进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. HAVING子句
2. ORDER BY 子句
3. LIMIT BY 子句
4. LIMIT 子句
1. HAVING子句
clickhouse也支持Having子句,需要与group by 同时出现,不能单独使用,它能够在聚合计算之后实现二次过滤数据。操作如下:
node1 :) select province,city,item,sum(totalcount) as total from mt_tbl2 group by province,city,item having total >1000;
┌─province─┬─city─┬─item─────┬─total─┐
│ 上海 │ 嘉定 │ 华为手机 │ 1400 │
└──────────┴──────┴──────────┴───────┘2. ORDER BY 子句
Order by 子句通过声明排序键来指定查询数据返回时的顺序。在MergeTree表引擎中也有Order by 参数用于指定排序键。在MergeTree表引擎中指定order by 后,数据在各个分区内按照其定义的规则排序,这是一种分区内的局部排序,如果在查询时数据跨越了多个分区,则他们返回的顺序是无法预知的,每一次查询返回的顺序都有可能不同。这种情况下,如果希望数据总是能够按照期望的顺序返回,就需要借助Order by 子句来指定全局排序。
3. LIMIT BY 子句
LIMIT BY 子句运行在Order by 之后和LIMIT 之前,能够按照指定分组,最多返回前n行数据,如果数据总行少于n行,则按实际数量返回,常用于TOPN的查询场景,功能类似Hive中的开窗函数。
LIMIT BY 的常规语法如下:
LIMIT n BY expressn指的是获取几条数据;express通常是一到多个字段,即按照express分组获取每个分组的前n条数据。
用法示例如下:
#目前有表mt_tbl2,数据如下:
node1 :) select * from mt_tbl2;
#查询表mt_tbl2中每个省份对应的totalcount top2最大值
node1 :) select province,totalcount from mt_tbl2 order by totalcount desc limit 2 by province;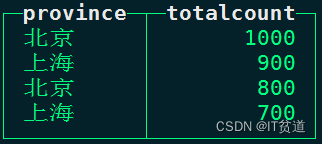
除了常规语法外,LIMIT BY 也支持跳过offset偏移量获取数据,具体语法如下:
#按照express分组,获取跳过y行后的top n行数据。
LIMIT n offset y BY express
#简化为
LIMIT y,n BY express举例:获取表mt_tbl2中每个省份第二、第三大销售额。
node1 :) select province,totalcount from mt_tbl2 order by totalcount desc limit 2 offset 1 by province;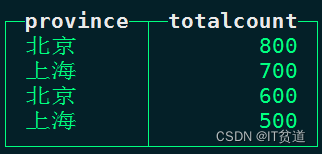
4. LIMIT 子句
LIMIT 子句用于返回指定的前n行数据,常用于分页场景,它的三种语法形式如下:
#返回前n行数据
LIMIT n
#指定从第m行开始返回前n行数据
LIMIT n OFFSET m
#指定从第m行开始返回前n行数据简化写法
LIMIT m,n👨💻如需博文中的资料请私信博主。