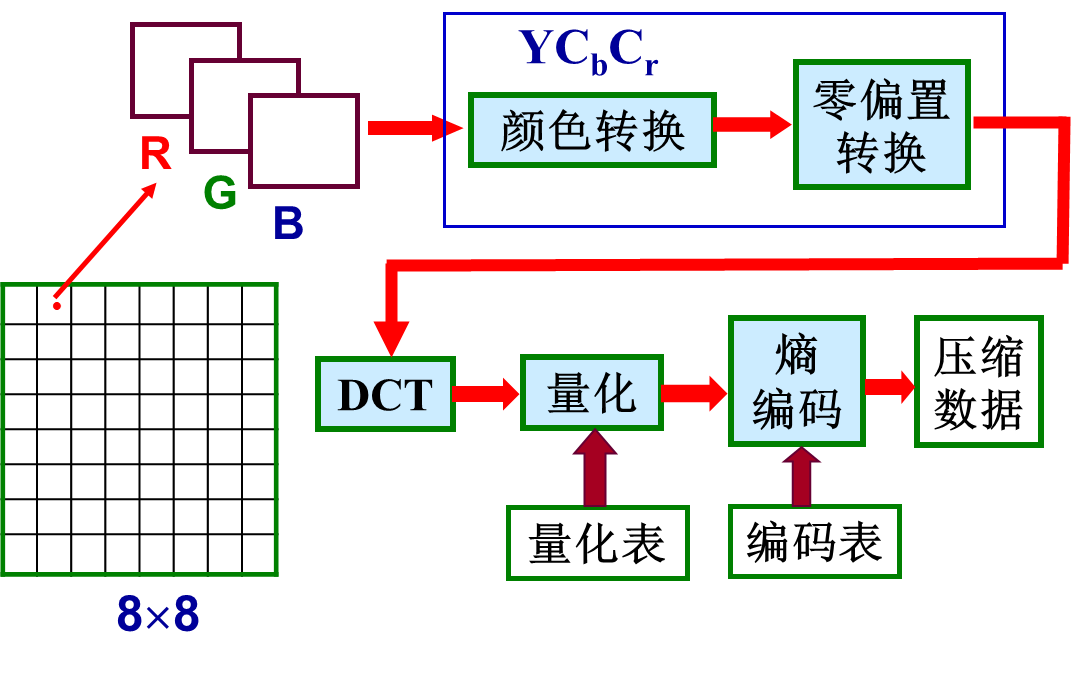
一、数据集
MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。
MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的灰度图像,每张图像包含一个手写数字。

1.1 准备数据
将数据集分为训练集、验证集和测试集
#训练集有60000张图片,前5000张图片作为验证集,后55000作为训练集
1. `x_train_all` 和 `y_train_all`:
- `x_train_all` 包含了完整的训练数据集的图像数据,这些图像用于训练深度学习模型。
- `y_train_all` 包含了完整的训练数据集的标签,即与 `x_train_all` 中的图像相对应的类别标签。
2. `x_test` 和 `y_test`:
- `x_test` 包含了测试数据集的图像数据,这些图像用于评估深度学习模型的性能。
- `y_test` 包含了测试数据集的标签,即与 `x_test` 中的图像相对应的类别标签。
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)1.2 标准化
# 标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)1.3 数据集
def make_dataset(data, target, epochs, batch_size, shuffle=True):
dataset = tf.data.Dataset.from_tensor_slices((data, target))
if shuffle:
dataset = dataset.shuffle(10000)
dataset = dataset.repeat(epochs).batch(batch_size).prefetch(50)
return dataset
batch_size = 64
epochs = 20
train_dataset = make_dataset(x_train_scaled, y_train, epochs, batch_size)1.4 搭建模型
model = keras.models.Sequential()
# 卷积
model.add(keras.layers.Conv2D(filters = 32,
kernel_size = 3,
padding = 'same',
activation='relu',
# batch_size, height, width, channels
input_shape=(28, 28, 1))) # (28, 28, 32)
model.add(keras.layers.Conv2D(filters = 32,
kernel_size = 3,
padding = 'same',
activation='relu'))
# 池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)
model.add(keras.layers.Conv2D(filters = 64,
kernel_size = 3,
padding = 'same',
activation='relu')) # (14, 14, 64)
model.add(keras.layers.Conv2D(filters = 64,
kernel_size = 3,
padding = 'same',
activation='relu'))
# 池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)
model.add(keras.layers.Conv2D(filters = 128,
kernel_size = 3,
padding = 'same',
activation='relu')) # (7, 7, 128)
model.add(keras.layers.Conv2D(filters = 128,
kernel_size = 3,
padding = 'same',
activation='relu')) # (7, 7, 128)
# 池化, 向下取整
model.add(keras.layers.MaxPooling2D()) # (3, 3, 128)
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.Dense(256, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print(model.summary())keras.models.Sequential()`是使用 Keras 构建神经网络模型的开始。`keras.models.Sequential()` 创建了一个 Sequential 模型对象,这是 Keras 中的一种常见模型类型。Sequential 模型是一个线性的、层叠的神经网络模型,适用于顺序层的堆叠,其中每一层都是依次添加到模型中。
一旦创建了 Sequential 模型,你可以使用 `.add()` 方法来逐层添加神经网络层,从输入层到输出层。每个层都可以通过实例化 Keras 中的层类来创建,例如
`keras.layers.Dense` 用于全连接层,
`keras.layers.Conv2D` 用于卷积层等。
以下是一个简单的例子,演示如何使用 Sequential 模型创建一个简单的前馈神经网络:
from tensorflow import keras # 创建一个 Sequential 模型 model = keras.models.Sequential() # 添加输入层和第一个隐藏层 model.add(keras.layers.Input(shape=(input_shape,))) # 输入层,input_shape 根据你的数据维度定义 model.add(keras.layers.Dense(units=128, activation='relu')) # 隐藏层1 # 添加第二个隐藏层 model.add(keras.layers.Dense(units=64, activation='relu')) # 隐藏层2 # 添加输出层 model.add(keras.layers.Dense(units=num_classes, activation='softmax')) # 输出层,num_classes 是输出类别的数量 # 编译模型 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])上面的代码创建了一个具有两个隐藏层和一个输出层的前馈神经网络模型,并使用了 ReLU 激活函数和 softmax 激活函数。这只是一个简单的示例,你可以根据你的任务和数据来构建更复杂的模型。一旦模型构建完成,你可以使用 `.fit()` 方法来训练模型。
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
是 Keras 中用于编译深度学习模型的代码,它设置了模型的损失函数、优化器和评估指标。让我为你解释每个参数的含义:
- `loss='sparse_categorical_crossentropy'`: 这里设置了模型的损失函数。`sparse_categorical_crossentropy` 是一种用于多类别分类问题的损失函数。它适用于目标变量是整数形式(类别标签)的情况,而不需要将目标变量进行独热编码(one-hot encoding)。模型的目标是最小化这个损失函数,从而使预测结果尽可能接近真实标签。
- `optimizer='adam'`: 这里设置了优化器,用于模型的参数更新。`'adam'` 是一种常用的优化算法,它基于梯度下降的方法,具有自适应学习率和动量的特性,通常在深度学习中表现良好。优化器的作用是最小化损失函数,从而调整模型的权重和参数以使模型更好地拟合数据。
- `metrics=['accuracy']`: 这里设置了评估指标,用于在模型训练期间监测模型性能。
`['accuracy']` 表示模型在训练期间将计算并输出准确度(accuracy),即正确分类的样本数与总样本数的比率。准确度通常用于分类问题的性能评估。
一旦模型编译完成,你可以使用 `model.fit()` 方法来训练模型,该方法会使用上述设置的损失函数、优化器和评估指标来进行训练。例如:
```python
model.fit(x_train, y_train, epochs=10, validation_data=(x_valid, y_valid))
```
1.5 train
eval_dataset = make_dataset(x_valid_scaled, y_valid, epochs=1, batch_size=32, shuffle=False)
history = model.fit(train_dataset,
steps_per_epoch=x_train_scaled.shape[0] // batch_size,
epochs=10,
validation_data=eval_dataset)
1.6 模型评估
model.evaluate(eval_dataset)
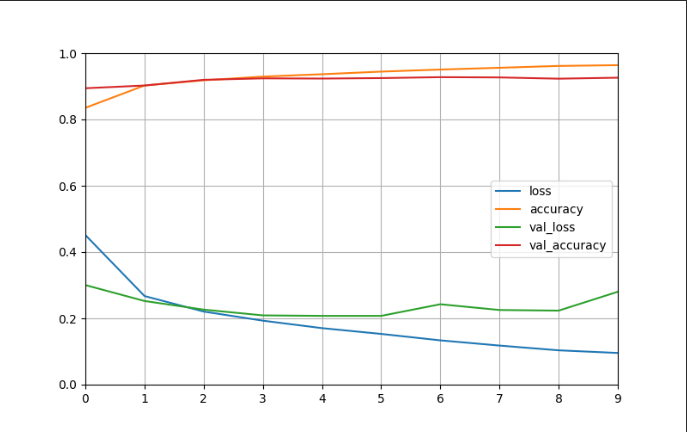
1.7 可视化
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)