一、TCP 状态转换


二、TCP协议的通信过程

三、TCP 通信流程

// TCP 通信的流程
// 服务器端 (被动接受连接的角色)
1. 创建一个用于监听的套接字
- 监听:监听有客户端的连接
- 套接字:这个套接字其实就是一个文件描述符
2. 将这个监听文件描述符和本地的IP和端口绑定(IP和端口就是服务器的地址信息)
- 客户端连接服务器的时候使用的就是这个IP和端口
3. 设置监听,监听的fd开始工作
4. 阻塞等待,当有客户端发起连接,解除阻塞,接受客户端的连接,会得到一个和客户端通信的套接字
(fd)
5. 通信
- 接收数据
- 发送数据
6. 通信结束,断开连接// 客户端
1. 创建一个用于通信的套接字(fd)
2. 连接服务器,需要指定连接的服务器的 IP 和 端口
3. 连接成功了,客户端可以直接和服务器通信
- 接收数据
- 发送数据
4. 通信结束,断开连接
套接字通信的客户端和服务端的实现_呵呵哒( ̄▽ ̄)"的博客-CSDN博客https://blog.csdn.net/weixin_41987016/article/details/132046488?spm=1001.2014.3001.5501
四 、解析HTTP请求报文
4.1 读取数据到缓冲区 bool http_conn::read()
// 循环读取客户数据,直到无数据可读或者对方关闭连接
bool http_conn::read() {
// printf("一次性读完数据\n");
if( m_read_idx >= READ_BUFFER_SIZE ) {
return false;
}
int bytes_read = 0;//读取到的字节
while(true) {//开始保存数据
// 数组起始位置(0) + 已经读的数据位置(100) = 下次开始写的位置(101)
// 从m_read_buf + m_read_idx索引出开始保存数据,大小是READ_BUFFER_SIZE - m_read_idx
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx,
READ_BUFFER_SIZE - m_read_idx, 0 );
if (bytes_read == -1) {
if( errno == EAGAIN || errno == EWOULDBLOCK ) {
// 没有数据
break;
}
return false;
} else if (bytes_read == 0) { // 对方关闭连接
return false;
}
m_read_idx += bytes_read;//读到数据,更新索引
}
// printf("读到了数据: %s\n",m_read_buf);
return true;
}
4.2 有限状态机
逻辑单元内部的一种高效编程方法:有限状态机(finite state machine)。有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑。如下是一种状态独立的有限状态机:
STATE_MACHINE( Package _pack )
{
PackageType _type = _pack.GetType();
switch( _type )
{
case type_A:
process_package_A( _pack );
break;
case type_B:
process_package_B( _pack );
break;
}
}这是一个简单的有限状态机,只不过该状态机的每个状态都是相互独立的,即状态之间没有相互转移。状态之间的转移是需要状态机内部驱动,如下代码:
STATE_MACHINE()
{
State cur_State = type_A;
while( cur_State != type_C )
{
Package _pack = getNewPackage();
switch( cur_State )
{
case type_A:
process_package_state_A( _pack );
cur_State = type_B;
break;
case type_B:
process_package_state_B( _pack );
cur_State = type_C;
break;
}
}
}该状态机包含三种状态:type_A、type_B 和 type_C,其中 type_A 是状态机的开始状态,type_C 是状态机的结束状态。状态机的当前状态记录在 cur_State 变量中。在一趟循环过程中,状态机先通过 getNewPackage 方法获得一个新的数据包,然后根据 cur_State 变量的值判断如何处理该数据包。数据包处理完之后,状态机通过给 cur_State 变量传递目标状态值来实现状态转移。那么当状态机进入下一趟循环时,它将执行新的状态对应的逻辑。
4.3 HTTP 请求格式

>>http get请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
提示: 每项信息之间都需要一个\r\n,是由http协议规定
************************************************
************************************************
>>http post请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
请求体
提示: 请求体就是浏览器发送给服务器的数据
在HTTP报文中,每一行的数据有\r\n作为结束字符,空行则是仅仅是字符\r\n。因此,可以通过查找\r\n将报文拆解成单独的行进行解析,项目中便是利用了这一点。
推荐文章:
http请求报文与响应报文_构造http请求报文,发送到天气预报的服务器,并获取http响应报文,将报文进行解析获_JSon liu的博客-CSDN博客![]() https://blog.csdn.net/weixin_45912307/article/details/109454522
https://blog.csdn.net/weixin_45912307/article/details/109454522
Http请求报文格式和响应报文格式-腾讯云开发者社区-腾讯云 (tencent.com)![]() https://cloud.tencent.com/developer/article/1953222我的往期文章:Web服务器简介及HTTP协议_呵呵哒( ̄▽ ̄)"的博客-CSDN博客
https://cloud.tencent.com/developer/article/1953222我的往期文章:Web服务器简介及HTTP协议_呵呵哒( ̄▽ ̄)"的博客-CSDN博客![]() https://blog.csdn.net/weixin_41987016/article/details/132610837?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_41987016/article/details/132610837?spm=1001.2014.3001.5501
4.4 状态转换图
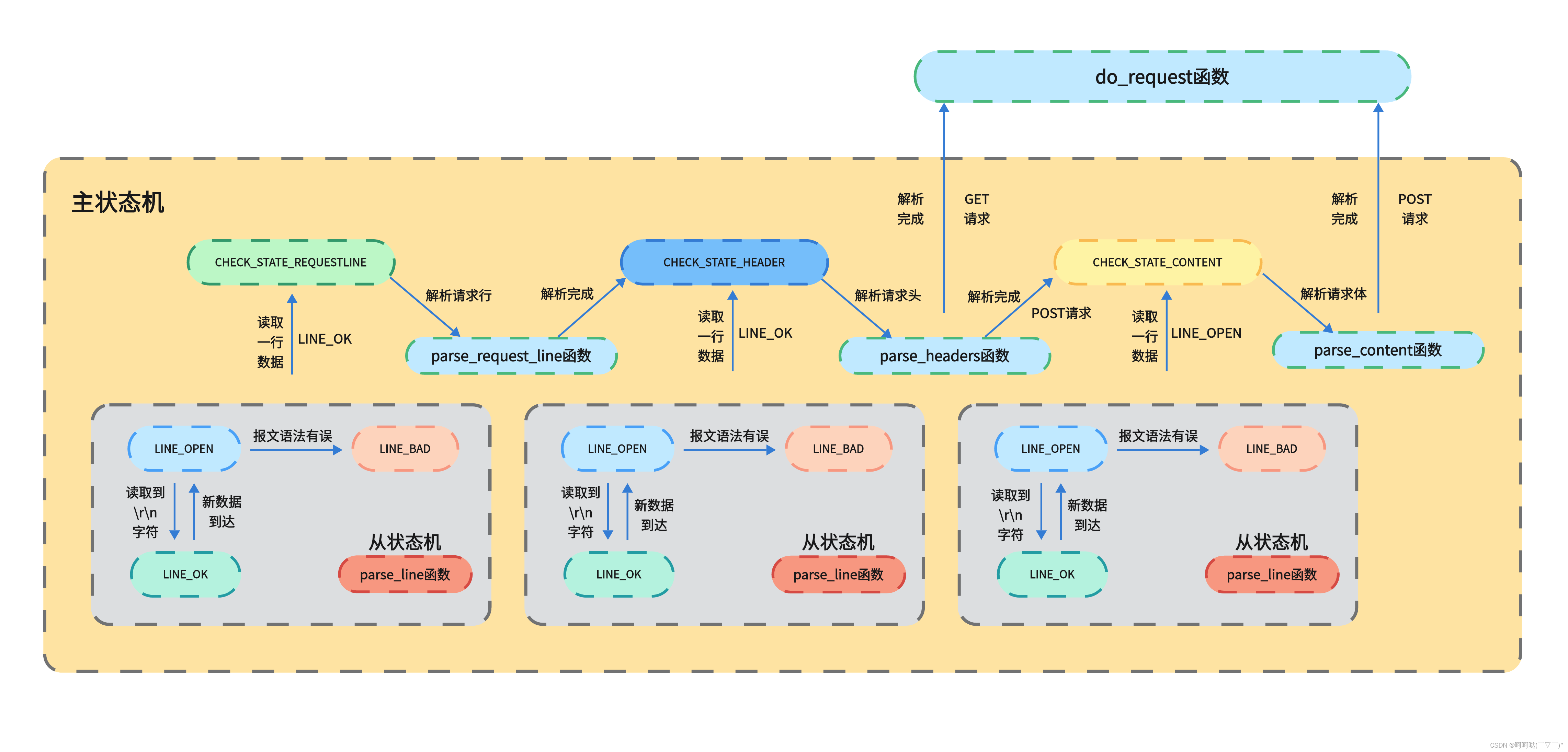
4.5 主状态机状态和从状态机状态
(1) 从状态机状态

>>从状态机逻辑
负责读取buffer中的数据,将每行数据末尾的\r\n置为\0\0,并更新从状态机在buffer中读取的位置m_checked_idx,从此来驱动主状态机解析
① 从状态机从m_read_buf中逐字节读取,判断当前字节是否为\r
- 接下来的字符是\n,将\r\n修改成\0\0,将m_checked_idx指向下一行的开头,则返回LINE_OK
- 然后达到了buffer末尾,表示buffer还需要继续接收,返回LINE_OPEN
- 否则,表示语法错误,返回LINE_BAD
② 当前字节不是\r,判断是否是\n
- 【注意】什么时候会是②这种情况?
一般是上次读取到\r就到了buffer末尾,没有接收完整,再次接收时会出现这种情况。- 【判断】如果前一个字符是\r,则将\r\n修改成\0\0,将m_checked_idx指向下一行的开头,则返回LINE_OK
③ 当前字节既不是\r,也不是\n
- 表示接受不完整,需要继续接收,返回LINE_OPEN
/*
从状态机,用于分析出一行内容
返回值为行的读取状态,由LINE_OK,LINE_BAD,LINE_OPEN
m_read_idx:指向缓冲区m_read_buf的数据末尾的下一个字节
m_checked_idx:指向从状态机当前正在分析的字节
*/
// 解析一行,判断依据\r\n
http_conn::LINE_STATUS http_conn::parse_line() {
char temp;
for ( ; m_checked_idx < m_read_idx; ++m_checked_idx ) {
// temp 为将要分析的字节
temp = m_read_buf[ m_checked_idx ];
// 如果当前是\r字符,则有可能会读取到完整行
if ( temp == '\r' ) {
// 下一个字符达到了buffer结尾,则接收不完整,需要继续接收
if ( ( m_checked_idx + 1 ) == m_read_idx ) {
return LINE_OPEN;
}
// 下一个字符是\n,将\r\n改为\0\0
else if ( m_read_buf[ m_checked_idx + 1 ] == '\n' ) {
m_read_buf[ m_checked_idx++ ] = '\0';
m_read_buf[ m_checked_idx++ ] = '\0';
return LINE_OK;
}
// 如果都不符合,则返回语法错误
return LINE_BAD;
}
// 如果当前字符是\n,也有可能读取到完整行
// 一般是上次读取到\r就到 buffer 末尾了,没有接收完整,再次接收时会出现这种情况
else if( temp == '\n' ) {
// 前一个字符是\r,则接收完整
if( ( m_checked_idx > 1) && ( m_read_buf[ m_checked_idx - 1 ] == '\r' ) ) {
m_read_buf[ m_checked_idx-1 ] = '\0';
m_read_buf[ m_checked_idx++ ] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
// 并没有找到\r\n,需要继续接收
return LINE_OPEN;
}例如:
>>http get请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
提示: 每项信息之间都需要一个\r\n,是由http协议规定
>>http get请求报文的格式
请求行\0\0
请求头\0\0
空行(\0\0)(2)主从状态机,http_conn::process_read()
>>解析报文整体流程
process_read 通过 while 循环,将主状态机进行封装,对报文的每一行进行循环处理
http_conn::process_read() 是一个HTTP请求处理函数,用于解析HTTP请求报文
① 解析一行数据,得到不同状态(包括请求行、请求头、请求体)
- LINE_OK
- LINE_BAD
- LINE_OPEN
② 根据不同的状态,解析请求行、请求头或请求体,并进行相应的处理
- CHECK_STATE_REQUESTLINE ---- parse_request_line()
- CHECK_STATE_HEADER ---- parse_headers()
- CHECK_STATE_CONTENT ---- parse_content()
③ 对于GET请求,根据具体的请求信息进行预处理,分析目标文件属性,并将其映射到内存地址m_file_address处
- do_request()
④ 返回处理结果,包括成功、失败或请求不完整等状态码
>>主从状态机模式
主从状态机模式:http_conn::process_read()用以应对不同的状态处理。
- 一个状态机作为主要的控制器,而其他状态机则被设计为从状态机
- 主状态机将它们之间的通信和事件处理进行协调
- 主状态机是在系统启动时创建的
- 从状态机可以在系统运行时动态创建、注册或注销
主状态机 process_read() 中进行循环,直到解析完整个 HTTP 请求数据

当且仅当解析到请求体时,才需要进一步判断是否已经解析完整个 HTTP 请求数据
① 表示若当前正在解析请求体,并且从状态机已经成功解析了一行请求数据,则需要继续解析下一行请求数据
(m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK)② 或者从状态机还未成功解析出一行完整的请求数据,就需要不断循环调用从状态机、解析请求数据
((line_status = parse_line()) == LINE_OK))(line_status = parse_line()) 表示调用从状态机 parse_line() ,并将返回值赋给变量 line_status
- 解析成功,line_status = LINE_OK
- 否则,line_status 为 LINE_OPEN、LINE_BAD等
③ 直到解析完成整个 HTTP 请求数据
// 主状态机,解析请求
http_conn::HTTP_CODE http_conn::process_read() {
// 定义初始状态
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char* text = 0;
// 解析一行数据,得到不同状态
// OK表示正常
// 主状态机 && 从状态机 || 解析到一行完整数据(或者请求体)
// 这里主状态机指的是process_read()函数,从状态机指的是parse_line()
while (((m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK))
|| ((line_status = parse_line()) == LINE_OK)) {
// 获取一行数据
text = get_line();
m_start_line = m_checked_idx;
printf( "got 1 http line: %s\n", text );
switch ( m_check_state ) {
case CHECK_STATE_REQUESTLINE: {
// 解析请求行,也就是 GET 中的 GET
/*
通过请求行的解析我们可以判断该HTTP请求的类型(GET/POST),
而请求行中最重要的部分就是URL部分
将这部分保存下来用于后面的生成HTTP响应
*/
ret = parse_request_line( text );
if ( ret == BAD_REQUEST ) {
return BAD_REQUEST;
}
break;// 正常解析就break
}
case CHECK_STATE_HEADER: {
ret = parse_headers( text );//解析请求头,GET 和 POST 中空行以上,请求行以下的部分
if ( ret == BAD_REQUEST ) {
return BAD_REQUEST;
} else if ( ret == GET_REQUEST ) {//遇到换行符就默认你解析完请求头,不管后面还有没有内容
return do_request();//解析具体的请求信息
}
break;
}
case CHECK_STATE_CONTENT: {
/*
解析请求数据,对于GET来说这部分是空的,
因为这部分内容已经以明文的方式包含在了请求行中的URL部分了;
只有POST的这部分是有数据的
*/
ret = parse_content( text );
if ( ret == GET_REQUEST ) {
/*
do_request() 需要做:
需要首先对 GET请求 和不同的 POST请求
(登录、注册、请求图片、视频等等)做不同的预处理,
然后分析目标文件的属性,若目标文件存在、对所有用户可读且不是目录时,
则使用mmap将其映射到内存地址m_file_address处,并告诉调用者获取文件成功
*/
return do_request();
}
line_status = LINE_OPEN;
break;
}
default: {
return INTERNAL_ERROR;
}
}
}
return NO_REQUEST;//主状态机请求不完整
}注意在http_conn.h 编写 get_line()函数
// m_start_line是已经解析的字符
// get_line用于将指针向后偏移,指向未处理的字符
/*
m_start_line是行在bufffer中的起始位置,将该位置后面的数据赋给text
此时从状态机已提前将一行的末尾字符\r\n变为\0\0,所以text可以直接取出完整的行进行解析
*/
char* get_line() {
return m_read_buf + m_start_line;
}(3)主状态机状态


>>主状态机逻辑
主状态机初始状态是CHECK_STATE_REQUESTLINE,通过调用从状态机来驱动主状态机,在主状态机进行解析前,从状态机已经将每一行的末尾\r\n符号改为\0\0,以便于主状态机直接取出对应字符串进行处理。
CHECK_STATE_REQUESTLINE
- 主状态机的初始状态,调用parse_request_line函数解析请求行
- 解析函数从m_read_buf中解析HTTP请求行,获得请求方法,目标URL及HTTP版本号
- 解析完成后主状态机的状态变为CHECK_STATE_HEADER
// 解析HTTP请求行,获得请求方法,目标URL,以及HTTP版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char* text) {
// 在HTTP报文中,请求行用来说明请求类型,要访问的资源以及所使用的HTTP版本,
// 其中各个部分之间通过\t或空格分隔
// 请求行中最先含有空格和\t任一字符的位置并返回
// GET /index.html HTTP/1.1
m_url = strpbrk(text, " \t"); // 判断第二个参数中的字符哪个在text中最先出现
// 如果没有空格或\t,则报文格式有误
if (! m_url) {
return BAD_REQUEST;
}
// 将该位置改为\0,用于将前面数据取出
// GET\0/index.html HTTP/1.1
*m_url++ = '\0'; // 置位空字符,字符串结束符
// 取出数据,并通过与GET和POST比较,以确定请求方式
char* method = text;
if ( strcasecmp(method, "GET") == 0 ) { // 忽略大小写比较
m_method = GET;
} else {
return BAD_REQUEST;
}
// /index.html HTTP/1.1
// 检索字符串 str1 中第一个不在字符串 str2 中出现的字符下标。
m_version = strpbrk( m_url, " \t" );
if (!m_version) {
return BAD_REQUEST;
}
*m_version++ = '\0';
// 仅支持HTTP/1.1
if (strcasecmp( m_version, "HTTP/1.1") != 0 ) {
return BAD_REQUEST;
}
/**
* http://192.168.110.129:10000/index.html
* 对请求资源前7个字符进行判断
* 这里主要是有些报文的请求资源中会带有http://,这里需要对这种情况进行单独处理
*/
if (strncasecmp(m_url, "http://", 7) == 0 ) {
m_url += 7;
// 在参数 str 所指向的字符串中搜索第一次出现字符 c(一个无符号字符)的位置。
m_url = strchr( m_url, '/' );
}
// 同样增加https情况
if (strncasecmp(m_url, "https://", 8) == 0 ) {
m_url += 8;
m_url = strchr( m_url, '/' );
}
// 一般的不会带有上述两种符号,直接是单独的/或/后面带访问资源
if ( !m_url || m_url[0] != '/' ) {
return BAD_REQUEST;
}
// 请求行处理完毕,将主状态机转移处理请求头
m_check_state = CHECK_STATE_HEADER; // 检查状态变成检查头
return NO_REQUEST;
}解析完请求行后,主状态机继续分析请求头。在报文中,请求头和空行的处理使用的同一个函数,这里通过判断当前的text首位是不是\0字符。
- 若是,则表示当前处理的是空行
- 若不是,则表示当前处理的是请求头
CHECK_STATE_HEADER
- 调用parse_headers函数解析请求头部信息
- 判断是空行还是请求头。若是空行,进而判断Content-length是否为0,如果不是0,表明是POST请求,则状态转移到CHECK_STATE_CONTENT;否则说明是GET,则报文解析结束
- 若解析的是请求头部字段,则主要分析Connection字段,Content-length字段等
- Connection字段判断是keep-alive 还是 close,决定是长连接还是短连接;如果是长连接,则将linger标志设置为true
- Content-length字段,这里用于读取post请求的消息体长度
// 解析HTTP请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char* text) {
// 遇到空行,表示头部字段解析完毕
if( text[0] == '\0' ) {
// 判断是GET 还是 POST 请求
/*
如果HTTP请求有消息体,则还需要读取m_content_length字节的消息体,
状态机转移到CHECK_STATE_CONTENT状态
*/
if ( m_content_length != 0 ) {
// POST需要跳转到消息体处理状态
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
// 否则说明我们已经得到了一个完整的HTTP请求
return GET_REQUEST;
}
// 解析请求头部连接字段
else if ( strncasecmp( text, "Connection:", 11 ) == 0 ) {
// 处理Connection 头部字段 Connection: keep-alive
text += 11;
// 跳过空格和\t字符
text += strspn( text, " \t" );
if ( strcasecmp( text, "keep-alive" ) == 0 ) {
// 如果是长连接,则将linger标志设置为true
m_linger = true;
}
}
// 解析请求头部内容长度字段
else if ( strncasecmp( text, "Content-Length:", 15 ) == 0 ) {
// 处理Content-Length头部字段
text += 15;
text += strspn( text, " \t" );
m_content_length = atol(text);
}
// 解析请求头部HOST字段
else if ( strncasecmp( text, "Host:", 5 ) == 0 ) {
// 处理Host头部字段
text += 5;
text += strspn( text, " \t" );
m_host = text;
} else {
printf( "oop! unknow header %s\n", text );
}
return NO_REQUEST;
}GET和POST请求报文的区别之一是有无消息体部分。GET请求没有消息体,当解析完空行之后,便完成了报文的解析。仅用从状态机的状态(line_status = parse_line()) == LINE_OK语句即可。
在POST请求报文中,消息体的末尾没有任何字符
>>http post请求报文的格式
请求行\r\n
请求头\r\n
空行(\r\n)
请求体所以无法使用从状态机的状态,转而使用主状态机的状态作为循环入口条件
((m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK))
解析完消息体之后,报文的完整解析也就完成了,此时主状态机的状态还是CHECK_STATE_CONTENT。意味着符合循环入口条件,还会再次进入循环。为此,需要在完成请求体解析后,将line_status变量更改为LINE_OPEN,便可跳出循环,完成报文解析任务
while (((m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK))
|| ((line_status = parse_line()) == LINE_OK)) {
// 获取一行数据
text = get_line();
m_start_line = m_checked_idx;
printf( "got 1 http line: %s\n", text );
switch ( m_check_state ) {
......
case CHECK_STATE_CONTENT: {
ret = parse_content( text );
if ( ret == GET_REQUEST ) {
return do_request();
}
// 在完成请求体解析后,将line_status变量更改为LINE_OPEN,跳出循环,完成报文解析任务
line_status = LINE_OPEN;
break;
}
......
}
}CHECK_STATE_HEADER
- 仅用于解析POST请求,调用parse_content函数解析请求体
- 用于保存post请求消息体,为后面的登录和注册做准备
// 我们没有真正解析HTTP请求的消息体,只是判断它是否被完整的读入了
http_conn::HTTP_CODE http_conn::parse_content( char* text ) {
// 判断buffer中是否读取了消息体
if ( m_read_idx >= ( m_content_length + m_checked_idx ) )
{
text[ m_content_length ] = '\0';
return GET_REQUEST;
}
return NO_REQUEST;
}参考和推荐文章:
最新版Web服务器项目详解 - 05 http连接处理(中) (qq.com)![]() https://mp.weixin.qq.com/s?__biz=MzAxNzU2MzcwMw==&mid=2649274278&idx=7&sn=d1ab62872c3ddac765d2d80bbebfb0dd&chksm=83ffbefeb48837e808caad089f23c340e1348efb94bef88be355f4d9aedb0f9784e1f9e072b1&scene=178&cur_album_id=1339230165934882817#rd【从0开始编写webserver·基础篇#02】服务器的核心---I/O处理单元和任务类 - dayceng - 博客园 (cnblogs.com)
https://mp.weixin.qq.com/s?__biz=MzAxNzU2MzcwMw==&mid=2649274278&idx=7&sn=d1ab62872c3ddac765d2d80bbebfb0dd&chksm=83ffbefeb48837e808caad089f23c340e1348efb94bef88be355f4d9aedb0f9784e1f9e072b1&scene=178&cur_album_id=1339230165934882817#rd【从0开始编写webserver·基础篇#02】服务器的核心---I/O处理单元和任务类 - dayceng - 博客园 (cnblogs.com)![]() https://www.cnblogs.com/DAYceng/p/17418584.html#%E5%A4%84%E7%90%86%E6%96%B0%E5%AE%A2%E6%88%B7%E7%AB%AF%E7%9A%84%E8%BF%9E%E6%8E%A5%E8%AF%B7%E6%B1%82
https://www.cnblogs.com/DAYceng/p/17418584.html#%E5%A4%84%E7%90%86%E6%96%B0%E5%AE%A2%E6%88%B7%E7%AB%AF%E7%9A%84%E8%BF%9E%E6%8E%A5%E8%AF%B7%E6%B1%82