数学建模国赛即将开始,小编总结近五年的数学建模ABC题题型,并根据题型总结建模常用的四大模型,如下:
A题
一般A题偏物理方面,专业性更强,偏难,新手不建议选择A题,原因在于可能看不懂题目,如果不理解题目,看不懂题目,就会导致分析问题不彻底,甚至没思路,可能半路换题(强烈不建议半路换题!!),A题考察优化算法比较多,近五年国赛A题考察的题型参考如下:

B题
B题难度一般介于A题和C题之间,题型一般不固定,大部分还会考察优化模型,也会考察预测、分类模型等。近五年国赛B题考察的题型参考如下:

C题
C题难度一般相较于A、B简单,并且往往选择C题的人最多,也最不容易拿奖,所以参赛队伍如果想拿奖,一般需要论文或者解决问题的模型比较优秀,C题的开放较高,很多情况没有固定答案,一般从实际问题角度出发,题目易于理解,如果是新手,建议可以优先考虑C题,C题所考察的模型也比较宽泛,近五年国赛C题考察的题型参考如下:

所以通过近五年的ABC题发现国赛数学建模常用的模型有分类模型、预测模型、评价模型以及优化模型。接下来进行说明。
题外话:处理python、MATLAB等,还可以使用SPSSAU进行分析。
无需担心是否会被认可。学术大佬都在用!!
01优化模型
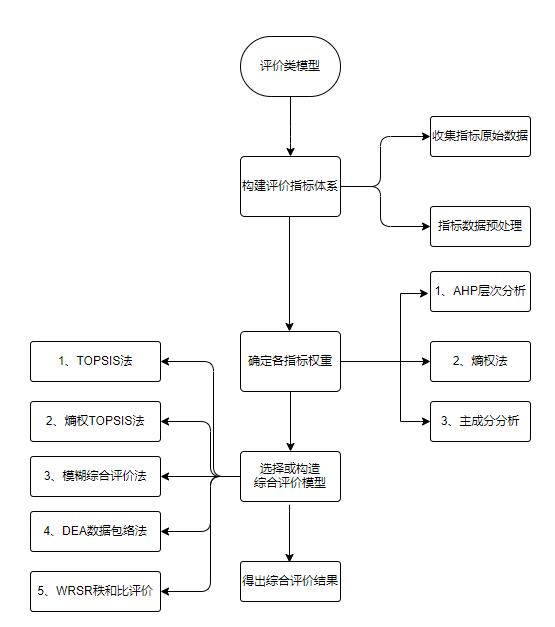
一、构架评价指标体系 (1)收集原始数据 (2)指标数据预处理 收集到的评价指标数据,有时候需要进行数据预处理,比如数据的标准化、归一化等等。下文总结了12种数据量纲化处理方法:
SPSSAU:12种数据量纲化处理方式140 赞同 · 8 评论文章编辑
二、指标权重确定方法 SPSSAU提供多种指标权重确定的方法,这里介绍3种常用的方法。

(1)AHP层次分析法 AHP层次分析法是一种解决多目标复杂问题的定性和定量相结合进行计算决策权重的研究方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。 比如现在想选择一个最佳旅游景点,当前有三个选择标准(分别是景色,门票和交通),并且对应有三种选择方案。现通过旅游专家打分,希望结合三个选择标准,选出最佳方案(即最终决定去哪个景区旅游)。诸如此类问题即专家打分进行权重计算等,均可通过AHP层次分析法得到解决。
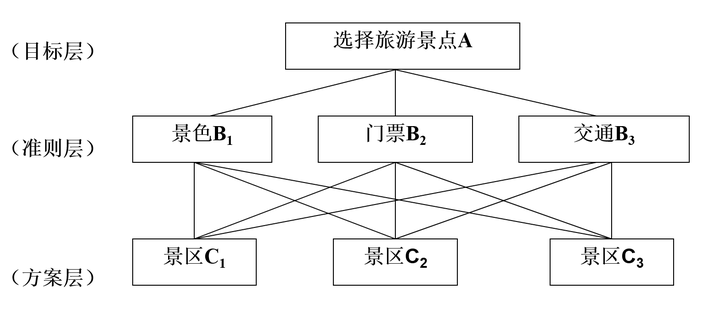
正如上述问题,专家可以对3个准则层标准(分别是景色,门票和交通)进行打分,得到3个选择标准对应的权重值;然后结合准则层得到的权重值,加上方案层的得分,最终选择出最佳方案。
相关案例文章: SPSS在线_SPSSAU_SPSS_AHP层次分析法
视频教程: SPSSAU数据分析常用方法教学:AHP层次分析法
【SPSSAU】AHP层次分析法应用及注意事项 | 数据分析常见问题解答
(2)熵权法
由于对数据要求少,且容易计算,熵值法一直是在综合评价研究中备受欢迎的权重计算方法。 通常熵值法的使用场景情况如下:
- 配合因子分析(或主成分析)得到一级指标权重,进一步使用熵值法计算具体二级指标的权重,最终构建权重体系。
- 单独使用熵值法进行权重计算。
相关案例文章:
SPSSAU:手把手教你用熵值法计算权重
视频教程: SPSSAU数据分析常用方法教学:熵值法
【SPSSAU】熵值法操作及应用 | 数据分析常见问题解答
【SPSSAU】熵值法的各类应用
(3)主成分分析
主成分分析用于对数据信息进行浓缩,比如总共有20个指标值,是否可以将此20项浓缩成4个概括性指标。主成分分析可用于权重计算和综合竞争力研究。
视频教程: SPSSAU数据分析常用方法教学:主成分分析 【SPSSAU】
主成分分析操作演示及结果解读 | 数据分析常见问题解答
【SPSSAU】主成分分析的几类应用及操作方法 | 数据分析常见问题解答
三、评价模型
SPSSAU提供多种综合评价模型,这里介绍五种常用的评价模型。
(1)TOPSIS法 TOPSIS法用于研究与理想方案相似性的顺序选优技术,通俗理解即为数据大小有优劣关系,数据越大越优,数据越小越劣,因此结合数据间的大小找出最优和最劣方案,然后进行权重计算,最终对数据的优劣进行判断。
相关案例文章:
SPSSAU:如何用TOPSIS法计算权重?
视频教程:
【SPSSAU】TOPSIS法计算权重 | 数据分析常见问题解答
(2)熵权TOPSIS
TOPSIS法用于研究评价对象与‘理想解’的距离情况,结合‘理想解’(正理想解和负理想解),计算得到最终接近程度C值。熵权TOPSIS法核心在于TOPSIS,但在计算数据时,首先会利用熵值(熵权法)计算得到各评价指标的权重,并且将评价指标数据与权重相乘,得到新的数据,利用新数据进行TOPSIS法研究。 通俗地讲,熵权TOPSIS法是先使用熵权法得到新数据newdata(数据成熵权法计算得到的权重),然后利用新数据newdata进行TOPSIS法研究。
相关案例文章: SPSSAU:如何寻找决策最优解?熵权TOPSIS助你科学决策
(3) 模糊综合评价法
模糊综合评价借助模糊数学的一些概念,对实际的综合评价问题提供评价,即模糊综合评价以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。 举例来讲:某服装品牌生产某种服装新款式,欲了解消费者对该种款式的接受程度。一共有五个评价指标(分别是花色,式样,价格,耐用度,舒适度),以及评语共有四项(分别是很欢迎,欢迎,一般,不欢迎)。现在希望分析出消费者的综合评价情况如何,到底是很欢迎,还是欢迎,也或者一般或者不欢迎等。
视频教程: SPSSAU数据分析方法教学:模糊综合评价
(4)WRSR秩和比评价
秩和比(RSR)是指分析方法可用于评价多个指标的综合水平情况,其实质原理是利用了RSR值信息进行各项数学计算,RSR值介于0~1之间且连续,通常情况下,该值越大说明评价越‘优’。
秩和比(RSR)分析法广泛应用于医疗卫生领域的多指标综合评价,使用简单方便。比如使用RSR法综合评价10个医院的医疗水平情况并且进行医疗水平排名和分档次,也或者利用RSR法综合评价10个医生的医疗能力并且进行排名和分等级档次等。
相关案例文章: SPSS在线_SPSSAU_SPSS_秩和比RSR
(5)DEA
数据包络分析DEA是一种多指标投入和产出评价的研究方法,其应用数学规划模型计算比较决策单元(DMU)之间的相对效率,对评价对象做出评价。比如有10个学校(即10个决策单元DMU,Decision Making Units),每个学校有投入指标(比如学生人均投入资金),也有产出指标(比如学生平均成绩,学生奥数比赛比例等),有的学校投入多,有的学校投入少,但是投入多或少,均会有对应的产出,那么具体哪个学校的投入产出更加优秀呢,诸如此类投入产出的优劣问题,则可使用数据包络DEA模型进行分析。
相关案例文章: SPSSAU:如何用数据包络分析(DEA)进行效率评估? 四、得出综合评价结果
02分类模型
分类模型主要包括聚类分析和判别分析,其中聚类分析又包括K-means聚类,系统聚类、模糊聚类等,判别分析又包括Fisher判别、Bayes判别、距离判别以及逐步判别等。聚类分析将数据分成若干组或者类的过程,并且组内数据对象具有较高的相似度,组间的数据对象是相似的(前提是不明确数据对象应该分为几类),判别分析是也是分类模型的一种方法,与聚类分析不同的是它在分析前就明确观察对象应该分为几类,用此方法的目的是从现有已知类别的观察对象中建立判别函数,然后去判别同质未知类别的观察对象。
- 聚类分析
典型的聚类分析一般包括三个阶段,特征选择、特征提取和数据对象见相似度的计算,可以对样品进行聚类也可以对变量进行聚类。具体划分如下:
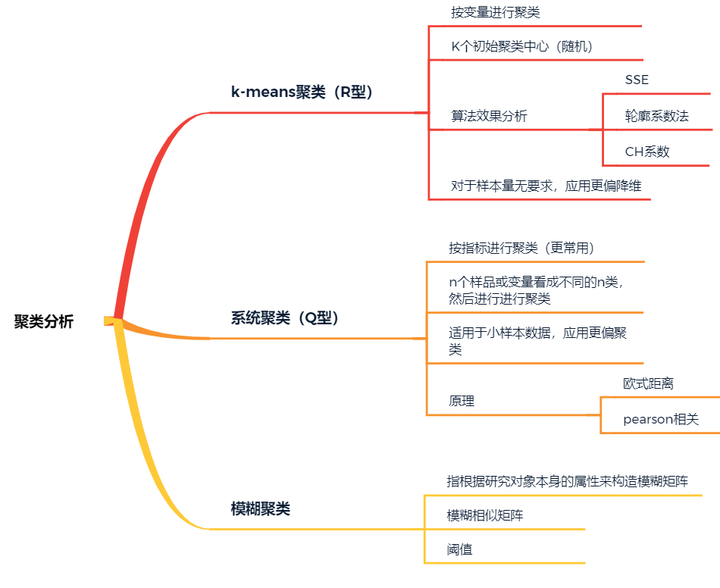
K-means聚类
K-means聚类流程如下:
Step1:选择聚类个数k
Step2:生成k个聚类中心点
Step3:计算所有样本点到中心点的距离,根据距离进行聚类
Step4:进行迭代
Step5:重复迭代,达到收敛要求
K-means聚类算法效果分析一般可以看SSE指标、轮廓系数法、CH系数,需要分析人员在分析前进行多次对比从而达到模型更优的目的。
算法效果一般可以参考,SSE指标、轮廓系数、CH系数等等。
SSE指标(误差平方和):
误差平方和是指真实值和预测值的差,比如:

在聚类分析中的SSE计算如下:


从图片上来看SSE(左图)>SSE(右图),同时也可以看出左侧更稀疏右侧更密集,SSE想要达到最优解,还需要初始聚类中心的选择,否则只能达到一个局部最优解,初始聚类中心的选择可以参考“肘部法”,一般认为“拐点”即下降率突然变缓慢时,认为此点为最佳k值。比如:
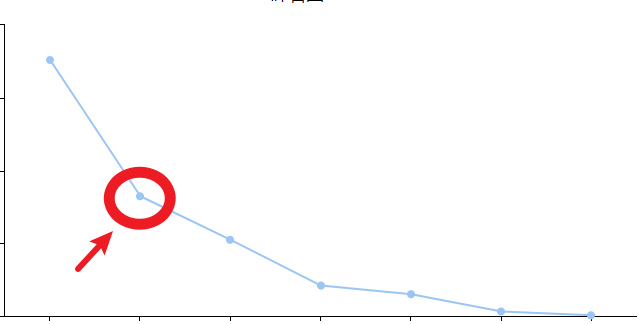
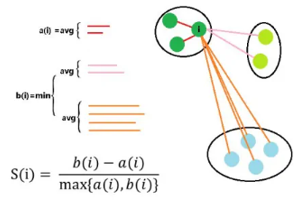
轮廓系数(SC系数):
轮廓系数适用于实际类别信息未知的情况,结合凝聚度和分散度,计算如下:
![]()
其中a为与同类别中其它样本的平均距离,b是与它距离其他类别的平均不相似程度的最小值,取值范围为【-1,1】,同类别中距离越近,不同类别距离越远越好,即轮廓系数越大越好。
CH系数:

系统聚类
系统聚类按指标进行聚类,适用于小样本数据,其步骤如下:
- 把每个指标各自归为一类,比如有n个样本,则为n类
- 寻找最近的两个类,把它们归为一类,此时为n-1类
- 重新计算距离,进行归类,直到所有样本归为一类,结束
- 一般查看树状图进行查看数据分为几类更合适
原理应用到pearson相关和欧式距离,其中欧式距离计算如下:
 其原理簇内距离越小越好,簇间距离越大越好。
其原理簇内距离越小越好,簇间距离越大越好。
模糊聚类
模糊聚类,每个样本以一定的隶属度进行分类,首先进行构建模糊相似矩阵,不需要训练样本,一般计算原理使用夹角余弦法以及相关系数法。
SPSSAU:手把手教你做K均值聚类分析(附操作数据)2 赞同 · 0 评论文章编辑
判别分析
判别分析的一般步骤如下:

判别分析一般分类如下:
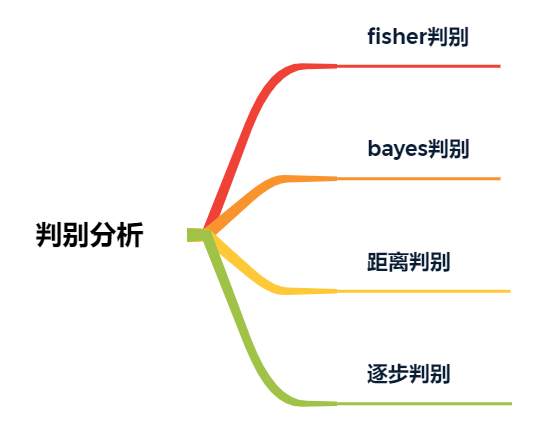
Fisher判别:
根据方差分析原理建立的判别方法,基本思路为投影,依据组间均方差与组内均方差之比最大的原则,进行选择最优的线性函数。
Bayes判别:
概率型判别函数,需要知晓各类别的先验概率或者分布密度,以每个样本属于某个类别的最大概率进行归类。
距离判别:
计算各类分组的均值(即重心),与哪类的重心距离最近,就认为它来自哪类。
逐步判别:
类似于回归分析,通过检验找出显著变量,剔除不显著变量,一般有向前法、向后法、逐步法。
一般进行fisher判别比较多,但是变量较多也可以先进行逐步判别进行筛选下。
SPSSAU:什么是判别分析?如何应用?44 赞同 · 3 评论文章编辑
03预测模型
预测模型常见的方法有:拟合插值预测(线性回归)、神经网络预测、时间序列预测(指数平滑法、移动平均法等)、logisitic回归模型、灰色预测、马尔科夫链预测、微分方程预测等等。
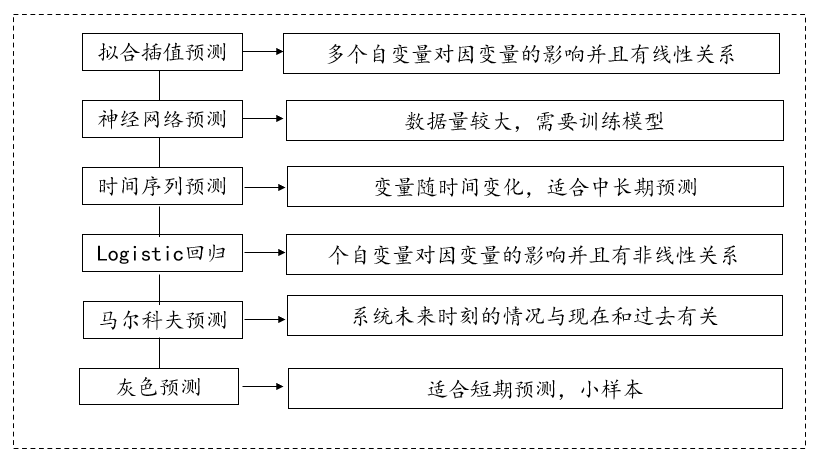
- 拟合插值预测
其中拟合插值算法(线性回归)最为简单,线性回归模型可以进行拟合也可以进行插值,拟合是预测的基础,模型拟合好,预测一般更准确,线性回归一般用于短期预测,并且如果数据有缺失,也是用此方法进行插值,使用该方法进行预测前,需要数据满足线性回归的要求(线性、独立性等等)。
- 神经网络预测
神经网络预测比较考察编程能力,属于现代优化算法,如果使用比较顺畅,当然可以使用此方法进行预测。但是此模型需要大量数据进行训练模型,并且对数据质量要求较高,并且结果不易于解释,如果没有接触过此算法,建议换用其它方法就进行预测,常用于股票预测、水位预测、能源预测等等。
SPSSAU:手把手教你做神经网络0 赞同 · 0 评论文章编辑
- 时间序列预测
时间序列一般预测定量数据的分析方法,使用该方法进行预测前需要考虑数据是否需要季节性调整或者趋势去除等等,常用于气象预报、经济发展情况预测、环境污染预测等等。
- logistic回归模型
logistic回归模型用于分类和预测性分析,适用于二分类和多分类问题,他根据给定的自变量数据集来估计事件发生的概率,比如“购买”和“未购买”,但是logistic回归模型容易出现过拟合或者欠拟合的情况,并且在特定条件下,对异常值较敏感,分析前需要注意。一般用于预测客户是否违约,或分类客户的风险等级。
- 其它
灰色预测一般适用于小样本数据进行预测,马尔科夫链常用于地理或者市场占有率的预测,销售期望利用的预测等等,微分方程常用的模型有传染病模型。理想火箭模型、人口模型等。也可以用于疾病的传播预测等。以及还有其它SVM、小波分析等预测方法。
04优化模型

排队论模型、图论模型、规划模型(目标规划、线性规划、非线性规划、动态规划)、现代优化算法(遗传算法、模拟退火算法、禁忌搜索法)、机器学习(神经网络模型、决策树、随机森林、SVM等)等等。
05比赛技巧
1、图表
一般插入图表会使论文更加美观易懂,但是不能盲目的、大量的进行插图,可以使用matlab、SPSSAU、R等进行绘制。
2、排版
建议尽量使用图文穿插,并且整体格式要正确,善于使用三线表,分段和标题要清晰。
3、模型评估
得到模型后一般进行评估,验证模型的优劣性。
4、摘要
一定要重视摘要,可以在写论文前,多看几篇优秀论文,建议简单明了+精准。
5、参考文献
书写论文时不要忘记标注参考文献。
SPSSAU![]() https://www.spssau.com/?100001217
https://www.spssau.com/?100001217



![[LeetCode周赛复盘] 第 112场双周赛20230903](https://img-blog.csdnimg.cn/f7d3a794b35542ab89e33303b90394e9.png)