- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:Pytorch实战 | 第P4周:猴痘病识别
- 🍖 原作者:K同学啊|接辅导、项目定制
一、前期准备
1.设置GPU
''' 设置GPU '''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))没有GPU则使用CPU

2.导入数据、数据预处理
import os,PIL,random,pathlib
data_dir = r'D:\P4'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
class_names = [path.name for path in data_paths]
print(class_names)
![]()
import pathlib
import torchvision.transforms as transforms
from torchvision import datasets
total_datadir = r'D:\P4'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
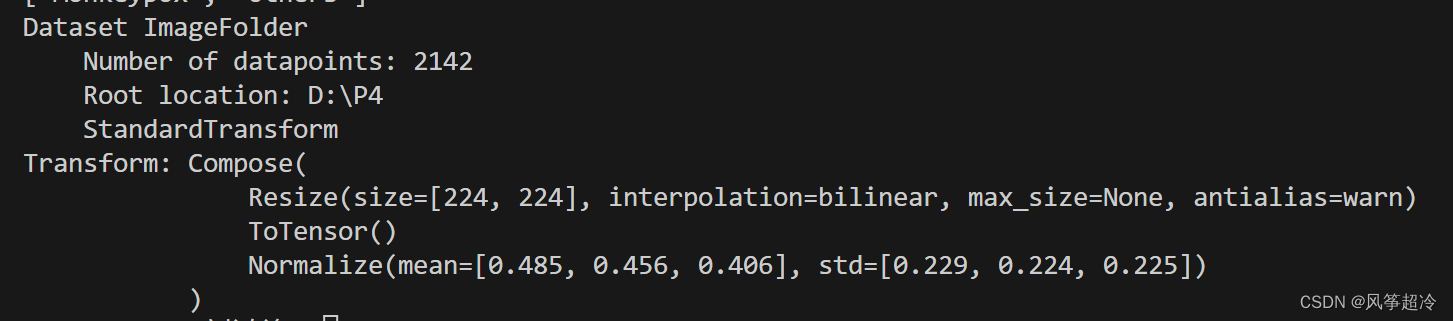
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)定义数据预处理操作 train_transforms:
transforms.Resize([224, 224]):将输入图像的尺寸调整为 224x224 像素,这通常是训练深度学习模型所使用的常见图像尺寸。transforms.ToTensor():将图像数据转换为PyTorch张量,并将像素值归一化到范围 [0, 1]。transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):对图像进行标准化处理,将像素值标准化为标准正态分布(高斯分布),这有助于模型更快地收敛。
使用 datasets.ImageFolder 加载图像数据集:
total_datadir是包含图像数据集的目录路径。transform=train_transforms指定了要应用的数据预处理操作。
3.标签映射
在DatasetFolder中,class_to_idx是一个字典,将类别名映射到类别标签(从0开始),其中类别名是文件夹的名称,类别标签是与之相关联的数字。
为什么要做标签映射呢?
- 将类别名映射到类别标签是因为在训练深度学习模型时,通常使用类别标签来表示每个样本的类别。
- 在训练模型时,输入数据被转换为张量,并且每个张量的标签是一个数字,表示与之相关联的类别。
- 类别标签使得模型可以根据真实标签和预测标签之间的误差来更新模型权重,从而使模型学习到如何将输入数据映射到正确的输出标签。
print(total_data.class_to_idx)![]()
二、划分数据集
import torch
from torch.utils.data import DataLoader
# total_data 包含了数据集,我们可以从 total_data 中划分出训练集和测试集
# 例如,可以按照一定的比例划分数据集,或者根据需要自定义训练集和测试集
# 划分数据集示例:
# 假设数据集总共有100个样本,可以将前80个样本用于训练,后20个用于测试
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32
train_dl = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
test_dl = DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=1)三、 构建 CNN 网络
import torch
import torch.nn as nn
import torch.nn.functional as F
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 53 * 53, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2)
self.dropout = nn.Dropout(0.5) # Adding dropout with a probability of 0.5
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, 16 * 53 * 53)
x = F.relu(self.fc1(x))
x = self.dropout(x) # Applying dropout after the first fully connected layer
x = F.relu(self.fc2(x))
x = self.dropout(x) # Applying dropout after the second fully connected layer
x = self.fc3(x)
x = F.log_softmax(x, dim=1)
return x
model = Network()
print(model)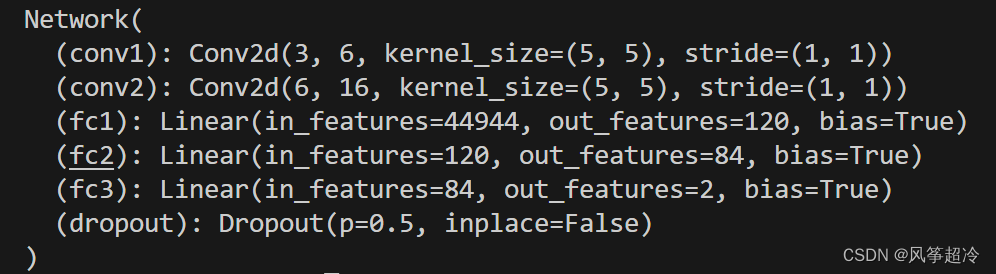
四、训练模型
1. 设置超参数
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
leaining_rate = 0.001
opt = torch.optim.Adam(model.parameters(),lr=leaining_rate)2.编写训练函数
# 训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for x, y in dataloader:
x, y = x.to(device), y.to(device)
# Compute prediction error
pred = model(x) # 网络输出
loss = loss_fn(pred, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
# 测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
test_loss += loss_fn(pred, y).item()
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
3.正式训练
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
代码在运行时出现下列问题可能是以下原因导致:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "D:\Python\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "D:\Python\lib\multiprocessing\spawn.py", line 125, in _main
prepare(preparation_data)
File "D:\Python\lib\multiprocessing\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "D:\Python\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "D:\Python\lib\runpy.py", line 289, in run_path
return _run_module_code(code, init_globals, run_name,
File "D:\Python\lib\runpy.py", line 96, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "D:\Python\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "c:\Users\刘鸿逸\Desktop\python\01.py", line 156, in <module>
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
File "c:\Users\刘鸿逸\Desktop\python\01.py", line 105, in train
for X, y in dataloader: # 获取图片及其标签
File "D:\Python\lib\site-packages\torch\utils\data\dataloader.py", line 441, in __iter__
return self._get_iterator()
File "D:\Python\lib\site-packages\torch\utils\data\dataloader.py", line 388, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "D:\Python\lib\site-packages\torch\utils\data\dataloader.py", line 1042, in __init__
w.start()
File "D:\Python\lib\multiprocessing\process.py", line 121, in start
self._popen = self._Popen(self)
File "D:\Python\lib\multiprocessing\context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "D:\Python\lib\multiprocessing\context.py", line 336, in _Popen
return Popen(process_obj)
File "D:\Python\lib\multiprocessing\popen_spawn_win32.py", line 45, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
File "D:\Python\lib\multiprocessing\spawn.py", line 154, in get_preparation_data
_check_not_importing_main()
File "D:\Python\lib\multiprocessing\spawn.py", line 134, in _check_not_importing_main
raise RuntimeError('''
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:if __name__ == '__main__':
freeze_support()
...The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
这个错误是由于在Windows操作系统上使用多进程时,未按照正确的方式设置了启动子进程的方法引起的。它提示需要在主模块中添加适当的if __name__ == '__main__':块以正确启动子进程。下面解释一下报错的含义以及如何解决它:
- 为了解决这个问题,应该确保在主模块中使用
if __name__ == '__main__':块来包装主要的执行代码,这是一种在使用多进程时常见的做法。 - 在主模块中包装代码后,子进程将只在主进程中执行,而不会在导入模块时执行。这可以防止上述报错。
修改后完整代码:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os
import PIL
import pathlib
# Your code for data loading, model definition, training, and testing should go here
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import os,PIL,random,pathlib
data_dir = r'D:\P4'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
class_names = [path.name for path in data_paths]
print(class_names)
total_datadir = r'D:\P4'
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, len(class_names))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
print(model)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
epochs = 17
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
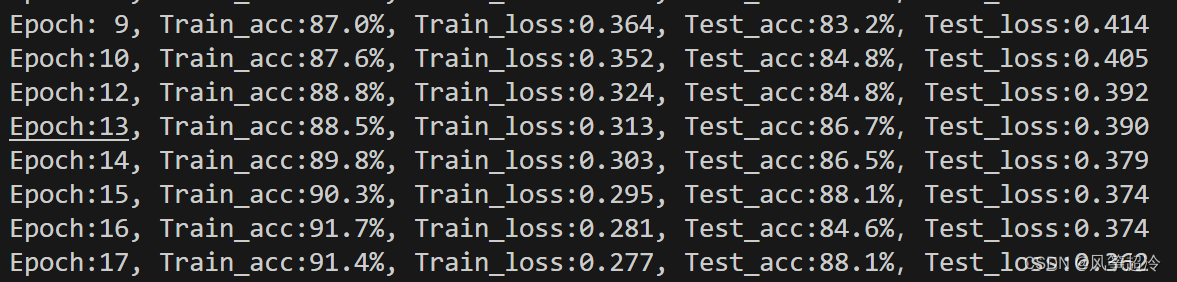
验证集正确率达到88%以上。