论文信息
题目:Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation
作者:Anurag Ranjan, Varun Jampani, Lukas Balles
来源:CVPR
时间:2019
代码地址:https://github.com/anuragranj/cc
Abstract
我们解决了低级视觉中几个相互关联问题的无监督学习:单视图深度预测、相机运动估计、光流以及将视频分割为静态场景和移动区域。
我们的主要见解是这四个基本视觉问题通过几何约束耦合在一起。因此,学习一起解决它们可以简化问题,因为这些解决方案可以相互促进。我们通过更明确地利用几何形状并将场景分割为静态和移动区域,超越了之前的工作。
为此,我们引入了竞争性协作,这是一个促进多个专业神经网络协调训练以解决复杂问题的框架。竞争性协作的工作原理与期望最大化非常相似,但神经网络既充当竞争者来解释与静态或移动区域相对应的像素,又充当通过调节器将像素分配为静态或独立移动的协作者。我们的新颖方法将所有这些问题集成在一个通用框架中,并同时推理场景分割为运动物体和静态背景、相机运动、静态场景结构的深度以及运动物体的光流。我们的模型在没有任何监督的情况下进行训练,并在所有子问题上的联合无监督方法中实现了最先进的性能。

Introduction
我们在本文中考虑了四个这样的问题:单视图深度预测、相机运动估计、光流和运动分割。之前的工作已经使用真实数据[5]和合成数据[4]通过监督来解决这些问题。然而,合成数据与真实数据之间始终存在现实差距,并且真实数据有限或不准确。
Approach。为了解决联合无监督学习的问题,我们引入了竞争性协作(CC),这是一种通用框架,网络在其中学习协作和竞争,从而实现特定目标。在我们的特定场景中,竞争性协作是一个三人游戏,由两个玩家竞争由第三个玩家(主持人)监管的资源。
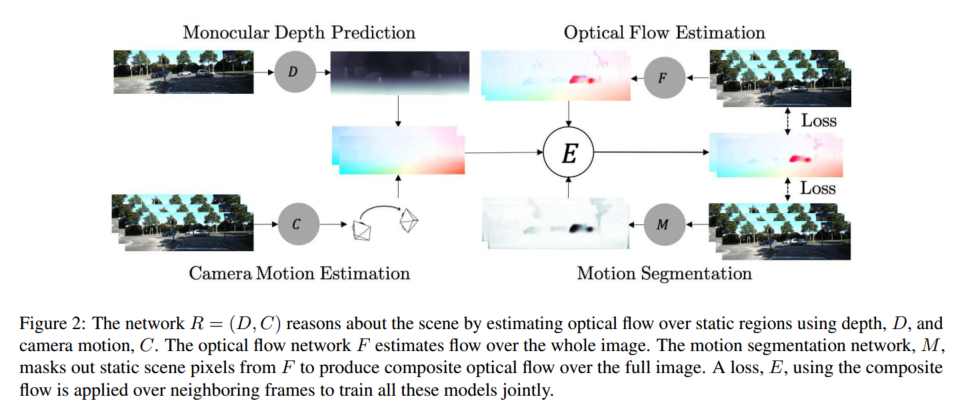
如图 2 所示,我们在框架中引入了两个参与者,即静态场景重建器 R = ( D , C ) R = (D, C) R=(D,C),它使用深度 D 和相机运动 C 来推理静态场景像素;以及运动区域重建器 F,其推理独立运动区域中的像素。这两个玩家通过推理图像序列中的静态场景和移动区域像素来竞争训练数据。比赛由运动分割网络 M 主持,该网络分割静态场景和运动区域,并将训练数据分发给选手。不过,主持人也需要培训,以保证公平竞争。因此,玩家 R 和 F 合作训练主持人 M,使其在训练周期的交替阶段正确分类静态和移动区域。这个通用框架在本质上与期望最大化 (EM) 类似,但专为神经网络训练而制定。
总之,我们的贡献是:
1)我们引入了竞争性协作,这是一种无监督学习框架,其中网络充当竞争对手和合作者以实现特定目标。
2)我们表明,使用该框架联合训练网络对其性能具有协同效应。
3)据我们所知,我们的方法是第一个使用深度、相机运动和光流等低级信息来解决分割任务而无需任何监督的方法。
4)我们在无监督方法中的单视图深度预测和相机运动估计方面实现了最先进的性能。我们在推理场景几何形状的无监督方法中实现了最先进的光流性能,并引入了完全无监督运动分割的第一个基线。
5)我们分析了我们方法的收敛特性,并使用 MNIST [19] 和 SVHN [25] 数字上的混合域学习给出了其泛化的直觉。
Competitive Collaboration
在我们的背景下,竞争性协作被表述为一个三人游戏,由两名玩家竞争由主持人监管的资源组成,如图 3 所示。
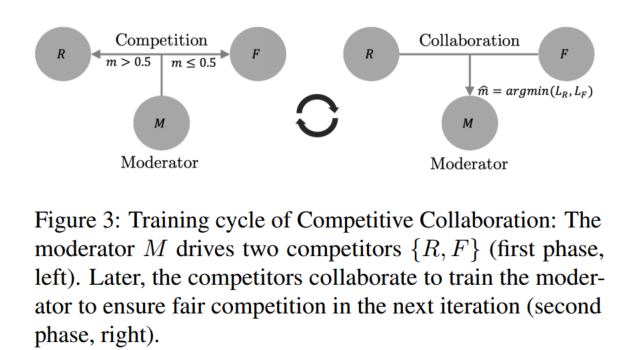
考虑一个未标记的训练数据集 D = D i : i ∈ N D = {D_i : i ∈ \mathbb{N}} D=Di:i∈N,其中可以分为两个不相交的集合。两个玩家{R,F}竞争获取这些数据作为资源,每个玩家都尝试对D进行分区以最小化其损失。分区由主持人的输出 m = M ( D i ) , m ∈ [ 0 , 1 ] Ω m = M(D_i),m ∈ [0, 1]^Ω m=M(Di),m∈[0,1]Ω 调节,Ω 是竞争对手的输出域。竞争玩家分别最小化他们的损失函数 L R 、 L F L_R、L_F LR、LF,这样每个玩家都会针对自己而不是群体进行优化。为了解决这个问题,我们的培训周期分为两个阶段。
在第一阶段,我们通过固定调节器网络 M 并最小化

然而,主持人M也需要接受培训。这发生在训练周期的第二阶段。
参赛者{R,F}形成共识并训练主持人M,使其在训练周期的下一阶段正确分配数据。在协作阶段,我们通过最小化
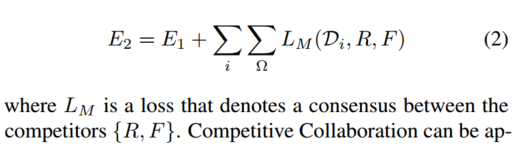
来修复竞争对手并培训主持人。
在联合学习深度、相机运动、光流和运动分割的背景下,
第一个参与者 R = (D, C) 由深度和相机运动网络组成,用于推理场景中的静态区域。
第二个参与者 F 是推理移动区域的光流网络。
为了训练参赛者,运动分割网络 M 在静态像素上选择网络 (D, C),并在属于运动区域的像素上选择 F。
竞赛确保 (D, C) 仅对静态部分进行推理,并防止移动像素破坏其训练。类似地,它可以防止任何静态像素出现在 F 的训练损失中,从而提高其在运动区域中的性能。在训练周期的第二阶段,参赛者(D、C)和 F 现在通过形成共识来合作推理静态场景和移动区域,该共识用作训练主持人 M 的损失。
我们在此框架内制定了深度、相机运动、光流和运动分割的联合无监督估计
Notation
我们使用 {Dθ, Cφ, Fψ, Mχ} 分别表示估计深度、相机运动、光流和运动分割的网络。下标{θ, φ, ψ, χ}是网络参数。为了简洁起见,我们将省略几个地方的下标。考虑具有目标帧 I 和时间相邻参考帧 I−、I+ 的图像序列 I−、I、I+。一般来说,我们可以有许多相邻帧。在我们的实现中,我们对 Cφ 和 Mχ 使用 5 帧序列,但为了简单起见,使用 3 帧来描述我们的方法。我们估计目标帧的深度为
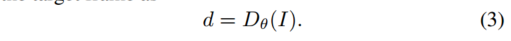
我们估计每个参考帧 I−、I+ 的相机运动 e。目标框架 I 为
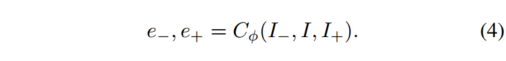
类似地,我们估计目标图像分割为静态场景和运动区域。静态场景的光流仅由相机运动和深度定义。这通常指的是场景的结构。移动区域具有独立运动场。与每对目标图像和参考图像相对应的分割掩模由下式给出
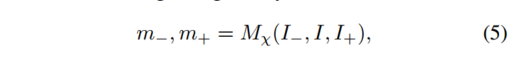
其中
m
−
,
m
+
∈
[
0
,
1
]
Ω
m_−, m_+ \in [0, 1]^Ω
m−,m+∈[0,1]Ω表示空间像素域 Ω 中静态区域的概率。
最后,网络 Fψ 估计光流。 Fψ 一次处理 2 个图像,在分别估计 u−、u+、后向和前向光流时共享其权重。
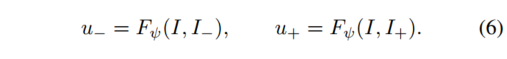
Loss
我们通过联合最小化能量
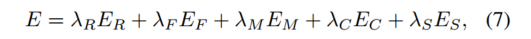
来学习网络参数 {Dθ, Cφ, Fψ, Mχ}, 其中 {λR, λF , λM, λC , λS}是各个能量项的权重。
E R E_R ER 和 E F E_F EF 项是两个竞争对手分别重建静态和移动区域时最小化的目标。数据竞争是由新兴市场驱动的。
较大的权重 λ M λ_M λM 将驱动更多像素流向静态场景重建器。 E C E_C EC 一词推动了协作,而 E S E_S ES 是平滑度正则化器。
静态场景项 E R E_R ER 最小化静态场景像素的光度损失,如下所示
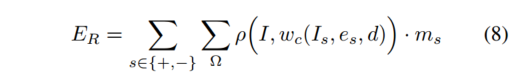
其中Ω是空间像素域,ρ是鲁棒误差函数,
w
c
w_c
wc根据深度d和相机运动e将参考帧向目标帧扭曲。同样,
E
F
E_F
EF 最大限度地减少了移动区域的光度损失
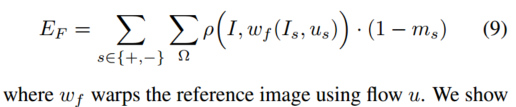
我们将鲁棒误差 ρ(x, y) 计算为

第二项也称为结构相似性损失(SSIM)[34],已在之前的工作[22, 37]中使用,
μ
x
、
σ
x
μ^x、σ^x
μx、σx 是像素邻域的局部均值和方差,其中
c
1
=
0.0
1
2
,
c
2
=
0.0
3
2
c_1 = 0.01^2, c_2 = 0.03^2
c1=0.012,c2=0.032 。

令 ν(e, d) 表示相机运动 e 和深度 d 引起的光流,如附录 A.2 中所述。共识损失
E
C
E_C
EC 通过在 ν(e, d) 给出的静态场景流和 Fψ 给出的光流估计之间取得共识来驱动协作并约束掩模来分割移动对象。它由下式给出

第一个指标函数有利于将掩模分配给竞争对手,通过比较
ρ
R
=
ρ
(
I
,
w
c
(
I
s
,
e
s
,
d
)
)
ρ_R = ρ(I, w_c(I_s, e_s, d))
ρR=ρ(I,wc(Is,es,d)) 和
ρ
F
=
ρ
(
I
,
w
f
(
I
s
,
u
s
)
)
ρ_F = ρ(I, w_f (I_s, u_s))
ρF=ρ(I,wf(Is,us)) 来实现像素上较低的光度误差。
在第二个指标函数中,如果静态场景流ν(e,d)接近光流u,则阈值λc迫使I = 1,表明静态场景。符号∨表示指标函数之间的逻辑或。如果 R 的光度误差低于 F 或 R 的诱导流与 F 的相似,共识损失
E
C
E_C
EC 鼓励将像素标记为静态。
最后,平滑项
E
S
E_S
ES 充当深度、分割和flow的正则化矩阵,

Inference
深度 d 和相机运动 e 直接从网络输出推断出来。运动分割 m* 由掩模网络 Mχ 的输出以及 Fχ 的静态流和光流估计之间的一致性获得。它由下式给出
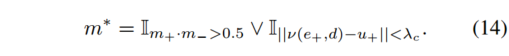
第一项采用 Mχ 使用前向和后向参考帧推断的掩模概率的交集。
第二项采用从 R = (Dθ, Cφ) 和 Fψ 估计的流量之间的共识来推理掩模。
最终的掩模是通过两项的并集获得的。最后,(I, I+) 之间的完整光流 u * 是来自静态场景和独立移动区域的光流的组合,由下式给出
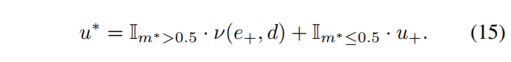
方程(7)中的损失被公式化以最小化相邻帧的重建误差。两个竞争对手,静态场景重建器 R = (Dθ, Cφ) 和移动区域重建器 Fψ 最小化了这种损失。
重建器 R 使用等式(8)对静态场景进行推理,重建器 Fψ 使用等式(9)对移动区域进行推理。
调节是通过掩模网络 Mχ 使用等式(11)来实现的。
此外,使用方程(12)驱动R、F之间的协作来训练网络Mχ。
如果场景完全静态,并且只有相机移动,则掩模会强制 (Dθ, Cφ) 重建整个场景。然而,(Dθ, Cφ) 在场景的独立移动区域中是错误的,并且这些区域是使用 Fψ 重建的。调节器 Mχ 经过训练,可以通过 (Dθ, Cφ) 和 Fψ 达成共识来正确分割静态和移动区域,以推理场景中的静态和移动部分,如等式 (12) 所示。
因此,我们的培训周期分为两个阶段。
在第一阶段,调节器 Mχ 使用方程(8、9)推动两个模型(Dθ、Cφ)和 Fψ 之间的竞争。
在第二阶段,参赛者(Dθ,Cφ)和Fψ共同协作,使用方程(11,12)训练调节器Mχ。