近年来,凭借高可扩展、高可用等技术特性,分布式数据库正在成为金融行业数字化转型的重要支撑。分布式数据库如何在不同的金融级应用场景下,在确保数据一致性的前提下,同时保障系统的高性能和高可扩展性,是分布式数据库的一个核心技术挑战。
针对以上分布式一致性的困境,中国人民大学-腾讯协同创新实验室研究提出“多级一致性”的事务处理理念。该技术包含严格可串行化、顺序可串行化、可串行化三大隔离级别,可针对不同应用场景要求,极大地平衡性能与一致性要求,满足金融及各类企业场景的分布式事务处理需求。该项技术已应用于腾讯分布式数据库TDSQL产品中,确保TDSQL按需提供数据一致性,并确保数据无异常。TDSQL是当前国内率先进入国有大型银行核心系统正式投产的国产分布式数据库,该项技术是其中的关键支撑。
这次,中国人民大学教授、博士生导师卢卫老师为大家全面解锁分布式数据库的多级一致性及构建技术!
背景
从本质上看,数据库是长期存储在计算机内、有组织的、可共享的数据集合。当多个用户并发操作数据库时,事务调度的可串行化是并发控制的正确性理论。但该观点在当前却受到了挑战。Daniel J. Abadi 在2019年发布的一篇博客中提到,以往学界普遍认为可串行化是数据库隔离级别的黄金标准,但经过研究,他发现实际上严格可串行化才是黄金标准。即在该理论中,可串行化仍存在一定的问题,只有严格可串行化才能做到没有问题。

在过去,为什么可串行化不存在问题?原因有两方面:
一是对集中式数据库而言,可串行化其实就是严格可串行化,两者之间并没有区别。 二是对于分布数据库而言,如果数据库里有唯一的事务调度器或协调器,这两者之间也可等价。

当来到去中心化的分布式数据库时代,我们希望分布式数据库产品可在全球部署。全球部署意味着范围更大,如果仍然依赖集中式调度,性能和可扩展性都无法满足应用的需求,因此需要在系统当中安排多个事务协调者进行协调。

回顾发展历程,20年前的数据库的标注配置为业务系统+主库+备库。业务系统访问主库,主库通过同步协议使数据在主库和备库之间保持一致性。在这一阶段,集中式的IBM小型机、Oracle数据库、EMC存储(IOE)在处理小规模的数据场景时较为合适。但这种架构模式的问题在于,当数据量比较大或者业务场景比较密集时,集中式主库就会成为整个系统的负担。

到了第二阶段,典型的做法是分库分表,将业务按照主库进行拆分,因为业务系统建立在主库之上,因此实现了业务的隔离,TDSQL的早期版本也采用了这种做法。这种做法的前提假设是数据/业务能够很好地进行切分,从而解决前一阶段业务不可扩展的问题。但当业务系统进行跨库访问时,就会带来新的问题。

为了解决上述问题,我们来到了第三阶段,即去中心化的分布式数据库阶段。在该阶段,数据库中设置了更多的事务调度器,由调度器来对每个节点数据上的子事务进行事务提交,每个事务调度器都可以独立地去处理事务。但这也会产生新的问题,即不同协调者之间如何协调。
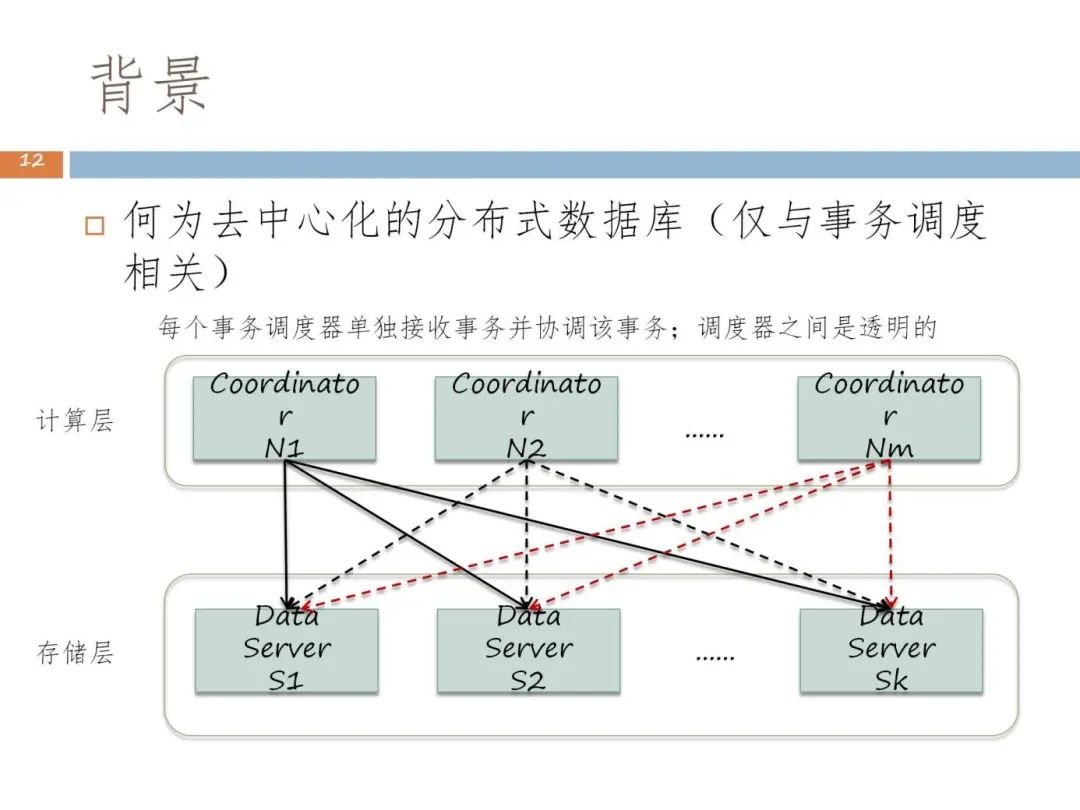
问题与挑战
我们以下图中的例子来说明分布式数据库中不同协调者之间如何协调的问题。假设有一个家庭账户,丈夫和妻子共用,都可以进行读和写。丈夫在 ATM机上存了 100 块,存完后通知妻子,但妻子有可能看不到丈夫存的这笔钱。因为这是一个多协调器的架构,设备1交由协调者1来进行协调,妻子发起的这个事务可能由另外一个协调者去发起,这就会出现协调者之间AMG时钟不统一的问题。
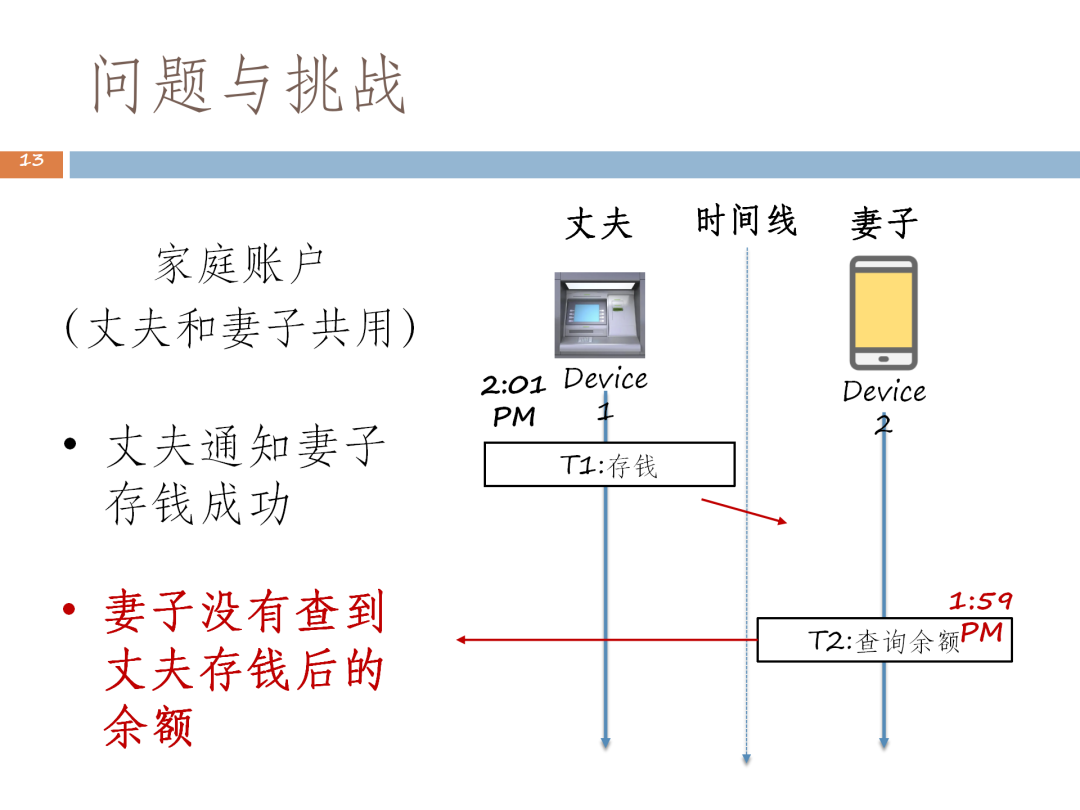
该事务发起的时间虽然在 2:01 PM后,但因为协调的时间偏慢,所以此时1:59 PM的这个时钟去读 2:01 PM的时间戳提交的这个数据,就会出现读不到的情况。

形象地说,即有两个协调器,其中一个协调器执行了事务 T0 、T1,T1 事务已经提交成功。这时协调者 2 发起了事务T2,当T2 查询余额时,我们发现时钟比 T1 提交的时钟来得小,所以读不到T1。但实际上,是先执行 T0 再执行 T2 再执行T1,属于可串行化。但这又会跟前述提到的执行相违背,因为既然T1已经提交, T2理应可以读到,但结果没有读到。因此Daniel J. Abadi 的可串行化存在一定的问题,读不到最新数据。

这个问题的本质是保序,而严格可串化的本质是线性一致性加上可串行化。从事务角度来看,根据线性一致性要求,如果T0事务已经结束,T1才开始,则T1要读到T0的写;同理,T1已经完成了T2才开始,T2要读到T1的写。虽然这里的 T0、T2、T1 是可串行化,但违背线性一致性的要求,只有T0→ T1→ T2时才是正确的,这就是保序。
因此,这里的实时序就是T0 结束后开始T1事务,T0 排在T1的前面;T0 完成后T2才开始,T0 排在T2的前面;T1结束后T2才开始,T1排在T2的前面。因此核心理念就是保序,即在原来可串行化全序的基础上,对可串行化的序做约束,这个约束是线性一致性所造成的。

严格串行化虽然能保证数据的准确性,但也带来了较多的问题。以Google Spanner为例,Google Spanner支持严格可串行化,但是严格可串行化要求有一个原子钟,或者有一个中心授时器(本质上是因为协调器和协调器之间缺少一个协调),因而导致性能较低,难以被广泛应用于实际业务场景中。

多级可串行化建模
基于上述情况,我们希望可以找到一个中间环节,在一致性上比可串行化级别高、比严格串行化级别低;在性能上接近可串行化、优于严格可串行化。针对这个需求,我们提出了多级可串行化建模,本质是在可串行化的基础上加了序。
线性一致性是并发系统中一致性最强的,比它弱一点的有顺序一致性、因果一致性、写读一致性、最终一致性等。我们尝试将可串行化与它们进行结合,最终发现只有可串行化和线性一致性以及可串行化和顺序一致性可以实现结合。因为可串行化要求全序,但因果一致性不要求全序,因此无法结合。

我们的做法是将可串行化+线性一致性,从而得到严格可串行化;可串行化+顺序一致性,从而得到顺序可串行化。所以我们提出了严格可串行化、顺序可串行化、可串行化这三个隔离级别。

多级可串行化实现的核心理念就是保序。我们定义了五个序:
- 实时序,即原来的线性一致性要求。
- 程序序,比如代码中的session order,session 连接后,事务之间就变成了T0,T0 提交后才能提交T1,这就是程序序。
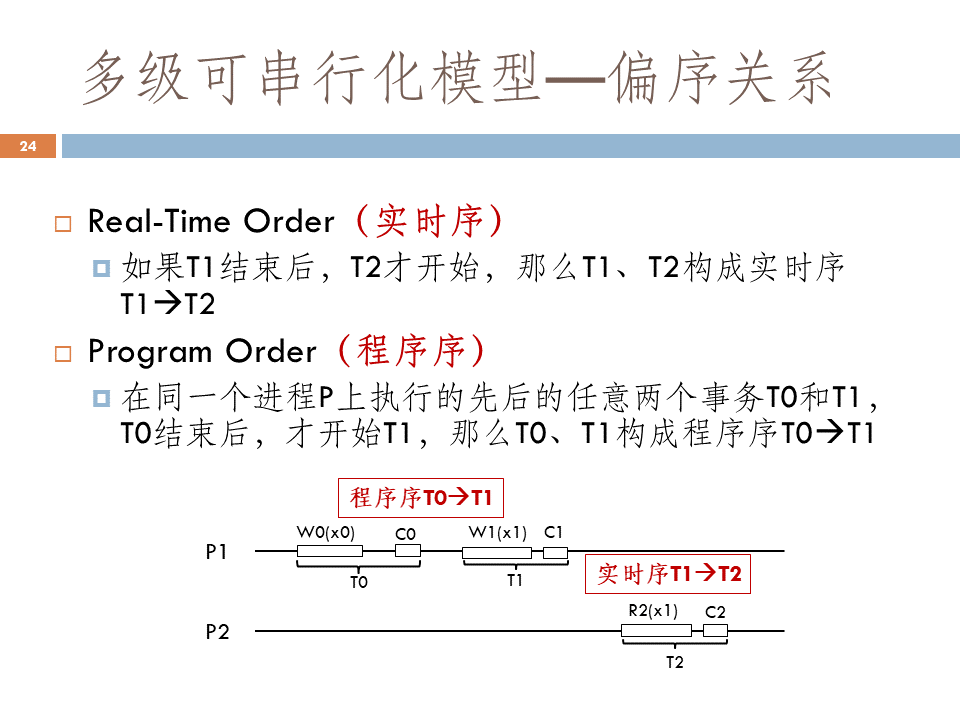
- 写读序,即如果T2读取了T1的写,T1必定排在T2 之前。
- 因果序,指写读序和程序序之间形成的闭包。
- 写合法,假设有一个x数据项,T1写了数据项x1,T3 写了数据项x2,但如果T2 读了一个x ,就必须要求T2 要紧跟T1,因为它不能紧跟在T3 后;如果它排在T3 后,则它读的应该是 x2 ,因此这时T1和T3形成了一个序,要求T2要排在T3 前。

有了序后,我们重新定义了事务的可串行化理论,即可串行化等于写读序的传递闭包+写合法;可串行化+顺序一致性,即写读序+程序序的传递闭包,再加写合法;严格可串行化就是写读序+实时序的传递闭包,加写合法。因此可以理解为所有的一致性模型就是保序。

该理论成果已经应用于腾讯分布式数据库TDSQL产品当中,使得TDSQL成为全球范围内首个能够具备严格可串行化、顺序可串行化、可串行化三大隔离级别的国产分布式数据库,还可针对不同应用场景要求,极大地平衡性能与一致性要求,满足金融及各类企业场景的分布式事务处理需求。
并发控制算法
并发控制算法-双向动态时间戳调整的实现如下图所示。图中有两个协调者P1和P2,协调者P1有两个事务T1和T3,协调者P2有T2 和T4 。我们先定义顺序,T1和T3之间有一个session order或program order,T2和T4也存在一个program order,我们将它preserve 出来。

其中还存在写读序,像T1和T4之间,T1写了x1,T4读了x1,此时就存在一个写读序,所以要把T1和T4的order preserve出来。同时还存在写合法,因为T3 读了y 数据项,然后 T2 写了y数据项, 但是基于可串行化理论,R3读取的是y0,没有读取到y2,如果读到y2,这时T3就必须排在T2后。因为此时读不到y2 ,要排在T2前面,因此T3和 T2之间存在写合法。在整个执行过程中,我们要保证必须存在保序。
主要思想是每次事务提交时,都需要判断能否违背事务的先后顺序。比如T1开始提交,因为T1只包含自身,我们将它放到队列中时不需要回滚。T2 提交时,T2和T1之间没有序,但T1和T3之间以及T2和T3之间都分别存在一个序,因为此时存在y数据项,所以只有T1、T3、T2 这样的序才能保证可串行化,否则T必须进行回滚。
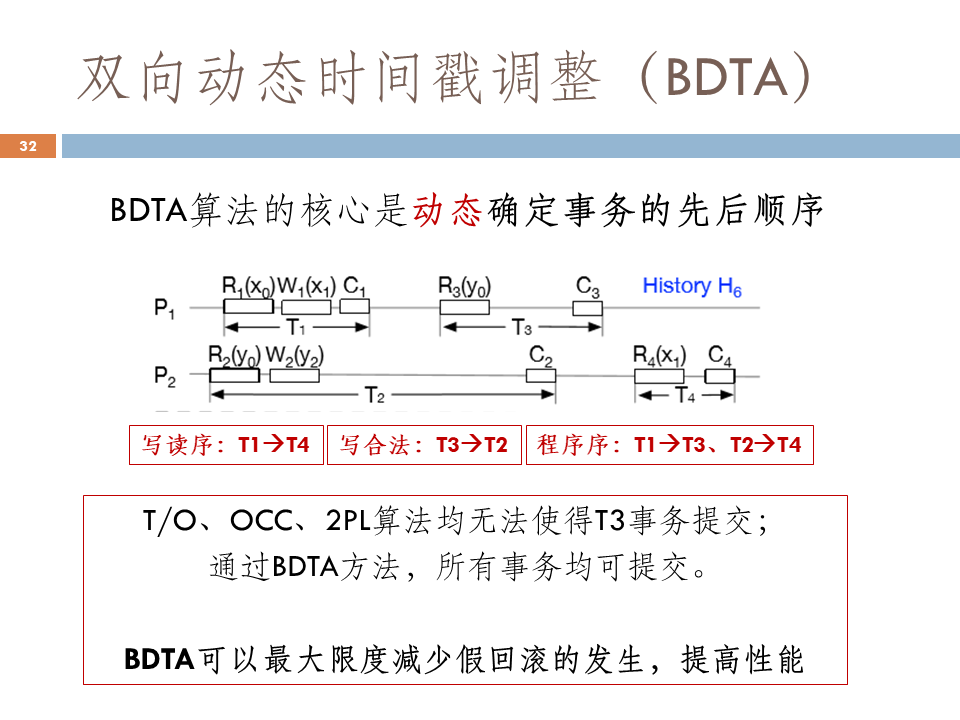
最后为保证协调器间能进行协调,我们还需要引入混合逻辑时钟,来保证因果序。

实验评价
我们以下图中的实验为例,来说明可串行化、严格可串行化和顺序可串行化之间的关系。如果在局域网情况下,在正确性方面,严格可串行化跟可串行化性能基本一致。但在广域网情况下,严格可串行化、顺序可串行化和可串行化之间的性能差异较大,所以导致在广域网上很难实现严格可串行化。

如图所示,BDTA算法比现有的算法如MAT、SUNDIAL等快了将近 1.8 倍,主要原因是BDTA中保序,但如果用前面的方法实现并发控制,就会造成大量事务的回滚。

总结与讨论
本文提出了提出了面向分布式数据库的多级可串行化模型,将并发系统中的一致性要求结合到可串行化中,实现了多级可串行化原型系统,保证了去中心化的事务处理机制,并设计了双向动态时间戳调整算法(BDTA),可以在统一系统架构下支持多个可串行化级别。
该技术已应用于腾讯云数据库TDSQL中,确保TDSQL无任何数据异常,且具备高性能的可扩展性,解决了分布式数据库在金融级场景应用的最核心技术挑战,使得国产分布式数据库实现在金融核心系统场景的可用。基于此,TDSQL是当前国内唯一进入国有大型银行核心系统正式投产的国产分布式数据库。
本文由博客一文多发平台 OpenWrite 发布!








![[附源码]java毕业设计家庭医生系统](https://img-blog.csdnimg.cn/a5f9675c122a487ea2da5d76dfd01348.png)