对事件进行采样,然后根据采样频率,评估各个函数的调用频率。可以用来分析CPU cache,CPU迁移,指令周期等各种硬件事件,他也可以对感兴趣的事件进行动态追踪。
效果:
cat available_events | grep receive

perf list | grep receive
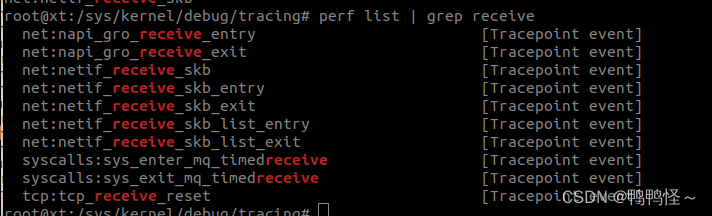
两者效果相同,但是实际使用perf支持的事件比ftrace多一倍左右
perf probe
perf probe --add do_sys_open //添加一个probe event
perf probe --del probe:do_sys_open //删除一个probe event
例子:perf record -e probe:do_sys_open -aR sleep 10
perf stat
perf stat ./test
task-clock:用于执行程序的cpu时间;
context-switches:程序在运行过程中经历的上下文切换次数;
page-faults:进程运行过程中产生的缺页次数;
cpu-migrations:程序在运行过程中发生的CPU迁移次数,即被调度器从一个CPU转移到另外一个CPU上运行;
instructions:该进程在这段时间内完成的CPU指令数;
cycles:CPU时钟周期;
perf top
当前实时查看当前系统进程函数占用情况

#include <stdio.h>
#include <math.h>
#include <sys/types.h>
#include <unistd.h>
void for_loop()
{
for (int i = 0; i < 1000; i++)
{
for (int j = 0; j < 10000; j++)
{
int x = sin(i) + cos(j);
}
}
}
void loopsmall()
{
for (int i = 0; i < 10; i++)
{
for_loop();
}
}
void loopbig()
{
for (int i = 0; i < 100; i++)
{
for_loop();
}
}
int main()
{
printf("pid=%d\n", getpid());
loopbig();
loopsmall();
return 0;
}
perf record
运行命令并保存profile到perf.data
perf record -p 1761 -a -g -F 99 -- sleep 10
或者
perf record -g -e cpu-clock ./test
-F :采样频率 --99
-g :启用调用图(堆栈链/回溯)记录
-e :指定event,默认是cpu 周期数
-a:从所有cpu 上采集
-p:pid --1256


perf report
从perf.data读取并且显示profile
perf script
从perf.data读取并且显示详细的采样数据
perf kmem 跟踪、测量内核内存属性
record :记录kmem event
stat : 报告内核内存统计信息
--slab :记录slab申请器的event;--page :记录page申请的event
perf mem 分析内存访问

perf lock 分析锁性能
perf kvm 针对kvm虚拟化分析
perf sched 分析内核调度器性能
record:采集和记录scheduling events
script:报告采集到的事件
latency : 报告每个任务的调度延迟和进程的进程的其他调度属性
timehist :提供调度进度的分析报告
perf sched record -p {进程号} -- sleep 10
实践:
perf probe -- add do_sys_open

perf record -e probe:do_sys_open -aR sleep 1

perf script

perf probe --del probe:do_sys_open

simpleperf(安卓)
需要下载源代码,然后在源代码的目录下操作
方法一:
1.simpleperf record -g -p 2684--duration 10 -f 12500 --call-graph fp -o /data/perf.data
2.system/extras/simpleperf/scripts下面有脚本可以解析
3.python3.8 ./report_html.py -i ./perf.data
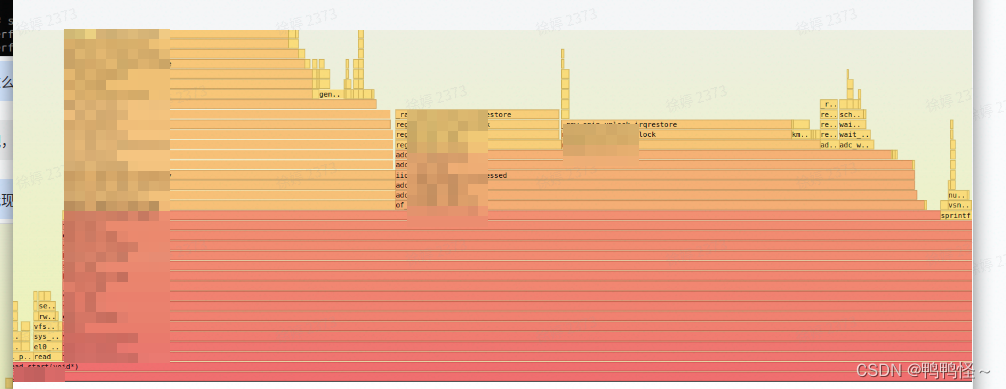
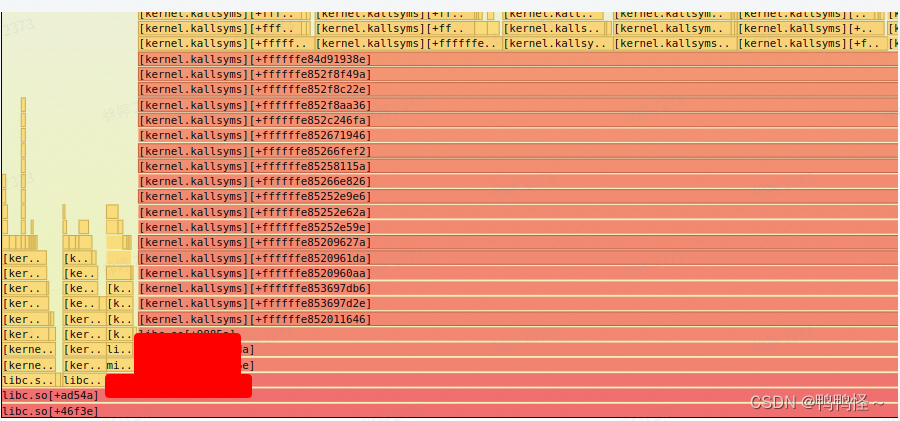
后来有的平台抓出来成这样了,可能是缺少符号表
方法2:
simpleperf record -p 进程号 -g --duration 10
simpleperf report -g -o out.perf