目录
一.引言
二.模型探索
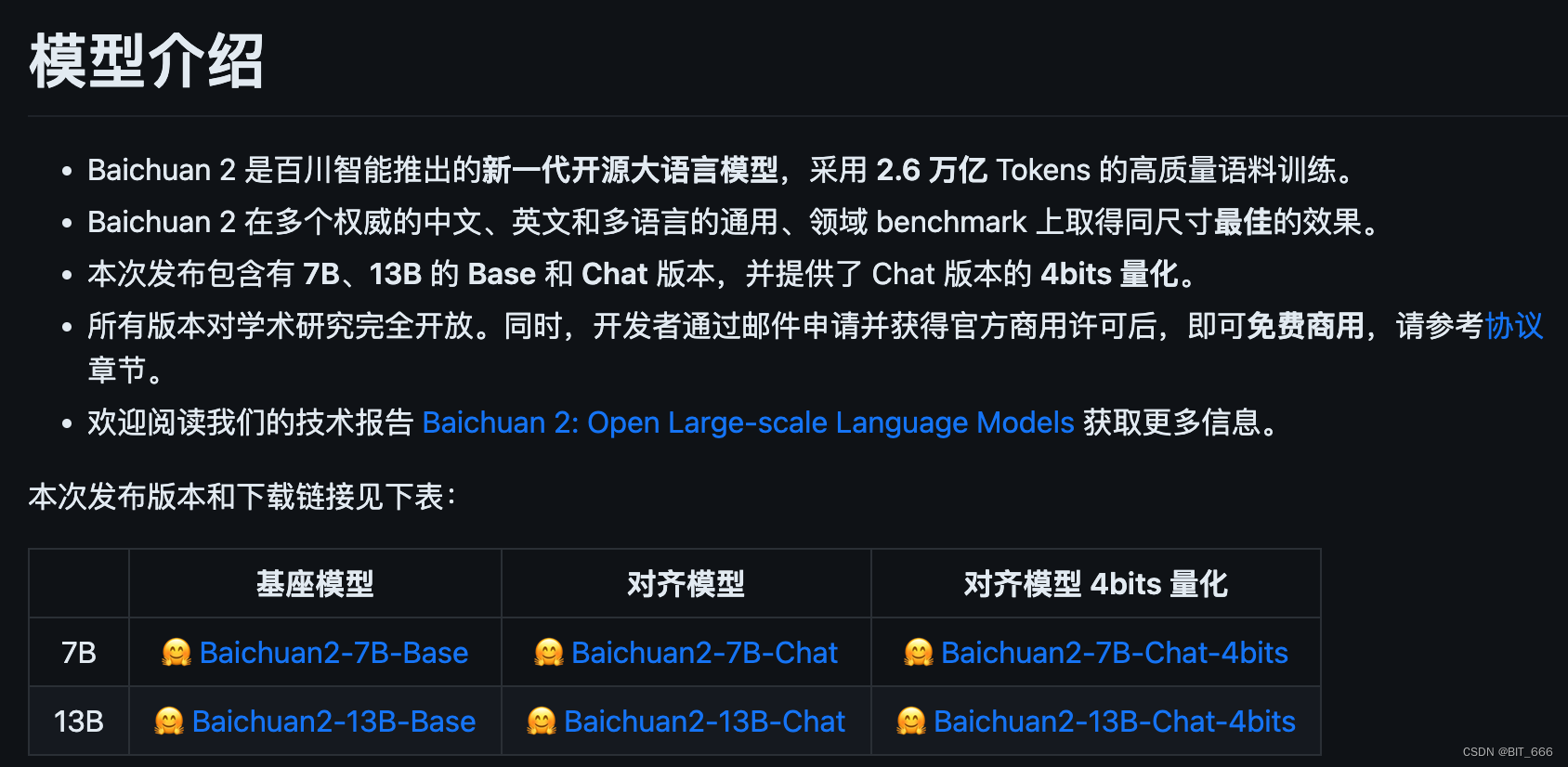
1.模型下载
2.模型结构
◆ Baichuan-2-13B 结构
3.模型测试
◆ Baichuan-2-13B Chat 推理
◆ Baichuan-2-13B 显存
4.模型量化
◆ 在线量化
◆ 离线量化
◆ 量化效果
5.模型迁移
三.总结
一.引言
昨天百川新推出了 Baichuan 7B、13B 的最新模型 Baichuan2。
根据官方介绍,Baichuan2 主要采用了新的高质量语料训练,在同尺寸模型上取得最佳的效果,以通用领域为基准做到了除 GPT-4 外的最佳,相比前面的 Baichuan-13B 也有十足的进步。
二.模型探索
1.模型下载
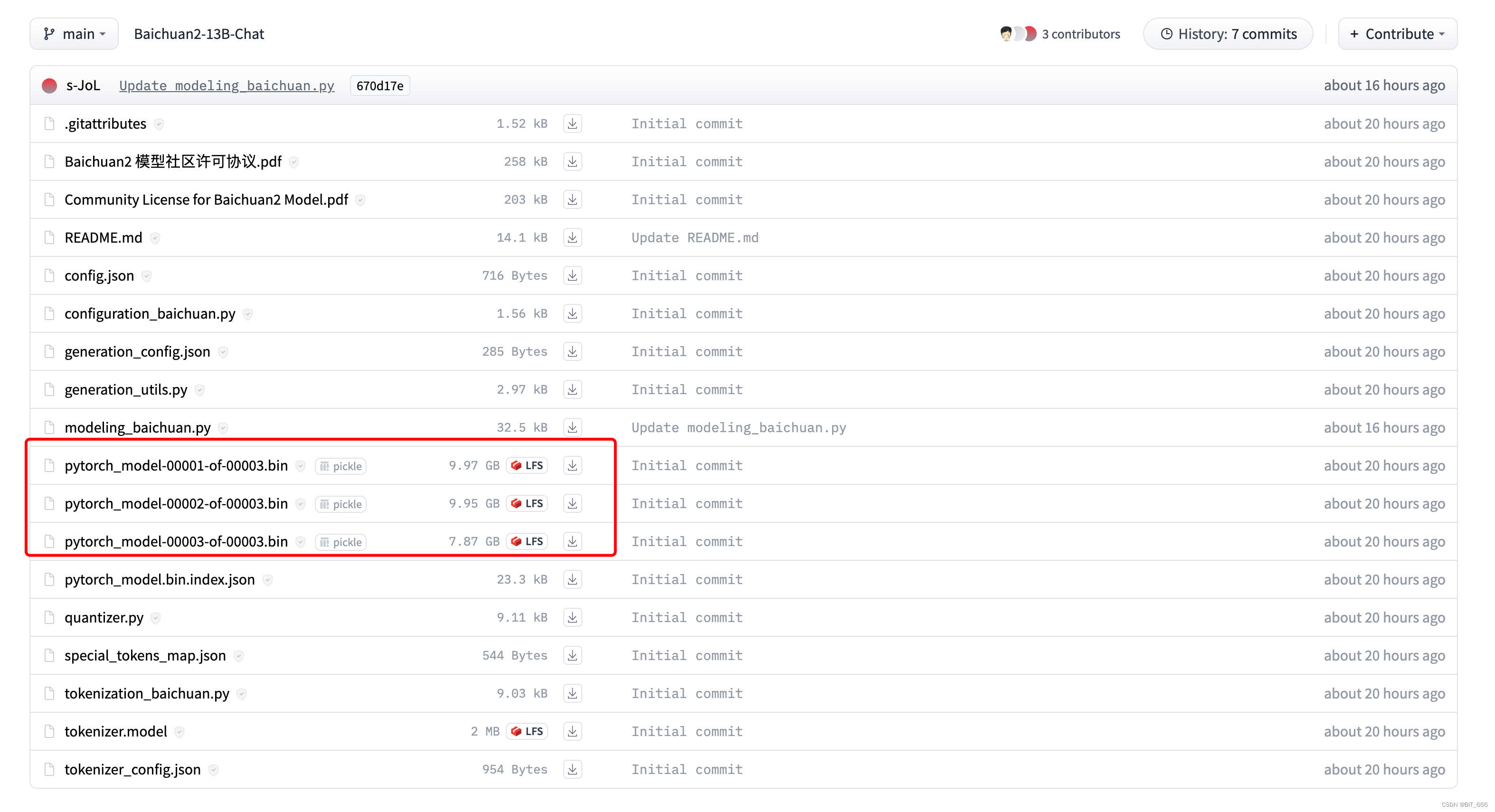
模型出来博主也是第一时间下载了 Baichuan-13B-chat 进行体验,链接:Baichuan-13B-chat

可以看到好多烙铁已经先我一步了,模型 bin 文件大小相较于 Baichuan-13B-chat 多了大概 3G,之前用 V100-32G 单卡是可以跑起来 Baichuan 的,不知道更新之后还行不行。
2.模型结构
◆ Baichuan-1-13B 结构
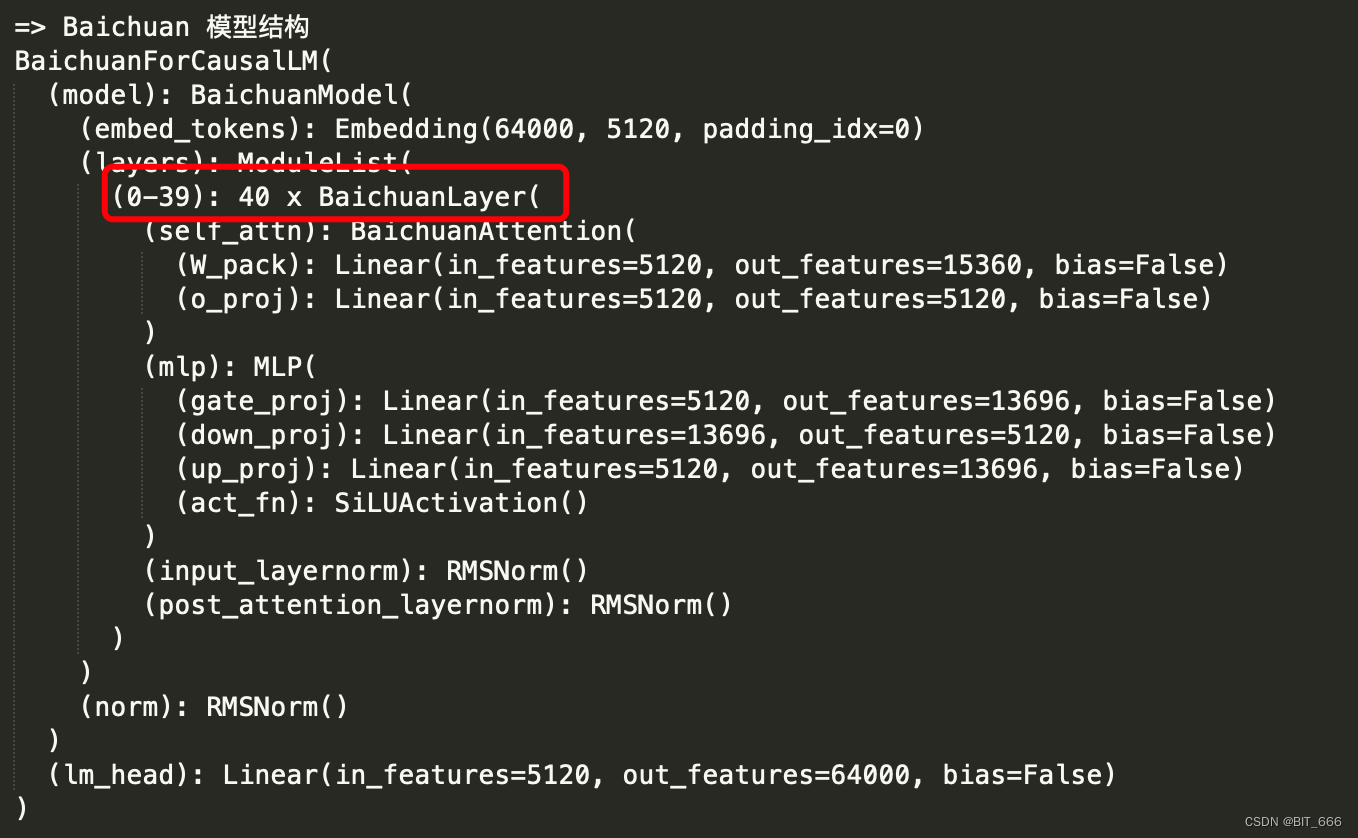
可以看到 Baichuan-1-13B 共堆叠了 40 个模块,其中包含 sele_attn 和 mlp,最前和最后分别是一个 Embedding 层和 lm_head 层,从这两个层也可以看出 Baichuan 的向量维度为 5120,共包含 64000 个输出 token 类型。
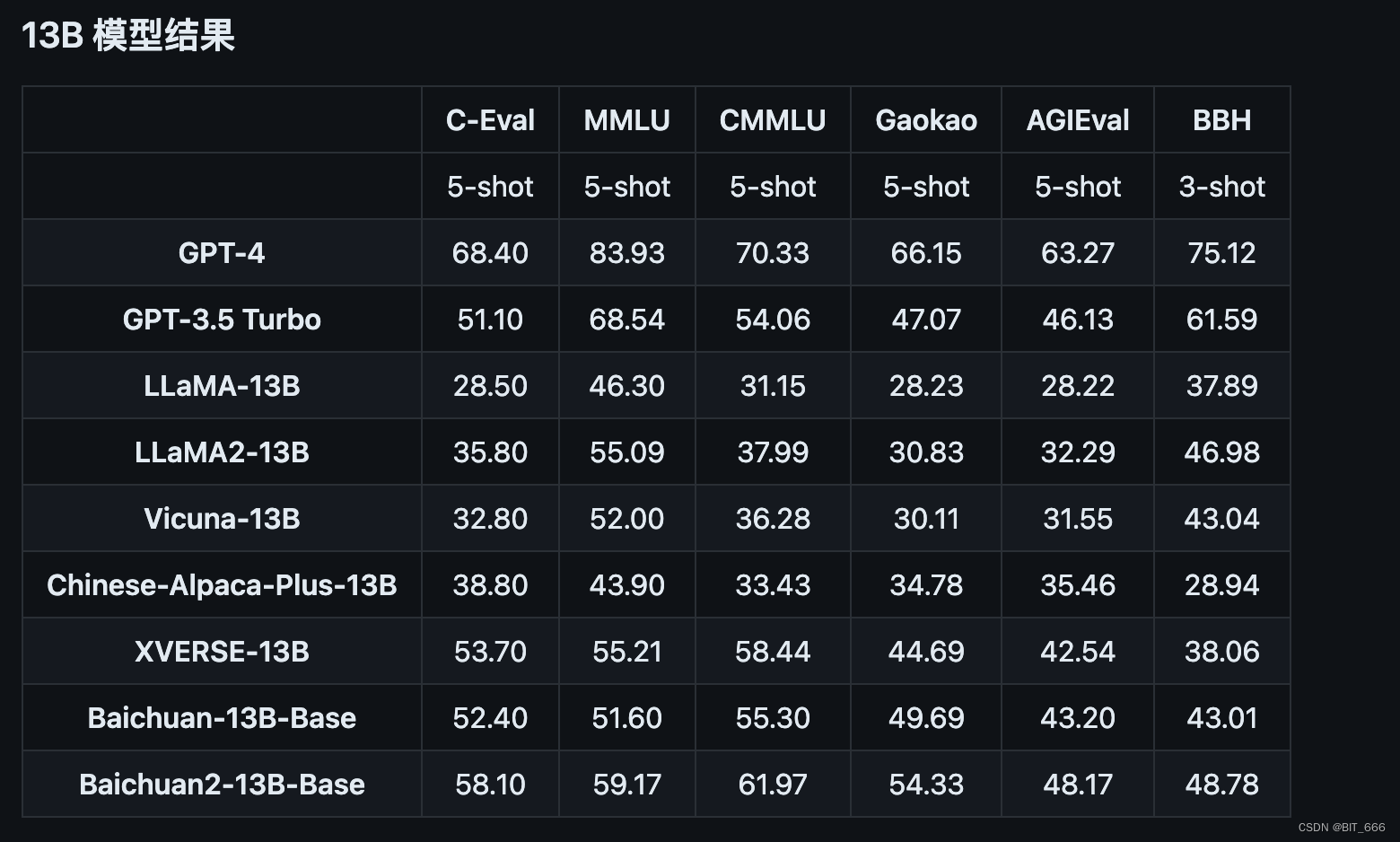
◆ Baichuan-2-13B 结构

相比 Baichuan-1-13B,模型整体结构未改变,还是 Embedding + 40 x Module 的模型堆叠且 embedding 维度保持 5120,区别是 Embedding 支持的 Token 数 125696 大于第一代的 64000,其次 lm_head 也从 Linear 变成 NormHead。
3.模型测试
◆ Baichuan-2-13B Chat 推理
下面我们把模型跑起来看看,直接拿官方给的 demo 试试:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
path='/data2/models/Baichuan2-13B'
tokenizer = AutoTokenizer.from_pretrained(path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(path)
messages = []
messages.append({"role": "user", "content": "解释一下“温故而知新”"})
response = model.chat(tokenizer, messages)
print(response)浅试下 chat 的效果:
==>
"温故而知新"是一句中国古代的格言,出自《论语·为政》篇。这句话的意思是:通过回顾过去的学习和经验,可以从中获得新的理解和启示。具体来说,它鼓励人们在学习和生活中要经常回顾和总结过去的知识、经验和教训,从而不断地提高自己,实现自我成长和提升。同时,这也强调了在学习过程中要注重知识的巩固和更新,以适应不断变化的环境和需求。
==>
"温故而知新"是一句源自《论语》的古语,这句话的意思是:通过回顾过去的学习和经验,从而获得新的理解和认识。这句话鼓励我们在学习过程中,不仅要关注新的知识,还要不断地回顾和巩固已经学过的知识,以便从中汲取新的启示和收获。这种方法有助于我们更好地吸收和理解新知识,提高学习效果。
==>
"温故而知新"是一句源自中国古代的成语,出自《论语·为政》篇。它的意思是在回顾过去的基础上,发现新的知识和理解。这句话鼓励我们在学习或生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。◆ Baichuan-2-13B 显存
为了测试推理需要的显存,先用 A800 尝尝咸淡,大概需要 30G 显存:
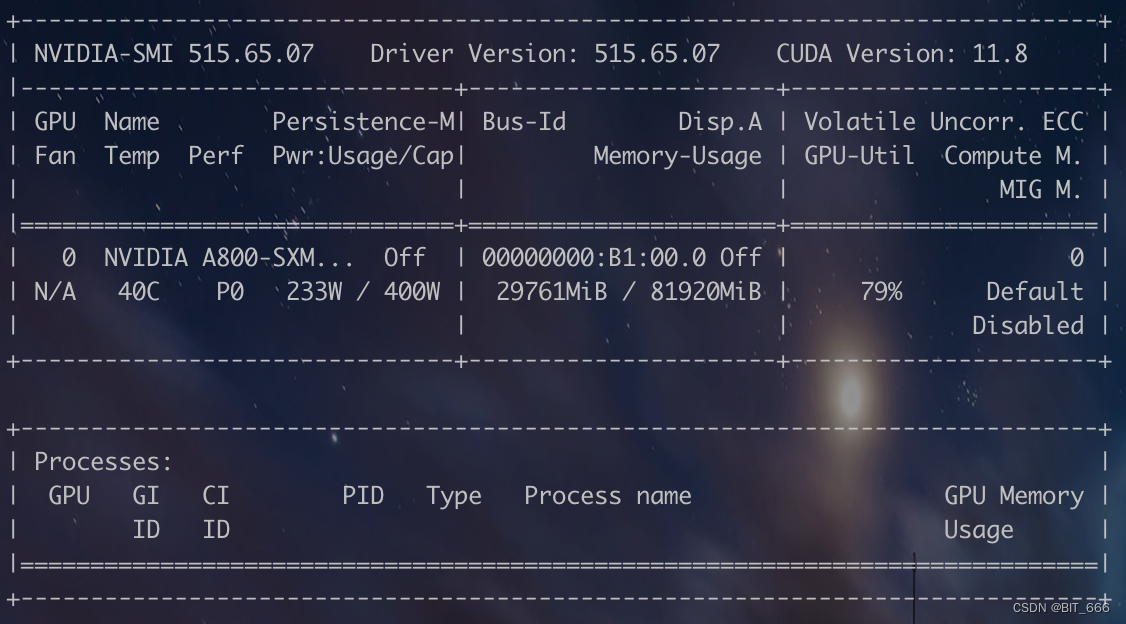
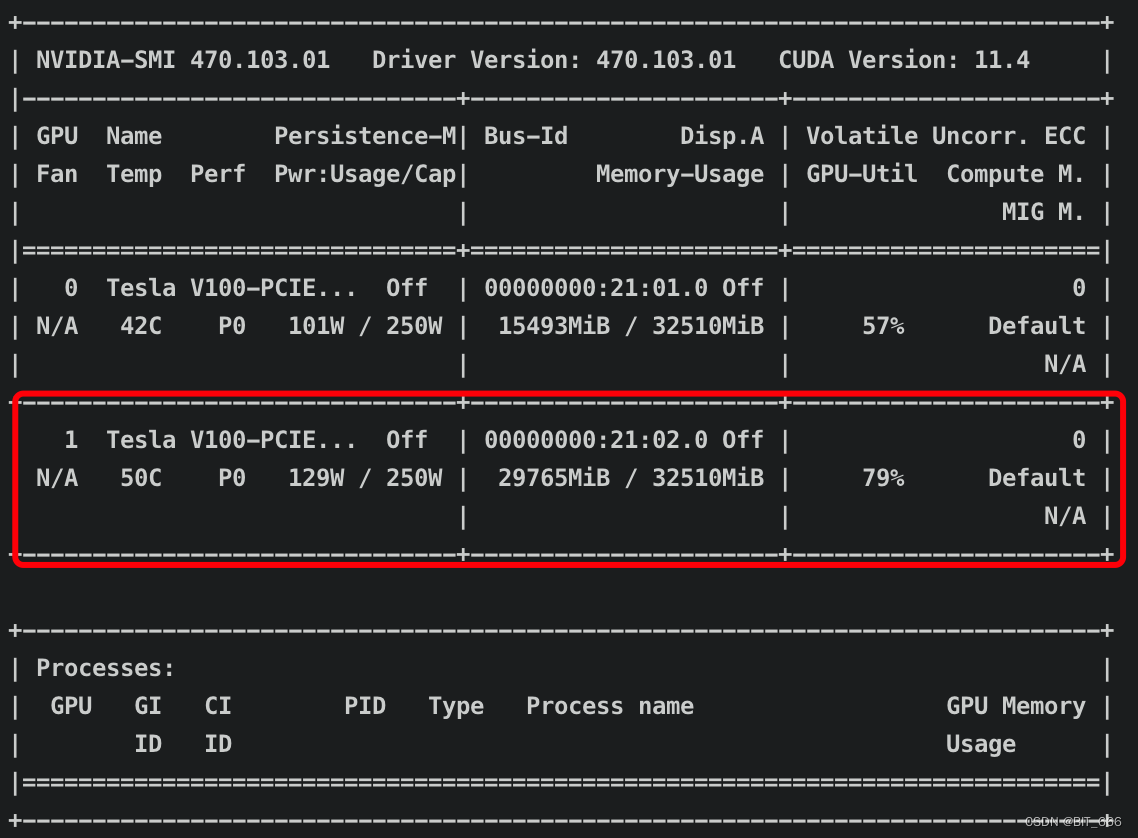
所以 V100-32G 应该也没问题可以跑起来最新的 Baichuan-2-13B,不过由于 Token 的扩充,遇到较长的 query 不确定 generate 是否会 OOM:
4.模型量化
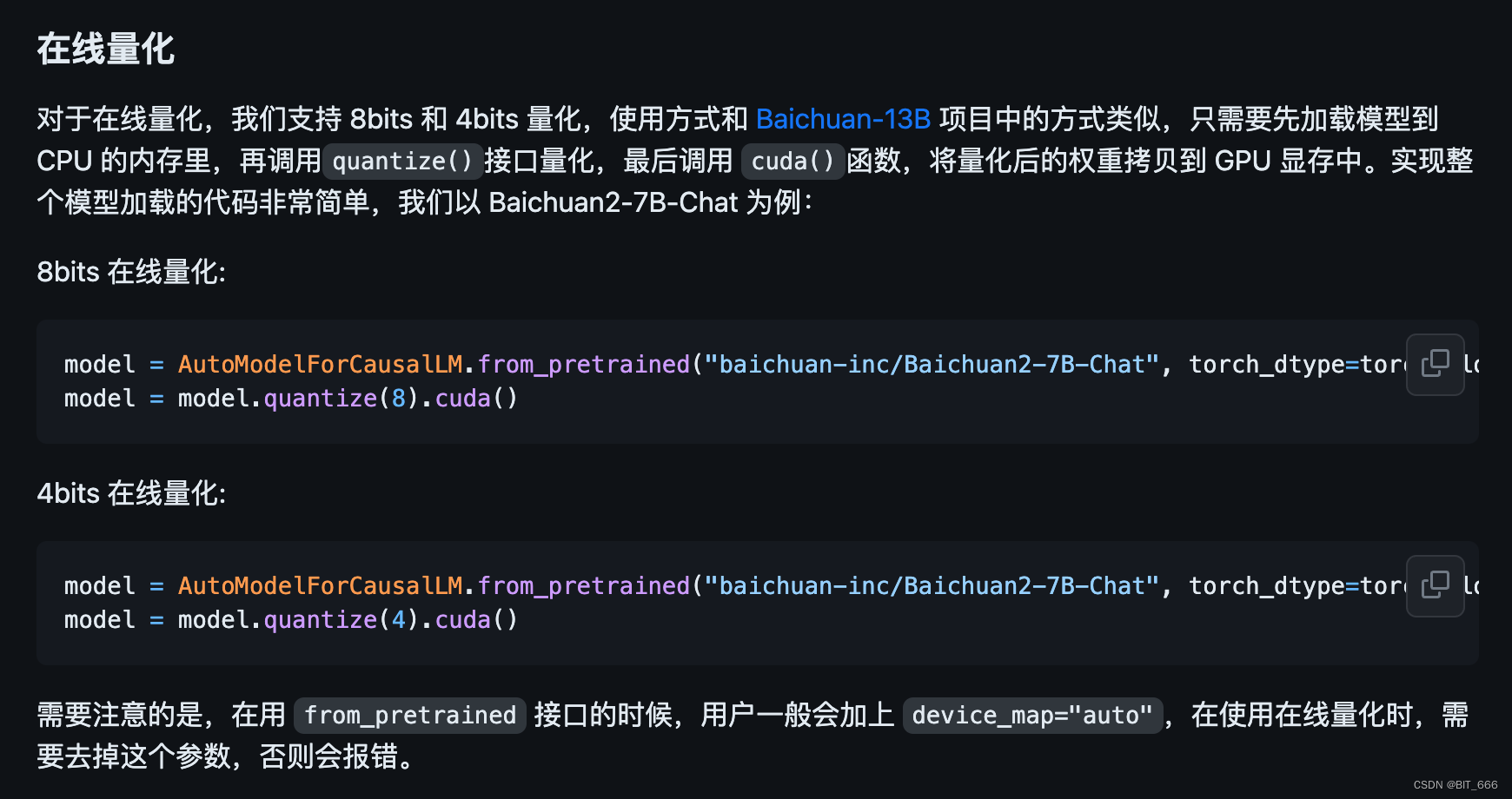
◆ 在线量化
◆ 离线量化

◆ 量化效果
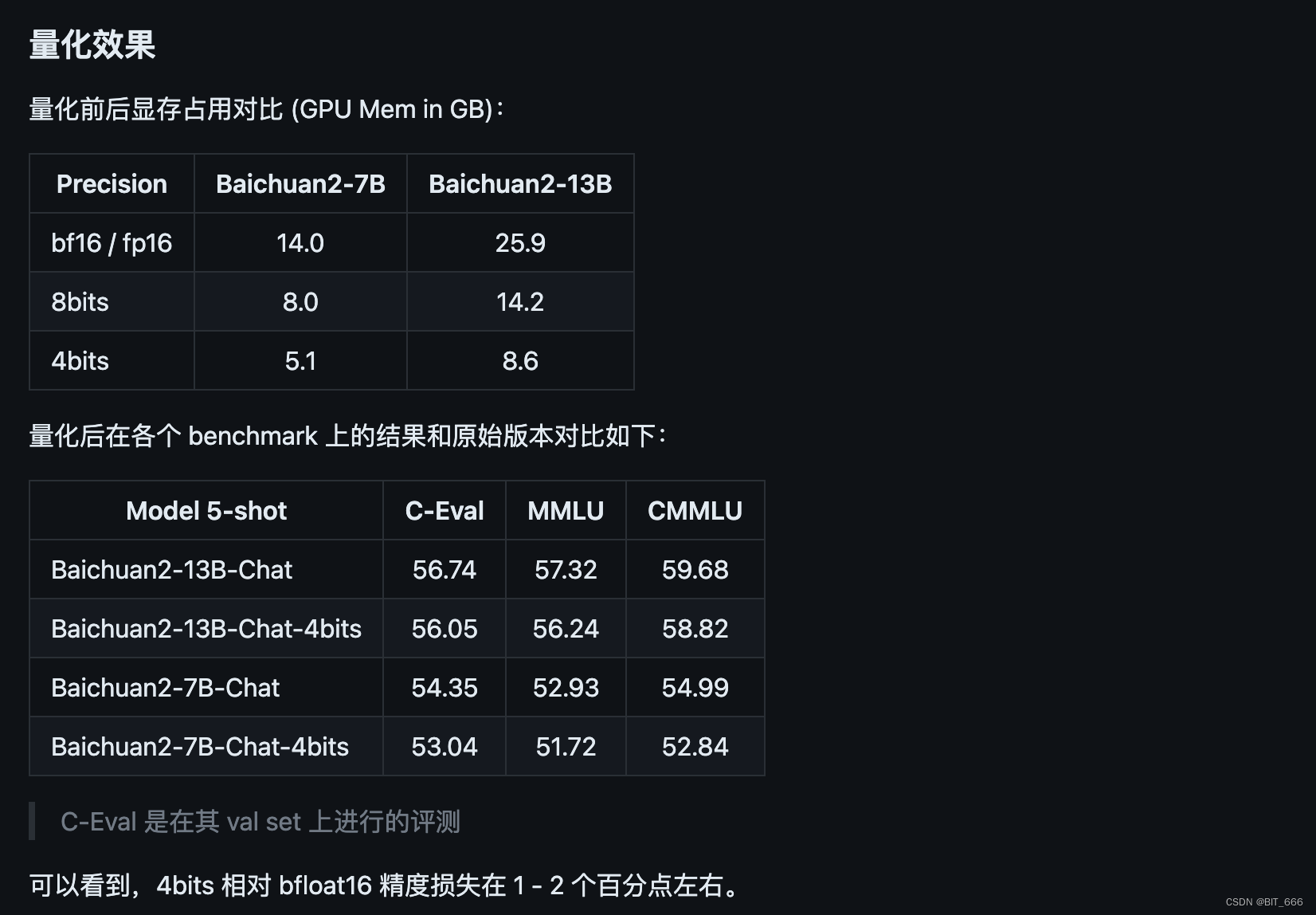
根据官方提供的数据集测试效果,量化后的效果整体损失不大,不过博主尝试了对 LLaMA-33B 进行 8-bit 量化,实际场景效果与未量化相差很大,大家可以在自己场景实际测试体验量化效果。其次这里量化的方式与一代也有一定区别,大家注意代码的修改。
5.模型迁移
由于很多同学在 Baichuan 1 (Baichuan-7B, Baichuan-13B) 上做了很多优化的工作,例如编译优化、量化等,为了将这些工作零成本地应用于 Baichuan 2,用户可以对 Baichuan 2 模型做一个离线转换,转换后就可以当做 Baichuan 1 模型来使用。具体来说,用户只需要利用以下脚本离线对 Baichuan 2 模型的最后一层 lm_head 做归一化,并替换掉 lm_head.weight 即可。替换完后,就可以像对 Baichuan 1 模型一样对转换后的模型做编译优化等工作了。这也印证了我们前面提到的 lm_head 两个模型的差异:
import torch
import os
ori_model_dir = 'your Baichuan 2 model directory'
# To avoid overwriting the original model, it's best to save the converted model to another directory before replacing it
new_model_dir = 'your normalized lm_head weight Baichuan 2 model directory'
model = torch.load(os.path.join(ori_model_dir, 'pytorch_model.bin'))
lm_head_w = model['lm_head.weight']
lm_head_w = torch.nn.functional.normalize(lm_head_w)
model['lm_head.weight'] = lm_head_w
torch.save(model, os.path.join(new_model_dir, 'pytorch_model.bin'))三.总结
上面是最新 Baichuan-2-13B 的使用初体验,后续还会测试基于 Baichuan-2-13B 微调的模型效果如何。更多 Baichaun-2 的细节大家可以移步官网:https://github.com/baichuan-inc/Baichuan2。