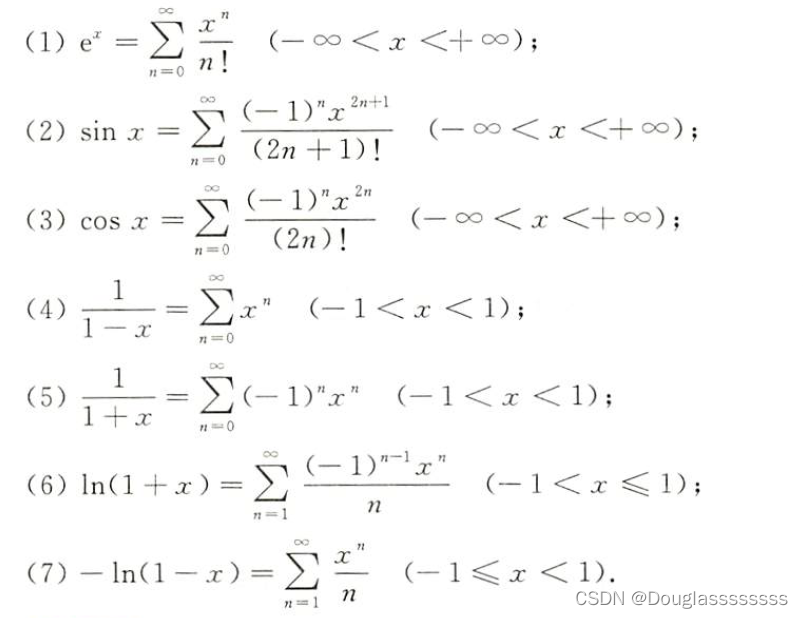文章目录
- Q1、SpringBoot可以同时处理多少请求
- Q2、SpringBoot如何优化启动速度
- Q3、谈谈对Spring的理解
- Q4、Spring的优缺点
Q1、SpringBoot可以同时处理多少请求
调试:
写一个测试接口:
@RestController
@Slf4j
public class RequestController{
@GetMapping("/test")
public String test(HttpServletRequest request) throws Exception{
log.info("线程:{}",Thread.currentThread().getName());
Thread.sleep(2000); //睡两秒
return "success";
}
}
服务配置中的相关参数:
server:
tomcat:
threads:
# 最少线程数
min-spare: 10
# 最多线程数
max: 20
# 最大连接数
max-connections: 30
# 最大等待数
accept-count: 10
此时,JMeter模拟100QPS:
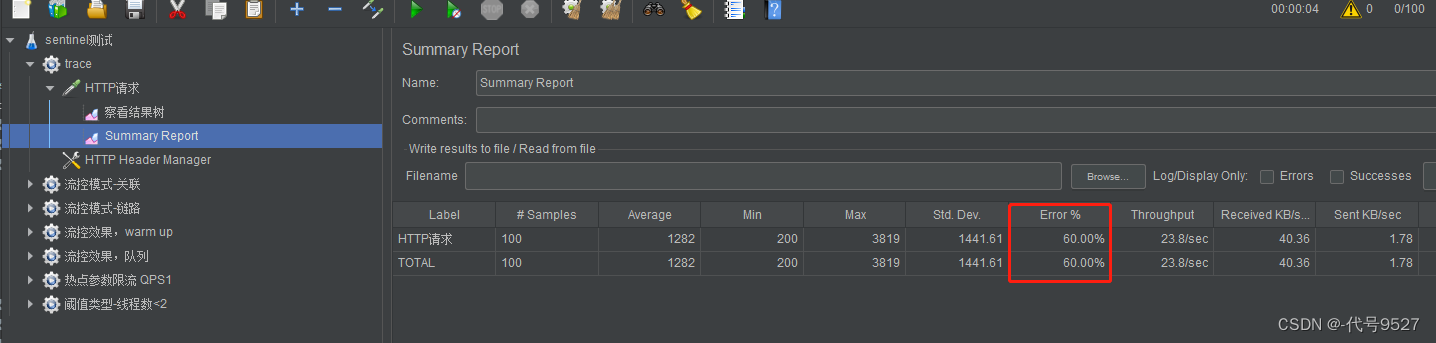
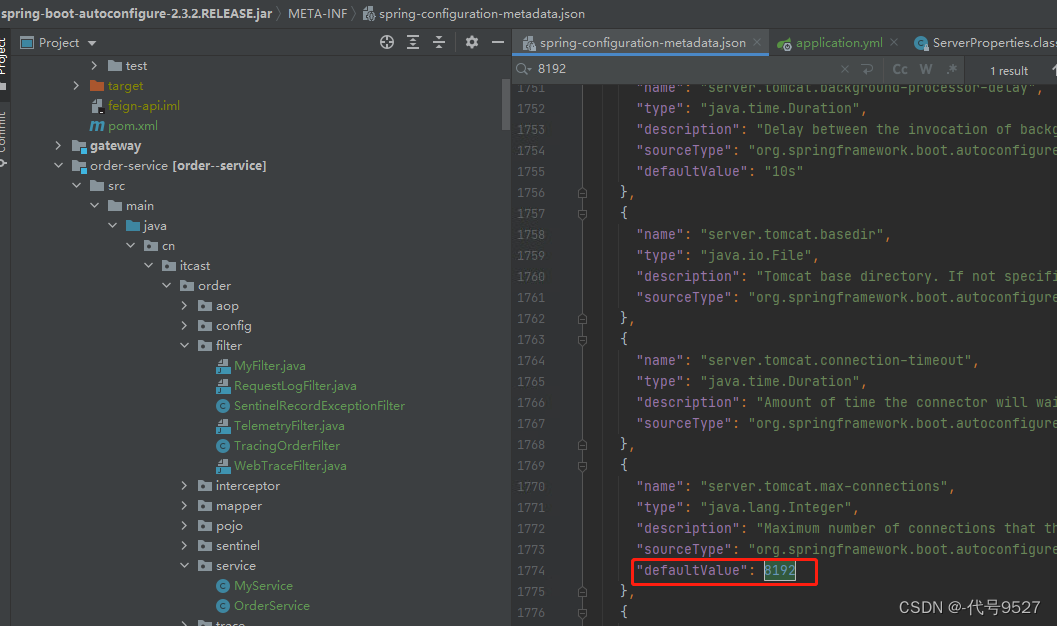
成功40个,刚好是(max-connections)+(accept-count),而这两个参数的默认值可以在Spring-boot-autoconfigure.jar的配置元数据的json文件spring-configuration-metadata.json中找到:(当然也可以直接在application.yaml中按住Ctrl去源码找)
答案:
max-connections默认值为8192,accept-count默认值100,因此默认情况下,可同时处理8192+100=8292
知识点补充:
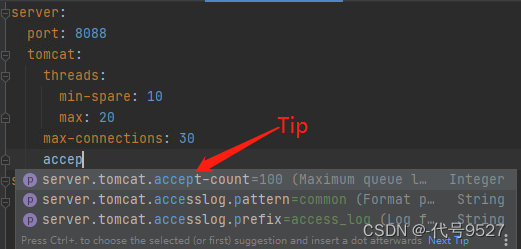
1、关于spring-configuration-metadata.json文件
配置spring-configuration-metadata.json文件后,在IDEA中编写application.yaml等配置文件时,会有提示。
要做一个体验良好的Starter,这个文件还是非常重要的,对于使用你封装的开发者来说,写配置的时候就会方便很多。关于这个文件的生成,需要引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
当再次编译的时候,spring-configuration-metadata.json文件就自动出现了。参考【spring-configuration-metadata.json】
2、关于各参数含义
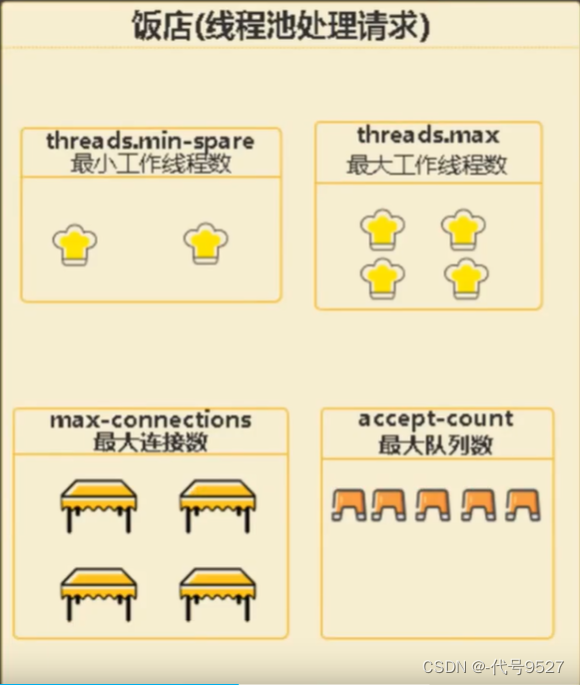
首先把web服务器当作是一个饭店:
最小工作线程数:这个饭店里正式员工的厨师最大工作线程数:当客人很多时,正式员工忙不过来,又来了兼职厨师(即最小线程数下,菜炒不完了)最大连接数:饭店里最多可容纳的客人数量最大队列数:店里坐不下了,去外面小板凳上坐下排队的人,即最多可以排队的人数。
按照上面调试代码里的配置,则:正式厨师10个,可招兼职的最多20个,店里能做30人,门口10个小板凳。某一会,来了100个客人,则只能先安排40个,另外60个不会光速走人,会先观望一下,即有自己的超时时间,等到了超时时间,还没轮到他进去吃,则走人,msg为connected timeout。(我上面代码中执行一次休眠2秒,而Jmeter中我设置的timeout时间为200ms,所以表现出来是60个人全部走人了)
Q2、SpringBoot如何优化启动速度
一般在SpringBoot项目启动中比较耗时的任务比如:数据库建立连接、初始线程池的创建等,可通过延迟这些操作的初始化来优化启动速度。
A1:开启bean的懒加载
SpringBoot 2.2版本引入spring.main.lazy-initialization属性,配置为true,开启懒加载,可将所有Bean延迟初始化。
spring:
main:
lazy-initialization: true
A2:创建扫描索引
Spring5之后提供了Spring-context-indexer功能,通过在编译时创建一个静态候选列表来提高大型应用程序的启动性能。首先引入依赖:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<optional>true</optional>
</dependency>
然后在启动类上加一个@Indexed注解,这样编译打包时会在项目中生成META-INF/spring.components文件。这个索引文件里,是提前将@ComponentScan需要扫描的bean全部建立好索引并排好顺序,然后项目启动时就根据这个文件来加载我们所有的Bean
A3:其余思路整理:
- 减少@ComponentScan @SpringBootApplication扫描类时候的范围
- 关闭 Spring Boot 的JMX监控,设置spring.jmx.enabled=false
- 设置JVM参数-noverify ,不对类进行验证
- 对非必要启动时加载的Bean,延迟加载
- 使用SpringBoot的全局懒加载
- AOPQ切面尽量不使用注解方式,这会导致启动时扫描全部方法
- 关闭endpoint的一些监控功能
- 排除项目多余的依赖
- swagger扫描接口时,指定只扫描某个路径下的类
- Feign客户端接口的扫描缩小包扫描范围
A4:还可尝试一些新特性:
- JDK12后支持G1、JDK13后支持ZGC,可将未使用的内存及时归还给操作系统
- SpringBoot3的新特性spring-graalvm-native,可将SpringBoot应用程序编译成本地可执行的镜像文件(显著优化!)
Q3、谈谈对Spring的理解
答案:
Spring是一个生态,可以构建java应用所需的一切基础设施,比如SpringCloud、SpringData、SpringSecurity…通常Spring指的就是Spring Framework。另外:
- Spring是一个轻量级的开源容器框架
- Spring是为了解决企业级应用开发的业务逻辑层和其他各层对象和对象直接的耦合问题
- Spring是一个IOC和AOP的容器框架:IOC控制反转、面向切面编程AOP、包含并管理应用对象的生命周期的容器
Q4、Spring的优缺点
A1:方便解耦,简化开发
通过Spring提供的IoC容器,集中管理对象,使得对象和对象之间的耦合度降低,避免硬编码造成的程序过度耦合,方便维护对象。
A2:AOP的支持:
在不修改原代码的情况下,对业务代码进行增强,减少重复代码,方便维护。
A3:声明事务的支持:
使用@Transactional注解进行声明式的事务管理,不再关注烦闷的事务管理代码,提高开发效率。
A4:程序测试方便:
Spring对Junit4的支持,可以通过注解方便的测试Spring程序。
A5:方便集成各种优秀框架:
集成能力非常强,只需要做简单配置就可以集成第三方框架。(Spring底层源码提供了非常多的可扩展接口)
A6:降低了Java EE中API的使用难度
Spring对Java EE中很多步骤繁琐的API,如JDBC、JavaMail、远程调用等提供了封装
A7:学习的范例
Spring源码底层的实现,比如大量的反射、设计模式、扩展接口等值得学习。但上层使用越简单,下层封装和实现就越复杂,想阅读源码后做扩展也就不容易了。