一.I/O复用
(一)基于I/O复用的服务器端
1.多进程服务器
每次服务都需要创建一个进程,需要大量的运算和内存空间
2.复用
只需创建一个进程。
3.复用技术在服务器端的应用
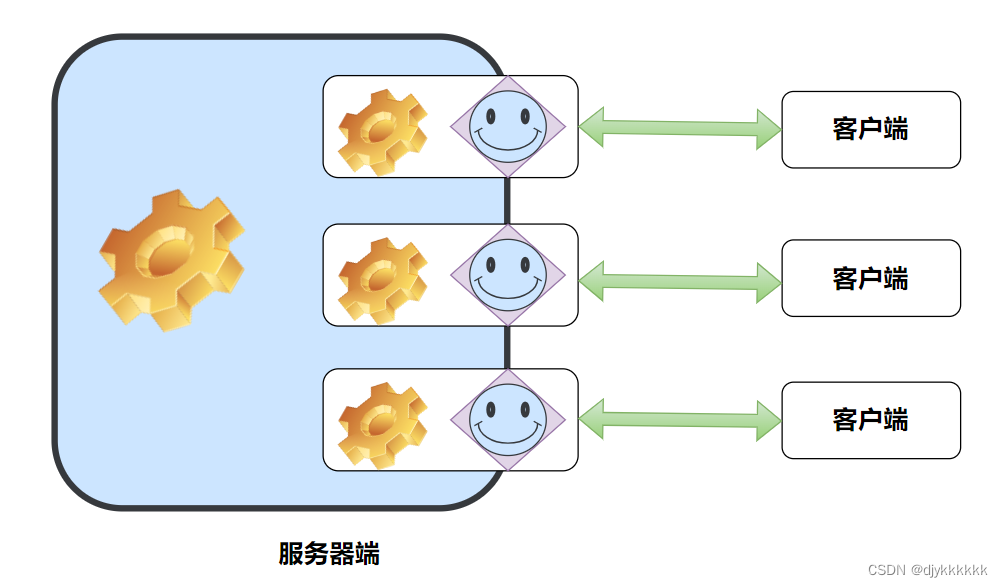

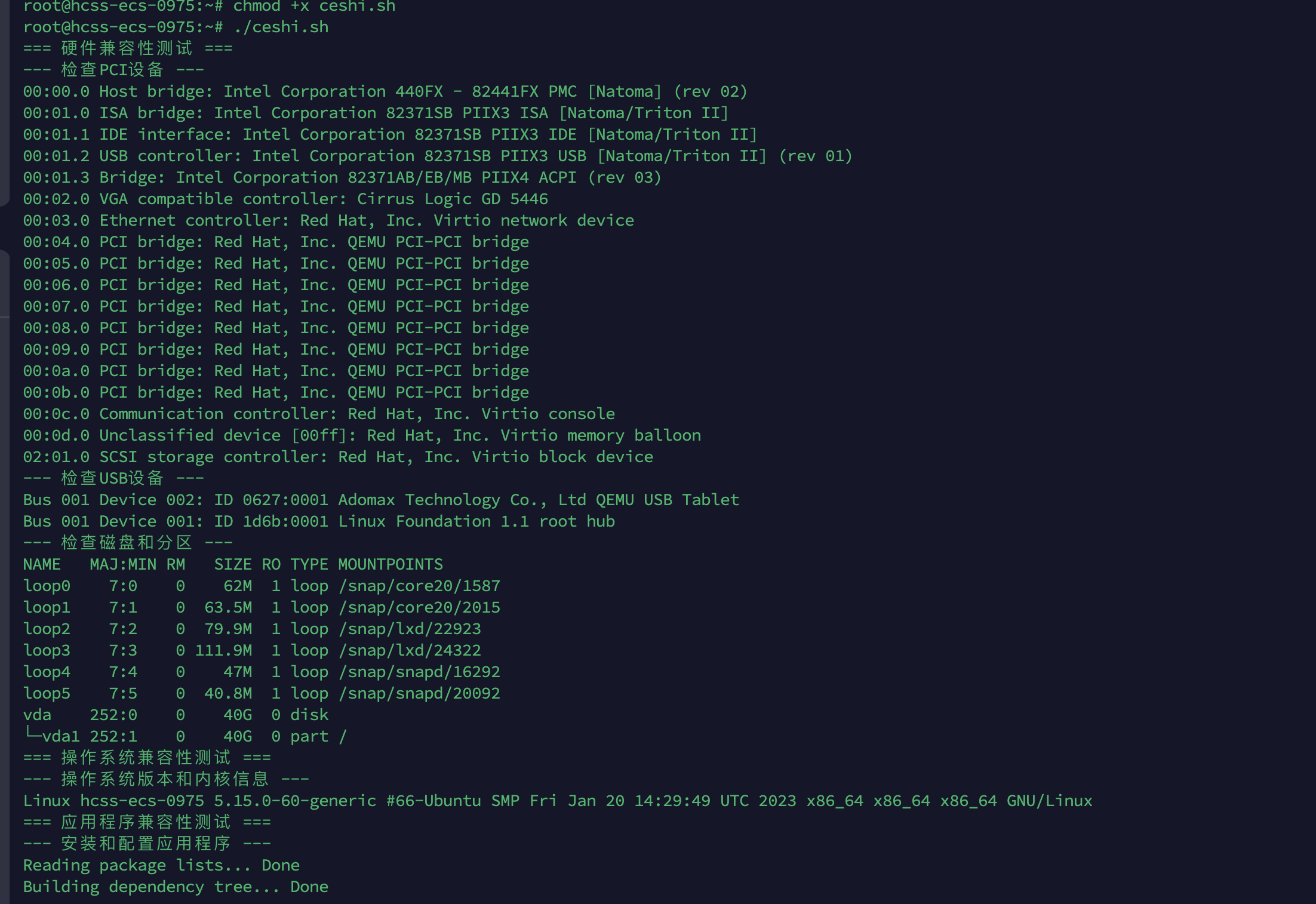
(二)select函数实现服务器端
- (Linux和Windows平台下均有select函数,所以具有良好移植性)
1.select函数调用过程:
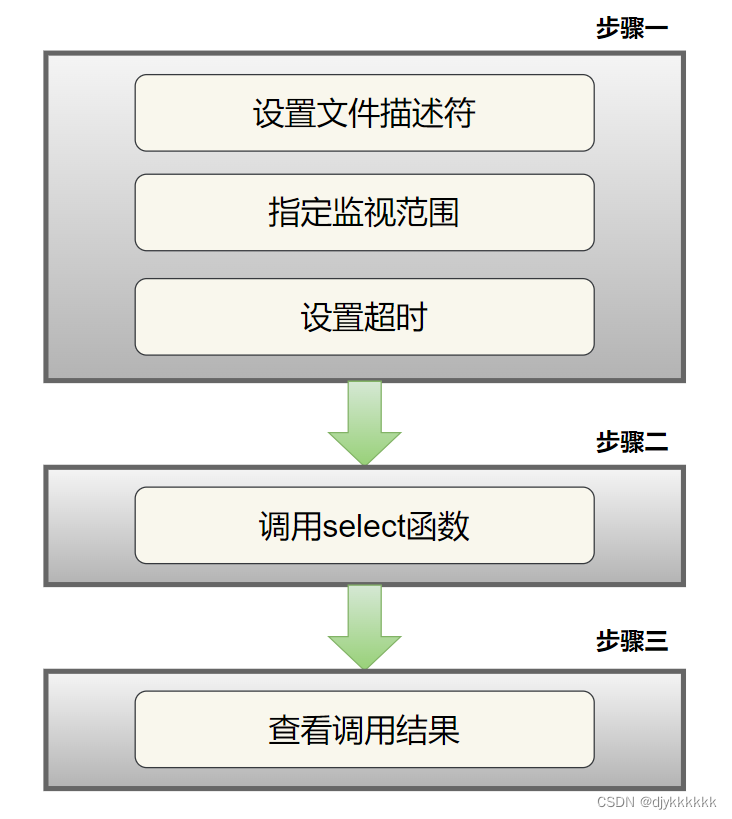
2.select函数示例:(5秒内控制才没有输入,就输出 Timeout ;否则打印输入。)
#include<iostream>
#include<unistd.h>
#include<sys/time.h>
#include<sys/select.h>
using namespace std;
#define BUF_SIZE 30
int main(int argc,char *argv[]){
fd_set reads,temps;
int result,str_len;//fd_set类型是一个文件描述符集合,
char buf[BUF_SIZE];//在这里声明了reads和temps两个集合用于I/O复用。
struct timeval timeout;
FD_ZERO(&reads);//用于清空文件描述符集合。
FD_SET(0,&reads);//将标准输入文件描述符添加到集合中
while(1){
temps=reads;//在每次循环开始时,将temps设置为上一次存有文件描述符的集合reads的副本。
timeout.tv_sec=5;//设置超时时间为5秒
timeout.tv_usec=0;
result=select(1,&temps,0,0,&timeout);调用select函数来等待可读事件就绪或超时发生。
if(result==-1){//第一个参数表示要监视的最大文件描述符值加1,
cout<<"select() error"<<endl;//第二个参数是指向待检查的文件描述符集合的指针,
break; //后面的三个参数是输出参数。
}
else if(result==0)
cout<<"Time out"<<endl;
else{
if(FD_ISSET(0,&temps))//检查输入文件描述符是否就绪
{
str_len=read(0,buf,BUF_SIZE);
buf[str_len]=0;
cout<<"message from console: "<<buf<<endl;
}
}
//如果select函数返回-1,表示出现了错误,输出错误信息并跳出循环。
//如果select函数返回0,表示超时,输出"Time out"。
//如果select函数返回大于0的值,表示文件描述符就绪。
//这里通过FD_ISSET宏检查标准输入文件描述符是否在集合中就绪。
//如果标准输入文件描述符就绪,调用read函数读取输入内容,并输出到控制台。
}
return 0;
}

3.实现I/O复用服务器端
#include<iostream>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<arpa/inet.h>
#include<sys/socket.h>
#include<sys/time.h>
#include<sys/select.h>
using namespace std;
#define BUF_SIZE 100//宏定义了一个缓冲区大小为100的常量。
void error_handling(const char *buf);
int main(int argc,char *argv[]){
int serv_sock,clnt_sock;
struct sockaddr_in serv_adr,clnt_adr;
struct timeval timeout;
fd_set reads,cpy_reads;
socklen_t adr_sz;
int fd_max,str_len,fd_num,i;
char buf[BUF_SIZE];
if(argc!=2){
cout<<"Usage:"<<argv[0]<<endl;
exit(1);
}
serv_sock=socket(PF_INET,SOCK_STREAM,0);//创建套接字
memset(&serv_adr,0,sizeof(serv_adr));//将结构体清零
serv_adr.sin_family=AF_INET;
serv_adr.sin_addr.s_addr=htonl(INADDR_ANY);//设置服务器地址信息、IP地址和端口号
serv_adr.sin_port=htons(atoi(argv[1]));
if(bind(serv_sock,(struct sockaddr*)&serv_adr,sizeof(serv_adr))==-1)
error_handling("bind() error"); //将套接字和指定地址绑定
if(listen(serv_sock,5)==-1)//开始监听连接请求
error_handling("listen() error");
FD_ZERO(&reads);//清空文件描述符集合
FD_SET(serv_sock,&reads);//将服务器套接字添加到reads集合中
fd_max=serv_sock;//fd_max初始化为服务器套接字的值
while(1){//进入主循环
cpy_reads=reads;//将reads集合复制过来
timeout.tv_sec=5;//超时时间
timeout.tv_usec=5000;
if((fd_num=select(fd_max+1,&cpy_reads,0,0,&timeout))==-1)
break; //监控文件描述符的状态变化
if(fd_num==0)
continue;
for(i=0;i<fd_max+1;i++){
if(FD_ISSET(i,&cpy_reads)){//检查文件描述符是否就绪
if(i==serv_sock){//如果是服务器套接字,表示有新的客户端连接请求
adr_sz=sizeof(clnt_adr);
clnt_sock=
accept(serv_sock,(struct sockaddr*)&clnt_adr,&adr_sz);
FD_SET(clnt_sock,&reads);
if(fd_max<clnt_sock)
fd_max=clnt_sock;
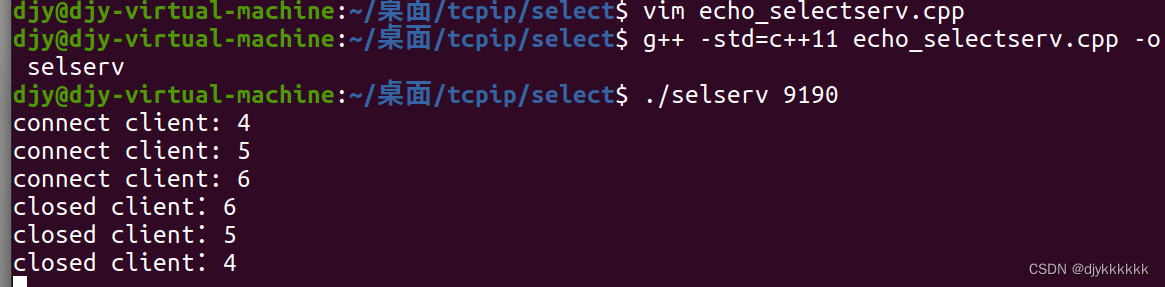
cout<<"connect client: "<<clnt_sock<<endl;
}
else{//如果不是服务器套接字,表示已连接的客户端有数据发送过来
str_len=read(i,buf,BUF_SIZE);
if(str_len==0){
FD_CLR(i,&reads);
close(i);
cout<<"closed client:"<<i<<endl;
}
else
write(i,buf,str_len);
}
}
}
}
close(serv_sock);
return 0;
}
void error_handling(const char *buf){
cout<<buf<<endl;
exit(1);
}
(三)总结
1.请解释复用技术的通用含义,并说明何为I/O复用。
复用技术指为了提高物理设备的效率,用最少的物理要素传递最多数据时使用的技术。同样,I/O复用是指将需要I/O的套接字捆绑在一起,利用最少限度的资源来收发数据的技术。
2.多进程并发服务器的缺点有哪些?如何在I/O复用服务器端中弥补?
多进程并发服务器的服务方式是,每当客户端提出连接要求时,就会追加生成进程。但构建进程是一项非常有负担的工作,因此,向众多客户端提供服务存在一定的局限性。而复用服务器则是将套接字的文件描述符捆绑在一起管理的方式,因此可以一个进程管理所有的I/O操作。
3.select函数的观察对象中应包含服务器端套接字(监听套接字),那么应将其包含到哪一类监听对象集合?请说明原因
服务器套接字的作用是监听有无连接请求,即判断接收的连接请求是否存在?应该将其包含到“读”类监听对象的集合中。
4.select函数使用的fd_set结构体在Windows和Linux中具有不同的声明。请说明却别,同时解释存在区别的必然性
Linux的文件描述符从0开始递增,因此可以找出当前文件描述符数量和最后生成的文件描述符之间的关系。但Windows的套接字句柄并非从0开始,并且句柄的整数值之间并无规律可循,因此需要直接保存句柄的数组和记录句柄数的变量。
二.多种I/O函数
(一)send & recv 函数
send()和recv()函数是在网络编程中常用的函数,用于发送和接收数据。
send()函数用于将数据从一个套接字发送到另一个套接字。它的语法如下:
ssize_t send(int sockfd, const void *buf, size_t len, int flags)
其中,sockfd是指定发送数据的套接字文件描述符;buf是要发送的数据的缓冲区;len是要发送的数据的长度;flags是可选参数,用于指定发送操作的行为。
send()函数的返回值是实际发送的字节数,如果发生错误,则返回-1。
recv()函数用于从套接字接收数据。它的语法如下:
ssize_t recv(int sockfd, void *buf, size_t len, int flags)
其中,sockfd是指定接收数据的套接字文件描述符;buf是接收数据的缓冲区;len是接收数据缓冲区的大小;flags是可选参数,用于指定接收操作的行为。
recv()函数的返回值是实际接收的字节数,如果连接关闭或发生错误,则返回0或-1。
这两个函数的使用注意事项如下:
- 在使用
send()函数发送数据之前,需要确保已经建立了有效的网络连接,并且发送端和接收端的套接字都处于可用状态。 send()函数可能会一次发送不完整的数据,因此在需要发送较大数据量时,可能需要使用循环来多次调用send()函数直到全部数据发送完毕。recv()函数可能会一次接收不完整的数据,因此在需要接收较大数据量时,可能需要使用循环来多次调用recv()函数直到获取到所需的全部数据。recv()函数会阻塞程序执行,直到接收到数据或发生错误。如果不希望阻塞,可以使用非阻塞模式或设置超时时间。- 在使用
recv()函数接收数据之前,需要确保有数据可接收,否则可能会一直阻塞等待。
(二)readv & writev 函数
readv()和writev()函数是在UNIX系统中用于进行多缓冲区的读写操作。
readv()函数用于从文件描述符中读取数据到多个缓冲区中,其原型如下:
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
其中,fd是文件描述符,iov是指向一个iovec结构体数组的指针,而iovcnt是iovec结构体数组的长度。iovec结构体定义如下:
struct iovec {
void *iov_base; // 缓冲区的起始地址
size_t iov_len; // 缓冲区的大小
};
readv()函数会按照iovec结构体数组的顺序将数据读取到对应的缓冲区中,并返回实际读取的字节数。如果发生错误,返回值为-1。
相对应地,writev()函数用于将多个缓冲区的数据写入到文件描述符中,其原型如下:
#include <sys/uio.h>
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
参数和返回值与readv()函数类似,只是作用相反。
这两个函数的优势在于可以通过一次系统调用完成多个缓冲区的读写操作,减少了系统调用的次数,提高了效率。它们常用于网络编程中的批量读写操作或者对数据进行分散和收集。
以下是一个简单的示例代码,演示了readv()和writev()函数的使用:
#include <iostream>
#include <sys/uio.h>
#include <unistd.h>
int main() {
// 缓冲区1
char buffer1[5];
// 缓冲区2
char buffer2[10];
struct iovec iov[2];
iov[0].iov_base = buffer1;
iov[0].iov_len = sizeof(buffer1);
iov[1].iov_base = buffer2;
iov[1].iov_len = sizeof(buffer2);
// 从标准输入读取数据到两个缓冲区中
ssize_t bytesRead = readv(STDIN_FILENO, iov, 2);
if (bytesRead == -1) {
std::cerr << "Failed to read data." << std::endl;
return 1;
}
// 将读取的数据写入到标准输出
ssize_t bytesWritten = writev(STDOUT_FILENO, iov, 2);
if (bytesWritten == -1) {
std::cerr << "Failed to write data." << std::endl;
return 1;
}
return 0;
}
上述示例代码演示了从标准输入读取数据到两个缓冲区中,然后将数据写入到标准输出。在实际应用中,可以根据需要自定义缓冲区的数量和大小,以及具体的读写逻辑。
需要注意的是,readv()和writev()函数一般用于原始的文件描述符读写操作,而不适用于C++的流式I/O。在C++中,可以使用std::ifstream和std::ofstream等类进行高级的文件读写操作。
(三)总结
1.利用readv&writev函数收发数据有何优点?分别从函数调用次数和I/O缓冲的角度给出说明。
readv&writev函数可以将分散保存在多个缓冲中的数据一并接受和发送,是对数据进行整合传输及发送的函数,因此可以进行更有效的数据传输。而且,输入输出函数的调用次数也相应减少,也会产生相应的优势。
2.通过recv函数见证输入缓冲是否存在数据时(确认后立即返回),如何设置recv函数最后一个参数中的可选项?分别说明各可选项的含义。
同时设置MSG_PEEK选项和MSG_DONTWAIT选项,以验证输入缓冲是否存在可接收的数据。设置MSG_PEEK选项并调用recv函数时,即使读取了输入缓冲数据也不会删除。因此,该选项通常与MSG_DONTWAIT合作,用于调用以非阻塞方式验证待读数据存在与否的函数。
3.可在Linux平台通过注册时间处理函数接收MSG_OOB数据。那Windows中如何接受?请说明接收方法。
MSG_OOB数据的接收,在select函数中属于异常数据,既在Windows中可以通过异常处理来接收Out-of-band数据。
三.多播和广播
多播(Multicast)和广播(Broadcast)都是在网络通信中用于向多个主机发送数据的方式,但它们有一些区别。
广播是将数据包发送到网络中的所有主机,无论它们是否订阅或感兴趣。发送广播消息时,源主机会将数据包发送到本地网络上的广播地址,而目标主机位于该网络上的所有设备都可以接收到这个消息。广播是一个简单且容易实现的方式,适用于需要向同一网络中的所有设备进行通信的场景。
多播是将数据包发送到一个特定的多播组,只有加入(或订阅)了该多播组的主机才能接收到数据包。多播使用专门的多播地址范围来标识不同的多播组,而不是发送到广播地址。多播适用于需要向特定组中的成员进行通信的场景,例如视频流、音频流等。
(一)多播
(1)多播的数据传输方式及流量方面的优点
-
节省带宽和网络资源:多播采用一对多的传输方式,只需一次发送就可以让多个目标主机接收数据,避免了单独向每个目标主机发送数据的开销,节省了网络带宽和网络资源的使用。
-
降低网络负载:由于多播只在需要的主机中传递数据,不会像广播一样向整个网络发送数据,因此可以减少网络中的流量和负载。这对于大规模的分布式系统、视频流、音频流等应用场景非常重要。
-
灵活性和可扩展性:多播可以支持动态加入和退出多播组的成员,使得系统具有较好的灵活性和可扩展性。新的成员可以根据需要加入特定的多播组,而不会影响其他成员的正常通信。
-
实时性和效率:多播传输方式能够提供较低的延迟和更高的效率。特别是对于实时应用程序或需要快速传输大量数据的场景,多播能够更好地满足需求。
-
支持广域网(WAN)和互联网通信:多播不受限于局域网,可以跨越不同的子网和网络边界进行传输。这使得多播在广域网和互联网通信中具有重要的应用价值,例如IP视频会议、流媒体传输等。
需要注意的是,多播的实现和支持需要网络设备(如路由器和交换机)和操作系统的支持,并且需要合适的网络协议(如IGMP)来管理多播组成员和传输。此外,多播的可用性也受网络拓扑、设备配置和网络策略的影响。因此,在使用多播之前,需要确保网络环境和设备都能够支持多播功能,并进行适当的配置和管理。
(2)路由(Routing)和TTL(TIme to Live,生存时间),以及加入组的方法
-
路由(Routing):路由是指在网络中选择数据包传输路径的过程。在多播通信中,路由器根据多播组地址和网络拓扑信息来决定如何将数据包从源主机传输到接收多播数据的目标主机。路由器使用多播路由协议(如PIM、IGMP等)来确定哪些网络接口具有对应多播组的成员,并将数据包转发到这些接口上,以便让接收方能够接收到多播数据。
-
TTL(Time to Live):TTL是一个在IP数据包头部中的字段,用于限制数据包在网络中的生存时间。它表示数据包经过路由器时可经过的最大跳数(即经过的路由器数量)。每经过一个路由器,TTL值就会减少1。当TTL的值达到0时,路由器会丢弃该数据包并发送一个“Time Exceeded”消息给源主机。TTL的作用是防止数据包在网络中无限循环,以避免网络拥塞和资源浪费。在多播中,TTL值常常用来控制多播数据包的范围,确保它仅限于特定的多播域或子网。
-
加入组的方法:通过加入(或订阅)多播组,主机表明它希望接收特定多播组的数据包。具体的加入组方法和实现细节取决于网络协议和操作系统的支持。
-
IGMP(Internet Group Management Protocol):用于IPv4环境中的多播组成员管理。主机可以通过发送IGMP报文向路由器表明它想要加入或离开某个特定的多播组。
-
MLD(Multicast Listener Discovery):用于IPv6环境中的多播组成员管理。主机可以通过发送MLD报文向路由器表明它想要加入或离开某个特定的多播组。
-
在编程语言中使用Socket API:编程语言提供的Socket API通常也提供了与多播相关的函数和选项,可以使用这些函数和选项来实现加入多播组的操作。
-
(二)广播
在网络编程中,广播是指将数据包从一个发送者发送到同一网络中的所有接收者的通信方式。广播可以用于向局域网(LAN)中的所有设备发送消息或通知。
实现网络广播有以下几种方法:
-
广播IP地址:每个局域网都有一个特殊的广播IP地址,通常是该子网的最后一个IP地址。发送者可以将数据包目标IP地址设置为广播IP地址,然后将数据包发送到局域网上。路由器会将该数据包传递给所有连接到该局域网的设备。
-
广播套接字:在网络编程中,可以使用广播套接字来发送和接收广播消息。使用广播套接字,发送者可以将消息发送到特定的广播地址,并且所有监听该广播地址的接收者都可以接收到该消息。在使用广播套接字时,需要注意设置套接字的选项,以启用广播功能。
(三)总结
1.TTL的含义是什么?请从路由器的角度说明较大的TTL值与较小的TTL值之间的区别及问题
TTL是Time to Live的缩写,是决定“信息传递距离”的主要因素。TTL表现为整数,没经过一个路由器就减1。如果该值为0,该数据报就会因无法再传递而消失。TTL设置大了会对网络流量造成不良影响,设置太小的话,就可能无法到达目的地。
2.多播和广播的异同是什么?请从数据通信的角度进行说明
多播和广播的相同点是,两者都是以UDP形式传输数据。一次传输数据,可以向两个以上主机传送数据。但传送的范围是不同的:广播是对局域网的广播;而多播是对网络注册机器的多播。
3.多播也对网络流量有利,请比较TCP数据交换方式解释其原因。
多播数据在路由器进行复制。因此,即使主机数量很多,如果各主机存在的相同路径,也可以通过一次数据传输到多台主机上。但TCP无论路径如何,都要根据主机数量进行数据传输。
4.多播方式的数据通信需要MBone虚拟网络。换言之,MBone是用于多播的网络,但它是虚拟网络。请解释此处“虚拟网络”。
以物理网络为基础,通过软件方法实现的多播通信必备的虚拟网络。