前言
lambda表达式是C++11标准才支持的,有了它以后在一些地方进行使用会方便很多,尤其在一些需要仿函数的地方,lambda表达式完全可以替代它的功能。代码的可读性也会提高。
目录
1.lambda表达式
2.lambda表达式语法
3.函数对象和lambda表达式
1.lambda表达式
在C++98中如果想要对一个数据集合进行排序,可以使用std::sort的方法
//仿函数
template<class T>
struct Greater
{
bool operator()(const T& nums1,const T& nums2)
{
return nums1 > nums2;
}
};
//函数
bool FunGreater(const int&nums1,const int&nums2)
{
return nums1 > nums2;
}
void TestSort()
{
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
std::sort(array, array + sizeof(array)/sizeof(array[0]) );
//如果按照默认的方式进行排序那么排序的结果就是升序
//如果我们需要进行降序排列怎么办呢?
//这时候就需要用到仿函数了
//我们需要通过仿函数或者函数指针来改变排序的规则
for (auto& e : array)
cout << e << " ";
cout << endl;
//用仿函数生成函数对象
Greater<int> gr;
std::sort(array, array + sizeof(array) / sizeof(array[0]),gr);
for (auto& e : array)
cout << e << " ";
//用函数指针传参进行排序
std::sort(array, array + sizeof(array) / sizeof(array[0]), FunGreater);
//仿函数和函数指针的效果是相同的
}但是如果要排序的元素为自定义类型时,需要用户定义排序规则。
struct Goods
{
string _name;//名字
double _price;//价格
int _num;//数量
Goods(const char* str, double price,int num)
:_name(str)
,_price(price)
,_num(num)
{ }
};
void TestSort1()
{
vector<Goods> v1 = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
//现在需要对自定义类型进行排序
//如果按照_name排序我们需要实现至少两个仿函数
//按照_price排序也需要两个仿函数
//按照_num排序也需要两个仿函数
//这样的话就需要我们实现很多的仿函数,如果仿函数的命名风格不好的话,别人对于这些仿函是干什么的必然不好理解,从这里也可以看出好的命名风格也是很重要的
}现在需要对自定义类型进行排序,如果按照_name排序我们需要实现至少两个仿函数,按照_price排序也需要两个仿函数, 按照_num排序也需要两个仿函数, 这样的话就需要我们实现很多的仿函数,如果仿函数的命名风格不好的话,别人对于这些仿函是干什么的必然不好理解,从这里也可以看出好的命名风格也是很重要的。
struct Goods
{
string _name;//名字
double _price;//价格
int _num;//数量
Goods(const char* str, double price,int num)
:_name(str)
,_price(price)
,_num(num)
{ }
};
struct ComparePriceLess
{
bool operator()(const Goods &g1, const Goods &g2)
{
return g1._price < g2._price;
}
};
struct ComparePriceMore
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
struct CompareNumLess
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._num < g2._num;
}
};
struct CompareNumMore
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._num > g2._num;
}
};
struct CompareNameLess
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._name < g2._name;//string重载了operator>和operator<所以可以直接比较
}
};
struct CompareNameMore
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._name > g2._name;
}
};
void TestSort1()
{
vector<Goods> v1 = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
//现在需要对自定义类型进行排序
//如果按照_name排序我们需要实现至少两个仿函数
//按照_price排序也需要两个仿函数
//按照_num排序也需要两个仿函数
//这样的话就需要我们实现很多的仿函数,如果仿函数的命名风格不好的话,别人对于这些仿函是干什么的必然不好理解,从这里也可以看出好的命名风格也是很重要的
std::sort(v1.begin(), v1.end(), ComparePriceMore());
std::sort(v1.begin(), v1.end(), CompareNumMore());
std::sort(v1.begin(), v1.end(), CompareNameMore());
}
int main()
{
TestSort1();
return 0;
}为了提高代码的可读性,所以在这里引入了lambda表达式。
2.lambda表达式语法
上述的问题也可以使用lambda表达式来解决。
void TestSort2()
{
vector<Goods> v1 = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
std::sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) ->bool {return g1._name > g2._name;});
std::sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {return g1._num > g2._num;});
std::sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2)->bool {return g1._price > g2._price;});
}实际上我们可以看到lambda表达式就是匿名函数。
lambda表达式的语法:
lambda表达式书写格式:[ capture-list ]( parameters ) mutable -> return -type{statement}
1.lambda表达式各部分说明
[capture]:捕捉列表,该列表总是出现在lambda表达式的开头位置 ,编译器根据[]来判断接下来的代码是否为lambda表达式,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
[paremeters]:参数列表。与普通函数的参数列表一样,如果不需要参数传递,则可以连同()一起省略。
mutable:默认情况下,lambda函数的总是一个const函数,mutable可以取消其常属性。使用该修饰符时,参数列表不可以省略。(即使参数为空)
->returntype:返回值类型。用来追踪返回类型形式声明函数的返回值类型,若果没有返回值时该部分可以省略,返回值类型明确的情况下也可以省略,由编译器对返回值类型进行推导。
{statement}:函数体。该函数体内除了可以使用其参数外,还可以使用所捕获到的变量。
注意:
在lambda函数定义中,参数列表和返回值类型是可选部分,而捕捉列表和函数体可以为空。因此C++11最简单的lambda表达式为[]{};该lambda表达式不做任何事情。
int main()
{
//最简单的lambda表达式
[] {};//但是这个表达式没有意义
//省略了参数列表和返回值类型返回值类型由编译器推导为int
int a = 3,b = 4;
[=] {return a + b;};
//省略了返回值类型,无返回值类型
auto fun1 = [&] (int c){b = a + c;};//由auto自动推导的一个对象
fun1(10);
cout << b << endl;
int c = 0;
//各部分都很完善的lambda表达式
auto fun2 = [=, &b]()->int {return b += a + c;};
//复制捕捉x
int x = 10;
auto add_x = [x](int a)mutable ->int {x *= 2;return a + x;};
return 0;
}通过上述的例子可以看出实际上lambda表达式可以理解为无名函数,该函数无法直接调用,需要通过auto将其赋值给一个变量。
2.捕捉列表说明
捕捉列表描述了上下文中哪些数据可以被lambda表达式使用,以及使用的方式是传值还是传引用。
[val]:表示值传递捕获变量val。
[=]:表示值传递捕获所有父作用域中的变量(包括this)。
[&val]:表示引用捕获变量val。
[&]:表示引用捕获所有的变量(包括this)。
[this]:表示值传递的方式捕获this指针。
注意:
a.父作用域指包含lambda表达式的语句块
b.语法上捕捉列表由多个捕捉项组成,并以逗号分隔
比如:[=,&b,&b];以引用方式捕捉变量a和b,使用值捕捉的方式捕捉其它变量。
[&,a,this]:以值捕捉的方式捕捉a和this指针,以引用的捕捉方式捕捉其它的值。
c.捕捉列表不允许变量重复传递,否则就会导致编译错误
比如:[=,a];以值的方式捕捉所有变量,然后又捕捉a变量重复了。
d. 在块作用域以外的lambda函数的捕捉列表必须为空
e.在块作用域中的lambda表达式仅能捕捉父作用域中的局部变量,捕捉任何非此局部域的或者非局部变量都会导致编译报错
f.lambda表达式之间不能互相赋值,即使看起来类型相同。
void (*PF)();
int main()
{
auto f1 = [] {cout << "hello world" << endl;};
auto f2 = [] {cout << "hello world" << endl;};
//f1 = f2;//此处会编译失败,因为lambda表达式的底层编译器会将它替换成一个仿函数;
auto f3(f2);//允许构造拷贝一个新的副本
f3();
//可以将lambda表达式赋值给相同类型的指针
PF = f2;
PF();
return 0;
}
3.函数对象和lambda表达式
函数对象又叫做仿函数,可以像函数一样使用的对象,就是在类中重载了operator()运算符的类对象。
class Rate
{
public:
Rate(double rate)
:_rate(rate)
{}
double operator()(double year, double money)
{
return money * year * _rate;
}
private:
double _rate;
};
int main()
{
//函数对象
double rate = 0.90;
Rate r1(rate);
r1(10000, 2);
//lambda
auto r2 = [=](double money, double year)->double {return money * year * rate;};
r2(10000, 2);
return 0;
}从使用方来看lambda表达式和函数对象完全一样,函数对象将rate作为其成员变量,定义时给初始值就好了,lambda表达式通过捕捉列表来对rate进行捕捉。
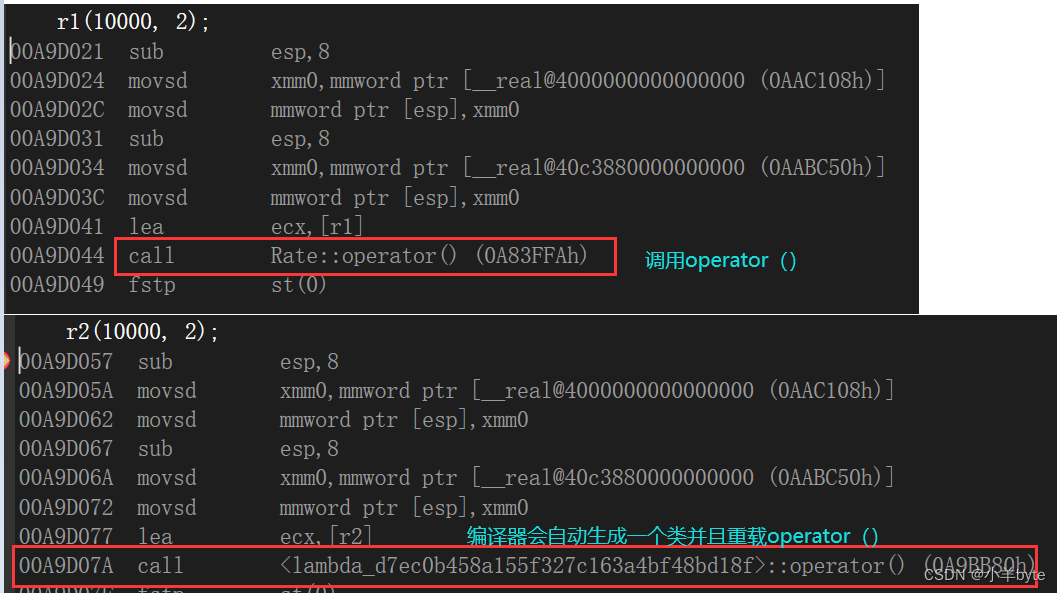
实际上在底层编译器对lambda表达式的处理是完全按照函数对象进行处理的,即如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载operator()。 调用lambda表达式时,编译器会给它起一个名字lambda_uuid,(唯一的名字,然后去调用它)。