USE Method: Rosetta Stone of Performance Checklists
USE Method: Rosetta Stone of Performance Checklists
USE 方法基于 3+1 模型(三种指标类型+一种策略),来切入一个复杂的系统。我发现它仅仅发挥了 5% 的力量,就解决了大概 80% 的服务器问题,并且正如我将证明的,它除了服务器以外,也同样适应于各种系统。
它应当被理解为一种工具,一种很大的方法工具箱里面的工具。不过,它目前仍然还有很多问题类型以待解决,还需要点其他方法和更多的时间。
Summary
USE 方法可以概括为:检查所有的资源的利用率,饱和度,和错误信息。
我们期望大家能尽早使用 USE 方法去做性能检查,或者是用它确定系统的瓶颈。
名词定义:
- 资源: 服务器功能性的物理组成硬件(CPU, 硬盘, 总线)
- 利用率: 资源执行某工作的平均时间
- 饱和:衡量资源超载工作的程度,往往会被塞入队列
- 错误: 错误事件的数量
分析软件资源,或者是软件的强制性限制(资源控制)也是很有用的,同时要关注哪些指标是处于正常的可接受范围之内的。这些指标通常用以下术语表示:
- 利用率: 以一个时间段内的百分比来表示,例如:一个硬盘以 90% 的利用率运行
- 饱和度: 一个队列的长度,例如:CPUs 平均的运行时队列长度是4
- 错误(数): 可度量的数量,例如:这个网络接口有 50 次(超时?)
我们应该要调查那些错误,因为它们会降低系统的性能,并且当故障模型处于可回复模式的时候,它可能不会立刻被发现。
这包括了那些失败和重试等操作,以及那些来自无效设备池的失效设备。
低利用率是否意味着未饱和?
即使在很长一段时间内利用率很低,一个爆发增长的高利用率,也会导致饱和 and 性能问题,这点要理解起来可能有违三观!
我举个例子,有一位客户遇到的问题,即使他们的监控工具显示 CPU 使用率从来没有超出过 80% ,但是 CPU 饱和度依然有问题(延迟)监控工具报告了 5 分钟的平均值,而其中,CPU利用率曾在数秒内高达 100% 。
资源列表
下面来看如何开始使用。
准备工作时, 你需要一个资源列表来按步就班的去做。 下面是一个服务器的通用列表:
- CPUs: sockets, cores, hardware threads (virtual CPUs)
- 内存: 容量
- 网络接口
- 存储设备: I/O, 容量
- 控制器: 存储, 网卡
- 通道: CPUs, memory, I/O
有些组件分两种类型的资源:存储设备是服务请求资源(I / O) 以及容量资源(population), 两种类型都可能成为系统瓶颈。 请求资源可以定义为队列系统,可以将请求先存入排队然后再消化请求。
有些物理组件已被省略,例如硬件缓存(例如,MMU TLB / TSB,CPU)。
USE 方法对于在高利用率或高饱和度下,遭受性能退化、导致瓶颈的资源最有效,在高利用率下缓存可以提高性能。
在使用 USE 方法排除系统的瓶颈问题之后 ,你可以检查缓存利用率和其他的性能属性。
如果你不确认要不要监控某一个资源时,不要犹豫,监控它,然后你就能看到那些指标工作的有多么的棒。
功能模块示意图
另外一种迭代资源的方法,是找到或者绘制一张系统的功能模块示意图。
这些显示了模块关系的图,在你查找数据流的瓶颈的时候是非常有用的,这里有一张Sun Fire V480 Guide(page 82)的例图:
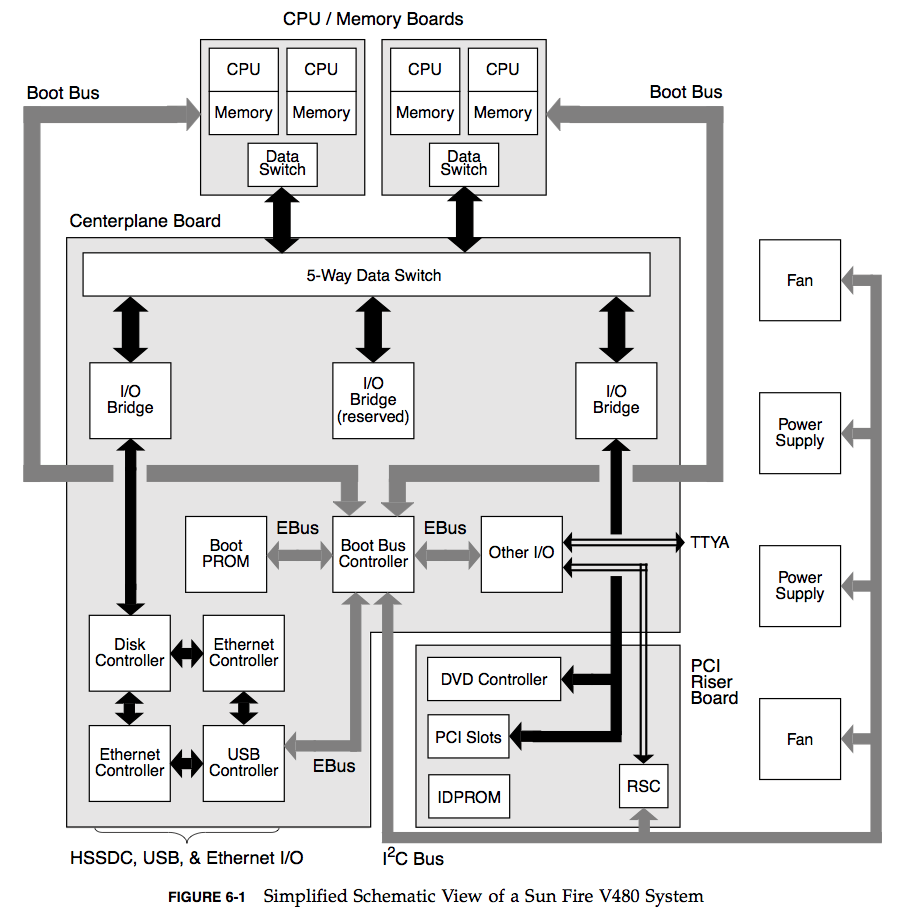
我喜欢这些图表,尽管制作出它很难。 不过,由硬件工程师来画这张图是最适合的-他们最善于做这类事。如果不信的话你可以自己试试。
在确定各种总线的利用率的同时,为每个总线的功能图表,注释好它的最大带宽。这样我们就能在进行单次测量之前,得到能将系统瓶颈识别出来的图表。
Interconnects
CPU,内存和I / O interconnects 往往被忽略。 幸运的是,它们并不会频繁地成为系统的瓶颈。 不幸的是,如果它们真的频繁的成为瓶颈,我们能做的很少(也许你可以升级主板,或减少 load:例如,“zero copy"项目减轻内存总线 load)。
使用 USE 方法,至少你会意识到你没有考虑过的内容:interconnect 性能。 有关使用 USE 方法确定的互连问题的示例,请参阅分析 Analyzing the HyperTransport。
Metrics
给定资源列表,识别指标类型:利用率,饱和度和错误指标。这里有几个示例。看下面的 table,思考下每个资源和指标类型,metric 列是一些通用的 Unix/Linux 的术语提示(你可以描述的更具体些):
resource type metric CPU utilization CPU utilization (either per-CPU or a system-wide average) CPU saturation run-queue length or scheduler latency(aka Memory capacity utilization available free memory (system-wide) Memory capacity saturation anonymous paging or thread swapping (maybe “page scanning” too) Network interface utilization RX/TX throughput / max bandwidth Storage device I/O utilization device busy percent Storage device I/O saturation wait queue length Storage device I/O errors device errors (“soft”, “hard”, …)
这些指标是每段间隔或者计数的平均值,作为你的自定义清单,要包括使用的监控软件,以及要查看的统计信息。如果是不可用的指标,可以打个问号。最后,你会完成一个完事的、简单、易读的 metrics 清单.
Harder Metrics
再来看几个硬件指标的组合
resource type metric CPU errors eg, correctable CPU cache ECC events or faulted CPUs (if the OS+HW supports that) Memory capacity errors Network saturation Storage controller utilization CPU interconnect utilization Memory interconnect saturation I/O interconnect utilization
这些依赖于操作系统的指标一般会更难测量些, 而我通常要用自己写的软件去收集这些指标。
重复所有的组合,并附上获取每个指标的说明,你会完成一个大概有30项指标的列表,其中有些是不能被测量的,还有些是难以测量的。
幸运的是,最常见的问题往往是简单的(例如,CPU 饱和度,内存容量饱和度,网络接口利用率,磁盘利用率),这类问题往往第一时间就能被检查出来。
本文的顶部,pic-1中的 example checklists 可作为参考。
In Practice
读取系统的所有组合指标,是非常耗时的,特别是当你开始使用总线和 interconnect 指标的情况下。
现在我们可以稍微解放下了,USE 方法可以让你了解你没有检查的部分,你可以只有关注其中几项的时间例如:CPUs, 内存容量, 存储容易, 存储设备 I/O, 网络接口等。通过 USE 方法,那些以前未知的未知指标现在变成了已知的未知指标(我理解为,以前我们不知道有哪些指标会有什么样的数据,现在起码能知道我们应该要关注哪些指标)。
如果将来定位一个性能问题的根本原因,对你的公司至关重要的时候,你至少已经有一个明确的、经过验证的列表,来辅助你进行更彻底的分析,请完成适合你自己的 USE 方法,有备无患。
希望随着时间的推移,易于检查的指标能得以增长,因为被添加到系统的 metrics 越多,会使 USE 方法将更容易(发挥它的力量)。 性能监视软件也可以帮上忙,添加 USE 方法向导to do the work for you(do what work? )。
Software Resources
有些软件资源可以用类似的方式去分析。 这通常适用于软件的较小组件,而不是整个应用程序。 例如:
- 互斥锁(mutex locks):利用率可以定义为锁等待耗时;饱和率定义为等待这把锁的线程个数。
- 线程池:利用率可以定义为线程工作的时长;饱和率是等待线程池分配的请求数量。
- 进程/线程 容量:系统是有进程或线程的上限的,它的实际使用情况被定义为利用率;等待数量定义为饱和度;错误即是(资源)分配失败的情况(比如无法 fork)。 (译注:fork 是一个现有进程,通过调用 fork 函数创建一个新进程的过程)
- 文件描述符容量(file descriptor capacity):和上述类似,但是把资源替换成文件描述符。
如果这几个指标很管用就一直用,要不然软件问题会被遗留给其他方法了(例如,延迟,后文会提到其他方法:other methodologies )。
Suggested Interpretations
USE 方法帮助你定位要使用哪些指标。 在学习了如何从操作系统中读取到这些指标后,你的下一步工作就是诠释它们的值。对于有的人来说, 这些诠释可能是很清晰的(因为他们可能很早就学习过,或者是做过笔记)。而其他并不那么明了的人,可能取决于系统负载的要求或期望 。
下面是一些解释指标类型的通用建议:
- Utilization: 利用率通常象征瓶颈(检查饱和度可以进一步确认)。高利用率可能开始导致若干问题:
- 对利用率进行长期观察时(几秒或几分钟),通常来说 70% 的利用率会掩盖掉瞬时的 100% 利用率。
- 某些系统资源,比如硬盘,就算是高优先级请求来了,也不会在操作进行中被中断。当他们的利用率到 70% 时候,队列系统中的等待已经非常频繁和明显。而 CPU 则不一样,它能在大部分情况下被中断。
- Saturation:任何非 0 的饱和度都可能是问题。它们通常是队列中排队的时间或排队的长度。
- Errors:只要有一条错误,就值得去检查,特别是当错误持续发生从而导致性能降低时候。
要说明负面情况很容易:利用率低,不饱和,没有错误。 这比听起来更有用 - 缩小调查范围可以快速定位问题区域。
Cloud Computing
在云计算环境中,软件资源控制可能是为了限制 使用共享计算服务的 tenants 的流量。在 Joyent 公司,我们主要使用操作系统虚拟化(SmartOS),它强加了内存限制, CPU 限制和存储I / O限制。 所有这些资源限制,都可以使用USE Method进行检查,类似于检查物理资源。
例如,在我们的环境中,“内存容量利用率"可以是 tenants 的内存使用率 vs 它的内存上限 。即使传统的 Unix 页面扫描程序可能处于空闲状态,也可以通过匿名页面活动看到"内存容量饱和度”。
Strategy
下面是用流程图 的方式画了 USE 方法的示意图。 请注意,错误检查优先于利用率和饱和度检查(因为通常错误更快的表现出来,并更容易解释)。
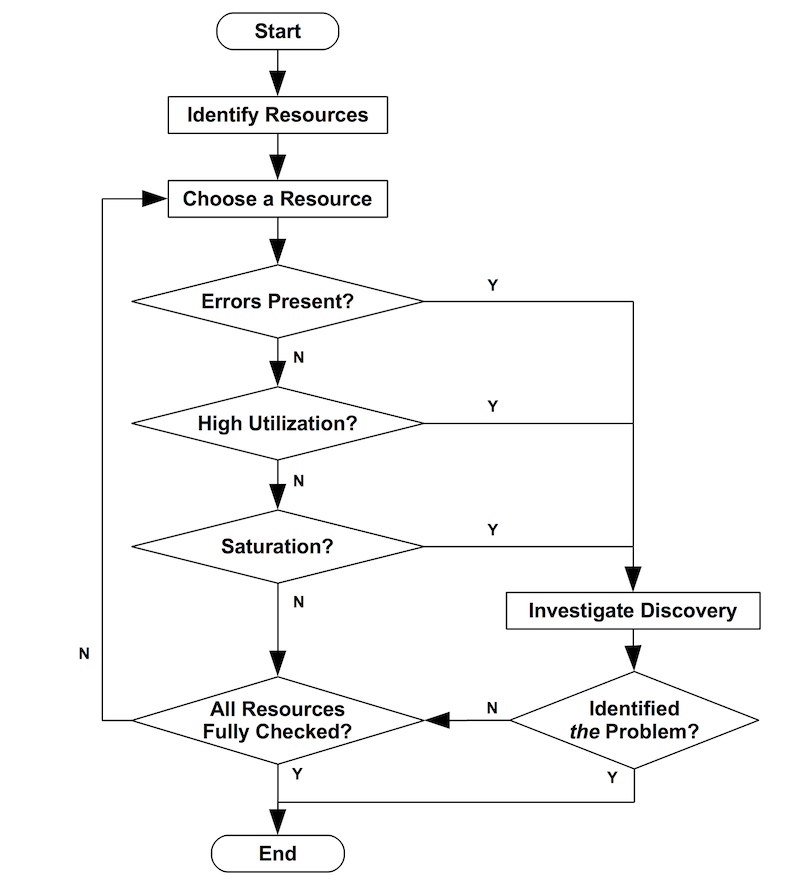
USE 方法定位到的问题,可能是系统瓶颈。 不幸的是,系统可能会遇到多个性能问题,因此您发现的第一个可能的问题最终却不是个问题。 发现的每个问题都可以用方法持续的挖掘,然后继续使用 USE 方法对更多资源进行反复排查。
进一步分析的策略包括工作量特征和 drill-down 分析。 完成这些后,你应该有依据据能判断,纠正措施是要调整应用的负载或调整资源本身。
Apollo
(译者注:Apollo 这一段我们可以不太关注,它主要是讲 USE 方法,与阿波罗登月计划相关的系统设计的一些渊源)
我之前有提到过,USE 方法可以被应用到除服务器之外。为了找到一个有趣的例子, 我想到了一个我没有完全不了解的系统,并且不知道从哪里开始:阿波罗月球模块指导系统。 USE 方法提供了一个简单的流程来尝试第一步是寻找一个资源列表,或者更理想的话,找到一个功能模块图表。我在 【Lunar Module - LM10 Through LM14 Familiarization Manual】中发现了以下内容:
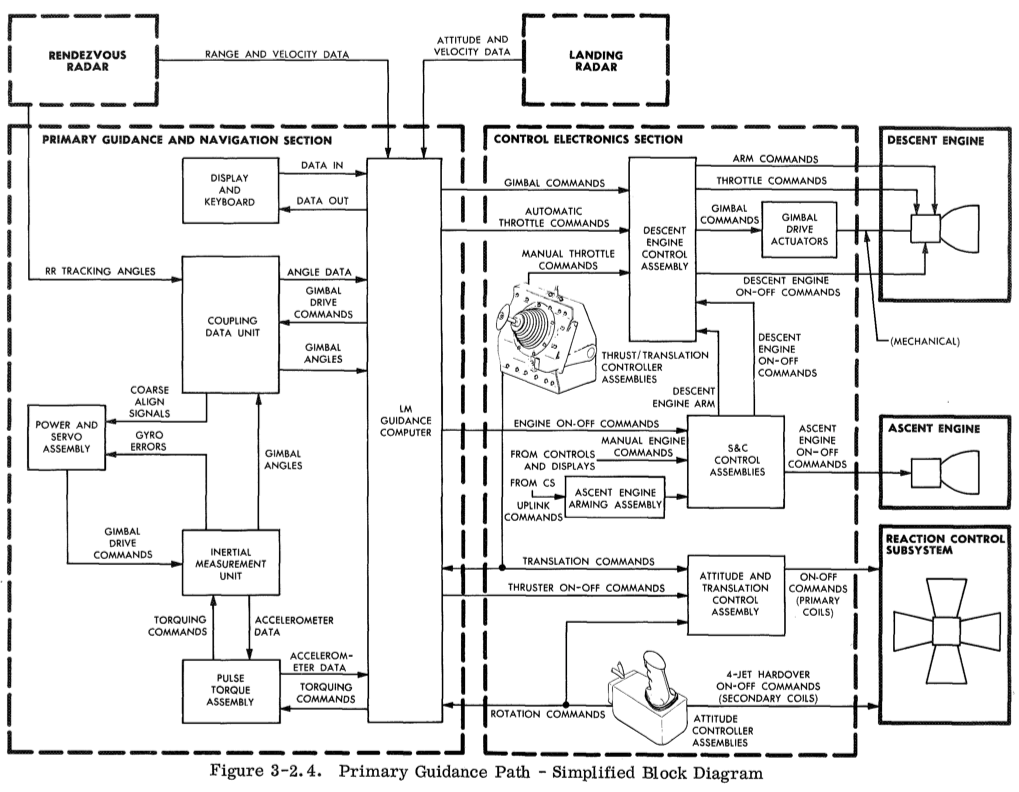
这些组件中的一部分可能未表现出利用率或饱和度特性。在迭代后, 就可以重新绘制只包含相关组件的图表(还可以包括:“可擦除存储"部分的内存,“核心区域"和 “vac区域 “寄存器)。
我将从阿波罗主脑(AGC)本身开始。 对于每个指标,我浏览了各种 LM 文档,看看哪些是合理的(有意义的):
- AGC utilization: This could be defined as the number of CPU cycles doing jobs (not the “DUMMY JOB”) divided by the clock rate (2.048 MHz). This metric appears to have been well understood at the time.
- AGC saturation: This could be defined as the number of jobs in the “core set area”, which are seven sets of registers to store program state. These allow a job to be suspended (by the “EXECUTIVE” program - what we'd call a “kernel” these days) if an interrupt for a higher priority job arrives. Once exhausted, this moves from a saturation state to an error state, and the AGC reports a 1202 “EXECUTIVE OVERFLOW-NO CORE SETS” alarm.
- AGC errors: Many alarms are defined. Apart from 1202, there is also a 1203 alarm “WAITLIST OVERFLOW-TOO MANY TASKS”, which is a performance issue of a different type: too many timed tasks are being processed before returning to normal job scheduling. As with 1202, it could be useful to define a saturation metric that was the length of the WAITLIST, so that saturation can be measured before the overflow and error occurs.
其中的一些细节,可能对于太空爱好者来说是非常熟悉的:在阿波罗 11 号降落的时候发生的著名的 1201(“NO VAC AREAS”)和 1202 警报。(“VAC"是向量加速器的缩写, 用于处理 vector quantities 作业的额外存储; 我觉得 wikipadia 上将 “向量"描述为"空"可能是错误的)。
鉴于阿波罗 11 号的 1201 警报,可以继续使用其他方法分析,如工作负载表征。 工作负载很多可以在功能图中看到,大多数工作负载是通过中断来生效的。 包括用于跟踪命令模块的会合雷达,即使 LM 正在下降,该模块也仍然在执行中断 AGC(阿波罗主脑)的任务。 这是发现非必要工作的一个例子(或低优先级的工作; 雷达的一些更新可能是可取的,因此 LM AGC可以立即计算出中止路径)。
作为一个更深的例子,我将把会合雷达当作资源去检查. 错误最容易识别。 有三种信号类型: “DATA NO GOOD”, “NO TRACK”, and “SHAFT- AND TRUNNION-AXIS ERROR”。
在有某一小段时间里,我不知道能从哪里开始使用这个方法, 去寻找和研究具体的指标。
Other Methodologies
虽然 USE 方法可能会发现 80% 的服务器问题,但基于延迟的方法(例如Method R)可以找到所有的问题。 不过,如果你不熟悉软件内部结构,Method R 就有可能需要花费更多时间。 它们可能更适合已经熟悉它的数据库管理员或应用程序开发人员。
而 USE 方法的职责和专长包括操作系统(OS)和硬件,它更适合初级或高级系统管理员,当需要快速检查系统健康时,也可以由其他人员使用。
Tools Method
以下介绍一个基于工具的方法流程(我称它作"工具方法”),与 USE 方法作比较:
- 列出可用的性能工具(可以选择性安装或购买其他的)。
- 列出每个工具提供的有用的指标
- 列出每个工具可能的解释规则
按照这个方法做完后,将得到一个符合标准的清单,它告诉我们要运行的工具,要关注的指标以及如何解释它们。 虽然这相当有效,但有一个问题,它完全依赖于可用(或已知的)的,可以提供系统的不完整视图的工具。 用户也不知道他们得到的是一张不完整的视图 - 所以问题将仍然存在。
而如果使用 USE 方法,不同的是, USE 方法将通过迭代系统资源的方式,来创建一个完整的待确认问题列表,然后搜索工具来回答这些问题。这样构建了一张更完整的视图,未知的部分被记录下来,它们的存在被感知(这一句我理解成前文中提到的:未知 的未知变为已知的未知)。 基于 USE ,同样可以开发一个清单类似于工具方法(Tool-Method),显示要运行的工具(可用的位置),要关注的指标以及如何解释它。
另一个问题是,工具方法在遍历大量的工具时,将会使寻找瓶颈的任务性能得到分散。而 USE 方法提供了一种策略,即使是超多的可用工具和指标,也能有效地查找瓶颈和错误。
Conclusion
USE 方法是一个简单的,能执行完整的系统健康检查的策略,它可以识别常见的系统瓶颈和错误。它可以在调查的早期部署并快速定位问题范围,如果需要的话,还可以进一步通过其他方法进行更详细的研究。
我在这个篇幅上,解释了 USE 方法并且提供了通用的指标案例,请参阅左侧导航面板中对应操作系统的示例清单, 其建议了应用 USE 方法的工具和指标。另请参阅基于线程的补充方法,TSA Method。
Acknowledgments
- 感谢 Cary Millsap and Jeff Holt (2003) 在"优化 Oracle 性能"一文中提到的 Method R 方法 (以及其他方法), 使我有了灵感,我应该要把这个方法论写出来。
- 感谢 Sun Microsystems 的组织,包括 PAE 和 ISV, 他们将 USE 方法(那时还没命名)应用于他们的存储设备系列,绘制了标注指标和总线速度的 ASCII 功能块图表 - 这些都比您想象的要困难(我们应该早些时候询问硬件团队的帮助)。
- 感谢我的学生们,多年前我授予他们这个方法论,谢谢他们提供给我的使用反馈。
- 感谢 Virtual AGC 项目组(The Virtual AGC project),读他们的站点 ibiblio.org 上的文档库,就象是一种娱乐. 尤其是 LMA790-2 “Lunar Module LM-10 Through LM-14 Vehicle Familiarization Manual” ( 48 页有功能模块图表), 以及 “阿波罗指导和月球导航模块入门学习指南”, 都很好的解释了执行程序和它的流程图 (These docs are 109 and 9 Mbytes in size.)
- 感谢 Deirdré Straughan 编辑和提供反馈,这提高了我的认知。
- 文章顶部的图片,是来自于波音 707 手册,1969 出版。它不是完整的,点击查看完整的版本(译注:为方便阅读,就是下面这张:)
Updates
USE Method updates:(略)
- It was published in ACMQ as Thinking Methodically about Performance (2012).
- It was also published in Communications of the ACM as Thinking Methodically about Performance (2013).
- I presented it in the FISL13 talk The USE Method (2012).
- I spoke about it at Oaktable World 2012: video, PDF.
- I included it in the USENIX LISA `12 talk Performance Analysis Methodology.
- It is covered in my book on Systems Performance, published by Prentice Hall (2013).
More updates (Apr 2014):
- LuceraHQ are implementing USE Method metrics on SmartOS for performance monitoring of their high performance financial cloud.
- LuceraHQ 正在 SmartOS 上,为他们高性能金融云的性能监测,实施 USE 方法指标
- I spoke about the USE Method for OS X at MacIT 2014 (slides)。