一、发展
1989年,Yann LeCun提出了一种用反向传导进行更新的卷积神经网络,称为LeNet。
1998年,Yann LeCun提出了一种用反向传导进行更新的卷积神经网络,称为LeNet-5
AlexNet,VGG,GoogleNet,ResNet
二、AlexNet
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+。 它是由Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,深度学习开始迅速发展。
ISLVRC 2012
训练集:1,281,167张已标注图片
验证集:50,000张已标注图片
测试集:100,000张未标注图片
该网络的亮点在于:
1
首次利
用
GPU
进行网络加速训练
。
2
使用
了
R
e
L
U
激活函数,而不是传统
的
S
i
g
m
o
i
d
激活函数以
及
T
anh
激活函数
。
3
使用
了
LRN
局部响应归一化
。(LPN是bn的变种)
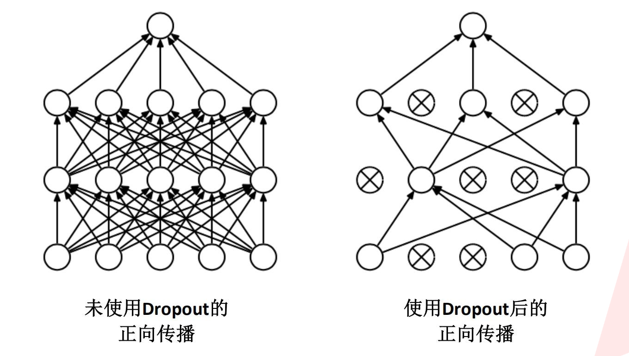
4
在全连接层的前两层中使用
了
D
r
opout
随机失活神经元操作,以减少过拟合
。
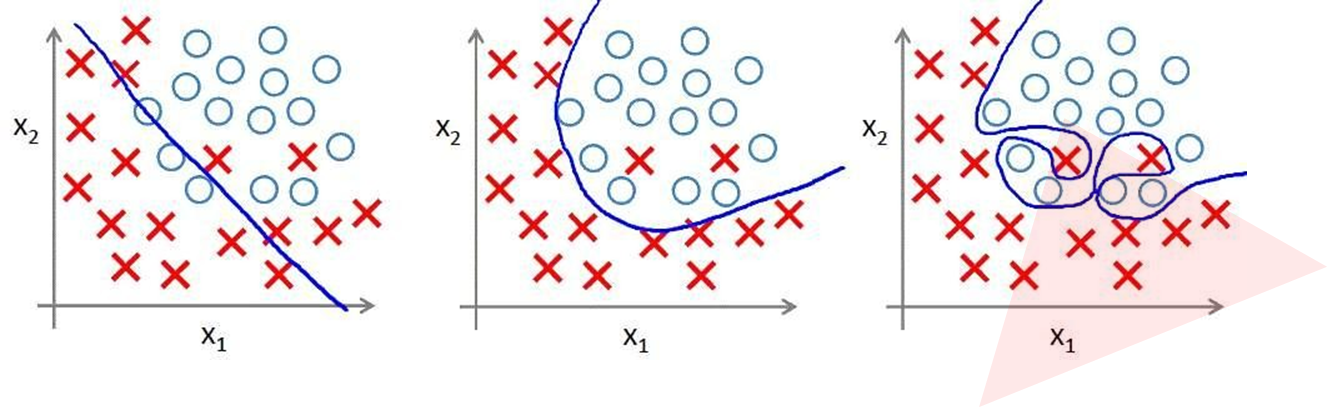
过拟合:根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测 训练集,但对新数据的测试集预测结果差。 过度的拟合了训练 数据,而没有考虑到泛化能力。
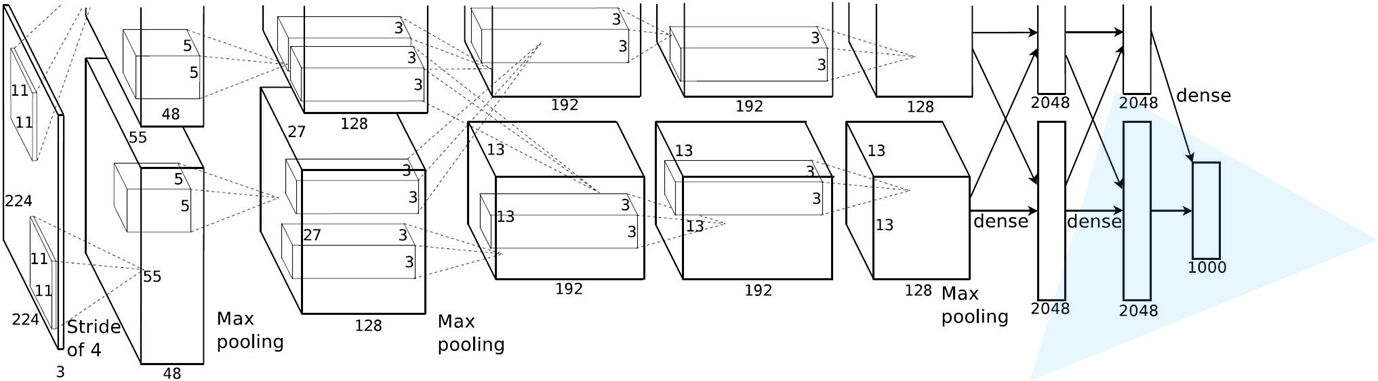
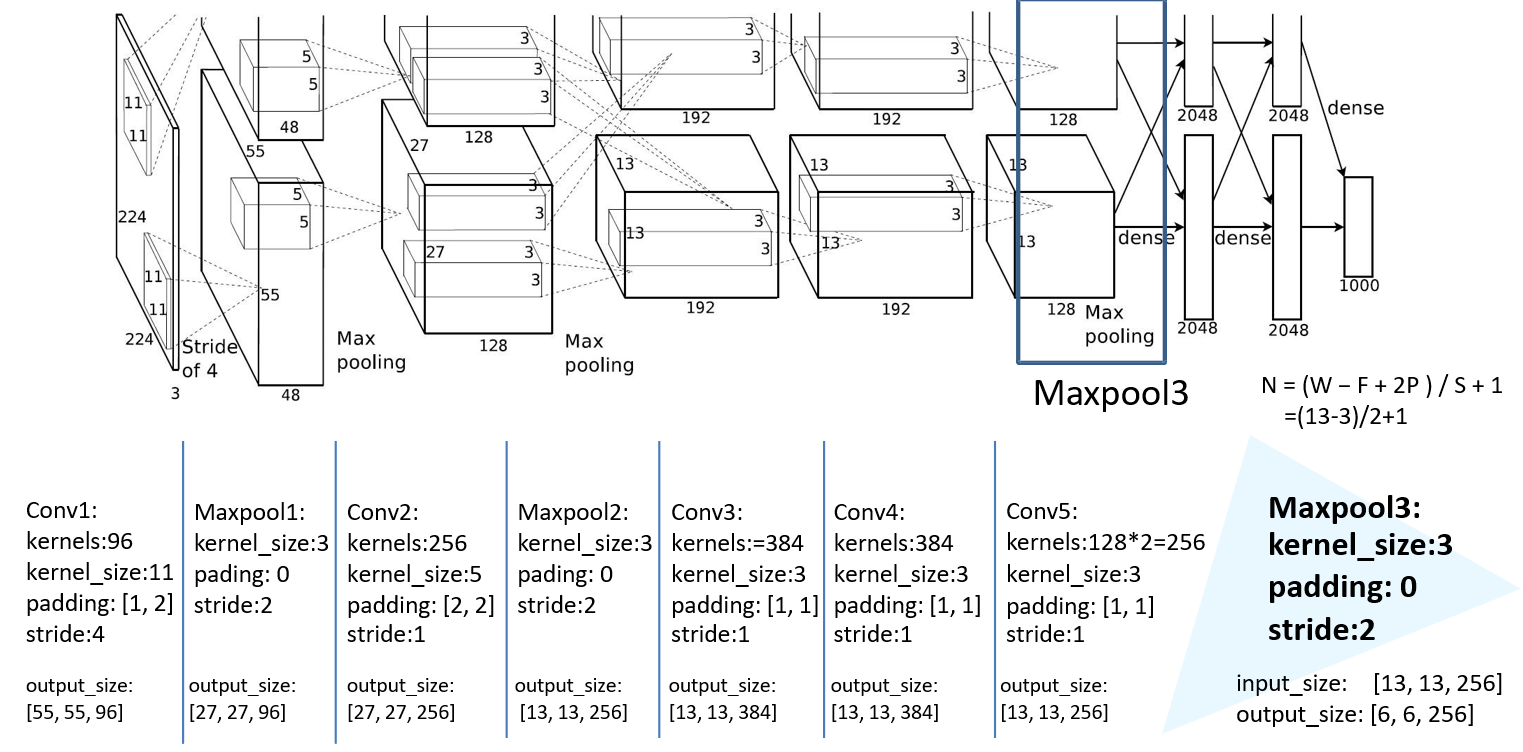
1.1 AlexNet详解
网络分为上下两层,用两个GPU同时在跑
第一层卷积:
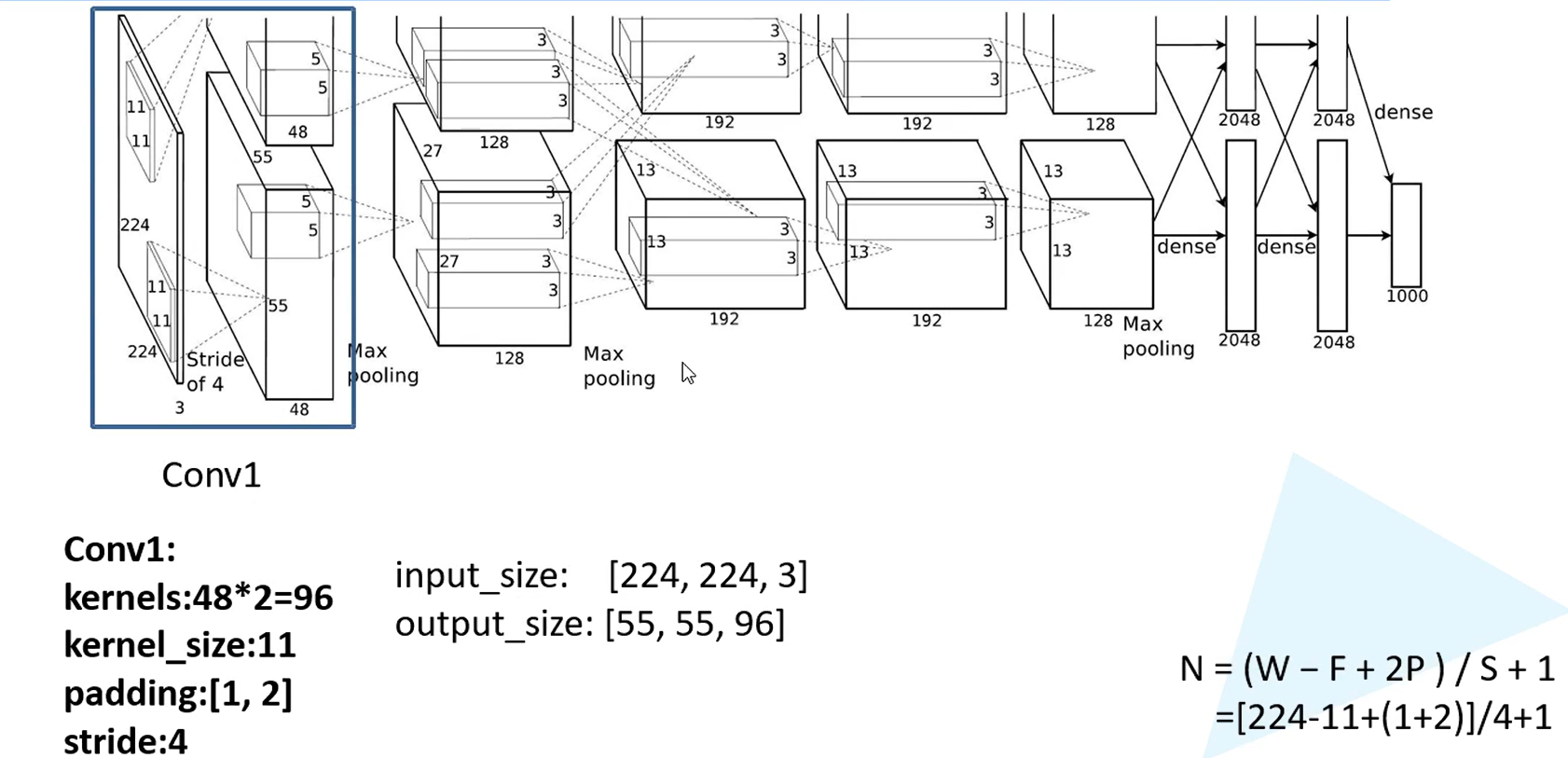
两个GPU跑,卷积核是48*2
padding [1,2] 是左边一列0,右边两列0,上边一行0,下面两行0
经卷积后的矩阵尺寸大小计算公式为:N = (W − F + 2P ) / S + 1
① 输入图片大小 W×W
② Filter大小 F×F
③ 步长 S
④ padding的像素数 P
第二层maxpool:

第三层卷积:
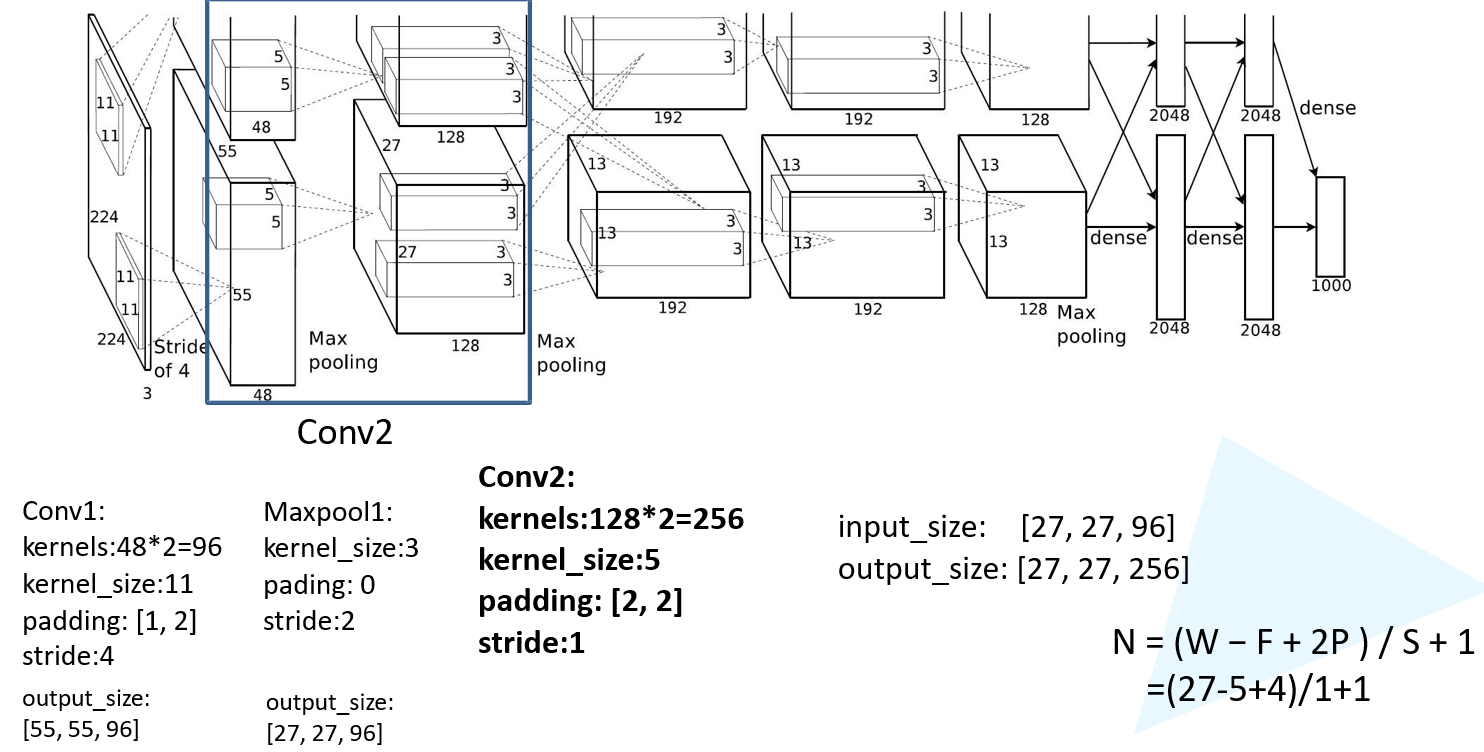
第四层maxpool:
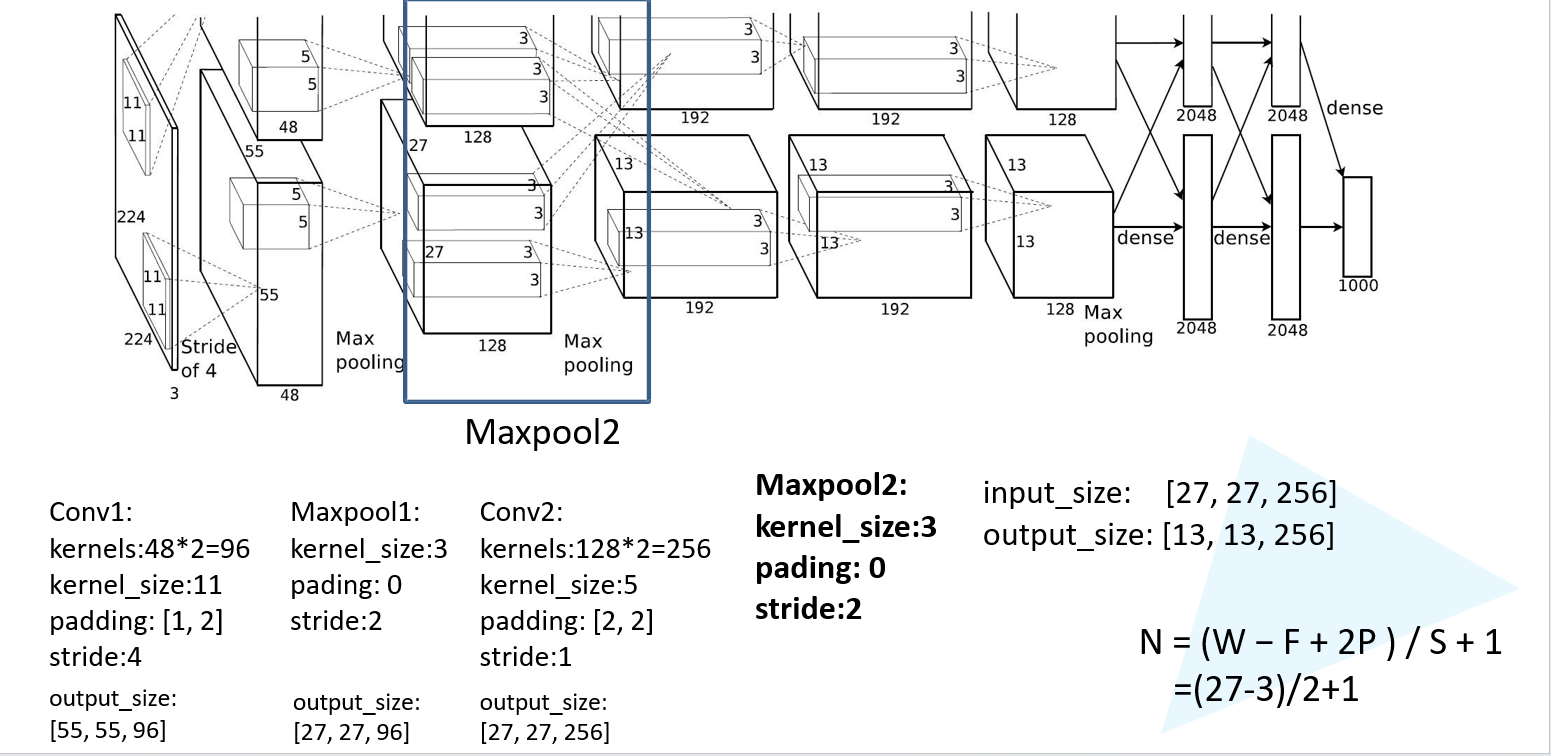
第五层卷积:

第六层卷积:
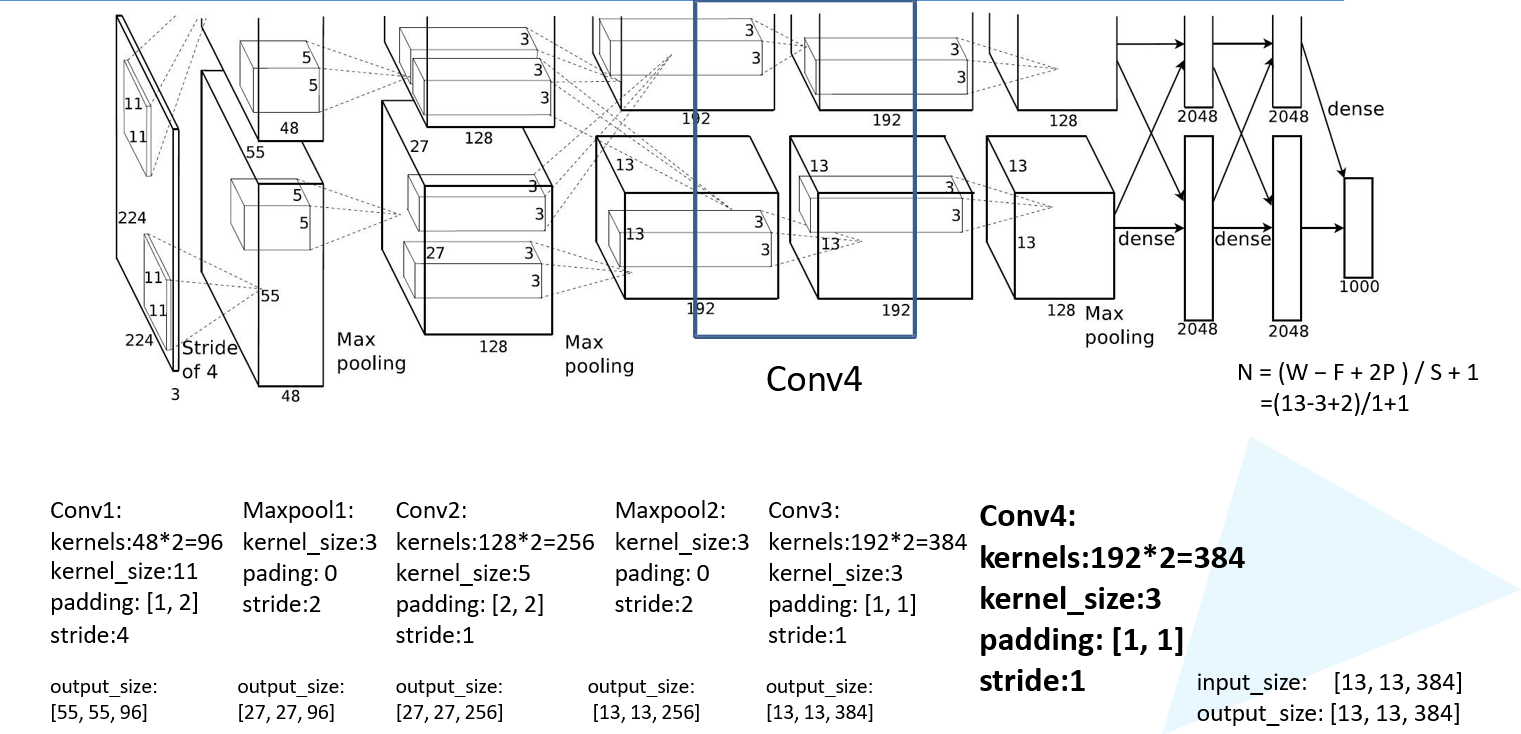
第七层卷积:

第八层maxpool:

1.2 AlexNet实现
模型实现
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 函数式和子类.
def AlexNet(im_height=224, im_width=224, num_classes=1000):
input_image = keras.layers.Input(shape=(im_height, im_width, 3), dtype=tf.float32)
# 手动padding
x = keras.layers.ZeroPadding2D(((1, 2), (1, 2)))(input_image)
x = keras.layers.Conv2D(48, kernel_size=11, strides=4, activation='relu')(x)
x = keras.layers.MaxPool2D(pool_size=3, strides=2)(x)
x = keras.layers.Conv2D(128, kernel_size=5, padding='same', activation='relu')(x)
x = keras.layers.MaxPool2D(pool_size=3, strides=2)(x)
x = keras.layers.Conv2D(192, kernel_size=3, padding='same', activation='relu')(x)
x = keras.layers.Conv2D(192, kernel_size=3, padding='same', activation='relu')(x)
x = keras.layers.Conv2D(128, kernel_size=3, padding='same', activation='relu')(x)
x = keras.layers.MaxPool2D(pool_size=3, strides=2)(x)
#全连接
# 前面不管几维,都变成2维
x = keras.layers.Flatten()(x)
x = keras.layers.Dropout(0.2)(x) #随机去掉20%神经元
x = keras.layers.Dense(2048, activation='relu')(x)
x = keras.layers.Dropout(0.2)(x) #随机去掉20%神经元
x = keras.layers.Dense(2048, activation='relu')(x)
x = keras.layers.Dense(num_classes)(x) #num_classes 最后输出类别
# 预测
predict = keras.layers.Softmax()(x)
model = keras.models.Model(inputs=input_image, outputs=predict)
return model数据准备
train_dir = './training/training/'
valid_dir = './validation/validation/'
# 图片数据生成器
train_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1. / 255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
vertical_flip = True,
fill_mode = 'nearest'
)
height = 224
width = 224
channels = 3
batch_size = 32
num_classes = 10
train_generator = train_datagen.flow_from_directory(train_dir,
target_size = (height, width),
batch_size = batch_size,
shuffle = True,
seed = 7,
class_mode = 'categorical')
valid_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1. / 255
)
valid_generator = valid_datagen.flow_from_directory(valid_dir,
target_size = (height, width),
batch_size = batch_size,
shuffle = True,
seed = 7,
class_mode = 'categorical')
print(train_generator.samples)
print(valid_generator.samples)训练
model = AlexNet(im_height=224, im_width=224, num_classes=10)
model.summary()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc'])
history = model.fit(train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=10,
validation_data=valid_generator,
validation_steps = valid_generator.samples // batch_size
)