DDPG算法
news2026/2/12 9:02:19

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/981390.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

ChartJS使用-环境搭建(vue)
1、介绍
Chartjs简约不简单的JavaScript的图表库。官网https://chart.nodejs.cn/ Chart.js 带有内置的 TypeScript 类型,并与所有流行的 JavaScript 框架 兼容,包括 React 、Vue 、Svelte 和 Angular 。 你可以直接使用 Chart.js 或利用维护良好的封装程…
单片机第三季-第一课:STM32基础
官方网址:STMCU中文官网
STM32系列分类: 型号命名原则: STM32F103系列: 涉及到的几个概念:
DMA:Direct Memory Access,直接存储器访问。DMA传输将数据从一个地址空间复制到另一个地址空间&…

机器学习:基于梯度下降算法的逻辑回归实现和原理解析
这里写目录标题 什么是逻辑回归?Sigmoid函数逻辑回归损失函数梯度下降 逻辑回归定义逻辑函数线性组合模型训练决策边界 了解逻辑回归:从原理到实现什么是逻辑回归?逻辑回归的原理逻辑回归的实现逻辑回归的应用代码示例算法可视化 当涉及到二元…
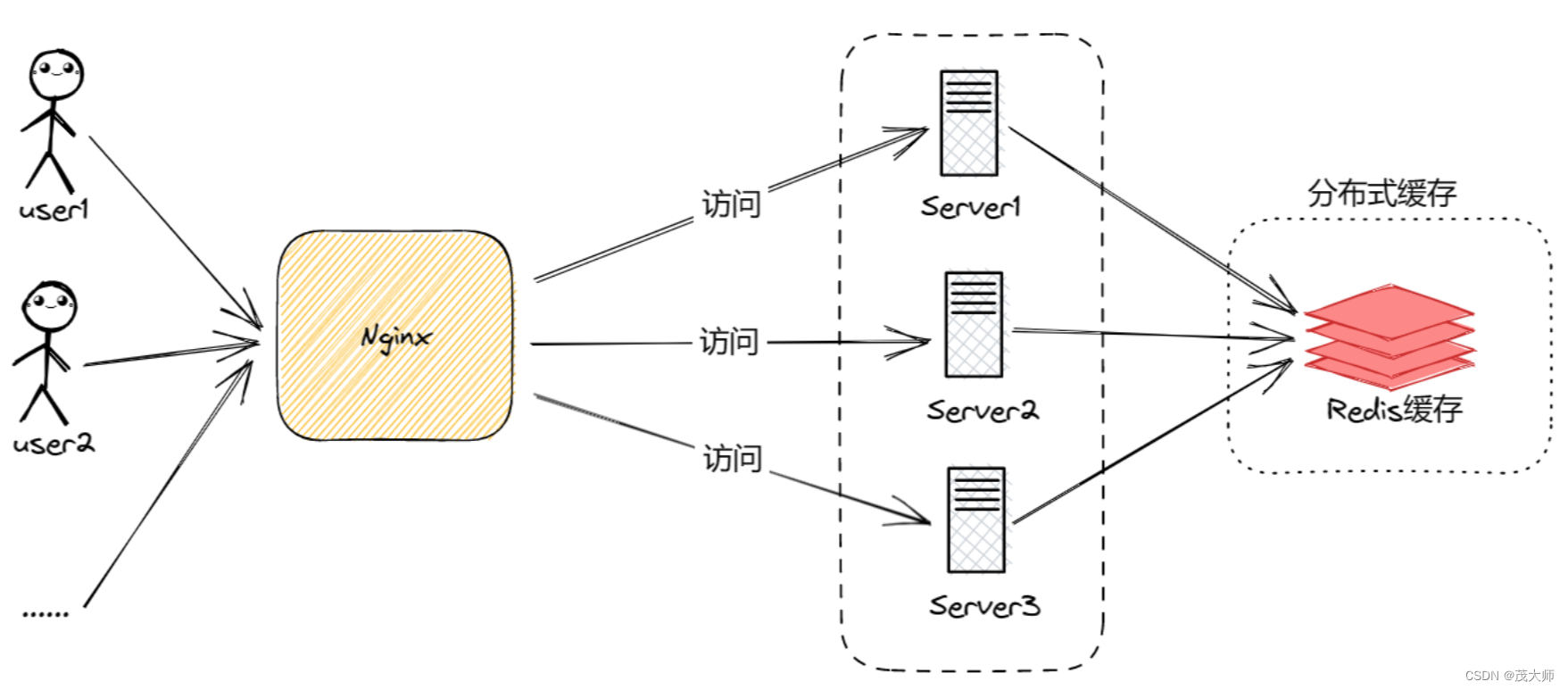
2023.8.1 Redis 的基本介绍
目录 Redis 的介绍
Redis 用作缓存和存储 session 信息
Redis 用作数据库
消息队列
消息队列是什么?
Redis 用作消息队列 Redis 的介绍 特点: 内存中存储数据:奠定了 Redis 进行访问和存储时的快可编程性:支持使用 Lua 编写脚…
mp4压缩视频不改变画质?跟我这样压缩视频大小
在当今数字化时代,视频文件变得越来越普遍,然而,这些文件通常都很大,给存储和传输带来了困难,为了解决这个问题,许多人都希望将视频压缩得更小,而又不牺牲画质,下面就来看看具体应该…
前端基础5——UI框架Layui
文章目录 一、基本使用二、管理后台布局2.1 导航栏2.2 主题颜色2.3 字体图标 三、栅格系统四、卡片面板五、面包屑六、按钮七、表单八、上传文件九、数据表格9.1 table模块常用参数9.2 创建表格9.3 表格分页9.4 表格工具栏9.5 表格查询9.5.1 搜索关键字查询9.5.2 选择框查询 9.…

RK3568平台开发系列讲解(音视频篇)H264 的编码结构
🚀返回专栏总目录 文章目录 一、H264 的编码结构1.1、帧类型1.2、GOP1.3、Slice沉淀、分享、成长,让自己和他人都能有所收获!😄 📢视频编码的码流结构其实就是指视频经过编码之后得到的二进制数据是怎么组织的,换句话说,就是编码后的码流我们怎么将一帧帧编码后的图像…

【Cisco Packet Tracer】管理方式,命令,接口trunk,VLAN
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …

日200亿次调用,喜马拉雅网关的架构设计
说在前面
在40岁老架构师 尼恩的读者社区(50)中,很多小伙伴拿到一线互联网企业如阿里、网易、有赞、希音、百度、滴滴的面试资格。
最近,尼恩指导一个小伙伴简历,写了一个《API网关项目》,此项目帮这个小伙拿到 字节/阿里/微博/…
【2023最新版】MySQL安装教程
目录
一、MySQL简介
二、MySQL安装
1. 官网
2. 下载
3. 安装
4. 配置环境变量 配置前
配置中
配置后
5. 验证 一、MySQL简介 MySQL是一种开源的关系型数据库管理系统(RDBMS),它被广泛用于存储和管理结构化数据。MySQL提供了强大的功…
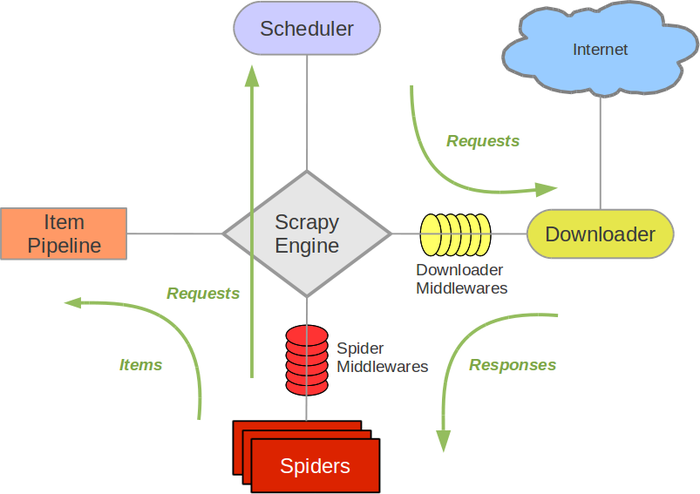
Scrapy简介-快速开始-项目实战-注意事项-踩坑之路
scrapy项目模板地址:https://github.com/w-x-x-w/Spider-Project
Scrapy简介
Scrapy是什么?
Scrapy是一个健壮的爬虫框架,可以从网站中提取需要的数据。是一个快速、简单、并且可扩展的方法。Scrapy使用了异步网络框架来处理网络通讯&…
![[管理与领导-75]:IT基层管理者 - 辅助技能 - 4- 乌卡时代(VUCA )的职业规划](https://img-blog.csdnimg.cn/a40cb2123dd44bff8c2fafa39ee8a3bf.png)
[管理与领导-75]:IT基层管理者 - 辅助技能 - 4- 乌卡时代(VUCA )的职业规划
目录
一、什么是职业规划的主要内容
二、乌卡时代的职业规划特点
2.1 时代特点
2.2 个人能力要求
三、乌卡时代如何做好职业规划 一、什么是职业规划的主要内容
职业规划是一个有目标和有策略的过程,通过此过程,个人能够发展和管理自己的职业生涯。…

GPDB-内核原理-如何指定发送数据目的地
GPDB-内核原理-如何指定发送数据目的地 GPDB是一个分布式数据库,数据存放在各个segment上。Master用于接收用户请求,并将执行计划发送到各个segment上去执行。各个segment将数据发送个master汇总并返回用户。当进行join,join条件不是分布键时…

3.3.2 【MySQL】客户端和服务器通信中的字符集
3.3.2.1 编码和解码使用的字符集不一致的后果
我们知道字符 我 在 utf8 字符集编码下的字节串长这样: 0xE68891 ,如果一个程序把这个字节串发送到另一个程序里,另一个程序用不同的字符集去解码这个字节串,假设使用的是 gbk 字符集…

【Ubuntu搭建MQTT Broker及面板+发布消息、订阅主题】
Ubuntu搭建MQTT Broker及面板发布消息、订阅主题
配置curl数据源
curl -s https://assets.emqx.com/scripts/install-emqx-deb.sh | sudo bash开始安装
sudo apt-get install emqx启动
sudo emqx start使用面板
根据自己的服务器是否开始了防火墙放行端口(1808…

【系统设计系列】 DNS和CDN
系统设计系列初衷 System Design Primer: 英文文档 GitHub - donnemartin/system-design-primer: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards.
中文版: https://github.com/donnemarti…
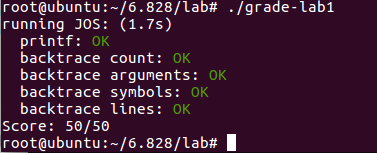
MIT6.828实验记录-Lab1
1.Lab1
刚刚入门,难度确实很大,大量的参考资料,知识点涉及的较深,好在每个实验,作者都给出了很多提示,让繁琐的实验变得有趣起来。逐个exercise进行,知识点有些断片,所以特意花点时…
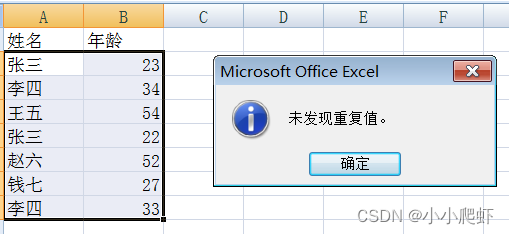
excel中删除重复项
数据如图: 要删除姓名这一列的重复项,操作:
(1)选中姓名这一列(2)点击“数据”(3)点击“删除重复项" 这是excel会自动检测出还有别的关联列 直接默认,点击删除重复项...弹出下面的界面 因为我们只要删除“姓名”列的重复值&…

C++智能指针之unique_ptr(保姆级教学)
目录
unique_ptr
概述
涉及程序
初始化
手动初始化
std::make_unique函数(C14)
unique_ptr常规操作
不支持操作:该指针不支持拷贝和赋值操作;所以不能拷贝到容器里
移动语义std::move();
release();
reset();
*解应用…
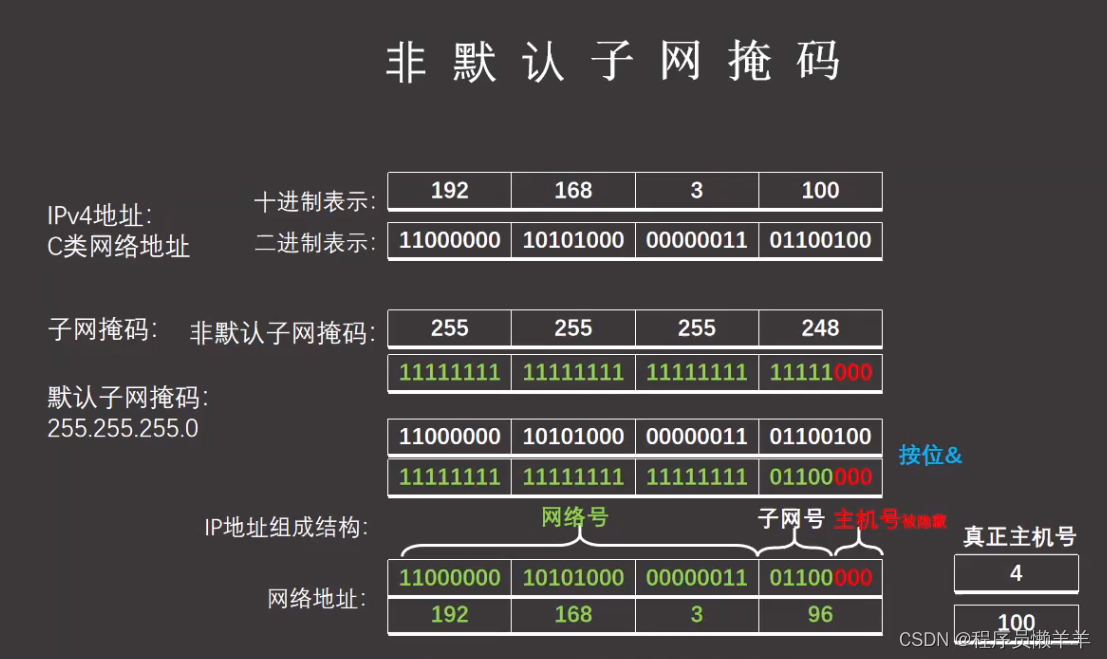
【计算机网络】 子网划分
文章目录 IP地址分类子网掩码网关广播地址非默认子网掩码子网划分常见问题 IP地址分类 学会十进制和二进制的相互转换可以很快速的有规律的记住
子网掩码
又叫网络掩码,地址掩码,子网络遮罩,就是说把子网络遮起来,不让外界窥探到…