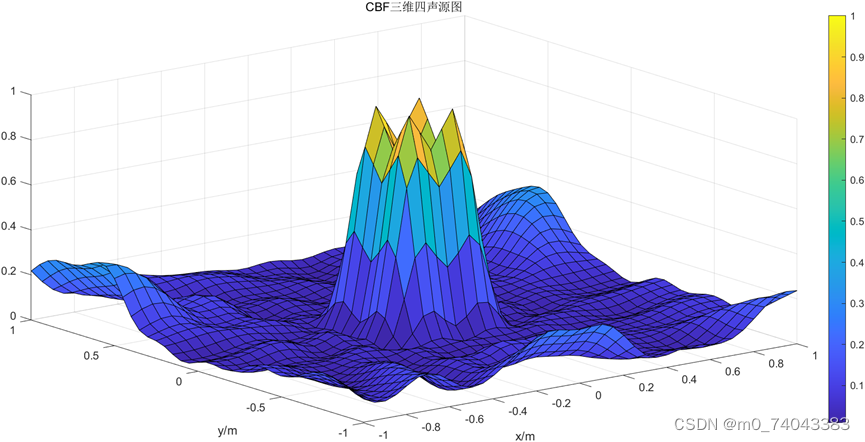
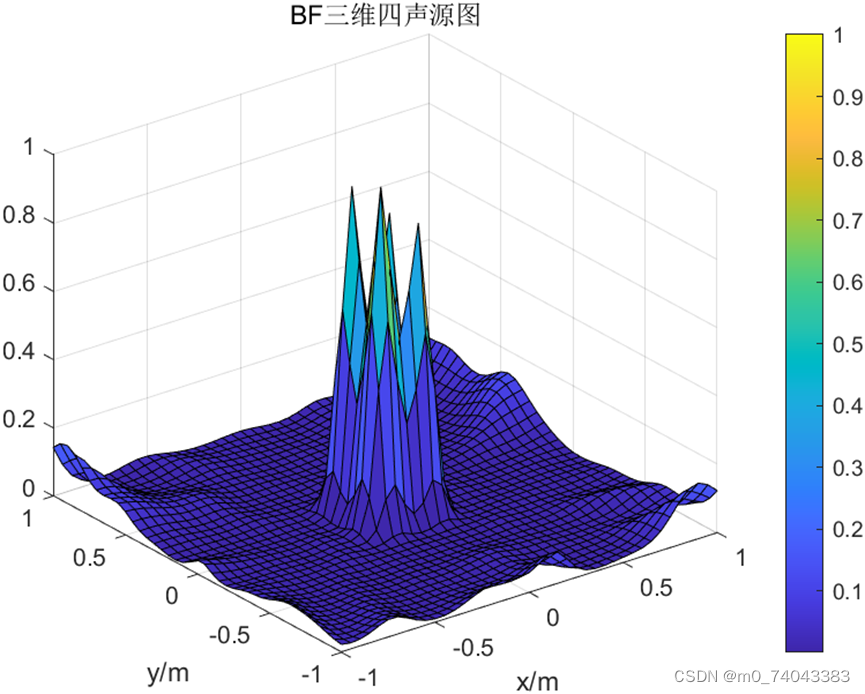
② BF 三维图
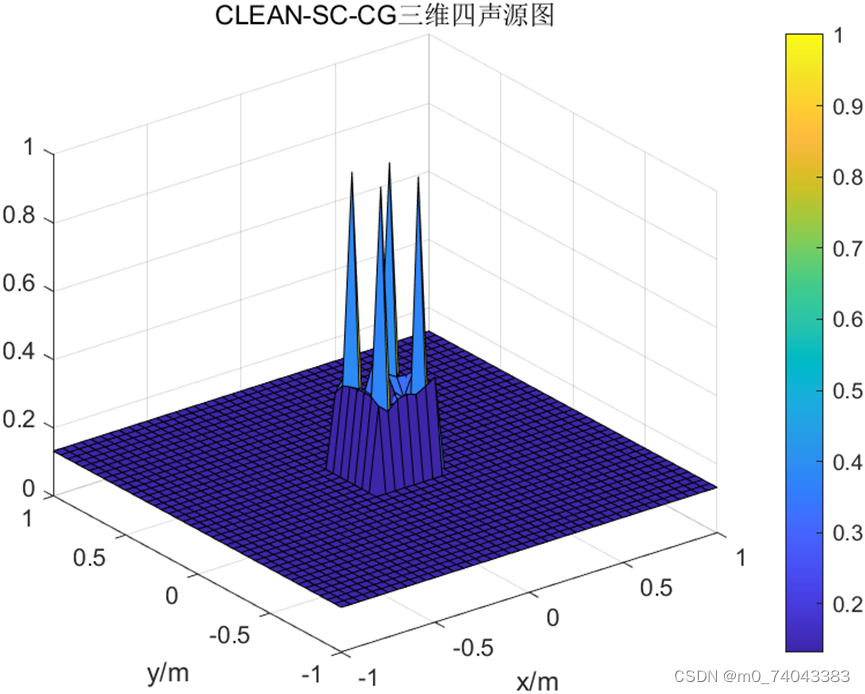
③ CLEAN-SC-CG 三维图
④ CLEAN-SC三维图