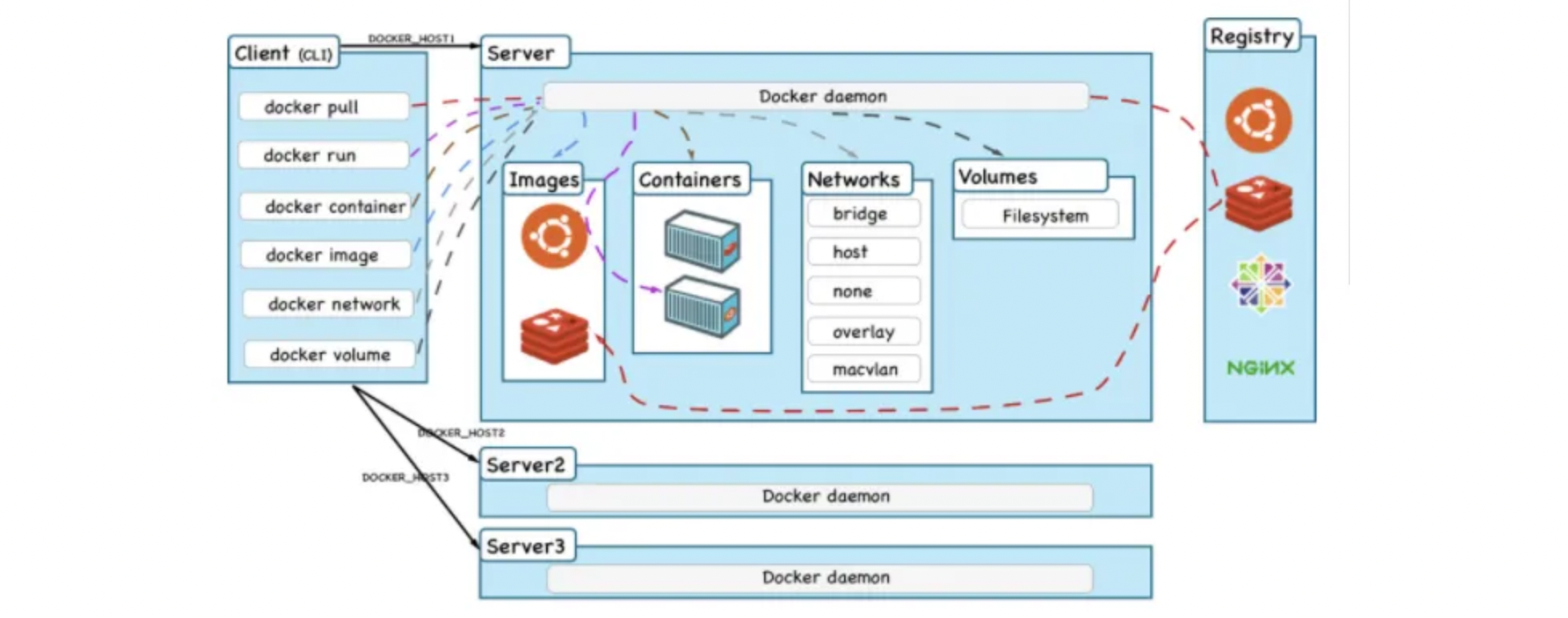
SQL笔记
基本概述
- 数据库:保存有组织的数据的容器(通常是一个文件或一组文件)。容易混淆:人们通常用数据库这个术语来代表他们使用的数据库软件,这是不正确的,也因此产生了许多混淆。确切地说,数据库软件应称为数据库管理系统(DBMS)。
- 什么是SQL?:SQL(Structured Query Language——结构化查询语言)是一种专门用来与数据库沟通的语言。
检索
-
DISTINCT关键字:DISTINCT关键字
select distinct id from table --检索table里面id不一样的值 -
TOP、LIMIT关键字:限制最多返回多少行
--SQL Server返回前五行 select top 5 user_name from user_table; --DB2 字面意思fetch first 5 rows only 只取五行 select user_name from user_table fetch first 5 rows only; --oracle 基于ROWNUM(行计数器)来计算行 select user_name from user_name where rownum <=5; --MySQL、MariaDB、PostgreSQL或者SQLite select user_name from user_table limit 5; --LIMIT 5 OFFSET 5指示MySQL等DBMS返回从第5行起的5行数据。第一个数字是检索的行数,第二个数字是指从哪儿开始 select user_name from user_table limit 5 offset 5 --简化 select user_name from user_table limit 5,5; --注意:第0行第一个被检索的行是第0行,而不是第1行。因此,LIMIT 1 OFFSET 1会检索第2行,而不是第1行。 --提示:MySQL、MariaDB和SQLite捷径MySQL、MariaDB和SQLite可以把LIMIT 4 OFFSET 3语句简化为LIMIT 3,4。使用这个语法,逗号之前的值对应OFFSET,逗号之后的值对应LIMIT(反着的,要小心)。 -
排序检索数据:ORDER BY,在指定一条ORDER BY子句时,应该保证它是SELECT语句中最后一条子句。如果它不是最后的子句,将会出错。
--按年龄排序 select name from table order by age; --多个排序,多个行具有相同的age值时才对table按name进行排序。如果age列中所有的值都是唯一的,则不会按name排序。 select name from table order by age,name; --按列位置排序 不介意使用 select name from table order by 2,3; /*说明: ORDER BY 2表示按SELECT清单中的第二个列age进行排序。ORDER BY 2, 3表示先按age,再按name进行排序。 这一技术的主要好处在于不用重新输入列名。但它也有缺点。首先,不明确给出列名有可能造成错用列名排序。其次,在对SELECT清单进行更改时容易错误地对数据进行排序(忘记对ORDER BY子句做相应的改动) */ --指定排序方向,数据排序不限于升序排序(从A到Z),这只是默认的排序顺序,为了进行降序排序,必须指定DESC关键字。 select name from table order by age desc;--年龄最大的排在最前面 /*警告: 在多个列上降序排序如果想在多个列上进行降序排序,必须对每一列指定DESC关键字。 */
过滤数据
-
过滤数据
-
where语句:数据根据WHERE子句中指定的搜索条件进行过滤。WHERE子句在表名(FROM子句)之后给出。
--检索name为Tom的数据 select * from table where name ='name';操作符
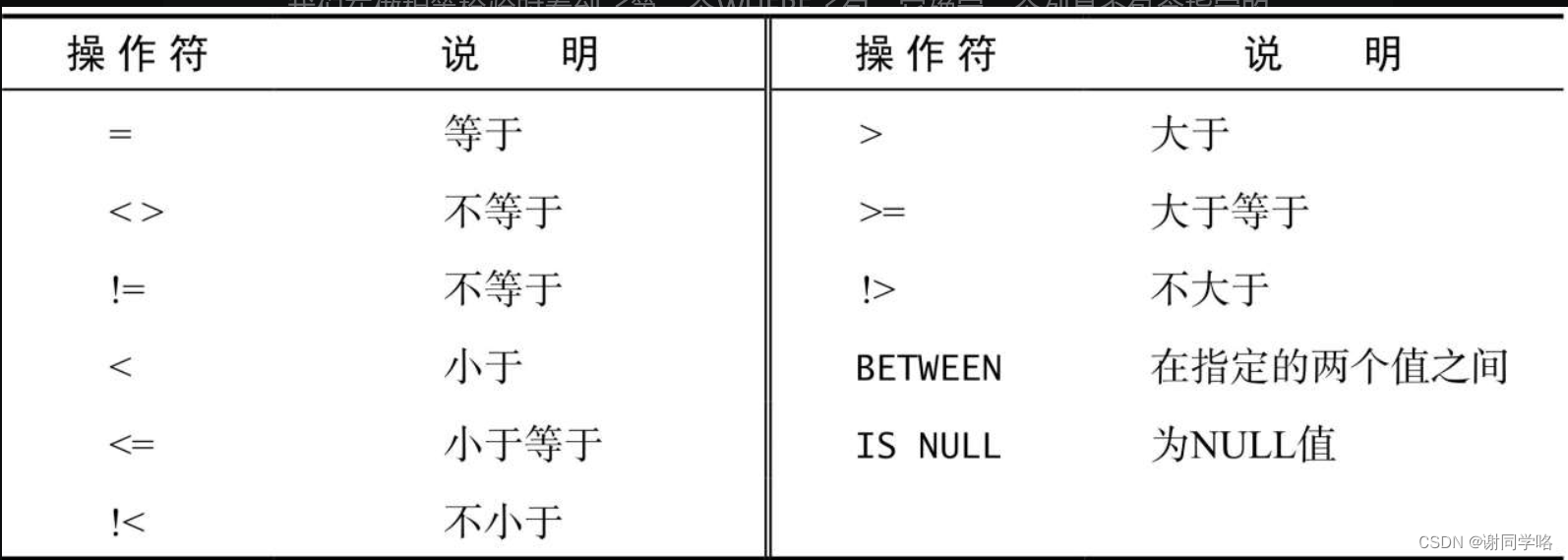
表中列出的某些操作符是冗余的(如< >与!=相同,!< 相当于>=)。并非所有DBMS都支持这些操作符。想确定你的DBMS支持哪些操作符,请参阅相应的文档。
-
BETWEEN操作符:其语法与其他WHERE子句的操作符稍有不同,因为它需要两个值,即范围的开始值和结束值。
--检索年龄5到15岁的数据 select * from table where age between 5 and 15; -
空值检查:NULL——无值(no value),它与字段包含0、空字符串或仅仅包含空格不同
--检索没写年龄/年龄为空的数据 select * from table where age is null; /* 通过过滤选择不包含指定值的所有行时,你可能希望返回含NULL值的行。但是这做不到。因为NULL比较特殊,所以在进行匹配过滤或非匹配过滤时,不会返回这些结果。 */-
求值顺序:括号——>and——>or
--假如需要列出价格为10美元及以上,且由DLL01或BRS01制造的所有产品 select pros_name ,prod_price from products where vend_id='DLL01' or vend_id='BRS01' and prod_price >=10;结果:
-
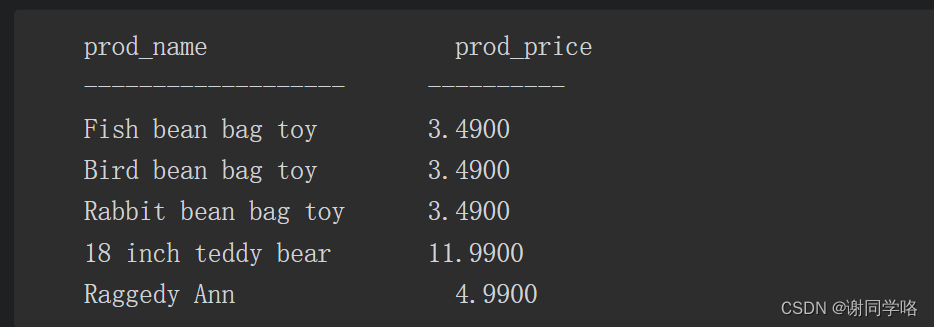
分析:返回的行中有4行价格小于10美元,显然,返回的行未按预期的进行过滤。
SQL(像多数语言一样)在处理OR操作符前,优先处理AND操作符。当SQL看到上述WHERE子句时,它理解为:由供应商BRS01制造的价格为10美元以上的所有产品,以及由供应商DLL01制造的所有产品,而不管其价格如何。换句话说,由于AND在求值过程中优先级更高,操作符被错误地组合了。
改正后:
select pros_name ,prod_price
from
products
where (vend_id='DLL01' or vend_id='BRS01')
and prod_price >=10;
/*
提示:在WHERE子句中使用圆括号任何时候使用具有AND和OR操作符的WHERE子句,都应该使用圆括号明确地分组操作符。不要过分依赖默认求值顺序,即使它确实如你希望的那样。使用圆括号没有什么坏处,它能消除歧义。
*/
圆括号具有比AND或OR操作符更高的优先级,所以DBMS首先过滤圆括号内的OR条件。这时,SQL语句变成了选择由供应商DLL01或BRS01制造的且价格在10美元及以上的所有产品,这正是我们希望的结果。
-
IN操作符:用来指定条件范围,范围中的每个条件都可以进行匹配。
--检索年龄为15,25的数据 select name from user_table where age in (15,25) --这其实和or是一样的 select name from user_table where age = 15 or age = 25; --上个例子里面,IN相当于加了个括号了 select pros_name ,prod_price from products where --(vend_id='DLL01' or vend_id='BRS01') vend_id in ('DLL01','BRS01') and prod_price >=10;用IN的优点:IN操作符一般比一组OR操作符执行得更快。
-
NOT操作符:WHERE子句中用来否定其后条件的关键字。
--检索id不是1522的数据 select * from table where not id = 1522; --等同于<>、!= selec * from table where id !=1522 -
LIKE操作符:模糊查询,和%、_等使用
SQL的通配符很有用。但这种功能是有代价的,即通配符搜索一般比前面讨论的其他搜索要耗费更长的处理时间
不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。在确实需要使用通配符时,也尽量不要把它们用在搜索模式的开始处。把通配符置于开始处,搜索起来是最慢的。仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
-
拼接字段:将值联结到一起(将一个值附加到另一个值)构成单个值。
Access和SQL Server使用+号。DB2、Oracle、PostgreSQL、SQLite和OpenOffice Base使用 || 。
--sql server 检索姓名和年龄 select name + '('+age+')' from table --PgSQL select name || '('|| age ||')' from table --RTRIM()函数去掉空格name 要为字符串 数字类型会报错 select age || '('|| rtrim(name)')' from table --别名 SELECT name || '('|| rtrim(address) ||')' as add_name FROM company -- MySQL 拼接name和sex作为username返回 select concat(name,'(',sex,')') as username from t_user order by name -
SQL算术操作符:+、-、*、/等等
--计算费用作为price_result返回 select prod_price*number as price_result, prod_price,number from products; --去除首尾空字符串 select trim(' abc ');-- abc --获取当前日期 select now() as time;
数据处理函数
函数
- 文本处理函数:用于处理文本字符串(如删除或填充值,转换值为大写或小写)的文本函数。
--上面用过的RTRIM()函数来去除列值右边的空格
--upper() 转化为大写
select name ,upper(name) as name_upper from user order by name;
/*
SQL函数不区分大小写,因此upper(), UPPER(), Upper()都可以,substr(), SUBSTR(), SubStr()也都行。随你的喜好,不过注意保持风格一致,不要变来变去,否则你写的程序代码就不好读了。
*/
常用的文本处理函数
| 函数 | 说明 |
|---|---|
| left()(或使用子字符串函数) | 返回字符串左边的字符 |
| length()(也使用datalength或len( )) | 返回字符串的长度 |
| lower() | 将字符串转换为小写 |
| ltrim() | 去掉字符串左边的空格 |
| right() (或者使用子字符串函数) | 返回字符串右边的字符 |
| ririm() | 去掉字符串右边的空格 |
| substr()或者substring() | 提取字符串的组成部分 |
| suondex() | 返回字符串的suodex值 |
| upper() | 将字符串转换为大写 |
说明:
SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对字符串进行发音比较而不是字母比较。虽然SOUNDEX不是SQL概念,但多数DBMS都提供对SOUNDEX的支持。
PostgreSQL不支持SOUNDEX(),因此以下的例子不适用于这个DBMS另外,如果在创建SQLite时使用了SQLITE_SOUNDEX编译时选项,那么SOUNDEX()在SQLite中就可用。因为SQLITE_SOUNDEX不是默认的编译时选项,所以多数SQLite实现不支持SOUNDEX()。
--Customers表中有一个顾客KidsPlace,其联系名为Michelle Green。但如果这是错误的输入,此联系名实际上应该是Michael Green,该怎么办呢?显然,按正确的联系名搜索不会返回数据
select name from customers where name='Michelle Green'; --显然检索不出来
select name from customers where soundex(name) ='Michelle Green';
-
日期函数:日期和时间函数在SQL中具有重要的作用。遗憾的是,它们很不一致,可移植性最差。
--SQL Serve 要检索出某年的所有订单,需要按订单日期去找,但不需要完整日期,只要年份即可。 select number from order_item where datepart(yy , create_date) = 2020; -- PgSql select number from order_item where date_part('year' , create_date) = 2020; --Oracle EXTRACT()函数用来提取日期的成分,year表示提取哪个部分,返回值再与2020进行比较。 select number from order_item where extract(year from create_date) = 2020; --DB2,MySQL和MariaDB select number from order_item where year(create_date) = 2020; --在SQLite中有个小技巧 select number from order_item where strftime('%Y' , create_date) = 2020; -
数值处理函数
函数 说明 ABS() 返回一个数的绝对值 COS() 返回一个角度的余弦 EXP() 返回一个数的指数值 PI() 返回圆周率的值 SIN() 返回一个角度的正弦 SQRT() 返回一个数的平方根 TAN() 返回一个角度的正切 -
聚合函数:对某些行运行的函数,计算并返回一个值。
常见例子:
确定表中行数(或者满足某个条件或包含某个特定值的行数);
获得表中某些行的和;
找出表列(或所有行或某些特定的行)的最大值、最小值、平均值。
/* 函数 说明 ------------------------------------------------------------------------------------------------------ AVG() 平均值 COUNT() 返回行数 MAX() 最大值 MIN() 最小值 SUM() 求和--求数量平均值,AVG()函数忽略列值为NULL的行 select AVG(number) avg_numer from orderNo /* 使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。 使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值 */ select count(*) from table; select count(id) from table; --聚集不同值,使用了DISTINCT参数,因此平均值只考虑各个不同的数值 select avg(distinct number) as avg_number from table;注意:DISTINCT不能用于COUNT(*)如果指定列名,则DISTINCT只能用于COUNT()。DISTINCT不能用于COUNT(*)。类似地,DISTINCT必须使用列名,不能用于计算或表达式。提示:将DISTINCT用于MIN()和MAX()虽然DISTINCT从技术上可用于MIN()和MAX(),但这样做实际上没有价值。一个列中的最小值和最大值不管是否只考虑不同值,结果都是相同的。
说明:其他聚集参数除了这里介绍的DISTINCT和ALL参数,有的DBMS还支持其他参数,如支持对查询结果的子集进行计算的TOP和TOP PERCENT。为了解具体的DBMS支持哪些参数,请参阅相应的文档。
-
组合聚集函数
--查询价格的总数、最大值、最小值和平均值 select count(*) as item_num, max(prod_price) as max_price, min(prod_price) as min_price, avg(prod_price) as avg_price from products; /* 注意:取别名在指定别名以包含某个聚集函数的结果时,不应该使用表中实际的列名。虽然这样做也算合法,但许多SQL实现不支持,可能会产生模糊的错误消息。 */
分组数据
-
GROUP BY子句
--按名称排序,分别显示数量 select name , count(*) from table group by name;- 大多数SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本或备注型字段)
- 除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前
-
HAVING支持所有WHERE操作符
--检索所有id>2的姓名,并按姓名分组 select name , count(*) from table group by name having id >2;where和having的区别:
-
where在数据分组前进行过滤,having在数据分组后进行过滤。
-
使用having时应该结合group by子句,而where子句用于标准的行级过滤。
-
-
group by 和order by

/*
一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
*/
select name, age from t_user where age>12 group by name, age order by age;
- select 子句和顺序
-
子查询
--检索 select name from t_user where age in(select age from t_user where sex ='男')说明:
对于能嵌套的子查询的数目没有限制,不过在实际使用时由于性能的限制,不能嵌套太多的子查询。
作为子查询的SELECT语句只能查询单个列。企图检索多个列将返回错误
-
作为计算字段使用子查询
select name ,(select count(*) from t_user) as num,age from t_user;
组合查询
-
UNION:UNION从查询结果集中自动去除了重复的行
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合四条SELECT语句,将要使用三个UNION关键字)。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过,各个列不需要以相同的次序列出)。
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含转换的类型(例如,不同的数值类型或不同的日期类型)
说明:
UNION的列名如果结合UNION使用的SELECT语句遇到不同的列名,那么会返回什么名字呢?比如说,如果一条语句是SELECT prod_name,而另一条语句是SELECTproductname,那么查询结果返回的是什么名字呢?答案是它会返回第一个名字,举的这个例子就会返回prod_name,而不管第二个不同的名字。这也意味着你可以对第一个名字使用别名,因而返回一个你想要的名字。这种行为带来一个有意思的副作用。由于只使用第一个名字,那么想要排序也只能用这个名字。拿我们的例子来说,可以用ORDER BY prod_name对结果排序,如果写成ORDER BY productname就会出错,因为查询结果里没有叫作productname的列。
-
UNION ALL:返回所有的匹配行
- UNION ALL为UNION的一种形式,它完成WHERE子句完成不了的工作。如果确实需要每个条件的匹配行全部出现(包括重复行),就必须使用UNIONALL,而不是WHERE。
插入、更新、删除
-
INSERT:插入
insert into t_user(id,name,age,sex) values (1,'tom',22,'男') -
更新
update t_user set name ='admin' where id =6; -
删除
delete from t_user where id=6;
视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询
SQL特性(约束、索引)
约束
-
主键:主键是一种特殊的约束,用来保证一列(或一组列)中的值是唯一的,而且永不改动
任意两行的主键值都不相同。
每行都具有一个主键值(即列中不允许NULL值)。
包含主键值的列从不修改或更新。(大多数DBMS不允许这么做,但如果你使用的DBMS允许这样做,好吧,千万别!)
主键值不能重用。如果从表中删除某一行,其主键值不分配给新行
-
外键:外键是表中的一列,其值必须列在另一表的主键中。外键是保证引用完整性的极其重要部分.
-
唯一约束:唯一约束用来保证一列(或一组列)中的数据是唯一的。它们类似于主键,但存在以下重要区别。
表可包含多个唯一约束,但每个表只允许一个主键。
唯一约束列可包含NULL值。
唯一约束列可修改或更新。
唯一约束列的值可重复使用。
与主键不一样,唯一约束不能用来定义外键。
-
检查约束:检查约束用来保证一列(或一组列)中的数据满足一组指定的条件。
检查约束的常见用途有以下几点。
检查最小或最大值。例如,防止0个物品的订单(即使0是合法的数)。
指定范围。例如,保证发货日期大于等于今天的日期,但不超过今天起一年后的日期。
只允许特定的值。例如,在性别字段中只允许M或F。
索引
-
索引用来排序数据以加快搜索和排序操作的速度。
-
创建索引前,应该记住以下内容:
索引改善检索操作的性能,但降低了数据插入、修改和删除的性能。在执行这些操作时,DBMS必须动态地更新索引。索引数据可能要占用大量的存储空间。
并非所有数据都适合做索引。取值不多的数据(如州)不如具有更多可能值的数据(如姓或名),能通过索引得到那么多的好处。
索引用于数据过滤和数据排序。如果你经常以某种特定的顺序排序数据,则该数据可能适合做索引。
可以在索引中定义多个列(例如,州加上城市)。这样的索引仅在以州加城市的顺序排序时有用。如果想按城市排序,则这种索引没有用处。
-
索引用CREATE INDEX语句创建。



![[附源码]Nodejs计算机毕业设计基于推荐算法的鞋服代购平台Express(程序+LW)](https://img-blog.csdnimg.cn/113244823bd94d0b951dad6f77c714cb.png)