进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. explain查询执行计划
2. WHERE与PRWHERE子句
3. GROUP BY 子句
1. explain查询执行计划
clickhouse在版本20.6.3之后支持explain查看执行计划。explain基本语法如下:
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...] SELECT ... [FORMAT ...]对以上解释如下:
- AST:用于查看语法树。
- SYNTAX:用于查询clickhouse优化后的语法。
- PLAN:用于查看执行计划,默认值。
- PIPELINE:用于查看PIPELINE计划,相对于PLAN更加详细。
1) AST查看语法树:
node1 :) EXPLAIN AST SELECT id,name,age,local FROM mr_tbl;
2) SYNTAX查看优化后语法,比较常用。
node1 :) EXPLAIN SYNTAX SELECT t.id,t.name FROM (SEELCT id,name FROM person_info) t WHERE t.id <3;
3) PLAN:用于查看执行计划,默认值。
在使用PLAN时有一些设置:
- header:打印计划中各个步骤的输出头,默认关闭,默认值0。
- description:打印计划中各个步骤的描述,默认开启,默认值1。
- indexes:打印计划中使用的索引,默认关闭,默认值0,支持MergeTree表引擎。
- actions:打印计划中各个步骤的详细信息,默认关闭,默认值0.
- json:打印计划步骤时使用json格式展示,默认关闭,默认值0,建议使用默认TSVRaw格式,避免不必要的开销。
node1 :) EXPLAIN PLAN SELECT id ,name ,age FROM mr_tbl;
#设置一些属性后查询结果node1 :) EXPLAIN PLAN header=1,description=1,indexes=1,actions=1,json=1 SELECT id ,name ,age FROM mr_tbl;编辑
以上关于json中详细的字段解释可以参照官网解释:EXPLAIN Statement | ClickHouse Docs
4) PIPELINE:用于查看PIPELINE计划,相当于是PLAN更详细的描述。
在执行pipeline是也可以设置一些参数:
- header:打印计划中各个步骤的输出头,默认关闭,默认值0。
- graph:使用DOT图形语言描述管道图,默认关闭,默认值0。
- compact:如果graph开启,以紧凑模式打印管道图,默认开启,默认值1。
node1 :) EXPLAIN PIPELINE header=1 SELECT sum(number) FROM numbers_mt(100000) GROUP BY number % 4;
2. WHERE与PRWHERE子句
Where 子句基于条件表达式来实现数据过滤,如果过滤条件恰好是主键字段,则能够借助索引加速查询。例如:
创建MergeTree引擎表mt_tbl,设置id为主键,并插入数据,操作如下:
#创建表 mt_tbl
node1 :) CREATE TABLE mt_tbl
(
`id` UInt8,
`name` String,
`age` UInt8,
`loc` String,
`birthday` Date
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(birthday)
ORDER BY id
#向表中插入以下数据
node1 :) insert into mt_tbl values (1,'zs',18,'beijing','2021-01-01'),(2,'ls',18,'shanghai','2021-02-01'),(3,'ww',18,'tianjin','2021-03-01'),(4,'ml',18,'nanjing','2021-01-02'),(5,'tq',18,'wuhan','2021-01-03'),(6,'gb',18,'beijing','2021-01-04'),(7,'a1',18,'shanghai','2021-03-01'),(8,'a2',18,'guanzhou','2021-04-01'),(9,'a3',18,'sehnzhen','2021-04-01'),(10,'a4',18,'beijing','2021-03-01');
对以上表进行如下查询,where中包含主键,说明能够使用索引过滤数据区间。
node1 :) select id,name,age from mt_tbl where id = 8;
┌─id─┬─name─┬─age─┐
│ 8 │ a2 │ 18 │
└────┴──────┴─────┘可以通过执行计划,来查看是否使用索引:
node1 :) explain plan indexes=1 select id,name,age from mt_tbl where id = 8;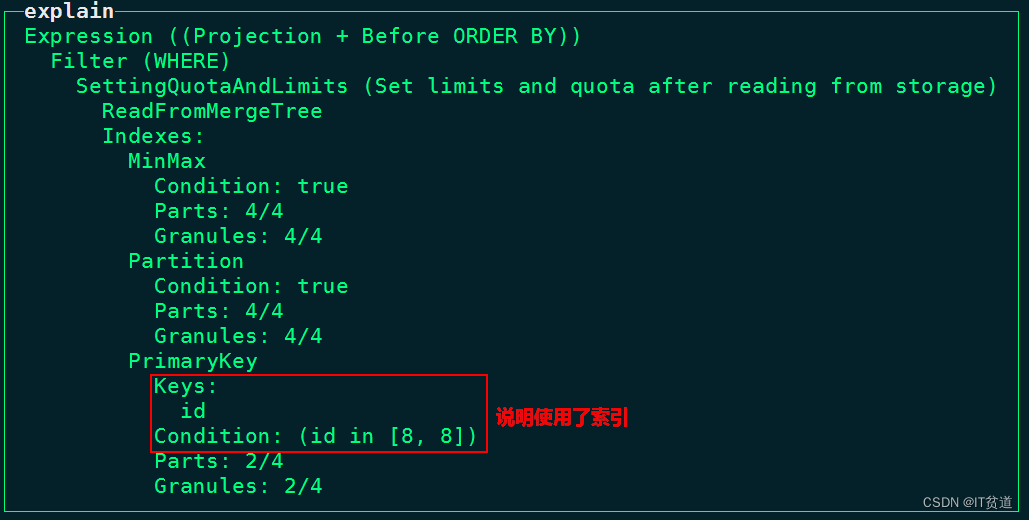
除了where子句中包含主键能使用索引加快查询速度之外,clickhouse还提供了PREWHERE子句。
PREWHERE子句目前只能用于MergeTree系列表引擎,可以看成是where的优化,作用也是来过滤数据。与where不同之处在于PREWHERE只会读取指定的列字段数据,用于数据过滤的条件判断,待数据过滤之后再读取SELECT声明的列字段以补全其余属性。所以在一些场合,PREWHERE相对于Where来说,处理的数据量更少,性能更高。
可以执行如下操作来对比where 与Prewhere之间的差异:
#首先执行set optimize_move_to_prewhere=0强制关闭自动优化,在clickhouse中此参数默认开启,在执行一些sql时,clickhouse会自动将where转换成prewhere,这里关闭这个功能,方便测试
node1 :) set optimize_move_to_prewhere=0;
#执行如下where语句:
node1 :) select WatchID,Title,GoodEvent FROM datasets.hits_v1 WHERE RequestNum>3000;
815411 rows in set. Elapsed: 2.143 sec. Processed 8.87 million rows, 891.17 MB (4.14 million rows/s., 415.86 MB/s.)
#执行如下prewhere 语句:
node1 :) select WatchID,Title,GoodEvent FROM datasets.hits_v1 PREWHERE RequestNum>3000;
815411 rows in set. Elapsed: 2.094 sec. Processed 8.87 million rows, 684.71 MB (4.24 million rows/s., 326.91 MB/s.)我们可以看到相同SQL语句使用where和prewhere查询的数据量一样,但是使用prewhere的效率很高,每秒读取数据吞吐量极大。
在clickhouse中不必将所有的where都替换成prewhere,clickhouse实现了自动优化的功能,在条件合适情况下,会将where替换成prewhere。如果想开启这项特性,需要将optimize_move_to_prewhere设置为1,默认即为1,开启优化功能。
我们可以重新在clickhouse中将optimize_move_to_prewhere参数设置为1,查看clickhouse对where的自动优化:
#设置optimize_move_to_prewhere=1
node1 :) set optimize_move_to_prewhere=1;
#查看如下SQL的优化语句
node1 :) explain syntax select WatchID,Title,GoodEvent FROM datasets.hits_v1 WHERE RequestNum>3000;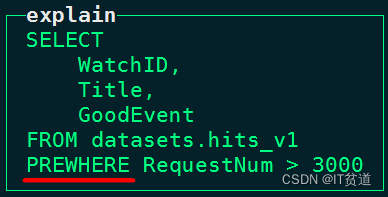
以下场景中Where不会自动优化成Prewhere:
- 使用常量表达式:
select id,name,age from tbl where 1=1 - 使用Alias字段:
select id ,name ,age from tbl where avg_age = 10
注意:avg_age是其他查询 as的字段- 包含arrayjoin的查询
select id,name,local from tbl array join local where id =2- select 查询的列字段与where谓词完全相同
select id from tbl where id = 1- 使用了主键字段
select id from tbl where id = 13. GROUP BY 子句
Group By子句又称聚合查询,与MySQL或者Hive中的使用方式一样,但是需要注意一点在Select查询中如果有聚合查询,例如max,min等,与聚合查询出现的字段一定要出现在Group by中,否则语句报错。
clickhouse中的Group by 还可以配合WITH ROLLUP、WITH CUBE、WITH TOTALS三种修饰符获取额外的汇总信息。
创建表mt_tbl2 并加载数据:
#创建表mt_tbl2
node1 :) CREATE TABLE mt_tbl2
(
`province` String,
`city` String,
`item` String,
`totalcount` UInt32
)
ENGINE = MergeTree()
ORDER BY (province, city)
#向表中插入如下数据:
node1 :) insert into mt_tbl2 values ('北京','海淀','苹果手机',100),('上海','黄浦','小米手机',200),('北京','丰台','苹果手机',300),('北京','大兴','华为手机',400),('上海','嘉定','华为手机',500),('
北京','海淀','华为手机',600),('上海','黄浦','小米手机',700),('北京','大兴','苹果手机',800),('上海','嘉定','华为手机',900),('北京','海淀','小米手机',1000);
- WITH ROLLUP
ROLLUP 能够按照聚合键从右向左上卷数据,基于聚合函数依次生成分组小计和总计。操作如下:
node1 :) select province,city,item,sum(totalcount) as total from mt_tbl2 group by province,city,item with rollup;
- WITH CUBE
CUBE 是立方体意思,WITH CUBE会基于聚合键之间所有的组合生成小计信息。操作如下:
node1 :) select province,city,item,sum(totalcount) as total from mt_tbl2 group by province,city,item with cube;

- WITH TOTALS
WITH TOTALS 会基于聚合键生成结果外,还会附带一行Totals汇总统计。操作如下:
node1 :) select province,city,item,sum(totalcount) as total from mt_tbl2 group by province,city,item with totals;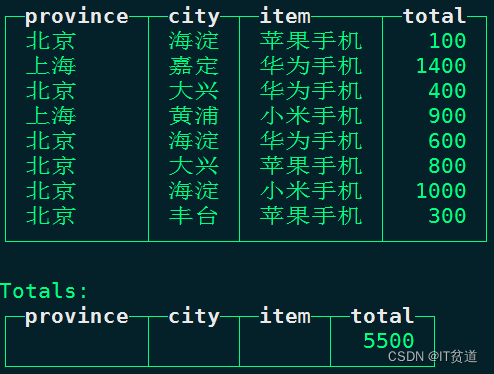
👨💻如需博文中的资料请私信博主。