目录
1. C语言的输入和输出和流
2. C++的IO流
2.1 C++标准IO流
2.2 C++文件IO流
2.3 stringstream(字符流)
3. 空间配置器(了解)
3.1 一级空间适配器
3.2 二级空间配置器
3.3 二级空间适配器的空间申请
3.4 二级空间配置器的空间回收
3.5 对象构造与释放和与容器结合
4. STL六大组件联系
本篇完。
1. C语言的输入和输出和流
C语言中我们用到的最频繁的输入输出方式就是scanf ()与printf()。 scanf(): 从标准输入设备(键 盘)读取数据,并将值存放在变量中。printf(): 将指定的文字/字符串输出到标准输出设备(屏幕)。 注意宽度输出和精度输出控制。C语言借助了相应的缓冲区来进行输入与输出。如下图所示:
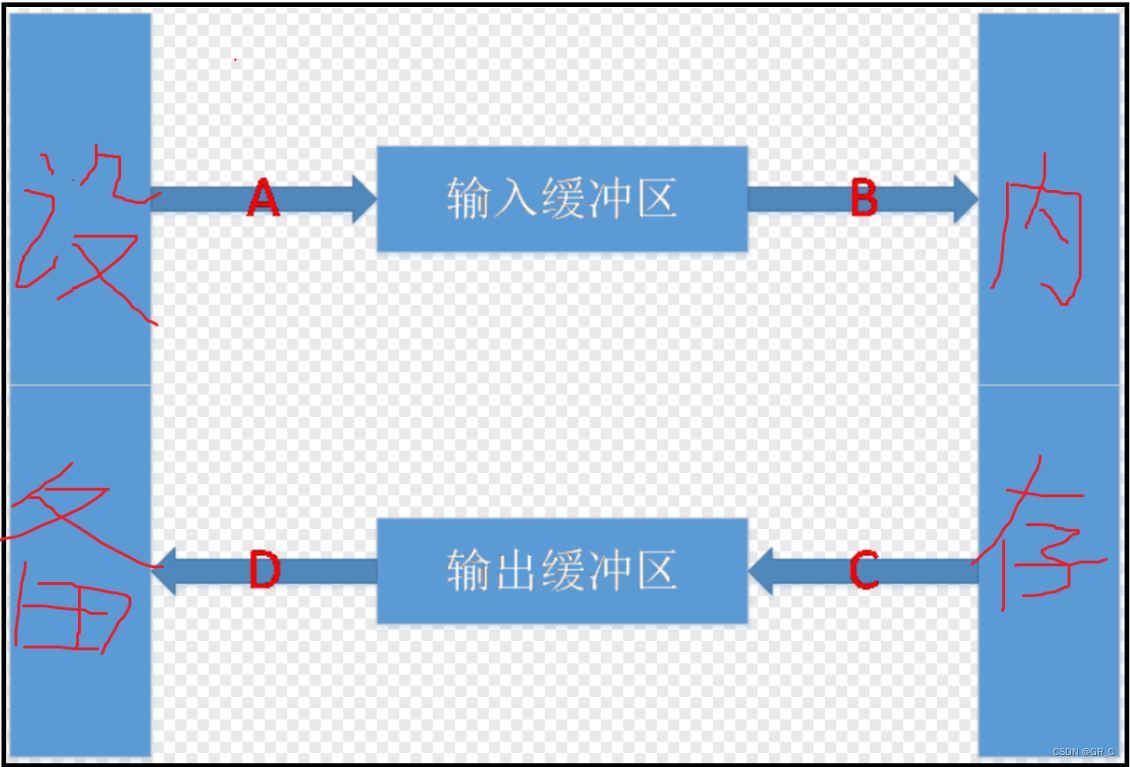
对输入输出缓冲区的理解:
① 可以屏蔽掉低级I/O的实现,低级I/O的实现依赖操作系统本身内核的实现,所以如果能够屏 蔽这部分的差异,可以很容易写出可移植的程序。
② 可以使用这部分的内容实现“行”读取的行为,对于计算机而言是没有“行”这个概念,有了这 部分,就可以定义“行”的概念,然后解析缓冲区的内容,返回一个“行”。
2. C++的IO流
流是什么:“流”即是流动的意思,是物质从一处向另一处流动的过程,是对一种有序连续且具有方向性的数据( 其单位可以是bit,byte,packet )的抽象描述。
C++流是指信息从外部输入设备(如键盘)向计算机内部(如内存)输入和从内存向外部输出设备(显示器)输出的过程。这种输入输出的过程被形象的比喻为“流”。
它的特点:有序连续、具有方向性。
C++定义了I/O标准类库来实现这种流动,这些每个类都称为流/流类,用以完成某种特定的功能。
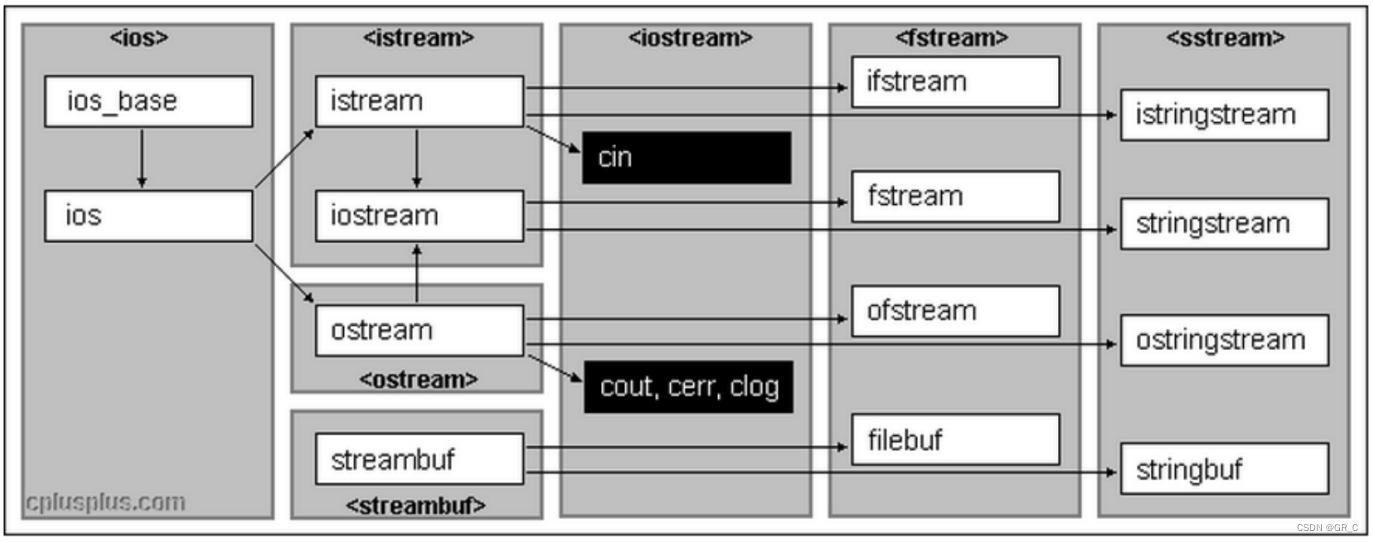
C++系统实现了一个庞大的类库,其中ios为基类,其他类都是直接或间接派生自ios类:
2.1 C++标准IO流
iostream类也叫做标准IO流,根据上面IO库可以看到,iostream是同时继承了istream标准输入和ostream标准输出。
C++标准库提供了4个全局流对象cin、cout、cerr、clog,使用cout进行标准输出,即数据从内存流向控制台(显示器)。使用cin进行标准输入即数据通过键盘输入到程序中,同时C++标准库还提供了cerr用来进行标准错误的输出,以及clog进行日志的输出,从上图可以看出,cout、 cerr、clog是ostream类的三个不同的对象,因此这三个对象现在基本没有区别,只是应用场景不 同。 在使用时候必须要包含文件并引入std标准命名空间。
先复习下标准输入:
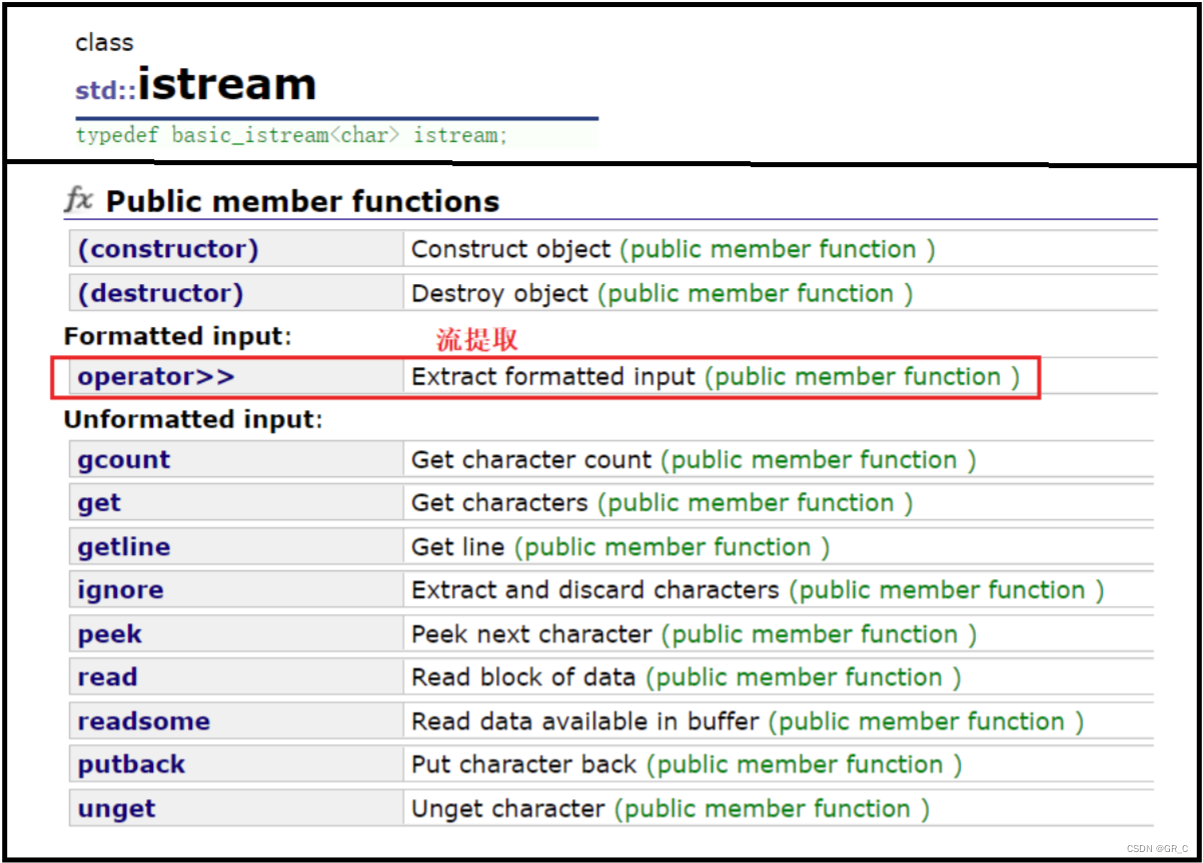
对于标准输入,只要包含了C++的IO库,就会有一个全局的istream对象cin,用来从IO流中将数据提取到内存中的指定位置。
而为了能实现数据从标准外设到内存的流动,重载了>>运算符,如上图红色框中所示函数operator>>,这个运算符也形象的表示了数据流动的方向,是向右流动的。
int a;
cin >> a;
如上面代码所示,数据从cin对象流到了变量a中,其中cin这个全局对象就代表标准输入(如键盘)。
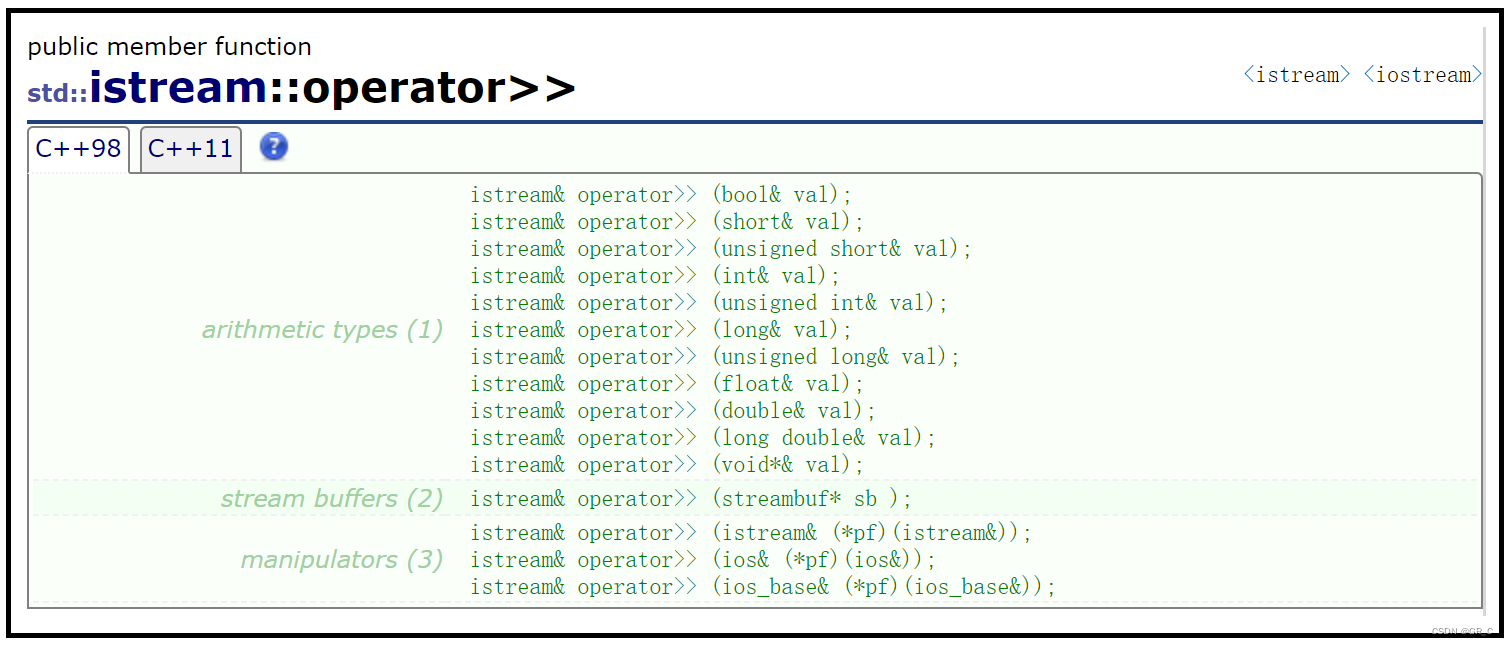
从operator>>的成员函数定义中,可以看到,所有的内置类型都进行了重载,这个工作是由C++IO库来完成的,我们可以直接使用。 而对于内置类型需要我们自己来实现>>的重载,我们在日期类就详细讲过了。
注意:
① cin为缓冲流。键盘输入的数据保存在缓冲区中,当要提取时,是从缓冲区中拿。如果一次输入过多,会留在那儿慢慢用,如果输入错了,必须在回车之前修改,如果回车键按下就无法挽回了。只有把输入缓冲区中的数据取完后,才要求输入新的数据。
② 输入的数据类型必须与要提取的数据类型一致,否则出错。出错只是在流的状态字state中应位置位(置1),程序继续。
③ 空格和回车都可以作为数据之间的分格符,所以多个数据可以在一行输入,也可以分行输 入。但如果是字符型和字符串,则空格(ASCII码为32)无法用cin输入,字符串中也不能有 空格。回车符也无法读入。
④ cin和cout可以直接输入和输出内置类型数据,原因:标准库已经将所有内置类型的输入和输出全部重载了。
⑤ 对于自定义类型,如果要支持cin和cout的标准输入输出,需要对<<和>>进行重载。
⑥ 在线OJ中的输入和输出: 对于IO类型的算法,一般都需要循环输入:输出:严格按照题目的要求进行,多一个少一个空格都不行。 连续输入时,vs系列编译器下在输入ctrl+Z加回车时结束。
⑦ istream类型对象转换为逻辑条件判断值
istream& operator>> (int& val);
explicit operator bool() const;实际上我们看到使用while(cin>>i)去流中提取对象数据时,调用的是operator>>,返回值是 istream类型的对象,那么这里可以做逻辑条件值,源自于istream的对象又调用了operator bool,operator bool调用时如果接收流失败,或者有结束标志,则返回false。

跟着上面知识重新看下日期类:
class Date
{
friend ostream& operator << (ostream& out, const Date& d);
friend istream& operator >> (istream& in, Date& d);
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{}
operator bool()
{ // 这里是随意写的,假设输入_year为0,则结束
if (_year == 0)
{
return false;
}
else
{
return true;
}
}
private:
int _year;
int _month;
int _day;
};
istream& operator >> (istream& in, Date& d)
{
in >> d._year >> d._month >> d._day;
return in;
}
ostream& operator << (ostream& out, const Date& d)
{
out << d._year << "年" << d._month << "月" << d._day << "日";
return out;
}
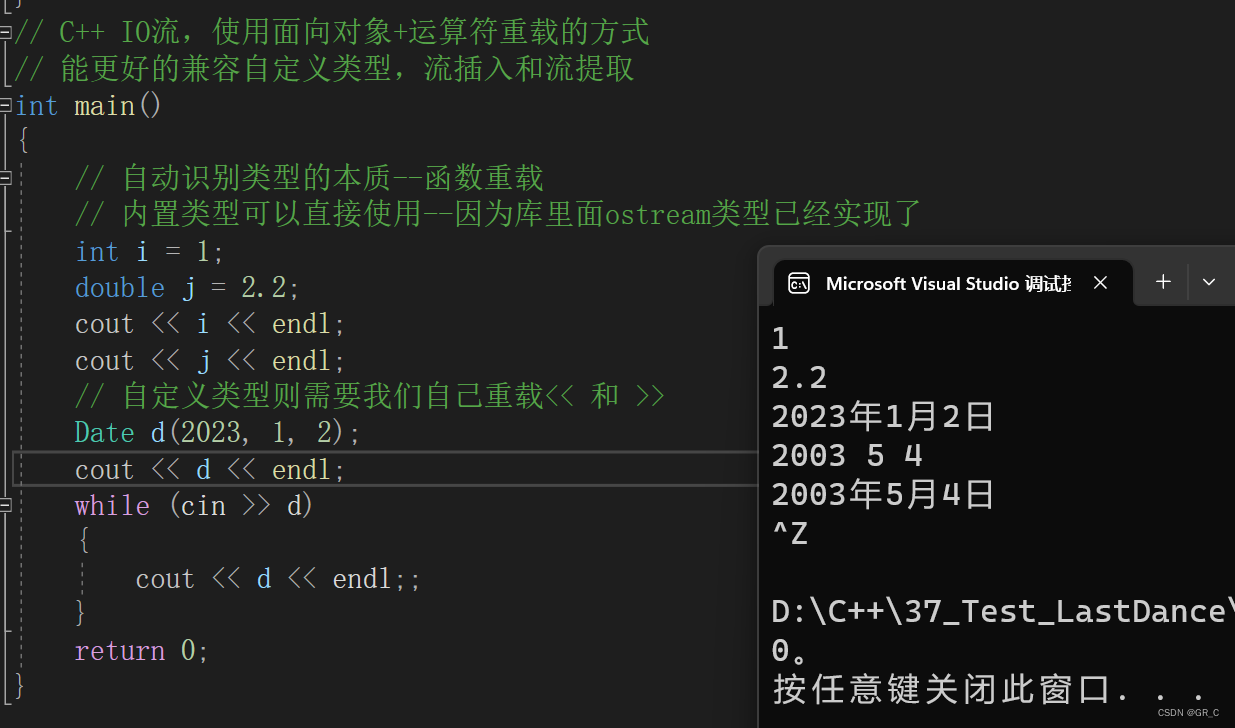
// C++ IO流,使用面向对象+运算符重载的方式
// 能更好的兼容自定义类型,流插入和流提取
int main()
{
// 自动识别类型的本质--函数重载
// 内置类型可以直接使用--因为库里面ostream类型已经实现了
int i = 1;
double j = 2.2;
cout << i << endl;
cout << j << endl;
// 自定义类型则需要我们自己重载<< 和 >>
Date d(2023, 1, 2);
cout << d << endl;
while (cin >> d)
{
cout << d << endl;;
}
return 0;
}
下面的C++文件IO流对于日期类这种自定义类型也有优点。
2.2 C++文件IO流
C++根据文件内容的数据格式分为二进制文件和文本文件。
采用文件流对象操作文件的一般步骤:
① 定义一个文件流对象 ifstream ifile(只输入用)ofstream ofile(只输出用)fstream iofile(既输入又输出用)
② 使用文件流对象的成员函数打开一个磁盘文件,使得文件流对象和磁盘文件之间建立联系
③ 使用提取和插入运算符对文件进行读写操作,或使用成员函数进行读写
④ 关闭文件
保留上面的日期类,再看段代码:(注意包含头文件#include <fstream>,还有日期类的输出要改一点)
class Date
{
friend ostream& operator<<(ostream& out, const Date& d);
friend istream& operator>>(istream& in, Date& d);
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{}
operator bool()
{ // 这里是随意写的,假设输入_year为0,则结束
if (_year == 0)
{
return false;
}
else
{
return true;
}
}
private:
int _year;
int _month;
int _day;
};
istream& operator>>(istream& in, Date& d)
{
in >> d._year >> d._month >> d._day;
return in;
}
ostream& operator<<(ostream& out, const Date& d)
{
out << d._year << " " << d._month << " " << d._day; // 文本读写先用空格分割,不然再从文件读就错了
return out;
}
struct ServerInfo
{
char _address[32];
int _port;
Date _date;
};
struct ConfigManager
{
public:
ConfigManager(const char* filename)
:_filename(filename)
{}
void WriteBin(const ServerInfo& info)
{
ofstream ofs(_filename, ios_base::out | ios_base::binary); // 两种状态
ofs.write((const char*)&info, sizeof(info));
}
void ReadBin(ServerInfo& info)
{
ifstream ifs(_filename, ios_base::in | ios_base::binary);
ifs.read((char*)&info, sizeof(info));
}
// C++文件流的优势就是可以对内置类型和自定义类型,都适用
// 一样的方式,去流插入和流提取数据
// 当然这里自定义类型Date需要重载>> 和 <<
// istream& operator >> (istream& in, Date& d)
// ostream& operator << (ostream& out, const Date& d)
void WriteText(const ServerInfo& info)
{
ofstream ofs(_filename);
ofs << info._address << " " << info._port << " " << info._date;
}
void ReadText(ServerInfo& info)
{
ifstream ifs(_filename);
ifs >> info._address >> info._port >> info._date;
}
private:
string _filename; // 配置文件
};
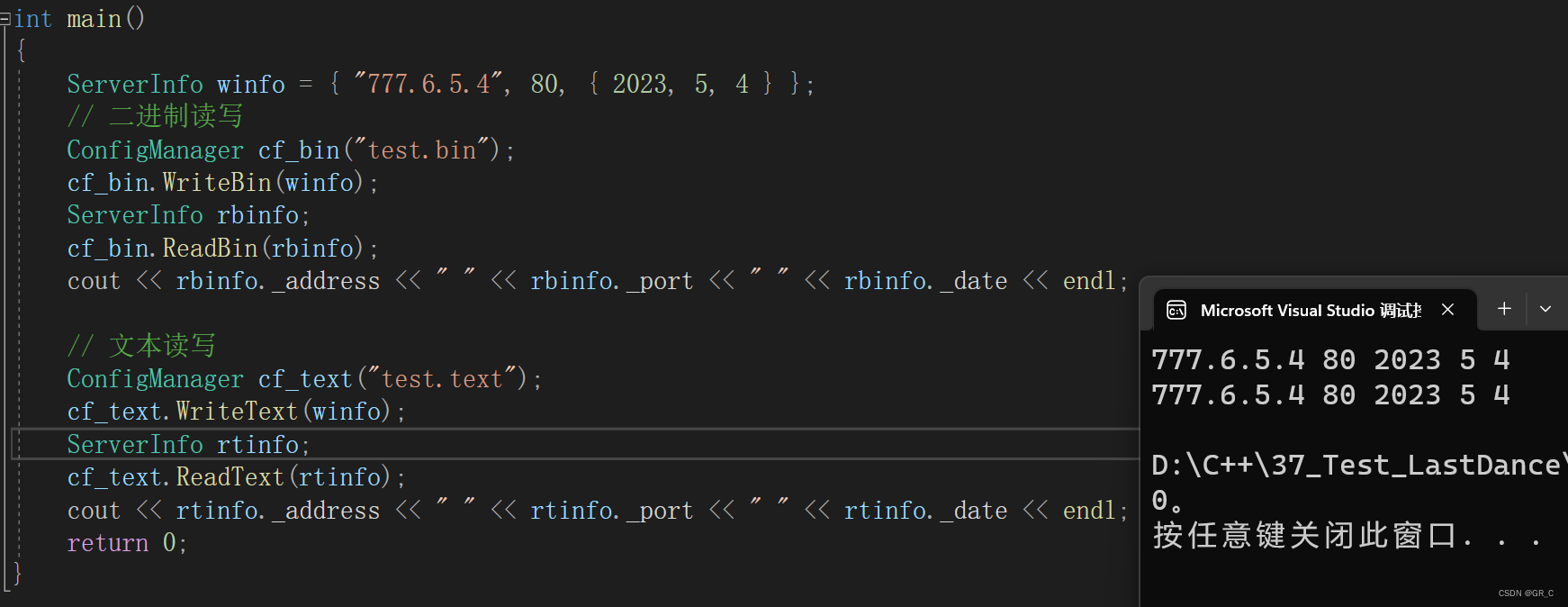
int main()
{
ServerInfo winfo = { "777.6.5.4", 80, { 2023, 5, 4 } };
// 二进制读写
ConfigManager cf_bin("test.bin");
cf_bin.WriteBin(winfo);
ServerInfo rbinfo;
cf_bin.ReadBin(rbinfo);
cout << rbinfo._address << " " << rbinfo._port << " " << rbinfo._date << endl;
// 文本读写
ConfigManager cf_text("test.text");
cf_text.WriteText(winfo);
ServerInfo rtinfo;
cf_text.ReadText(rtinfo);
cout << rtinfo._address << " " << rtinfo._port << " " << rtinfo._date << endl;
return 0;
}
2.3 stringstream(字符流)
在C语言中,如果想要将一个整形变量的数据转化为字符串格式,如何去做?
- ① 使用itoa()函数
- ② 使用sprintf()函数
但是两个函数在转化时,都得需要先给出保存结果的空间,那空间要给多大呢,就不太好界定, 而且转化格式不匹配时,可能还会得到错误的结果甚至程序崩溃。
在C++中,可以使用stringstream类对象来避开此问题。
在程序中如果想要使用stringstream,必须要包含头文件sstream。
在该头文件下,标准库三个类: istringstream、ostringstream 和 stringstream,分别用来进行流的输入、输出和输入输出操作。
这里主要介绍stringstream。 stringstream主要可以用来:
① 将数值类型数据格式化为字符串
② 字符串拼接
③ 序列化和反序列化结构数据
①②都不重要,但是先看看 ① 将数值类型数据格式化为字符串:
#include<sstream>
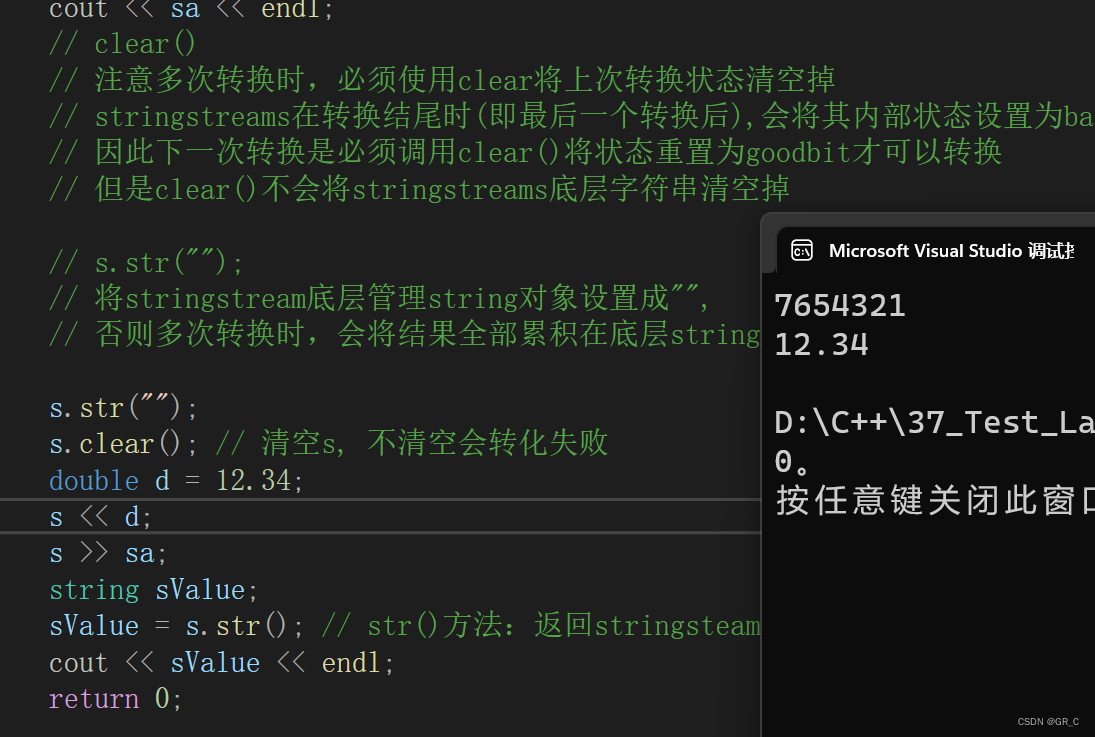
int main()
{
int a = 7654321;
string sa;
// 将一个整形变量转化为字符串,存储到string类对象中
stringstream s;
s << a;
s >> sa;
cout << sa << endl;
// clear()
// 注意多次转换时,必须使用clear将上次转换状态清空掉
// stringstreams在转换结尾时(即最后一个转换后),会将其内部状态设置为badbit
// 因此下一次转换是必须调用clear()将状态重置为goodbit才可以转换
// 但是clear()不会将stringstreams底层字符串清空掉
// s.str("");
// 将stringstream底层管理string对象设置成"",
// 否则多次转换时,会将结果全部累积在底层string对象中
s.str("");
s.clear(); // 清空s, 不清空会转化失败
double d = 12.34;
s << d;
s >> sa;
string sValue;
sValue = s.str(); // str()方法:返回stringsteam中管理的string类型
cout << sValue << endl;
return 0;
}
再随便看看②字符串拼接:
int main()
{
stringstream sstream;
// 将多个字符串放入 sstream 中
sstream << "first" << " " << "string,";
sstream << " second string";
cout << "strResult is: " << sstream.str() << endl;
// 清空 sstream
sstream.str("");
sstream << "third string";
cout << "After clear, strResult is: " << sstream.str() << endl;
return 0;
}
最后看看③ 序列化和反序列化结构数据
这里就类似于一个设备给另一个设备发信息,然后这段代码把要发的信息排列成易看的格式发出。
class Date
{
friend ostream& operator<<(ostream& out, const Date& d);
friend istream& operator>>(istream& in, Date& d);
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{}
operator bool()
{ // 这里是随意写的,假设输入_year为0,则结束
if (_year == 0)
{
return false;
}
else
{
return true;
}
}
private:
int _year;
int _month;
int _day;
};
istream& operator>>(istream& in, Date& d)
{
in >> d._year >> d._month >> d._day;
return in;
}
ostream& operator<<(ostream& out, const Date& d)
{
out << d._year << " " << d._month << " " << d._day; // 文本读写先用空格分割,不然再从文件读就错了
return out;
}
struct ChatInfo
{
string _name; // 名字
int _id; // id
Date _date; // 时间
string _msg; // 聊天信息
};
int main()
{
// 结构信息序列化为字符串
ChatInfo winfo = { "清濑灰二", 777999, { 2023, 5, 4 }, "晚上去跑步吗" };
ostringstream oss;
oss << winfo._name << " " << winfo._id << " " << winfo._date << " " << winfo._msg;
string str = oss.str();
cout << str << endl << endl;
// 我们通过网络这个字符串发送给对象,实际开发中,信息相对更复杂,
// 一般会选用Json、xml等方式进行更好的支持
// 字符串解析成结构信息
ChatInfo rInfo;
istringstream iss(str);
iss >> rInfo._name >> rInfo._id >> rInfo._date >> rInfo._msg;
cout << "-------------------------------------------------------" << endl;
cout << "姓名:" << rInfo._name << "(" << rInfo._id << ") ";
cout << "时间" << rInfo._date << endl;
cout << "信息:>" << rInfo._msg << endl;
cout << "-------------------------------------------------------" << endl;
return 0;
}
总结注意:
① stringstream实际是在其底层维护了一个string类型的对象用来保存结果。
② 多次数据类型转化时,一定要用clear()来清空,才能正确转化,但clear()不会将 stringstream底层的string对象清空。
③ 可以使用s. str("")方法将底层string对象设置为""空字符串。
④ 可以使用s.str()将让stringstream返回其底层的string对象。
⑤ stringstream使用string类对象代替字符数组,可以避免缓冲区溢出的危险,而且其会对参 数类型进行推演,不需要格式化控制,也不会出现格式化失败的风险,因此使用更方便,更安全。
3. 空间配置器(了解)
空间配置器,顾名思义就是为各个容器高效的管理空间(空间的申请与回收)的,在默默地工作。虽然在常规使用STL时,可能用不到它,但站在学习研究的角度,学习它的实现原理对我们有很大的帮助。
前面在模拟实现vector、list、map、unordered_map等容器时,所有需要空间的地方都是通过new申请的,虽然代码可以正常运行,但是有以下不足之处:
- 空间申请与释放需要用户自己管理,容易造成内存泄漏。
- 频繁向系统申请小块内存,容易造成内存碎片,还会影响程序运行效率。
- 直接使用malloc与new进行申请,每块空间前有额外空间浪费。
- 申请空间失败怎么应对。
最重要的就是,使用空间配置器来管理内存可以提供程序运行的效率。
在C++标准库中,存在着空间配置器:
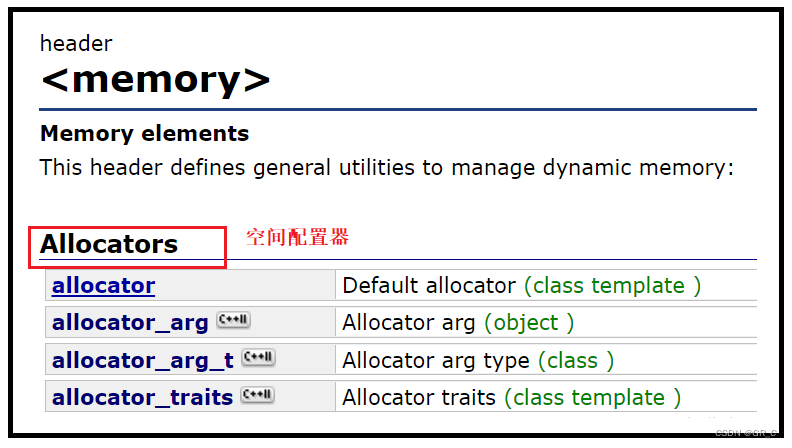
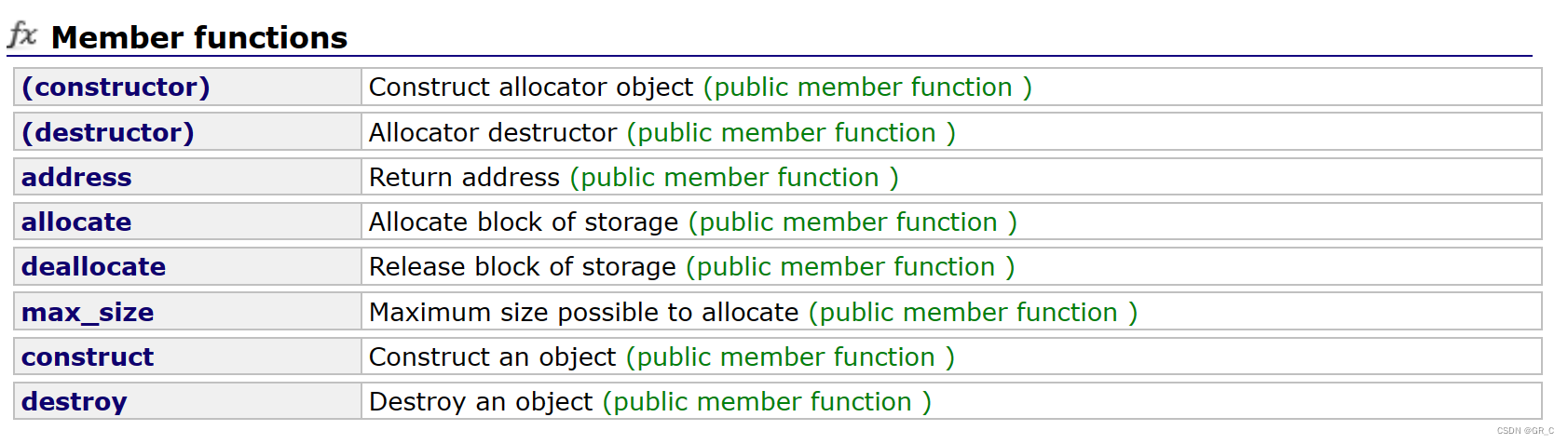
最重要的就是allocate开辟空间以及deallocate释放空间。

无论使用哪种STL中的容器,都会有一个空间配置器的模板参数,默认的是给了一个缺省值的,也就是C++库中实现的空间配置器,我们也可以才入自己实现的空间配置器,但是必须要有allocate和deallocate这两个接口。
3.1 一级空间适配器
上面提到的几点不足之处,最主要还是:频繁向系统申请小块内存造成的。那什么才算是小块内存?SGI-STL以128作为小块内存与大块内存的分界线,将空间配置器其分为两级结构,一级空间 配置器处理大块内存,二级空间配置器处理小块内存。
一级空间配置器原理非常简单,直接对malloc与free进行了封装,去开辟和释放空间。
STL一级空间配置器的部分源码:
template <int inst>
class __malloc_alloc_template
{
private:
static void* oom_malloc(size_t);
public:
// 对malloc的封装
static void* allocate(size_t n)
{
// 申请空间成功,直接返回,失败交由oom_malloc处理
void* result = malloc(n);
if (0 == result)
result = oom_malloc(n);
return result;
}
// 对free的封装
static void deallocate(void* p, size_t /* n */)
{
free(p);
}
};一级空间配置器就可以理解为使用malloc去开辟空间,使用free去释放空间。
3.2 二级空间配置器
二级空间配置器专门负责处理小于128字节的小块内存。
如何才能提升小块内存的申请与释放的方式呢?
SGI-STL采用了内存池的技术来提高申请空间的速度以及减少额外空间的浪费,采用哈希桶的方式来提高用户获取空间的速度与高效管理。
内存池:先申请一块比较大的内存块做备用,当需要内存时,直接到内存池中去取,当池中空间不够时,再向内存使用malloc中去取,当用户不用时,直接还回内存池即可。
避免了频繁向系统申请小块内存所造成的效率低、内存碎片以及额外浪费的问题。
二级空间配置器中存在3个成员变量:
template <int inst>
class __default_alloc_template
{
char* start;
char* end;
size_t heap_size;
};
start表示内存池的起始位置,end表示内存池的结束位置,heap_size表示内存池的大小。
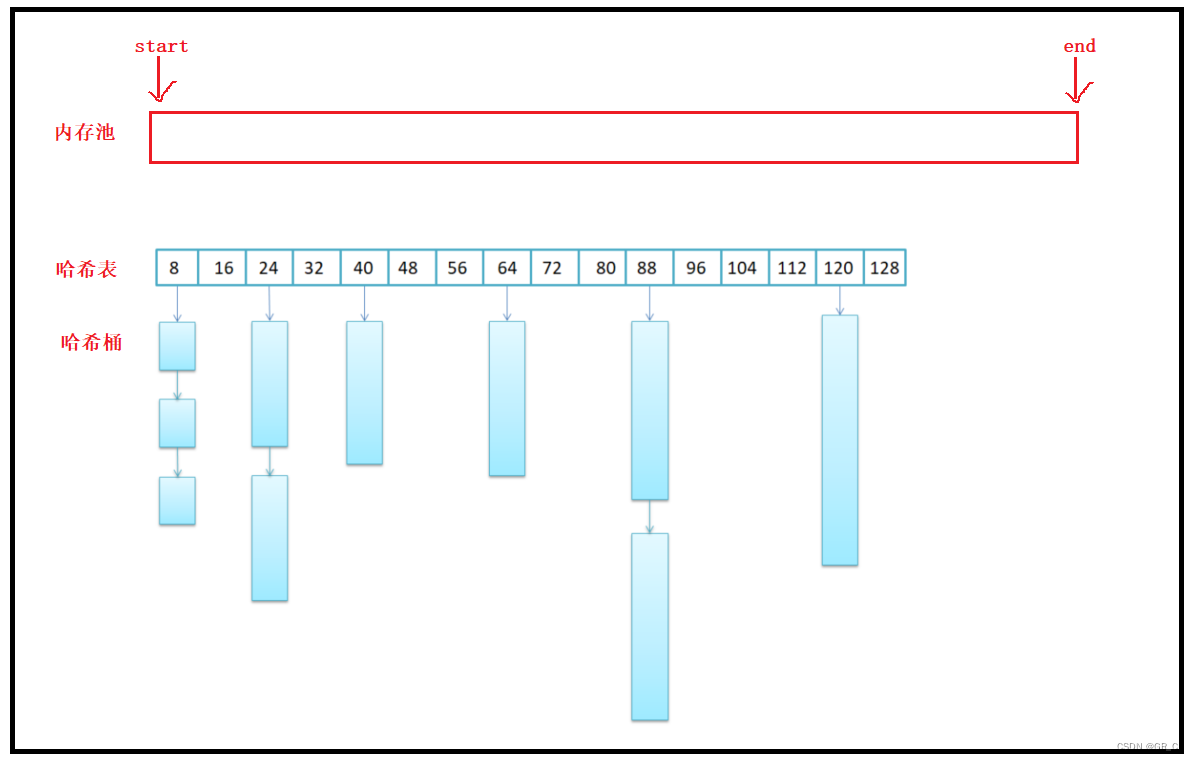
二级空间配置器的结构如上图所示,存在一个内存池,还有一个哈希表,下面挂着哈希桶。哈希表中的数字,表示挂在这个位置哈希桶的大小,也就是所需要空间的大小。
在第一次开辟空间的时候,此时内存池是空的,哈希表中也是空的,没有挂任何一个桶。
假设要new一个16个字节大小的节点,首先会去哈希表中挂载16个字节大小的位置查找有没有哈希桶存在,因为是第一次,所以没有。
此时再去内存池中要内存,但不是仅要16个字节,而是要多个16个字节,STL中采样一次要20个16个字节的内存,也就是一共320个字节,但是此时的内存池同样也没有内存,所以去使用malloc向系统申请,申请好后放在内存池中。
此时内存池中就有20个16个字节的内存,因为new节点需要一个,所以就拿走一个给容器使用,剩下的19个,挂在哈希表中表示16个字节大小的位置处。
当之后再次new16个字节的节点时,此时哈希表中挂载着多个16个字节大小的桶。每new一个节点,就从哈希表中拿走一个16个字节的桶。
如果有归还的节点,那么就头插到哈希表中,之后再new节点时,归还的桶还可以再用。
如果new6个字节大小的节点,那么就去哈希表中寻找大小为8的桶,继续重复上面的操作。
哈希表中每个位置挂载的桶的大小是存在对齐的,规律就是8的倍数,但是不超过128。
每个哈希桶又是以什么样的方式挂载的呢?
union obj
{
union obj* next;//下一个哈希桶的地址
char * data[8*i];//大小是8的整数倍
};
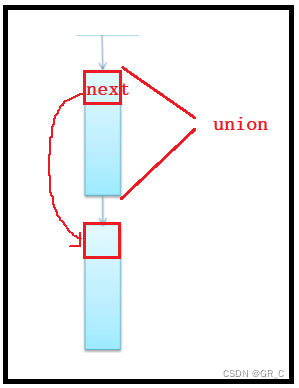
挂载的哈希桶是联合体变量,第一个变量是union obj* next也就是下一个哈希桶的指针。
第二个变量才是真正的内存空间,可以供容器存放数据的空间。
- 哈希桶的地址只有在挂载的时候才有意义,而此时存放数据的空间里的内容是不重要的。
- 哈希桶被从哈希表拿走后,它里面存放地址的成员又不重要了,因为此时容器需要的是它存放数据的空间。
- 当这块空间被归还头插到哈希表中的时候,只需要将里面的指针变量指向下一快挂载的空间即可。
这里使用联合体变量可以节省很多的空间,而且充分利用到了联合体的特性。
如果是64位的机器,那么指针变量的大小就是8个字节,所以在挂载的是,大小为8的那个桶中,所有的内存块中都只能存放下一个指针。
这也就是为什么哈希桶要采用8的倍数对齐的原因。
- 当某个位置的哈希桶中的内存块都被使用完毕后,在new新的节点时,会继续向内存池中要内存,如果内存池中没有就会向系统malloc申请内存。
如果此时系统中也没有内存了,malloc失败了会怎么办呢?会从哈希表中向后面查找是否存在哈希桶,如果存在就分隔后面的,如果都没有,则申请失败抛异常。
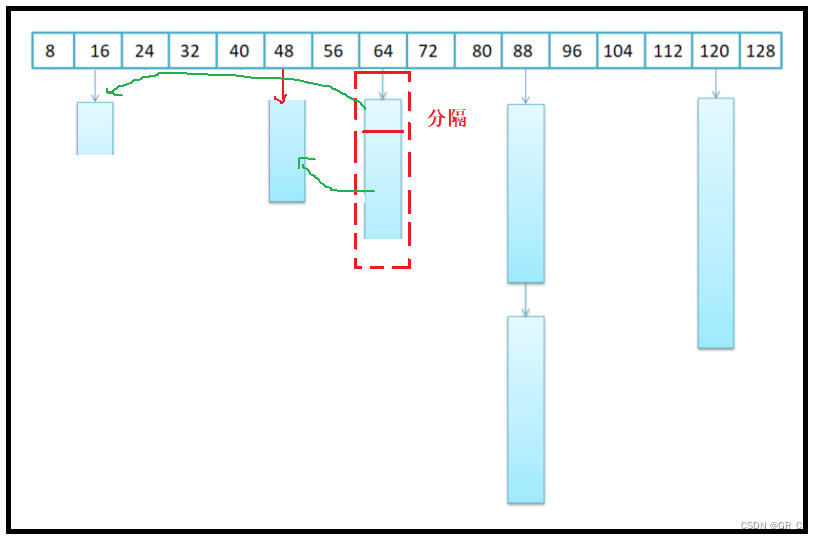
假设在现在申请的new的是16个字节大小的节点,该位置的哈希桶为空,并且系统中也没有内存了。
此时就会向后面的哈希桶中寻找,找到64位置的时候,发现存在哈希桶,就将这里64个字节的内存空分隔成16字节和48字节两部分,16字节的给new出来的新节点使用,48字节的部分挂载在48的位置处。
SGI-STL默认使用一级还是二级空间配置器,通过USE_MALLOC宏进行控制:
#ifdef __USE_MALLOC
typedef malloc_alloc alloc;
typedef malloc_alloc single_client_alloc;
#else
// 二级空间配置器定义
#endif在SGI_STL中该宏没有定义,因此:默认情况下SGI_STL使用二级空间配置器
3.3 二级空间适配器的空间申请
这里代码比较细,不看也行,看看文字步骤
① 前期准备,简单看下前期准备的源码:
// 去掉代码中繁琐的部分
template <int inst>
class __default_alloc_template
{
private:
enum { __ALIGN = 8 }; // 如果用户所需内存不是8的整数倍,向上对齐到8的整数倍
enum { __MAX_BYTES = 128 }; // 大小内存块的分界线
enum { __NFREELISTS = __MAX_BYTES / __ALIGN };//采用哈希桶保存小块内存时所需桶的个数
// 如果用户所需内存块不是8的整数倍,向上对齐到8的整数倍
static size_t ROUND_UP(size_t bytes)
{
return (((bytes)+__ALIGN - 1) & ~(__ALIGN - 1));
}
private:
// 用联合体来维护链表结构----同学们可以思考下此处为什么没有使用结构体
union obj
{
union obj* free_list_link;
char client_data[1]; /* The client sees this. */
};
private:
static obj* free_list[__NFREELISTS];
// 哈希函数,根据用户提供字节数找到对应的桶号
static size_t FREELIST_INDEX(size_t bytes)
{
return (((bytes)+__ALIGN - 1) / __ALIGN - 1);
}
// start_free与end_free用来标记内存池中大块内存的起始与末尾位置
static char* start_free;
static char* end_free;
// 用来记录该空间配置器已经想系统索要了多少的内存块
static size_t heap_size;
// ...
};② 申请空间,前面是空间申请的准备,现在申请空间:

使用空间配置器管理空间的时候,在申请内存时,如果是大于128字节,那么直接使用一级空间配置器,使用malloc开辟大块空间。如果是小于128字节,那么就使用二级空间配置器去管理内存。
- 当申请的空间大于128的时候,就按照大内存块去处理。
- 一级空间配置器是嵌套在二级空间配置器里面的。
由于哈希结构的插入以及查找效率非常高,所以空间配置器能够很大程度上提高程序的运行效率。
③ 填充内存块
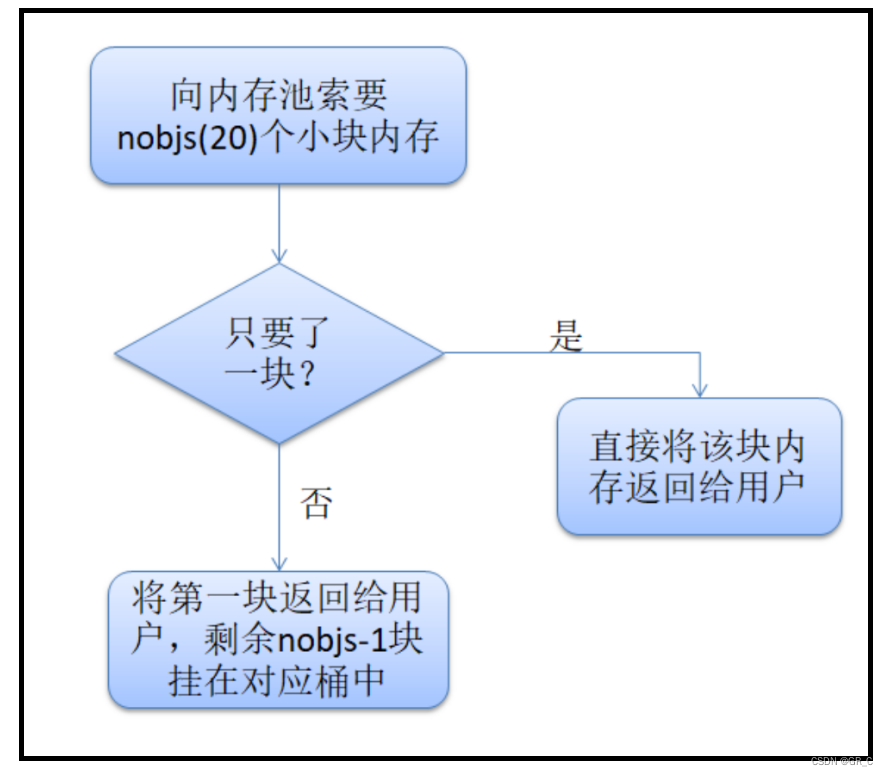
// 函数功能:向空间配置器索要空间
// 参数n: 用户所需空间字节数
// 返回值:返回空间的首地址
static void* allocate(size_t n)
{
obj* __VOLATILE* my_free_list;
obj* __RESTRICT result;
// 检测用户所需空间释放超过128(即是否为小块内存)
if (n > (size_t)__MAX_BYTES)
{
// 不是小块内存交由一级空间配置器处理
return (malloc_alloc::allocate(n));
}
// 根据用户所需字节找到对应的桶号
my_free_list = free_list + FREELIST_INDEX(n);
result = *my_free_list;
// 如果该桶中没有内存块时,向该桶中补充空间
if (result == 0)
{
// 将n向上对齐到8的整数被,保证向桶中补充内存块时,内存块一定是8的整数倍
void* r = refill(ROUND_UP(n));
return r;
}
// 维护桶中剩余内存块的链式关系
*my_free_list = result->free_list_link;
return (result);
};④ 向内存池中索要空间
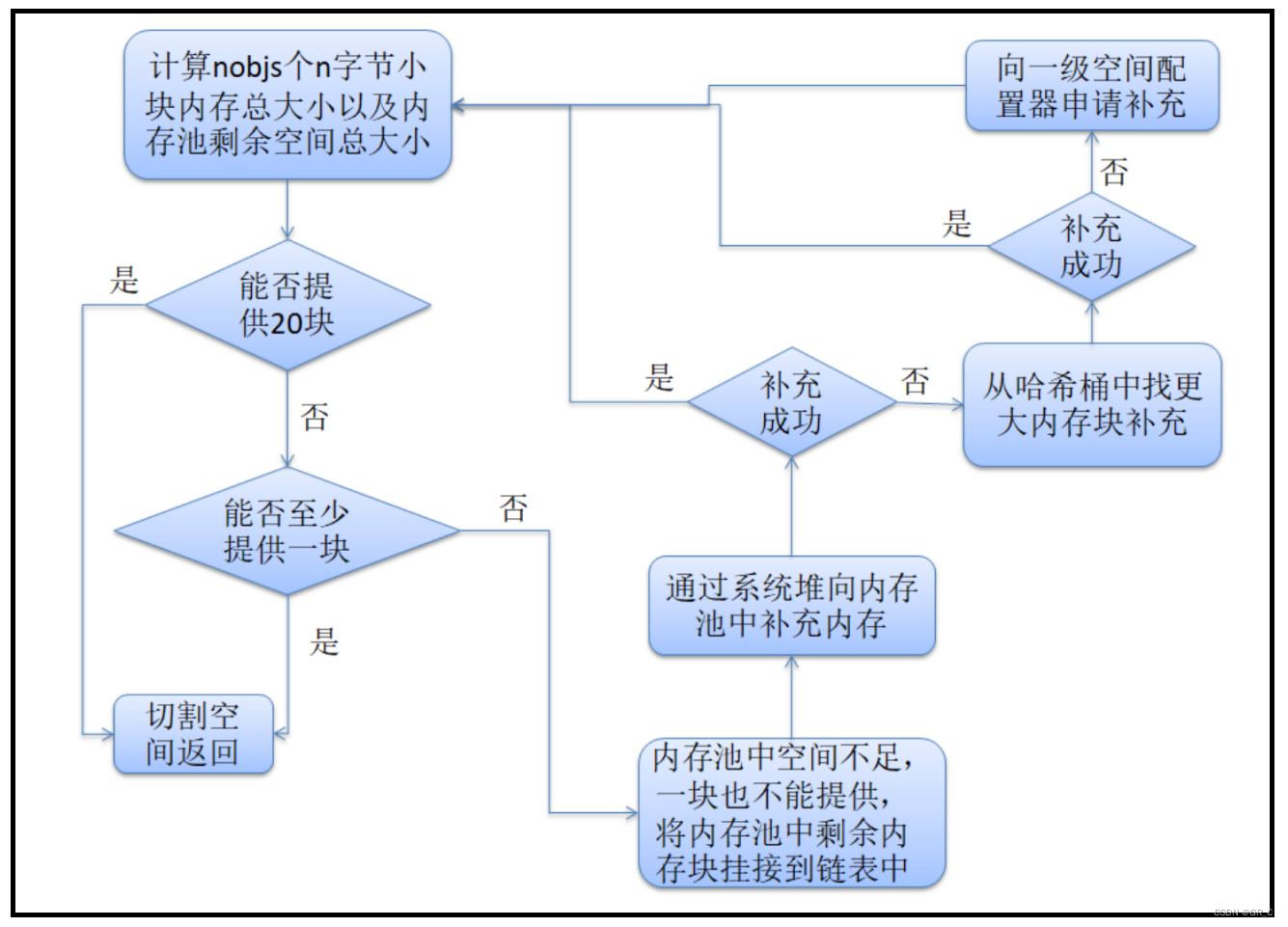
template <int inst>
char* __default_alloc_template<inst>::chunk_alloc(size_t size, int& nobjs)
{
// 计算nobjs个size字节内存块的总大小以及内存池中剩余空间总大小
char* result;
size_t total_bytes = size * nobjs;
size_t bytes_left = end_free - start_free;
// 如果内存池可以提供total_bytes字节,返回
if (bytes_left >= total_bytes)
{
result = start_free;
start_free += total_bytes;
return(result);
}
else if (bytes_left >= size)
{
// nobjs块无法提供,但是至少可以提供1块size字节内存块,提供后返回
nobjs = bytes_left / size;
total_bytes = size * nobjs;
result = start_free;
start_free += total_bytes;
return(result);
}
else
{
// 内存池空间不足,连一块小块村内都不能提供
// 向系统堆求助,往内存池中补充空间
// 计算向内存中补充空间大小:本次空间总大小两倍 + 向系统申请总大小/16
size_t bytes_to_get = 2 * total_bytes + ROUND_UP(heap_size >> 4);
// 如果内存池有剩余空间(该空间一定是8的整数倍),将该空间挂到对应哈希桶中
if (bytes_left > 0)
{
// 找对用哈希桶,将剩余空间挂在其上
obj** my_free_list = free_list + FREELIST_INDEX(bytes_left);
((obj*)start_free)->free_list_link = *my_free_list;
*my_ree_list = (obj*)start_free;
}
// 通过系统堆向内存池补充空间,如果补充成功,递归继续分配
start_free = (char*)malloc(bytes_to_get);
if (0 == start_free)
{
// 通过系统堆补充空间失败,在哈希桶中找是否有没有使用的较大的内存块
int i;
obj** my_free_list, * p;
for (i = size; i <= __MAX_BYTES; i += __ALIGN)
{
my_free_list = free_list + FREELIST_INDEX(i);
p = *my_free_list;
// 如果有,将该内存块补充进内存池,递归继续分配
if (0 != p)
{
*my_free_list = p->free_list_link;
start_free = (char*)p;
end_free = start_free + i;
return(chunk_alloc(size, nobjs));
}
}
// 山穷水尽,只能向一级空间配置器求助
// 注意:此处一定要将end_free置空,因为一级空间配置器一旦抛异常就会出问题
end_free = 0;
start_free = (char*)malloc_alloc::allocate(bytes_to_get);
}
// 通过系统堆向内存池补充空间成功,更新信息并继续分配
heap_size += bytes_to_get;
end_free = start_free + bytes_to_get;
return(chunk_alloc(size, nobjs));
}
}3.4 二级空间配置器的空间回收

// 函数功能:用户将空间归还给空间配置器
// 参数:p空间首地址 n空间总大小
static void deallocate(void* p, size_t n)
{
obj* q = (obj*)p;
obj** my_free_list;
// 如果空间不是小块内存,交给一级空间配置器回收
if (n > (size_t)__MAX_BYTES)
{
malloc_alloc::deallocate(p, n);
return;
}
// 找到对应的哈希桶,将内存挂在哈希桶中
my_free_list = free_list + FREELIST_INDEX(n);
q->free_list_link = *my_free_list;
*my_free_list = q;
}3.5 对象构造与释放和与容器结合
一切为了效率考虑,SGI-STL决定将空间申请释放和对象的构造析构两个过程分离开,因为有些对 象的构造不需要调用析构函数,销毁时不需要调用析构函数,将该过程分离开可以提高程序的性 能:
// 归还空间时,先先调用该函数将对象中资源清理掉
template <class T>
inline void destroy(T* pointer)
{
pointer->~T();
}
// 空间申请好后调用该函数:利用placement-new完成对象的构造
template <class T1, class T2>
inline void construct(T1* p, const T2& value)
{
new (p) T1(value);
}① 在释放对象时,需要根据对象的类型确定是否调用析构函数(类型萃取)
② 对象的类型可以通过迭代器获萃取到
以上两步在实现时稍微有点复杂,有兴趣可参考STL源码。
这里给出list与空间配置器是如何结合的,大家参考可给出vector的实现。
template <class T, class Alloc = alloc>
class list
{
// ...
// 实例化空间配置器
typedef simple_alloc<list_node, Alloc> list_node_allocator;
// ...
protected:
link_type get_node()
{
// 调用空间配置器接口先申请节点的空间
return list_node_allocator::allocate();
}
// 将节点归还给空间配置器
void put_node(link_type p)
{
list_node_allocator::deallocate(p);
}
// 创建节点:1. 申请空间 2. 完成节点构造
link_type create_node(const T& x)
{
link_type p = get_node();
construct(&p->data, x);
return p;
}
// 销毁节点: 1. 调用析构函数清理节点中资源 2. 将节点空间归还给空间配置器
void destroy_node(link_type p)
{
destroy(&p->data);
put_node(p);
}
// ...
iterator insert(iterator position, const T& x)
{
link_type tmp = create_node(x);
tmp->next = position.node;
tmp->prev = position.node->prev;
(link_type(position.node->prev))->next = tmp;
position.node->prev = tmp;
return tmp;
}
iterator erase(iterator position)
{
link_type next_node = link_type(position.node->next);
link_type prev_node = link_type(position.node->prev);
prev_node->next = next_node;
next_node->prev = prev_node;
destroy_node(position.node);
return iterator(next_node);
}
// ...
};空间配置器只会存在一个,所以可以也是一个单例对象,不同的容器甚至是不同线程都可以使用。比如map归还的空间set可以继续使用。
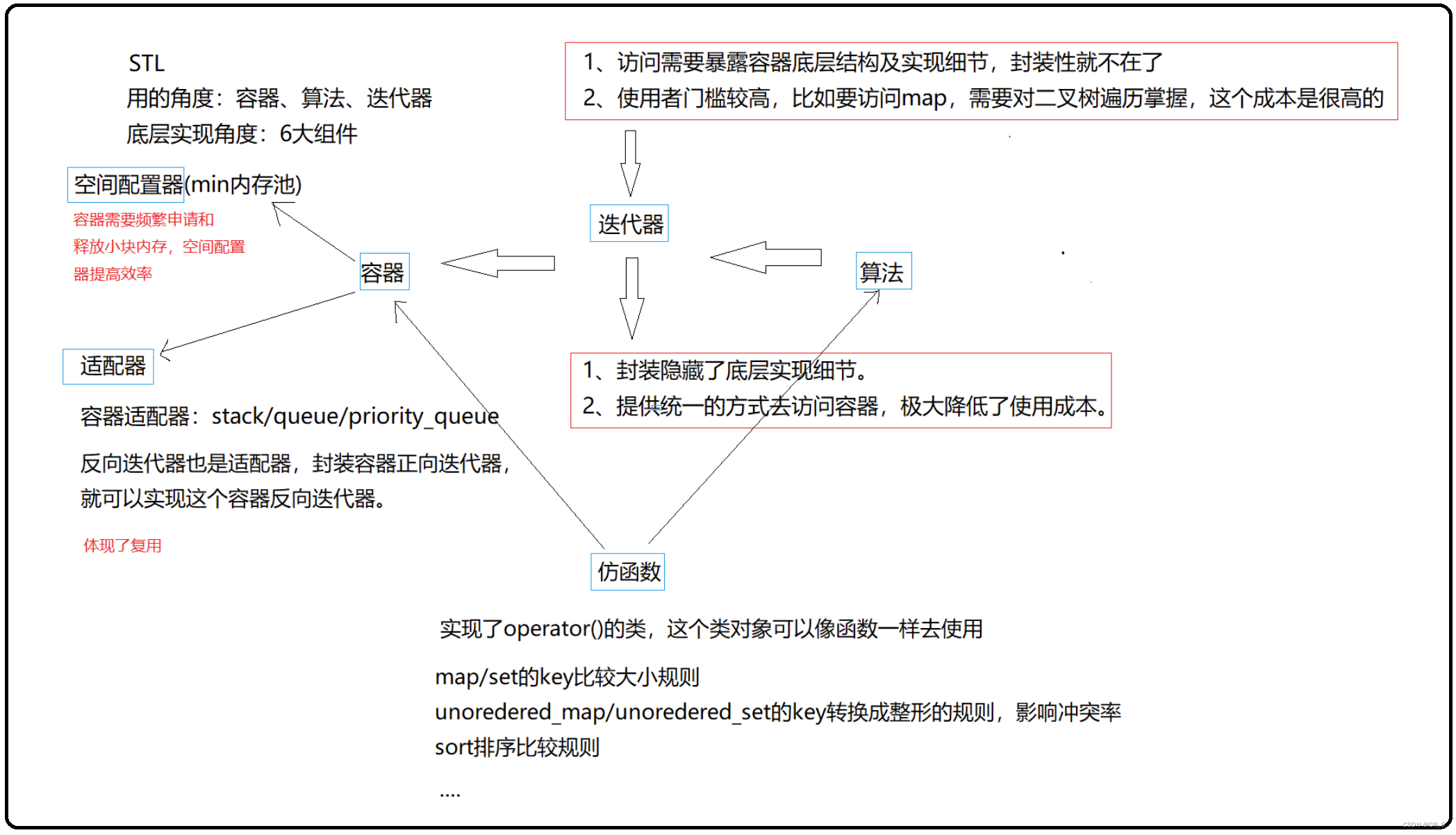
4. STL六大组件联系
STL 提供了六大组件,而从代码广义上讲,主要分为三类:container(容器)、iterator(迭代器)和 algorithm(算法),几乎所有的代码都采用了模板类和模版函数的方式,这相比于传统的由函数和类组成的库来说提供了更好的代码重用机会。
算法、容器、迭代器三者的关系是:算法操作数据,容器存储数据,迭代器是算法操作容器的桥梁,迭代器与容器一一对应。如下图所示:
STL 的中心思想在于将数据容器(Containers)和算法(Algorithm)分开,彼此独立设计,最后以一帖胶着剂将它们撮合在一起。
STL 的一个重要特点是数据结构和算法的分离。正是这种分离设计,使得 STL 变得非常通用。例如,由于 STL 的 sort() 函数是完全通用的,你可以用它来操作几乎任何数据集合,包括链表,容器和数组。
STL 另一个重要特性是它不是面向对象的。为了具有足够通用性,STL 主要依赖于模板,而不是 OOP 的三个要素 —— 封装、继承和虚函数(多态性),这使得你在 STL 中找不到任何明显的类继承关系。
这里再贴一张图有利于复习:
本篇完。
C++到这基本介绍了,有时间可以回去复习复习,还有一两篇关于多线程的问题放到Linux操作系统之后再放出来了,
下一篇:从C语言到C++_39(C++笔试面试题)总结复习。
下下篇:零基础Linux_1(前期准备)Linux发展史和环境安装。