介绍
Datax是一个异构数据源离线同步工具,致力于实现包括关系数据库、HDFS、Hive、ODPS、Hbase等各种异构数据源之间稳定高效的数据同步功能
- 设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步;
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已 持续稳定运行了7年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB;
框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中,软件核心功能写入Framework 主体框架中。

主体框架为插件预留接口,如果后期需要什么新功能,可以再去开发插件实现,而主体框架无需改动。
3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业 生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系
DataX作业生命周期的时序图
模块关系
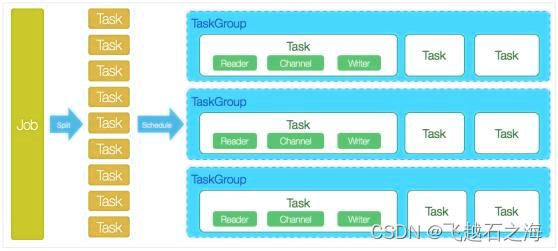
DataX完成单个数据同步的作业,我们称之为Job,DataX接收到一个Job之后,将启 动一个进程来完成整个作业同步过程;
DataX Job模块是单个作业的中枢管理节点, 承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理 等功能;
DataX Job启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行;
Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作;
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组);
每一个TaskGroup负责并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5(可配置) ;
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader— >Channel — >Writer的线程来完成任务同步工作
datax作业运行起来之后,job监控并等待多个taskgroup模块任务完成,完成之后job成功退出;否则,异常退出,进程退出值非0。
调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个 100张分表的mysql数据同步到odps里面;
调度决策思路:
1)DataXJob根据分库分表切分成了100个Task;
2)根据20个并发,DataX计算共需要分配4个TaskGroup;
3)4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运 行25个Task;
4)计算
100个Task,20个并发就是20个Channel;4(20 / 5 = 4) 个Taskgroup,每个Taskgroup内的25(100 / 4 = 25)个Task,能够同时运行的任务是20个Channel等于20个并发。
环境需求与安装
1)环境需求
Linux
JDK(1.8以上,推荐1.8)
Python(2或3都可以)
2)安装工具
下载后解压至本地某个目录,进入bin目录,即可运行同步作业
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本
$ python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
如果报错
运行以下指令,再输入自检脚本指令
rm -rf {YOUR_DATAX_HOME}/plugin//._
具体就不详细介绍了。
入门案例
- Stream -> Stream
目的:打印输出10行 hello,世界
步骤:
1)打开Datax工具目录
cd {YOUR_DATAX_HOME}
2)获取模板文件
python bin/datax.py -r streamreader -w streamwriter
3)修改
vim job/stream2Stream.json
参数
column表示列
type表示该列的类型
value表示该列的值
column里面可以写多个列
sliceRecordCount:表示要打印多少次
encodding设置字符编码格式
print表示是否打印到控制台
setting
speed表示控制并发数
channel设置并发的数量
如果设置的print为true,则会打印slicRecordCount*channel次
如果是从mysql导入hdfs等其他操作,则会是真正代表并发数,而不是打印多少次
内容
{"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{type:"long",value:"1024"},{
type:"string",value:"hello,世界"}],
"sliceRecordCount": "10"}},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8",
"print": true
}}}],
"setting":
{"speed": {"channel": "2"}}}}
4)运行
python bin/datax.py job/stream2Stream.json
- MySQL -> MySQL
目的:MySQL数据库的t_emp表数据导入到另一个MySQL数据库的表中
步骤:获得模板文件
python bin/datax.py -r mysqlreader -w mysqlwriter
修改如下
vim job/mysql2Mysql.json
内容
{"job": {
"content": [{
"reader": {
"name": "mysqlreader","parameter": {
"column": ["*"],"splitPk": "emp_id",
"connection": [{"jdbcUrl": [jdbc:mysql://localhost:3306/demo?
useUnicode=true&characterEncoding=utf8"],"table": ["t_emp"]}]
"username": "root","password": "123456",}},
"writer": {
"name": "mysqlwriter","parameter": {
"column": ["*"],"connection": [{
"jdbcUrl": "jdbc:mysql://localhost:3306/democlone? useUnicode=true&characterEncoding=utf8","table": ["t_emp"]}],
"preSql": ["truncate t_emp"],
"session": ["set session sql_mode='ANSI'"],
"username": "root","password": "123456",
"writeMode": "insert"}}}],
"setting": {"speed": {"channel": "2"}}}}
//mysql端提前将表建好
//参数
//session sql_mode 数据校验模式
运行
python bin/datax.py job/mysql2Mysql.json
- MySQL -> HDFS
目的:MySQL数据库中的t_emp表导入到HDFS中的/datax/mysql2hdfs/
步骤:
获得模板文件
修改如下
内容
{"job": {"content": [{
"reader": {"name": "mysqlreader","parameter": {
"column": [
"emp_id",
"dept_id",
"emp_name",
"emp_gender",
"emp_in_time"],
"connection": [{"jdbcUrl":["jdbc:mysql://localhost:3306/demo"],
"table": ["t_emp"]}],
"password": "123456","username": "root",
"where": ""}},
"writer": {"name": "hdfswriter",
"parameter": {"column": [{
type:"int",name:"emp_id"},{
type:"int",name:"dept_id"},{
type:"string",name:"emp_name"},{
type:"string",name:"emp_gender"},{
type:"date",name:"emp_in_time"}],
"compress":"",
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "mysqlToHdfs",
"fileType": "orc",
"path": "/datax/mysql2hdfs",
"writeMode": "append"}}}],
"setting": {"speed": {"channel": "2"}}}}
运行
python bin/datax.py job/mysql2Hdfs.json
-
MySQL -> Hive
目的:MySQL数据库中的t_emp表导入到Hive数据仓库的orc_emp表
步骤:类似上面的步骤 -
Hive -> MySQL
增量导入
目的:解决全量同步数据量较大时,同步被中断的问题
使用 DataX 进行全量同步和增量同步的唯一区别
增量同步需要使用 where 进 行条件筛选
关键参数
使用where参数或者querySql参数进行增量导入
步骤
修改
vim job/mysql2HiveIncrement.json
内容
{"job": {"content": [{
"reader": {"name": "mysqlreader","parameter": {
"column": [
"emp_id",
"dept_id",
"emp_name",
"emp_gender",
"emp_in_time"],
"connection": [{"jdbcUrl":["jdbc:mysql://localhost:3306/demo"],
"querySql":["select * from t_emp_from_hive
where emp_id > ${id}"]}],
"password": "123456","username": "root"}},
"writer": {"name": "hivewriter","parameter": {
"column": [{
type:"int",name:"emp_id"},{
type:"string",name:"emp_name"},{
type:"string",name:"emp_gender"},{
type:"date",name:"emp_in_time"}],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "mysqlToHiveTEmp",
"fileType": "orc",
"path": "/user/hive/warehouse/demo.db/orc_emp", "writeMode": "append"}}}],
"setting": {"speed": {"channel": "3"}}}}
运行
赋值格式
-p “-DpropertyName=propertyValue -D…”
命令
$ python bin/datax.py job/mysql2HiveIncrement.json -p "-Did=20 -D"
$ python bin/datax.py job/mysql2HiveIncrement.json -p "-DstartId=0 -DendId=3"
Java执行Datax脚本
项目配置
环境
Windows 10+
安装 JDK1.8+、开发工具
安装 Python2.7.5+
下载解压datax.tar.gz
Maven本地仓库配置
解压Datax工具压缩包,提取两个jar文件 -core -common
安装两个依赖到Maven本地库
创建Maven项目
pom.xml文件中添加依赖
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-core</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>datax-common</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.60</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
public class JobMysql2Mysql {
static Logger log = LoggerFactory.getLogger(Stream2Stream.class);
public static void main(String[] args) {
int exitCode = 0;
String dataXPath = "D:/MyProgramFiles/BigData/datax/"; String jobFilePath = dataXPath + "job/mysql2Mysql.json"; System.setProperty("datax.home", dataXPath);
String[] dataXArgs = {
"-job", jobFilePath,
"-mode", "standalone",
"-jobid", "-1"
};
try {
Engine.entry(dataXArgs);
} catch(Throwable throwable) {
exitCode = -1;
log.error("\n\n经DataX智能分析,该任务最可能的错误原因::\n"
+ ExceptionTracker.trace(throwable));
}
System.exit(exitCode);
}
}
MySQL 增量导入
//目的
//迭代的方式将MySQL数据表中数据导入到另一个MySQL数据库表中
//使用Java程序迭代并传递参数的形式,完成MySQL数据库之间的数据同步
public class JobMysql2MysqlIncrement {
static Logger log = LoggerFactory.getLogger(Stream2Stream.class);
public static void main(String[] args) {
int exitCode = 0;
String dataXPath = "D:/MyProgramFiles/BigData/datax/";
String jobFilePath = dataXPath + "job/mysql2MysqlIncrement.json"; System.setProperty("datax.home", dataXPath);
String[] dataXArgs = {
"-job", jobFilePath,
"-mode", "standalone",
"-jobid", "-1"
};
try {
// 数据表中总行数,可以使用JDBC获取
int rowTotal = 5;
// 迭代增量的形式,分批次导入数据
for(int i = 0; i < rowTotal; i = i + 3) {
System.setProperty("offset", String.valueOf(i));
System.setProperty("rows", "3");
Engine.entry(dataXArgs);
System.out.println("------------Job End------------");
}
} catch(Throwable throwable) {
exitCode = -1;
log.error("\n\n经DataX智能分析,该任务最可能的错误原因::\n" + ExceptionTracker.trace(throwable));
}
System.exit(exitCode);
}
}
注意
配置文件中需要写查询语句limit限制导入的数据量,java脚本中的参数才能传入,最后才能正常分批次运行
配置文件
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://192.168.2.102:3306/goods_sources?useUnicode=true&characterEncoding=utf8"],
"querySql":["select * from s_order limit ${offset},${rows}"]
}
],
"username": "root",
"password": "123456"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.2.102:3306/goods_targets?useUnicode=true&characterEncoding=utf8",
"table": ["t_order"]
}
],
"password": "123456",
"session": ["set session sql_mode='ANSI'"],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
补充
DataX和sqoop的比较
对于脏数据的处理
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,提供多种的脏数据处理模式
Job支持用户对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值),当Job传输过程出现的脏数据大于用户指定的数量/百分比,DataX Job报错退出
图中的配置的意思是当脏数据大于10条,或者脏数据比例达到0.05%,任务就会报错
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性
丰富的数据转换功能
DataX作为一个服务于大数据的ETL(Extract-Transform-Load 的缩写,即数据抽取、转换、装载的过程)工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数