一、单Master集群
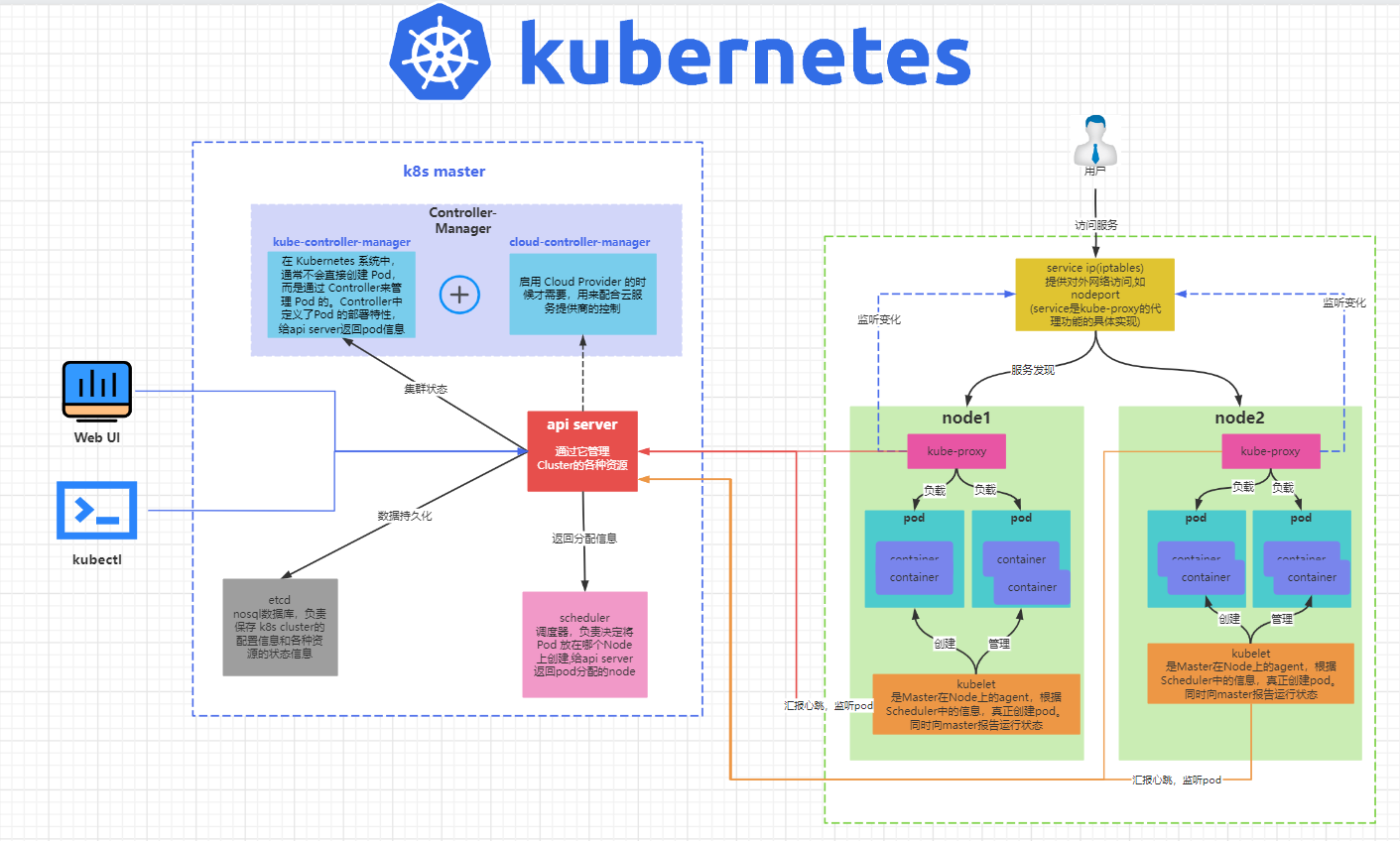
k8s 集群是由一组运行 k8s 的节点组成的,节点可以是物理机、虚拟机或者云服务器。k8s 集群中的节点分为两种角色:master 和 node。
- master 节点:master 节点负责控制和管理整个集群,它运行着一些关键的组件,如 kube-apiserver、kube-scheduler、kube-controller-manager 等。master 节点可以有一个或多个,如果有多个 master 节点,那么它们之间需要通过 etcd 这个分布式键值存储来保持数据的一致性。
- node 节点:node 节点是承载用户应用的工作节点,它运行着一些必要的组件,如 kubelet、kube-proxy、container runtime 等。node 节点可以有一个或多个,如果有多个 node 节点,那么它们之间需要通过网络插件来实现通信和路由。
一般情况下我们会搭建单master多node集群。它是一种常见的 k8s 集群架构,它只有一个 master 节点和多个 node 节点。这种架构的优点是简单易搭建,适合用于学习和测试 k8s 的功能和特性。这种架构的缺点是 master 节点成为了单点故障,如果 master 节点出现问题,那么整个集群就无法正常工作。
搭建 k8s 单 master 多 node 集群有多种方法,根据不同的需求和场景,可以选择合适的方式来搭建和运维node集群。一般来说,有以下几种常见的方式:
- 使用kubeadm:这是一种使用官方提供的工具kubeadm来快速创建和管理node集群的方式。kubeadm可以自动安装和配置node节点上所需的组件,如kubelet、kube-proxy、容器运行时等。这种方式适用于学习和测试目的,或者简单的生产环境。
- 使用kops:这是一种使用开源工具kops来在云服务商(如AWS、GCP等)上创建和管理node集群的方式。kops可以自动创建和配置云资源,如虚拟机、网络、存储等,并安装和配置node节点上所需的组件。这种方式适用于在云端部署高可用和可扩展的node集群。
- 使用其他工具或平台:这是一种使用其他第三方提供的工具或平台来创建和管理node集群的方式。例如,你可以使用Ansible、Terraform、Rancher等工具来自动化和定制node集群的创建和配置过程。或者,你可以使用云服务商提供的托管服务(如EKS、GKE、AKS等)来直接创建和管理node集群。这种方式适用于不同的需求和偏好,但可能需要更多的学习和调试成本。
二、多Master集群
通常情况下如果只有一个master节点,那么一旦它出现故障或者不可用,那么整个集群就会失去控制,无法进行任何操作。因此,为了保证集群的高可用性,需要使用多个master节点来构建master集群。多master集群可以分为应用集群与存储集群。应用集群主要是apiserver、scheduler、controller-manager的集群它们可以是单独的节点实现负载均衡集群,而etcd可以实现多节点的高可用集群。其中etcd高可以集群也可以分为内置集群与外部集群的方式。以下就具体的介绍:
1、应用负载均衡集群
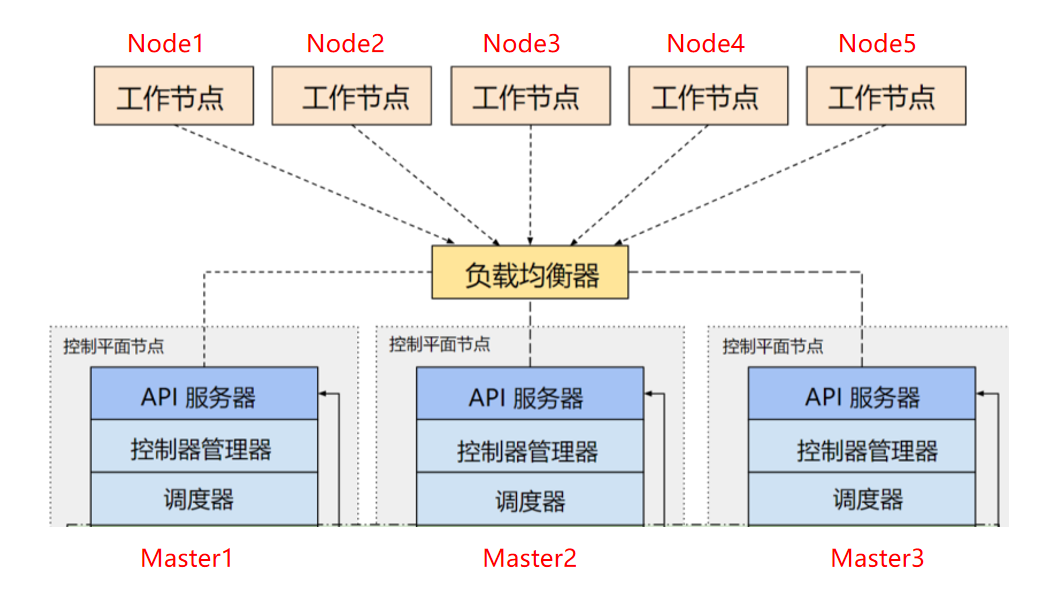
kubernetes多master集群是指使用多个master节点来提高集群的可用性和容错性的方案。master节点是负责控制和管理集群中的资源和服务的节点,它运行着以下组件:
- kube-apiserver:提供了HTTP REST接口的关键服务进程,是集群中所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。
- kube-scheduler:负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。
- kube-controller-manager:集群中所有资源对象的自动化控制中心,可以将其理解为资源对象的“大总管”。
实现kubernetes master集群有多种方式,根据不同的需求和场景,可以选择合适的方式来搭建和运维master集群。一般来说,根据实现方式,负载均衡集群可以分为以下几种方案:
- 硬件负载均衡:硬件负载均衡是使用专门的硬件设备来实现负载均衡的方案,如 F5、Cisco 等。硬件负载均衡的优点是性能高、稳定性强,缺点是成本高、扩展性差。
- 软件负载均衡:软件负载均衡是使用普通的服务器和软件来实现负载均衡的方案,如 Nginx、HAProxy 等。软件负载均衡的优点是成本低、扩展性好,缺点是性能低、稳定性差。
- 混合负载均衡:混合负载均衡是结合硬件和软件来实现负载均衡的方案,如使用硬件设备作为全局入口,使用软件作为局部分发。混合负载均衡的优点是兼顾了性能和成本,缺点是复杂度高、维护难。
2、存储高可用集群
etcd:分布式键值存储系统,用于保存集群中所有资源对象的状态和元数据。
k8s配置高可用(HA)Kubernetes etcd集群。
你可以设置 以下两种HA 集群:
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
2.1、堆叠(Stacked)etcd 拓扑--内置etcd集群
堆叠(Stacked)HA集群是一种这样的拓扑,其中 etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行。
每个控制平面节点运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 kube-apiserver 使用负载均衡器暴露给工作节点。
每个控制平面节点创建一个本地etcd成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。 这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群, 设置起来更简单,而且更易于副本管理。
然而,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则etcd 成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。
因此,你应该为 HA 集群运行至少三个堆叠的控制平面节点。
这是 kubeadm 中的默认拓扑。当使用 kubeadm init 和 kubeadm join --control-plane 时, 在控制平面节点上会自动创建本地 etcd 成员。

2.2、外部 etcd 拓扑--外部etcd集群
具有外部 etcd 的 HA 集群是一种这样的拓扑, 其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。
就像堆叠的 etcd 拓扑一样,外部 etcd 拓扑中的每个控制平面节点都会运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 同样,kube-apiserver 使用负载均衡器暴露给工作节点。但是 etcd 成员在不同的主机上运行, 每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信。
这种拓扑结构解耦了控制平面和 etcd 成员。因此它提供了一种 HA 设置, 其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余。
但此拓扑需要两倍于堆叠 HA 拓扑的主机数量。 具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机。

如果文章对你有帮助,欢迎关注+点赞!