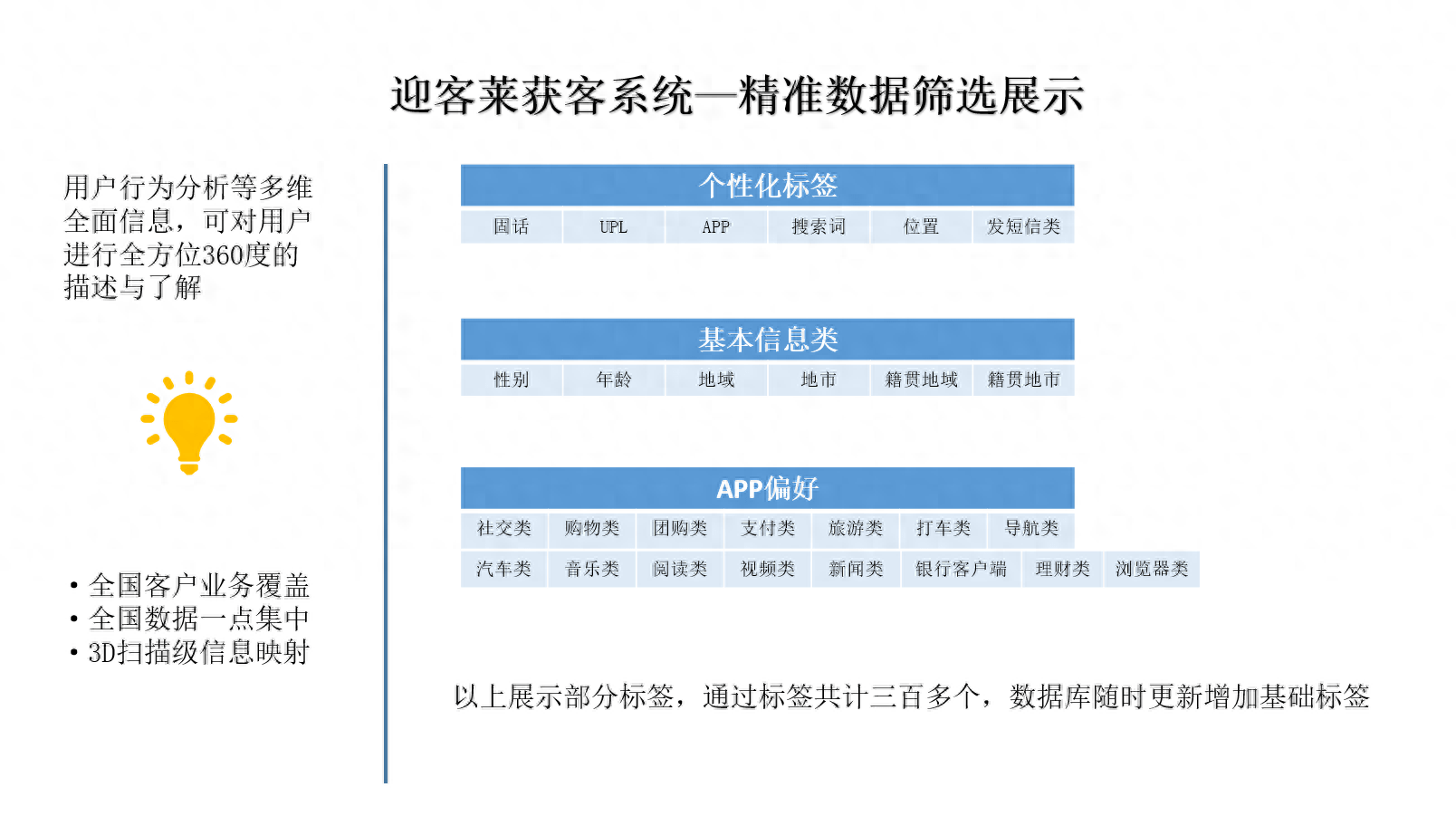
背景:
项目中有个数据量大小为5195 * 512 * 128float = 1.268G的显存,发现有个函数调用很耗时,函数里面就是对这个显存进行128个元素求和,得到一个5195 * 512的图像
分析
1. 为什么耗时
直观上感觉这个流程应该不怎么耗时才对,但是写了个demo测试发现
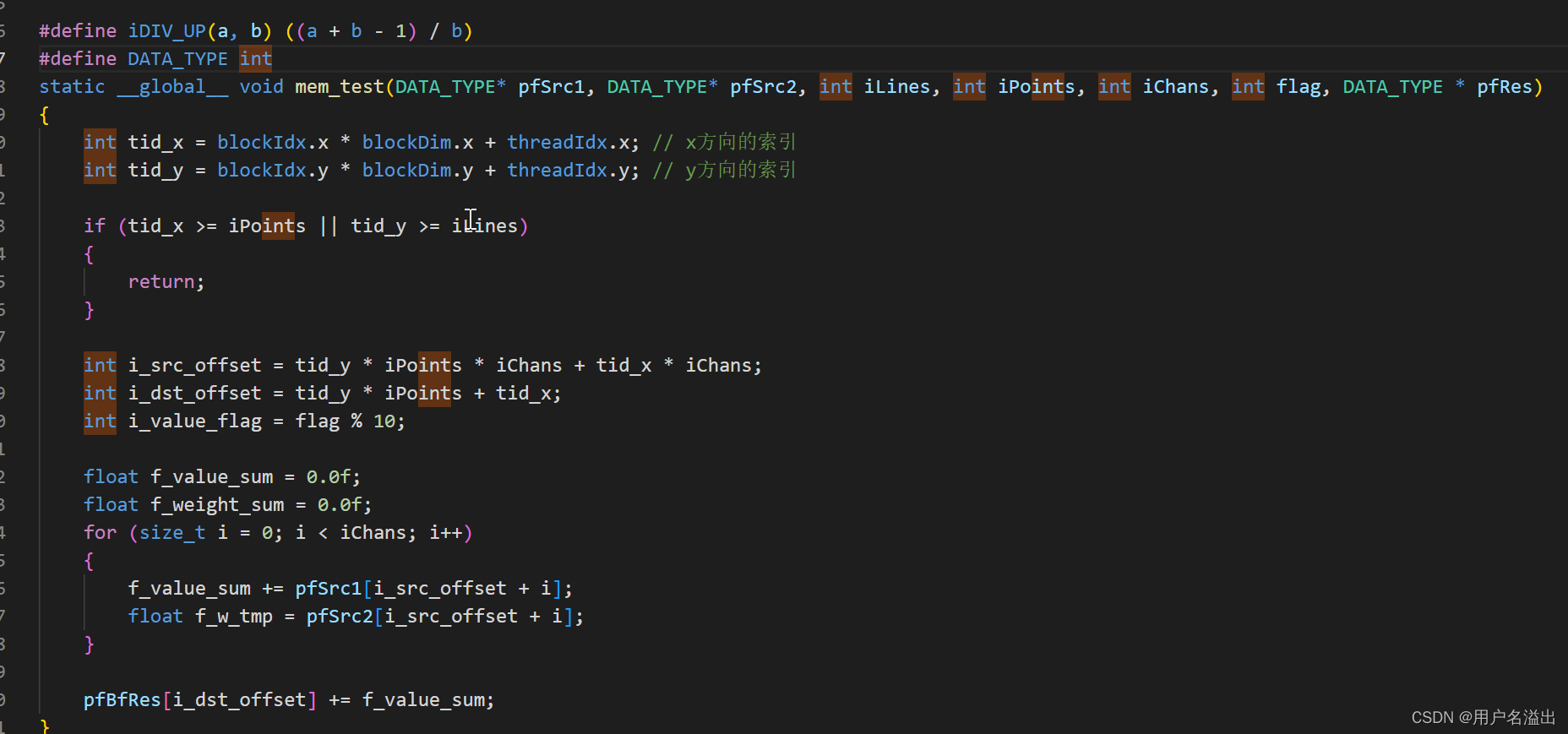
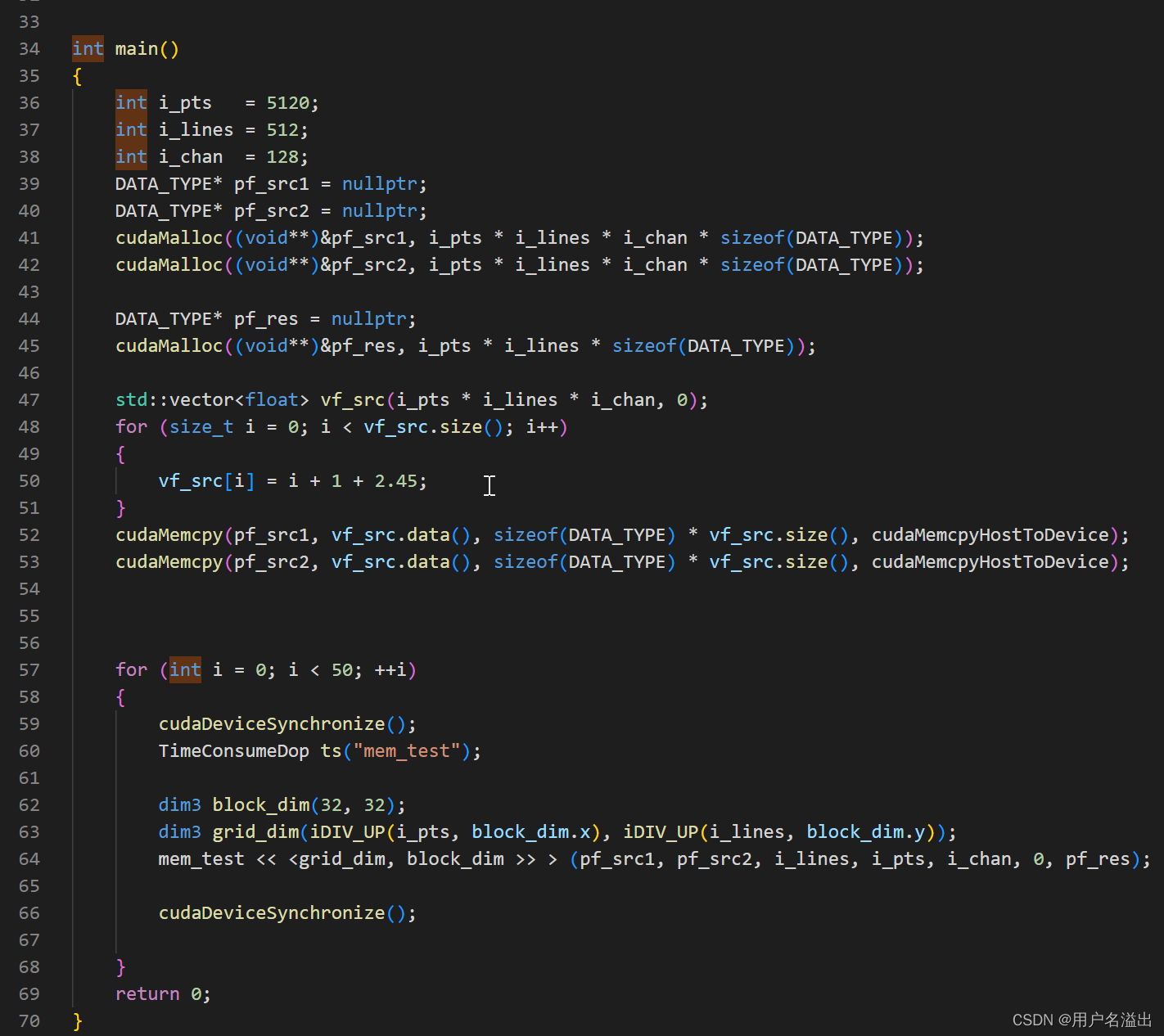
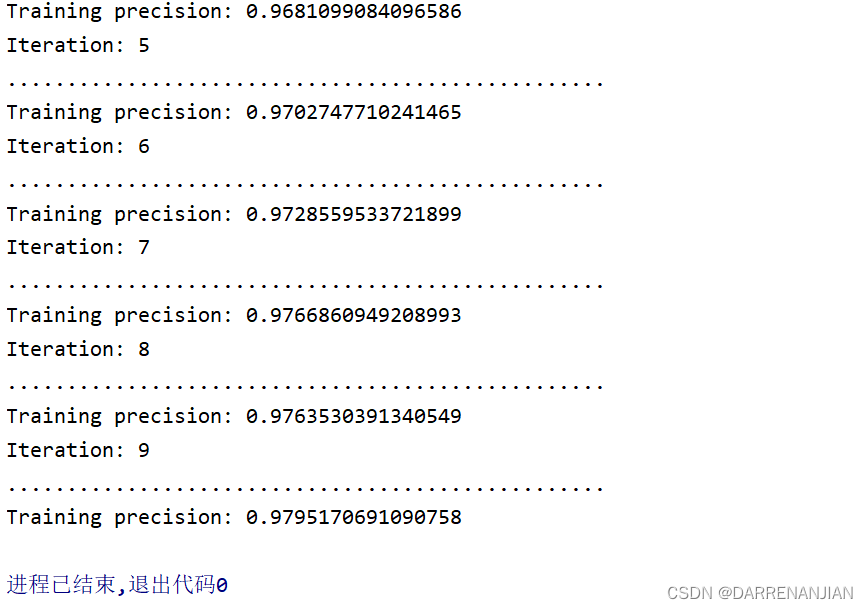
上面代码,统计耗时

需要消耗掉50ms左右(显卡是Quadro P2200)
太恐怖了
2.修改数据类型为int16_t
将数据类型修改为int16_t访问的显存大小降为0.6G左右
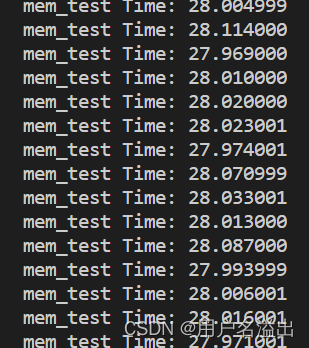
降低为上面结果
3.修改数据类型为int8_t
将数据类型修改为int8_t访问的显存大小降为0.3G左右

降低不再明显
3. 修改访问方式
由于显存是按照内存事务一次性加载的,如果按照上面代码进行访问,按照个人理解,32个线程一次加载的内存是不够用的,需要至少32次内存事务才能完成处理,尝试修改代码:
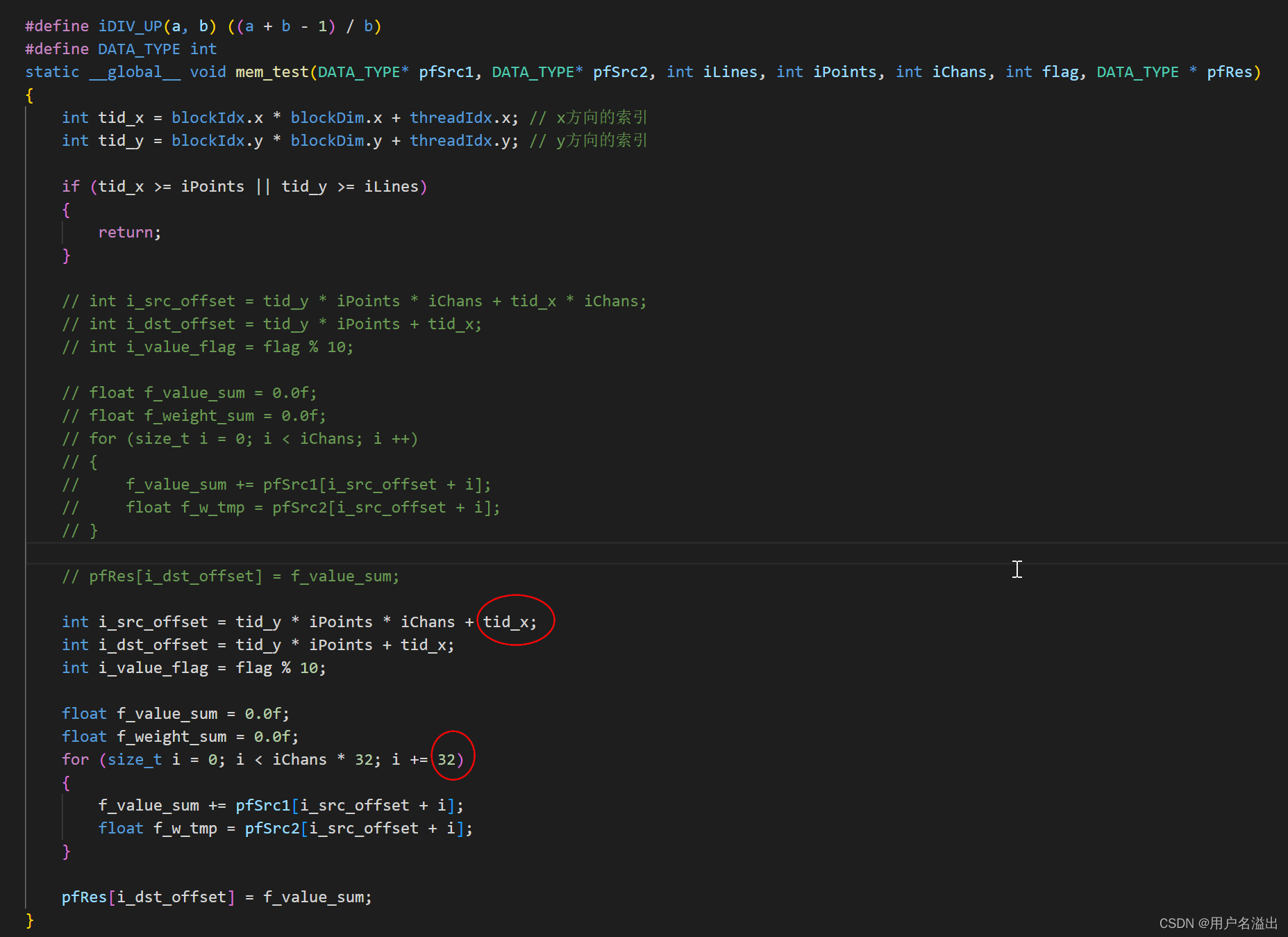
同样是int类型,耗时如下:
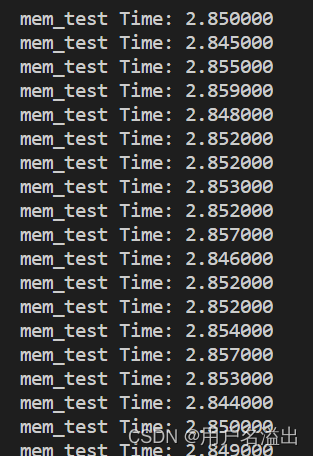
结论:
当cuda程序需要访问的显存过大时,将会出现耗时非常严重的问题
参考链接:
cuda 学习之内存层次结构_请说明 register,shared,global 以及 constant 四类 cuda 内 存_xukang95的博客-CSDN博客