Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器(框架)。
一、什么是IOC?
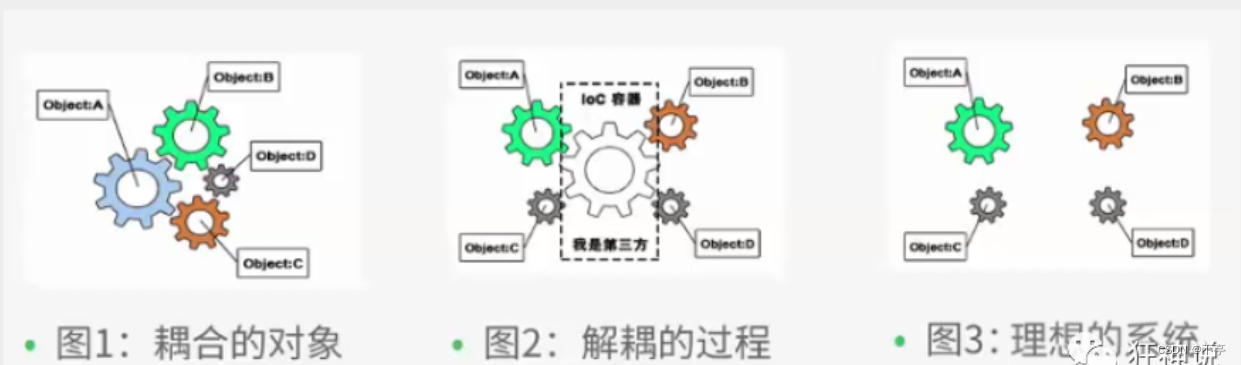
IoC = Inversion of Control 翻译成中⽂是“控制反转”的意思,也就是说 Spring 是⼀个“控制反转”的容器。
1.1控制反转推导
这个控制反转怎么理解呢?我们来推导一下这个过程:
我们现在构建⼀辆“⻋”的程序,我们的实现思路和代码实现是这样的:
轮胎的尺⼨的固定的,然⽽随着对的⻋的需求量越来越⼤,个性化需求也会越来越多,这时候我们就需要加⼯多种尺⼨的轮胎,那这个时候就要对上面的程序进⾏修改了,修改后的代码如下所示:
从上面的代码中可以看出传统写法的缺陷:代码耦合性太高。
那上述问题我们可以怎么解决呢?
这就好⽐我们打造⼀辆完整的汽车,传统的方式是所有的配件都是⾃⼰造,那么当客户需求发⽣改变的时候,⽐如轮胎的尺⼨不再是原来的尺⼨了,那我们要⾃⼰动⼿来改了,但如果我们是把轮胎外包出去,那么即使是轮胎的尺⼨发⽣变变了,我们只需要向代理⼯⼚下订单就⾏了,我们⾃身是不需要出⼒的。
所以:我们可以尝试不在每个类中自己创建下级类,如果⾃⼰创建下级类就会出现当下级类发⽣改变操作,⾃⼰也要跟着修改。
此时,我们只需要将原来由自己创建的下级类,改为传递的方式(也就是注入的方式),因为我们不需要在当前类中创建下级类了,所以下级类即使发生变化(创建或减少参数),当前类本身也⽆需修改任何代码,这样就完成了程序的解耦。
代码实现思路如下:

总结对比一下:
执行顺序:
在传统的代码中对象创建顺序是:Car -> Framework -> Bottom -> Tire
改进之后解耦的代码的对象创建顺序是:Tire -> Bottom -> Framework -> Car
通⽤程序的实现代码,类的创建顺序是反的,传统代码是 Car 控制并创建了Framework,Framework 创建并创建了 Bottom,依次往下,⽽改进之后的控制权发⽣的反转,不再是上级对象创建并控制下级对象了,⽽是下级对象把注⼊将当前对象中,下级的控制权不再由上级类控制了,这样即使下级类发⽣任何改变,当前类都是不受影响的,这就是典型的控制反转,也就是 IoC 的实
现思想。
上述过程不知道各位小伙伴能不能理解,但总结来说就是传统的写法所有的东西都是由程序去控制创建的,改进后的写法是由调用者自行控制创建对象 , 把主动权交给了调用者 . 程序不用去管怎么创建,怎么实现了 . 它只负责提供一个接口 .。
这种思想 , 从本质上解决了问题 , 我们程序员不再去管理对象的创建了 , 更多的去关注业务的实现 . 耦合性大大降低 . 这也就是IOC的原型 。
1.2、IOC的本质:
控制反转IoC(Inversion of Control),是一种设计思想,DI(依赖注入)是实现IoC的一种方法,也有人认为DI只是IoC的另一种说法。没有IoC的程序中 , 我们使用面向对象编程 , 对象的创建与对象间的依赖关系完全硬编码在程序中,对象的创建由程序自己控制,控制反转后将对象的创建转移给第三方,个人认为所谓控制反转就是:获得依赖对象的方式反转了。
1.2.1、DI依赖注入
说到 IoC 不得不提的⼀个词就是“DI”,DI 是 Dependency Injection 的缩写,翻译成中⽂是“依赖注
⼊”的意思。
所谓依赖注⼊,就是由 IoC 容器在运⾏期间,动态地将某种依赖关系注⼊到对象之中。所以,依
赖注⼊(DI)和控制反转(IoC)是从不同的⻆度的描述的同⼀件事情,就是指通过引⼊ IoC 容
器,利⽤依赖关系注⼊的⽅式,实现对象之间的解耦。
IoC 是“⽬标”也是⼀种思想,⽽⽬标和思想只是⼀种指导原则,最终还是要有可⾏的落地⽅案,⽽ DI就属于具体的实现。
DI 概念说明:
将对象存放到容器中的好处:将对象存储在 IoC 容器相当于将以后可能⽤的所有⼯具制作好都放到仓库中,需要的时候直接取就⾏了,⽤完再把它放回到仓库。⽽ new 对象的⽅式相当于,每次需要⼯具了,才现做,⽤完就扔掉了也不会保存,下次再⽤的时候还得重新做,这就是 IoC 容器和普通程序开发的区别
二、创建有一个Spring项目
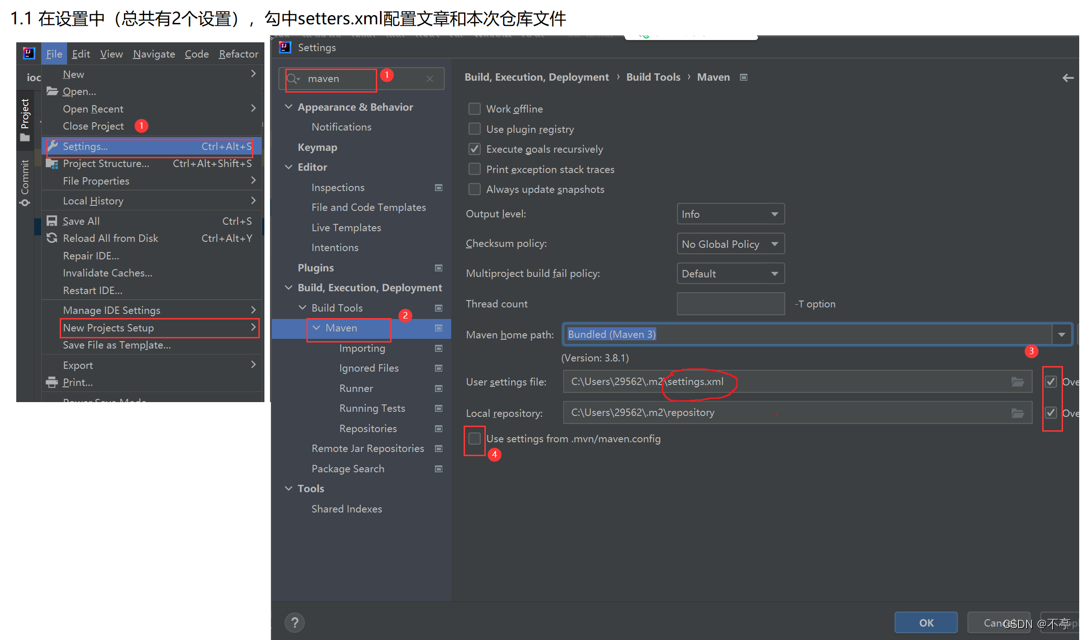
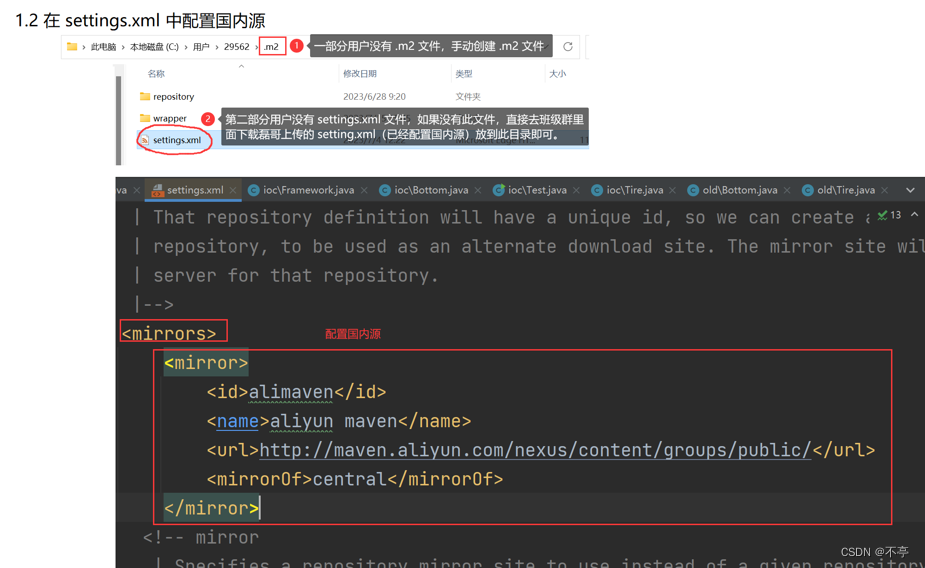
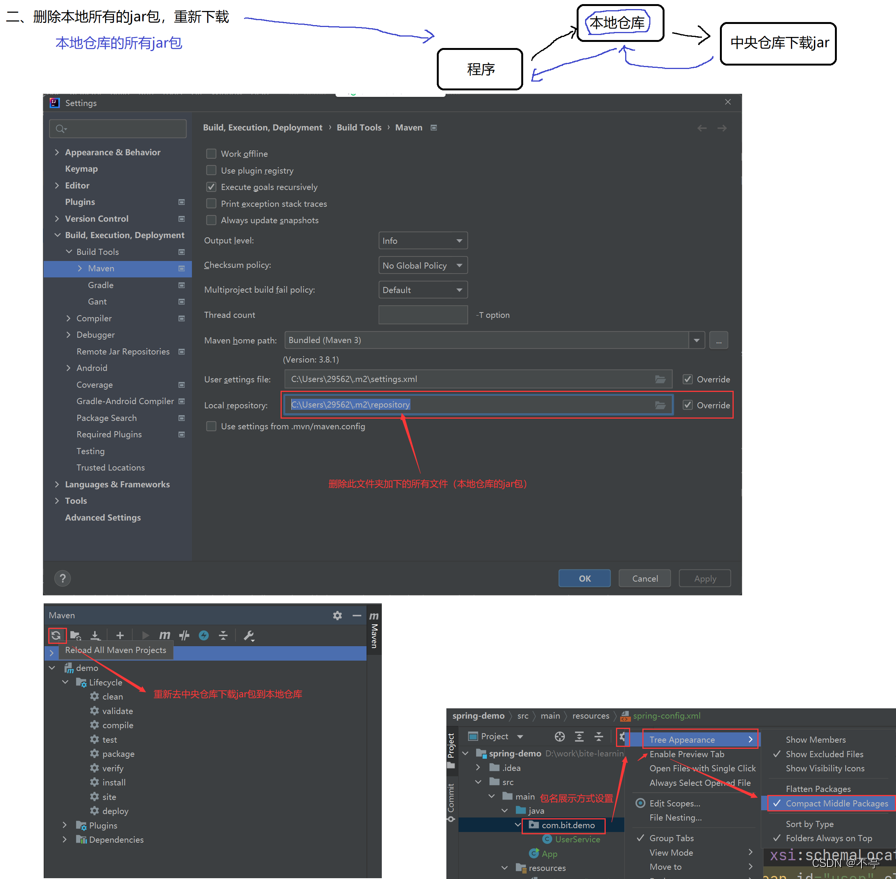
1、配置maven国内源
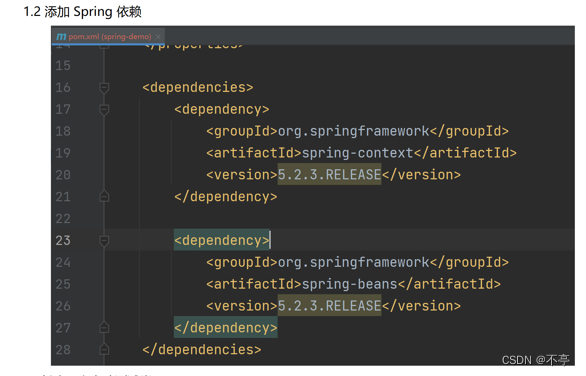
2、创建spring项目

<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.2.3.RELEASE</version>
</dependency>
</dependencies>
 按照上述步骤配置完成,启动成功不报错,那么一个spring项目就创建好了,接下来我们体验一下Spring是如何获取和使用Bean的。
按照上述步骤配置完成,启动成功不报错,那么一个spring项目就创建好了,接下来我们体验一下Spring是如何获取和使用Bean的。
3、获取和使用Spring对象
3.1、添加 Spring 配置⽂件 spring-config.xml
在创建好的项⽬中添加 Spring 配置⽂件 spring-config.xml,将此⽂件放到 resources 的根⽬录下
Spring 配置⽂件的固定格式为以下内容(以下内容⽆需记忆,只需要保存到⾃⼰可以找到的地
就可以了,因为它是固定不变的)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans htt
p://www.springframework.org/schema/beans/spring-beans.xsd">
</beans>3.2、将Bean对象存储到Spring(IOC容器)
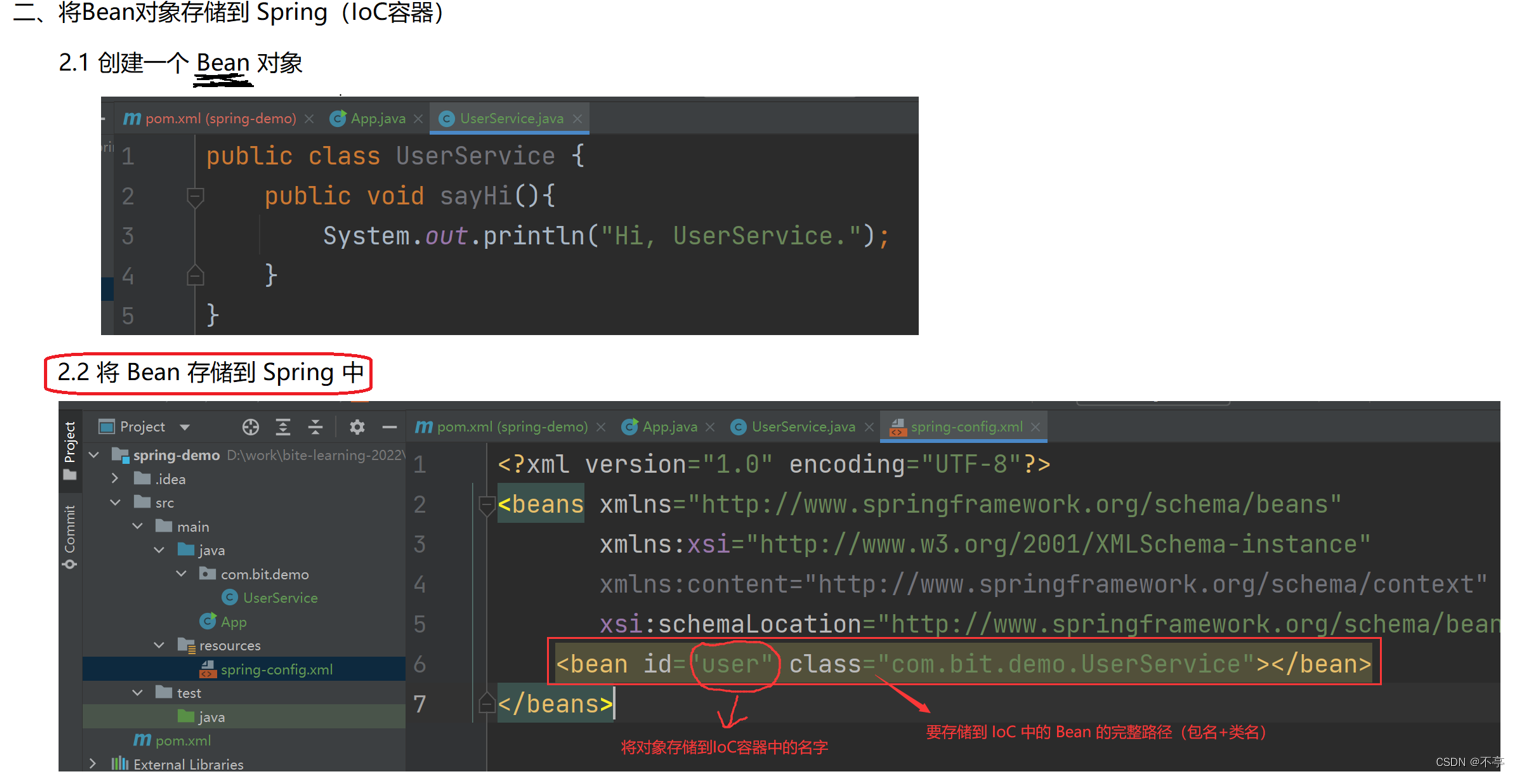 【解释一下:这里的我们正常创建一个类是这么写的:类型 变量名 = new 类型();bean中的 id 相当于变量名,class 相当于 new的对象】
【解释一下:这里的我们正常创建一个类是这么写的:类型 变量名 = new 类型();bean中的 id 相当于变量名,class 相当于 new的对象】
3.2、从容器中获取Bean对象
获取并使⽤ Bean 对象,分为以下 3 步:
- 得到 Spring 上下文对象,因为对象都交给 Spring 管理了,所以获取对象要从 Spring 中获取,那么就得先得到 Spring 的上下文。
- 通过 Spring 上下文,获取某⼀个指定的 Bean 对象。
- 使⽤ Bean 对象。
如果取多个 Bean 的话重复以上第 2、3 步骤。
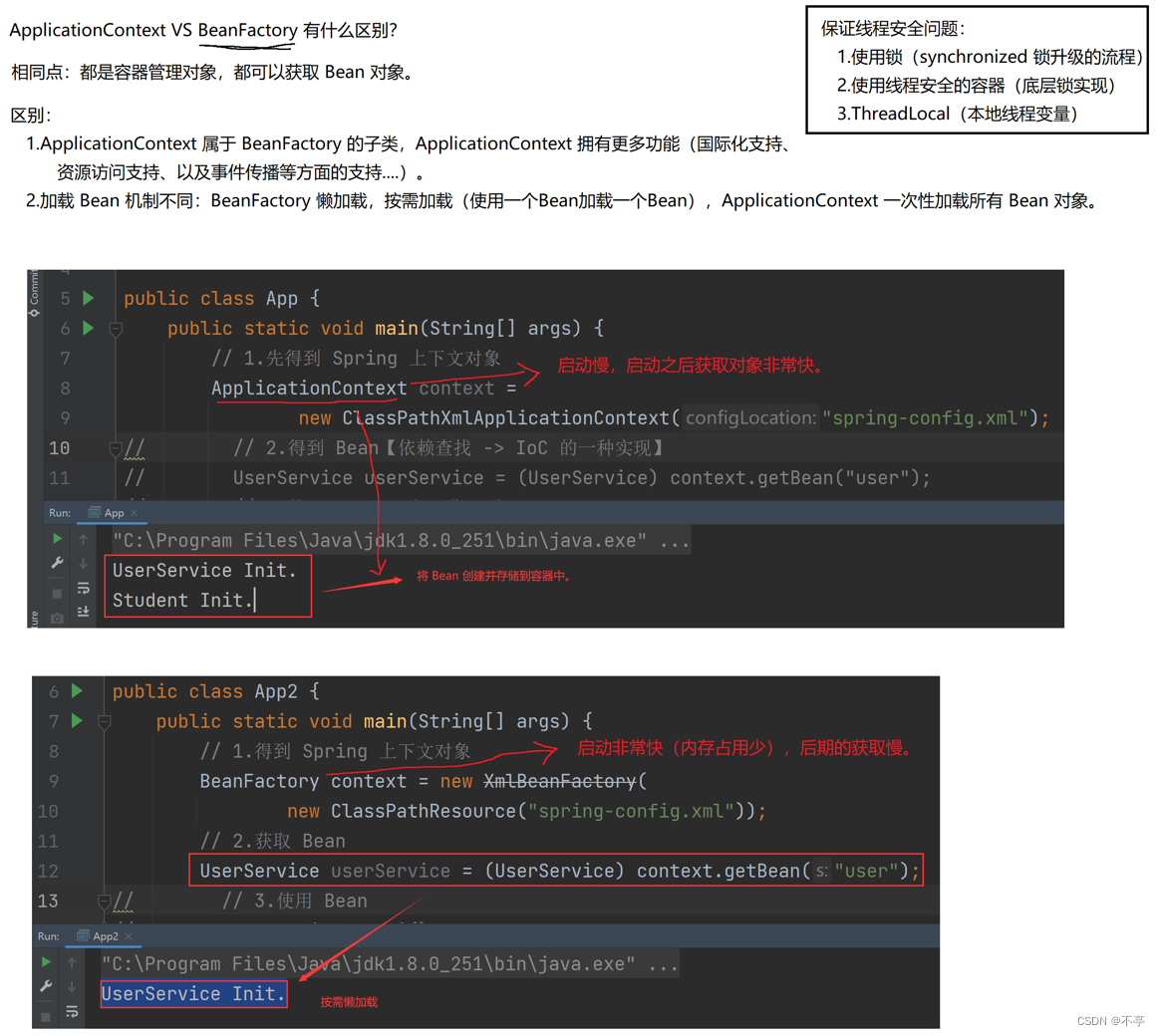
除了 ApplicationContext 之外,我们还可以使⽤ BeanFactory 来作为 Spring 的上下⽂,如下代码所示:
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("springconfig.xml"));ApplicationContext 和BeanFactory 的区别
3.3、getBean ⽅法的更多⽤法
getBean() ⽅法有很多种重载⽅法,我们也可以使⽤其他⽅式来获取 Bean 对象

三、Spring 更简单的读取和存储对象——注解
3.1、配置扫描路径
前置工作,在之前的spring-config.xml文件中配置bean的扫描路径,如果不配置,后面所有的操作都不会生效。

3.2、注解
想要将对象存储在 Spring 中,有两种注解类型可以实现:
- 类注解:@Controller、@Service、@Repository、@Component、@Configuration。
- 方法注解:@Bean。
3.2.1、五类注解
@Controller // 将对象存储到 Spring 中
public class UserController {
public void sayHi(String name) {
System.out.println("Hi," + name);
}
}
public class Application {
public static void main(String[] args) {
// 1.得到 spring 上下⽂
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2.得到 bean
UserController userController = (UserController) context.getBean(
"userController");
// 3.调⽤ bean ⽅法
userController.sayHi("Bit");
}
}
========================
@Service
public class UserService {
public void sayHi(String name) {
System.out.println("Hi," + name);
}
}
class App {
public static void main(String[] args) {
// 1.得到 spring 上下⽂
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2.得到 bean
UserService userService = (UserService) context.getBean("userServi
ce");
// 3.调⽤ bean ⽅法
userService.sayHi("Bit");
}
}
=======================================
@Repository
public class UserRepository {
public void sayHi(String name) {
System.out.println("Hi," + name);
}
}
class App {
public static void main(String[] args) {
// 1.得到 spring 上下⽂
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2.得到某个 bean
UserRepository userRepository = (UserRepository) context.getBean(
"userRepository");
// 3.调⽤ bean ⽅法
userRepository.sayHi("Bit");
}
}
=================================================
@Component
public class UserComponent {
public void sayHi(String name) {
System.out.println("Hi," + name);
}
}
class App {
public static void main(String[] args) {
// 1.得到 spring 上下⽂
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2.得到某个 bean
UserComponent userComponent = (UserComponent) context.getBean("use
rComponent");
// 3.调⽤ bean ⽅法
userComponent.sayHi("Bit");
}
}
=======================
@Configuration
public class UserConfiguration {
public void sayHi(String name) {
System.out.println("Hi," + name);
}
}
class App {
public static void main(String[] args) {
// 1.得到 spring 上下⽂
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
// 2.得到某个 bean
UserConfiguration userConfiguration = (UserConfiguration) context.
getBean("userConfiguration");
// 3.调⽤ bean ⽅法
userConfiguration.sayHi("Bit");
}
}
观察上述代码,可以发现,这五个注解的功能是一样的,那么我们为什么要用那么多个注解呢?用一个不就行了?
这和为什么每个省/市都有⾃⼰的⻋牌号是⼀样的?⽐如陕⻄的⻋牌号就是:陕X:XXXXXX,北京的⻋牌号:京X:XXXXXX,⼀样。甚⾄⼀个省不同的县区也是不同的,⽐如⻄安就是,陕A:XXXXX,咸阳:陕B:XXXXXX,宝鸡,陕C:XXXXXX,⼀样。这样做的好处除了可以节约号码之外,更重要的作⽤是可以直观的标识⼀辆⻋的归属地
同理,我们使用那么多的类注解也是相同的原因,就是让程序员看到类注解之后,就能直接了解当前类的⽤途:
这五类注解的用途如下:
@Controller 【控制器】 校验参数的合法性(相当于安检系统)
@Service 【服务】业务组装(客服中心)
@Repository 【数据持久层】实际业务处理中心(实际办理业务的)
@Component【组件】工具类层(基础的工具)
@Configuration【配置层】配置
程序的工程分层,调⽤流程如下: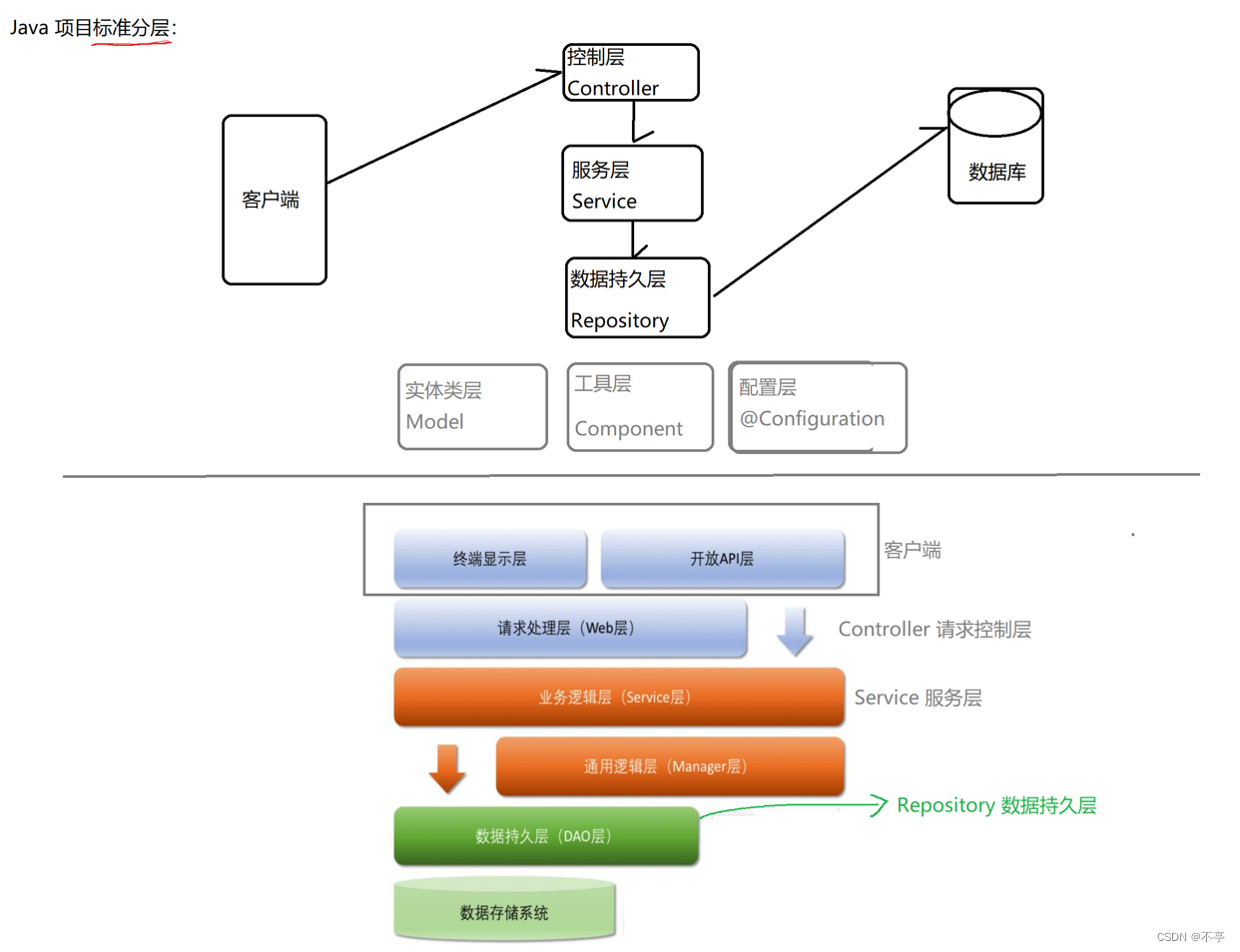
这五个注解之间的关系:

我们查看源码后发现,其实这些注解⾥⾯都有⼀个注解 @Component,说明它们本身就是属于 @Component 的“子类”
方法注解@Bean
类注解是添加到某个类上的,而方法注解是放到某个⽅法上的,如以下代码的实现: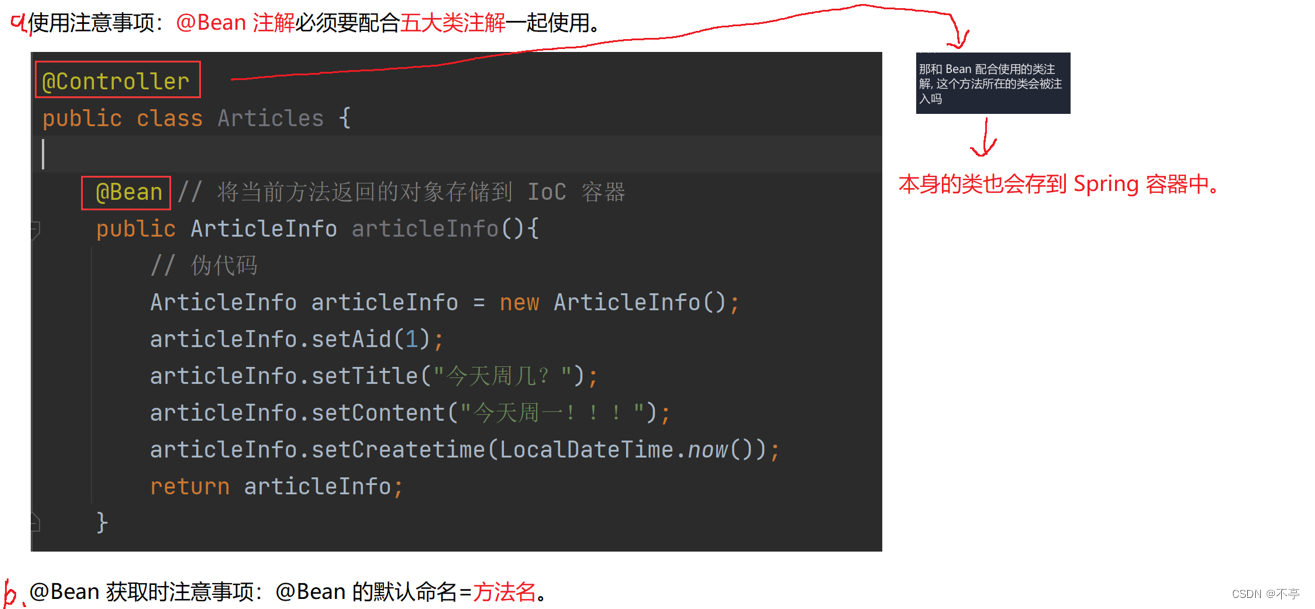
3.3、Bean命名规则

3.3.1、@Bean的重命名:


3.4、获取 Bean 对象(对象装配)
获取 bean 对象也叫做对象装配,是把对象取出来放到某个类中,有时候也叫对象注⼊
对象装配(对象注⼊)的实现⽅法以下 3 种:
- 属性注⼊
- 构造⽅法注⼊
- Setter 注⼊
3.4.1、 属性注⼊
属性注⼊是使用 @Autowired 实现的,将 Service 类注⼊到 Controller 类中。
Service 类的实现代码如下:
@Service
public class UserService {
public User getUser(Integer id) {
// 伪代码,不连接数据库
User user = new User();
user.setId(id);
user.setName("Java-" + id);
return user;
}
}Controller 类的实现代码如下:
@Controller
public class UserController {
// 注⼊⽅法1:属性注⼊
@Autowired
private UserService userService; //属性注入的核心代码
public User getUser(Integer id) {
return userService.getUser(id);
}
}获取 Controller 中的 getUser ⽅法:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class UserControllerTest {
public static void main(String[] args) {
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
UserController userController = context.getBean(UserController.cla
ss);
System.out.println(userController.getUser(1).toString());
}
}最终结果如下: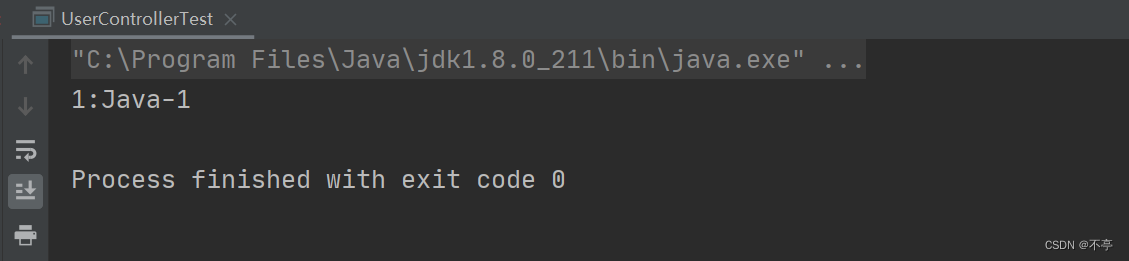
3.4.1.1、注意: 同类型的Bean存储到容器多个,获取时会报错
@Component
public class Users {
@Bean
public User user1() {
User user = new User();
user.setId(1);
user.setName("Java");
return user;
}
@Bean
public User user2() {
User user = new User();
user.setId(2);
user.setName("MySQL");
return user;
}
在另⼀个类中获取 User 对象,代码和运行结果如下:

解决方案:
1. 使⽤ @Resource(name="")
2. 使⽤ @Qualifier("")

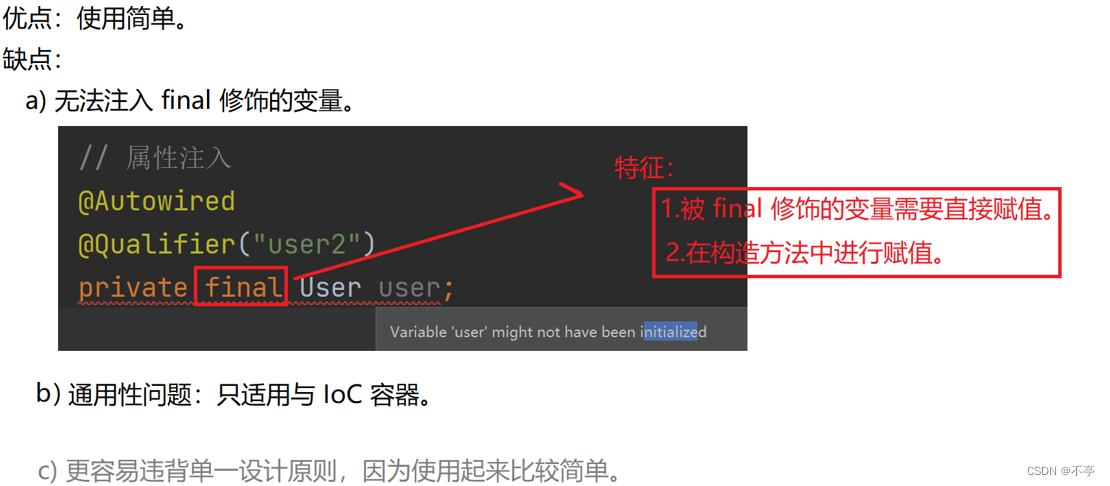
3.4.1.2、属性注入的优缺点:
3.4.2、Setter 注入
Setter 注入和属性的 Setter ⽅法实现类似,只不过在设置 set ⽅法的时候需要加上 @Autowired 注解(不能省),Controller 类的实现代码如下:
@Controller
public class UserController3 {
// 注⼊⽅法3:Setter注⼊
private UserService userService;
@Autowired
public void setUserService(UserService userService) {
this.userService = userService;
}
public User getUser(Integer id) {
return userService.getUser(id);
}
}3.4.1.1、Setter注入优缺点:
 3.4.3、构造方法注入
3.4.3、构造方法注入
构造⽅法注⼊是在类的构造⽅法中实现注⼊,Controller 类的实现代码如下:
@Controller
public class UserController2 {
// 注⼊⽅法2:构造⽅法注⼊
private UserService userService;
@Autowired
public UserController2(UserService userService) {
this.userService = userService;
}
public User getUser(Integer id) {
return userService.getUser(id);
}
}注意:如果只有⼀个构造⽅法,那么 @Autowired 注解可以省略,如下图所示: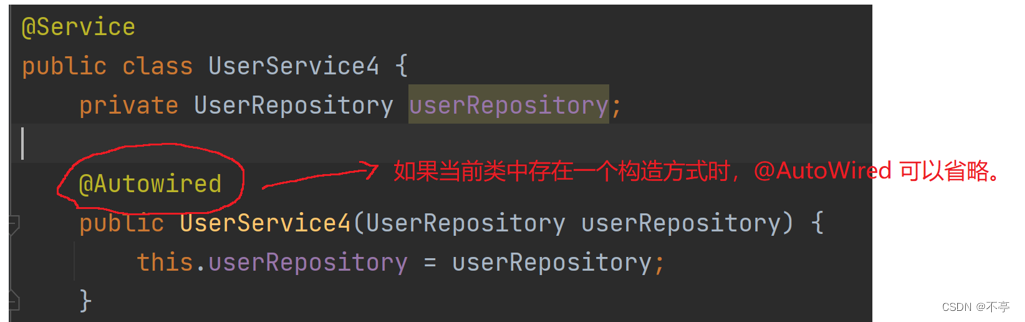
3.4.3.1、构造方法注入优缺点:

Spring为什么使用三级缓存解决循环依赖?_哔哩哔哩_bilibili
3.2.4、三种注入优缺点分析
- 属性注⼊的优点是简洁,使用方便;缺点是只能⽤于 IoC 容器,如果是⾮ IoC 容器不可⽤,并且只有在使⽤的时候才会出现 NPE(空指针异常)。
- 构造⽅法注⼊是 Spring 推荐的注入方式,它的缺点是如果有多个注⼊会显得⽐较臃肿,但出现这种情况你应该考虑⼀下当前类是否符合程序的单⼀职责的设计模式了,它的优点是通⽤性,在使⽤之前⼀定能把保证注⼊的类不为空。
- Setter ⽅式是 Spring 前期版本推荐的注⼊⽅式,但通⽤性不如构造⽅法,所有 Spring 现版本已经推荐使⽤构造⽅法注⼊的⽅式来进⾏类注入了。
@Resource:另⼀种注⼊关键字
在进⾏类注⼊时,除了可以使⽤ @Autowired 关键字之外,我们还可以使⽤ @Resource 进⾏注⼊:
@Controller
public class UserController {
// 注⼊
@Resource
private UserService userService;
public User getUser(Integer id) {
return userService.getUser(id);
}
}@Autowired 和 @Resource 的区别

四、Bean 作⽤域和⽣命周期
4.1、作用域
限定程序中变量的可⽤范围叫做作⽤域,或者说在源代码中定义变量的某个区域就叫做作⽤域。
⽽ Bean 的作⽤域是指 Bean 在 Spring 整个框架中的某种⾏为模式,⽐如 singleton 单例作⽤域,就表示 Bean 在整个 Spring 中只有⼀份,它是全局共享的,那么当其他⼈修改了这个值之后,那么另⼀个⼈读取到的就是被修改的值
Spring 容器在初始化⼀个 Bean 的实例时,同时会指定该实例的作⽤域。
Spring有 6 种作⽤域,最后四种是基于 Spring MVC ⽣效的:
1. singleton:单例作⽤域(单例模式,默认的作用域)
2. prototype:原型作⽤域(原型模式,多例作⽤域)
3. request:请求作⽤域,只适用于SpringMVC项目(Spring Web)
4. session:回话作⽤域,一个Http会话共享一个Bean。只适用于SpringMVC项目(Spring Web)
5. application:应用作用域(全局作用域)表示的是一个Context容器共享一个作用域。只适用于SpringMVC项目(Spring Web)
6. websocket:HTTP WebSocket 作⽤域,只适用于websocket作用域。
单例作用域(singleton) VS 全局作用域(application)
singleton 是 Spring Core 的作⽤域;application 是 Spring Web 中的作用域;
singleton 作⽤于 IoC 的容器,而 application 作⽤于 Servlet 容器。
4.2、设置作⽤域
使⽤ @Scope 标签就可以⽤来声明 Bean 的作⽤域,⽐如设置 Bean 的作⽤域,如下代码所示:
@Component
public class Users {
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
@Bean(name = "u1")
public User user1() {
User user = new User();
user.setId(1);
user.setName("Java");
return user;
}
}@Scope 标签既可以修饰方法也可以修饰类,@Scope 有两种设置⽅式:
- 直接设置值:@Scope("prototype")
- 使⽤枚举设置:@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
4.3、Spring 执⾏流程
启动 Spring 容器 -> 实例化 Bean(分配内存空间,从⽆到有) -> Bean 注册到 Spring 中(存操作) -> 将 Bean 装配到需要的类中(取操作)。 4.4、Bean 生命周期
4.4、Bean 生命周期
所谓的⽣命周期指的是⼀个对象从诞⽣到销毁的整个生命过程,我们把这个过程就叫做⼀个对象的生命周期。
Bean 的⽣命周期分为以下 5 ⼤部分:
1.实例化 Bean(为 Bean 分配内存空间)
2.设置属性(Bean 注⼊和装配)
3.Bean 初始化
实现了各种 Aware 通知的⽅法,如 BeanNameAware、BeanFactoryAware、
ApplicationContextAware 的接⼝⽅法;
执⾏ BeanPostProcessor 初始化前置⽅法;
执⾏ @PostConstruct 初始化⽅法,依赖注⼊操作之后被执⾏;
执⾏⾃⼰指定的 init-method ⽅法(如果有指定的话);
执⾏ BeanPostProcessor 初始化后置⽅法。
4.使⽤ Bean
5.销毁 Bean
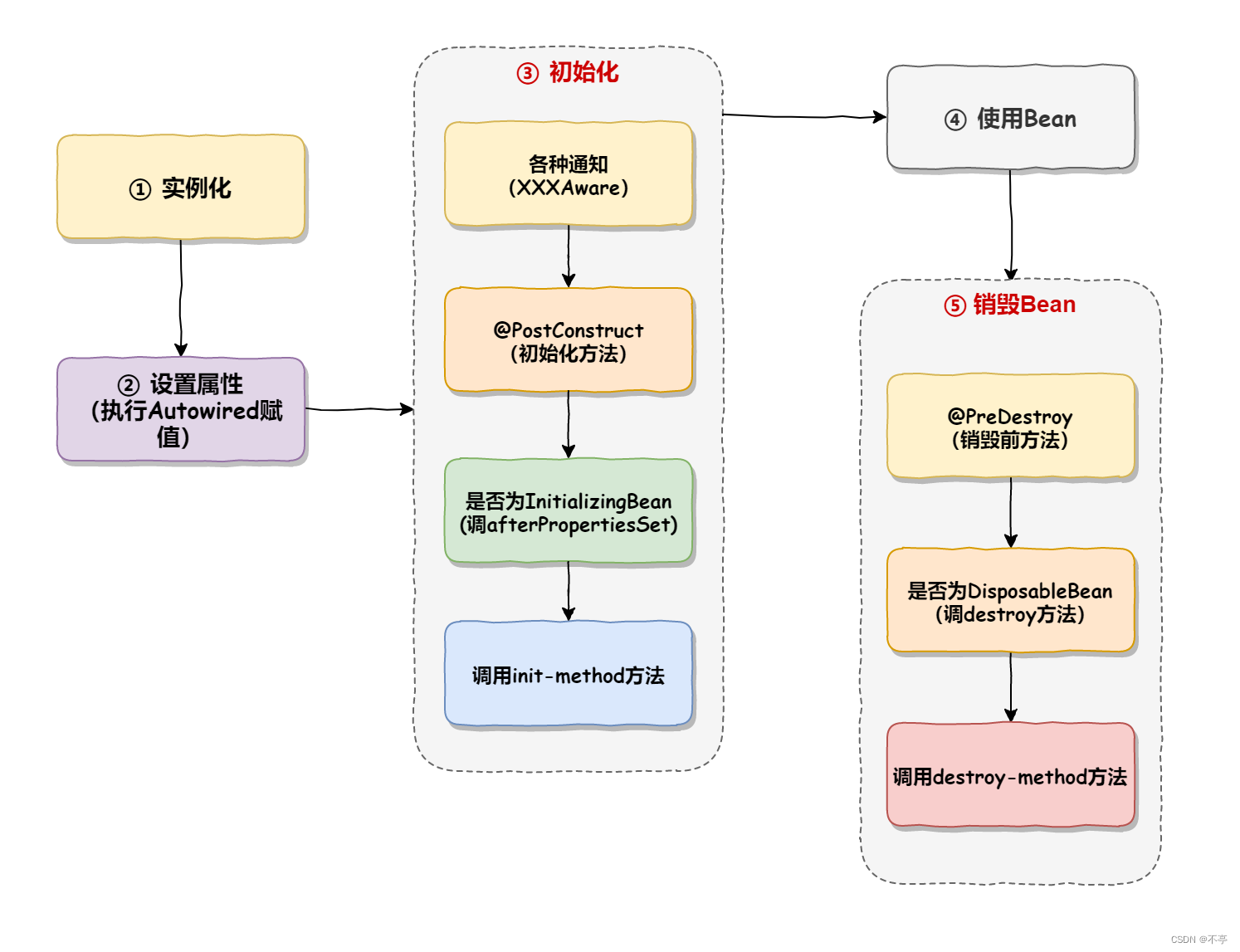 4.4、实例化和初始化的区别
4.4、实例化和初始化的区别
实例化和属性设置是 Java 级别的系统“事件”,其操作过程不可人工干预和修改;⽽初始化是给开发者提供的,可以在实例化之后,类加载完成之前进行自定义“事件”处理
以上就是本文分享的主要内容,对你有帮助的话,可以点个赞哦~~




![[LeetCode周赛复盘] 第 112场双周赛20230903](https://img-blog.csdnimg.cn/f7d3a794b35542ab89e33303b90394e9.png)