容器类型:
- 标准STL序列容器:
vector, string, deque, list - 标准STL关联容器:
set, multiset, map, multimap - 非标准序列容器
slist和rope - 非标准关联容器:
hash_set, hash_multiset, hash_map, hash_multimap - 标准的非STL容器:
数组, bitset, valarray, stack, queue, qriority_queue
不要试图编写独立于容器类型的代码
可能有的方法是某种容器独有的,有的方法虽然名字相同,但返回值不同,迭代器/指针的失效情况也不尽相同,要编写通用的代码只能取每个容器功能的交集,但是这样又在功能上产生了很大的局限性。在选择容器时要谨慎。
有时候不可避免的要更换容器类型,一种常规的方法是:使用封装技术。最简单的方式是使用typedef对容器类型和其迭代器起别名:
// 不推荐
class Widget{...};
vector<Widget> vw;
Widget bestWidget;
//...
vector<Widget>::iterator i = find(vw.begin(), vw.end(), bestWidget);
// 推荐
class Widget{...};
typedef vector<Widget> WidgetContainer;
typedef WidgetContainer::iterator WCIterator;
WidgetContainer cw;
Widget bestWidget;
//...
WCIterator i = find(cw.begin(), cw.end(), bestWidget);
这样改变容器类型就简单的多,编写代码时使用别名也更加方便。
确保容器中的对象拷贝正确高效
容器中很多操作都需要调用容器所存放的对象的拷贝构造函数。比如在vector, string, deque执行元素的插入或删除操作,可能会对现有的元素进行移动,移动过程中就会产生拷贝事件。
在存在继承关系的情况下,拷贝动作会导致对象切片(slicing)。如果创造了一个存放基类对象的容器,但是向其中添加了派生类对象,那么派生类对象通过基类的拷贝构造函数拷贝进容器,派生类独有的部分就会丢失。
可以通过在容器内存放指针来避免这种切片现象,而且指针拷贝的效率也很高,同时考虑智能指针会避免传统指针可能导致的内存泄露的问题,所以容器内存放智能指针是比较好的选择。
但是容器相对传统数组还是有优势的:
Widget w[maxNumWidgets]; // 每个对象都会使用默认构造函数来创建
vector<Widget> vw; // 不会调用任何默认构造函数
vw.reserve(maxNumWidgets); // 同样不会调用任何默认构造函数
调用empty而不是检查size()
对于大部分容器来说if (c.size() == 0)本质上和if(c.empty())是等价的,empty()通常被实现为内联函数,并且所做的仅仅是返回size是否为0
但是对于一些list实现,size()会消耗线性时间。为什么list不提供常数时间的size()呢,原因在于list所独有的链接操作,要保证链接操作是常数时间,那么size()就不能实现为常数时间。
区间成员函数优先于单元素成员函数
给定v1和v2两个vector,使v1的内容和v2的后半部分相同推荐操作是:
v1.assign(v2.begin() + v2.size() / 2, v2.end());
为什么不推荐循环赋值呢?
-
使用区间成员函数,通常可以少些一些代码
-
使用区间成员函数通常会得到意图更加清晰的代码
-
同时效率也有一定差别
加入要把一个int数组插入到一个vector的最前面,使用区间函数如下:int data[numValues]; vector<int> v; // ... v.insert(v.begin(), data, data + numValues);而如果要通过循环操作的话:
vector<int>::iterator insertLoc(v.begin()); for (int i = 0; i < numValues; ++i) { insertLoc = v.insert(insertLoc, data[i]); ++insertLoc; }每次循环都需要进行很多额外的赋值操作,这样会更频繁的进行内存分配,更频繁的拷贝对象,还有可能有冗余操作。
更详细对比单元素版本的insert()和区间版本的insert(),单元素版本总共在三个方面影响的效率
- 不必要的函数调用,在循环中对
insert()进行了numValues次调用,虽然这种调用产生的影响可以通过内联来避免,但是实际insert()的实现不一定是内联的 - 会把
v中已有的元素频繁的移动到插入后它们所在的位置,这种影响是内联也无法避免的 - 如果容器内是自定义类型的话,还会额外调用拷贝构造函数
区间版本的insert()函数直接把现有的元素移动到他们最终的位置上;单元素插入过程中还有可能发生多次扩容,而区间版本由于知到自己需要多少新内存,所以不必多次重新分配内存。
上面的大部分论断对于其他序列容器都适应,但是对于list而言,虽然拷贝和内存分配的问题不存在,但是额外的函数调用问题依旧存在,与此同时还出现了新问题,对于指针的额外赋值操作。
总结一下有哪些成员函数支持区间:
-
区间创建:所有的标准容器都提供了下面形式的构造函数
container::container(InputIterator begin, InputIterator end); -
区间插入:所有的标准序列容器都提供了如下形式的
insertvoid container::insert(iterator position, // 插入开始的位置 InputIterator begin, // 区间开始 InputIterator end); // 区间结束关联容器利用比较函数决定元素该插入何处,它们提供了一个省去position参数的函数原型
void container::insert(InputIterator begin, InputIterator end); -
区间删除:所有标准容器都提供了区间形式删除操作,但是序列容器和关联容器的返回值有所不同。序列容器是以下的形式
iterator container::erase(iterator begin, iterator end);关联容器提供了如下形式
void container::erase(iterator begin, iterator end); -
区间赋值:所有的标准容器都提供了区间形式的赋值操作
void container::assign(InputIterator begin, InputIterator end);
优先选择区间成员函数而不是其对应的单元素成员函数:区间成员函数写起来更容易;能更清晰地表达意图;并且它们表现出了更高的效率。
注意C++编译器的分析机制
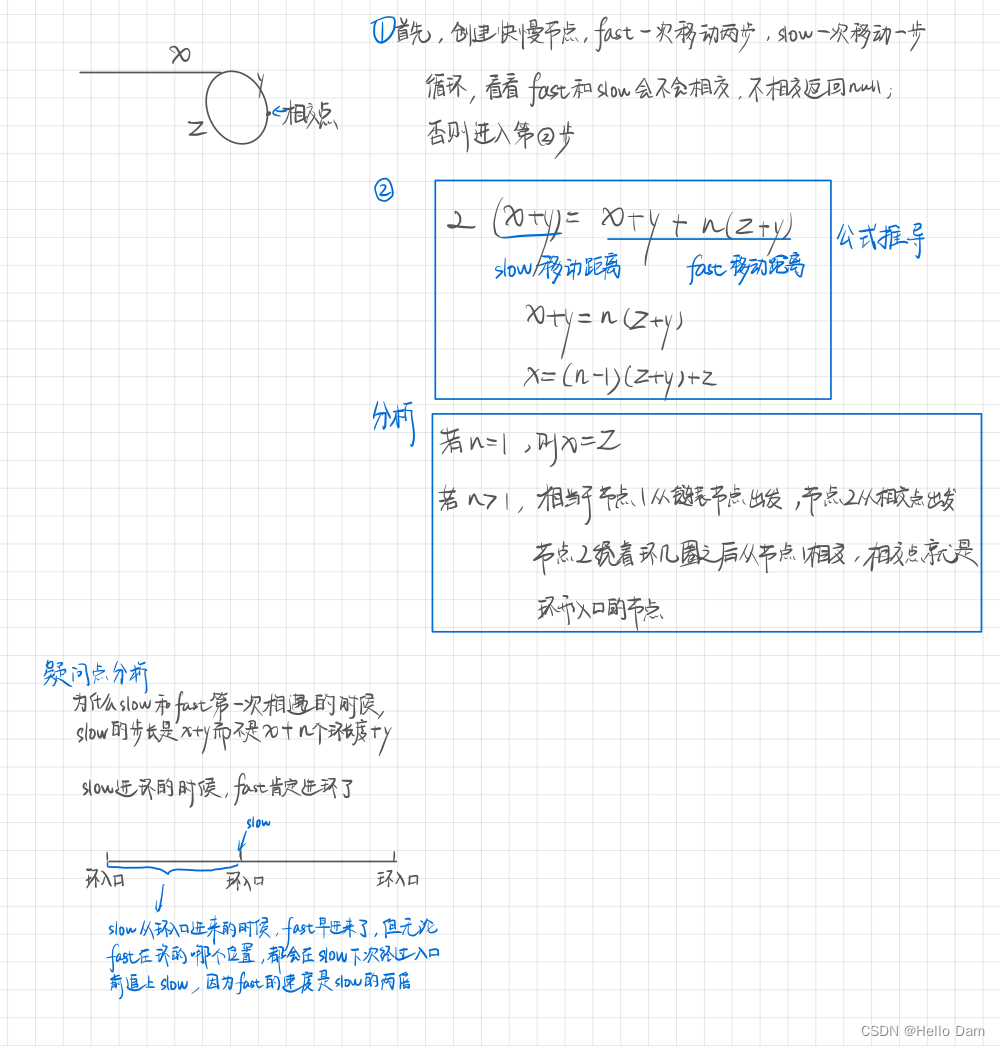
假设有一个存有整数(int)的文件,现在要把这些整数拷贝到一个list中去。下面是一种合理的做法
ifstream dataFile("int.dat");
list<int> data(istream_iterator<int>(dataFile), // 尝试传入指向文件流开始的位置
istream_iterator<int>()); // 文件流的末尾
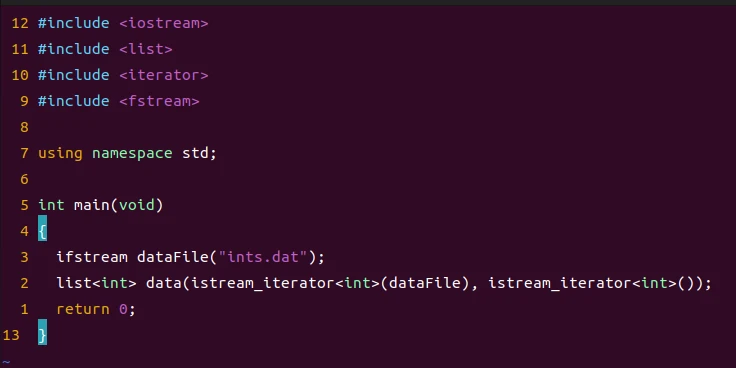
上面这段代码也可以通过编译器编译,但是实际上这段代码并不能达到我们想要的效果,实际上上面的这段话声明了一个函数,为什么会这样呢?
先考虑函数的声明
// 下面这行声明了一个合法的函数
int f(double d);
// 下面这种做法也是正确的
int f(double (d)); // d两边的括号会被忽略
// 下面这种做法同样是正确的
int f(double);
再看参数带函数指针的函数的声明
int g(double(*pf) ());
int g(double pf()); // 同上,pf为隐式指针
int g(double ()); // 同上,省去了参数名
再看原来的代码
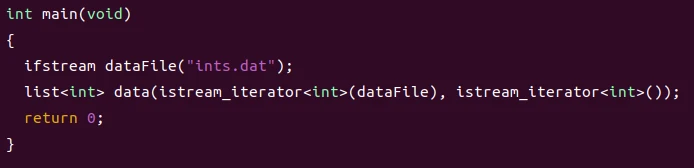
它实际上声明了一个函数data,返回值为list<int>类型。这个函数有两个参数
- 第一个参数名为
dataFile。它的类型是istream_iterator<int>。形参名两边的括号被忽略了 - 第二个参数没有名称。它的类型是指向不带参数的函数指针,这个函数的返回类型是
istream_iterator<int>
非常的神奇,这是因为C++中有一条普遍的规律,即尽可能地解释为函数声明。实际上在前面编译的时候编译器已经警告我们了:
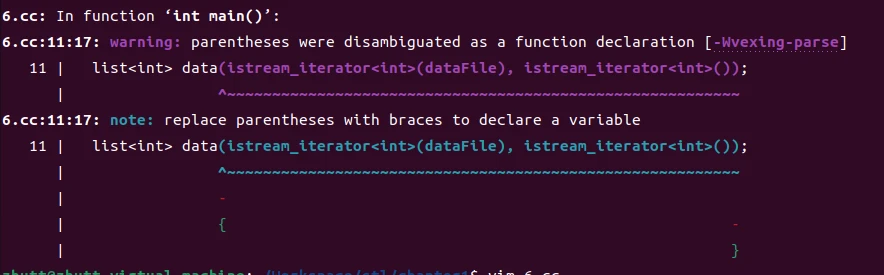
类似的错误还有下面这种
class Widget{
// ...
};
Widget w(); // 并不会调用默认构造函数
那该怎么避免这种问题呢?给形式参数的声明用括号括起来是非法的,但是给函数参数加上括号是合法的。所以当出现歧义的时候,我们可以通过加上一对括号来强迫编译器消除这种歧义:
list<int> data((istream_iterator<int>(dataFile)),
istream_iterator<int>());
这次编译也不会产生警告了,代码也可以达到我们想要的意思了。但是有的编译器不支持这种方式,那么我们通过在构造函数调用的前面先把对象声明好,也同样可以达到效果:
istream_iterator<int> dataBegin(dataFile);
istream_iterator<int> dataEnd;
list<int> data(dataBegin, dataEnd);
元素的删除
假设有一个标准STL容器Container<int> c;,删除这个容器中特定值的元素会因容器类型而异,没有通用的方法。
如果针对连续内存容器(vector ,deque, string),那么最好的方法就是使用erase-remove方法
c.erase(remove(c.begin(), c.end(), 1963),
e.end());
如果采用循环erase的方法,每次循环erase都会产生大量元素移动的开销;remove()函数并不真正的删除元素,而是把符合删除条件的元素全部排到容器的末尾,然后返回指向第一个待删除元素的迭代器,通过这样的方法可以提高删除效率。
针对list上面的方法同样使用,但是list的成员函数remove更加有效
c.remove(1963);
当针对标准关联容器,使用remove或remove_if都是错误的,他们不能用于返回const_iterator的容器。正确的做法是调用erase成员函数
c.erase(1963);
接下来把上面的问题更改一下,这次不是从c中删除所有特定值,而是通过一个函数来判断一个元素是否需要被删除:
bool badValue(int );
针对序列容器,我们把remove调用换成remove_if就行了
c.erase(remove_if(c.begin(), c.end(), // 当c为vector, string或deque
badValue), c.end());
c.remove_if(badValue); // 当c为list
针对关联容器来说,有两种方法:一种是通过remove_copy_if把我们需要的值拷贝到一个新容器中,然后把原来的容器和新容器的内容进行交换:
AssocContainer<int> c;
AssocContainer<int> goodValues;
remove_copy_if(c.begin(), c.end(),
inserter(goodValues, goodValues.end()),
badValue);
c.swap(goodValues);
如果不想付出这么多的拷贝代价,那么我们可以使用另外一种方法:直接从原始的容器中删除元素,但是关联容器没有提供类似remove_if的成员函数,所以我们需要写一个循环来遍历c中的元素,在遍历的过程中删除。
AssocContainer<int> c;
for (AssocContainer<int>::iterator i = c.begin(); i != c.end(); ) {
if (badValue(*i)) c.erase(i++); // 注意这里要使用后缀自增, 防止迭代器失效
else ++i;
}
如果需要在删除元素的同时进行一些其他的操作(如添加日志),那么针对序列容器来说,就需要改用循环删除了
ofstream logFile;
for (SeqContainer<int>::iterator i = c.begin();
i != c.end();) {
if (badValue(*i)) {
logFile << "Erasing " << *i << '\n';
i = c.erase(i); // erase返回了下一个可用的迭代器
}
}
针对关联容器来说只需要在上面的循环删除过程中直接添加就行了
AssocContainer<int> c;
for (AssocContainer<int>::iterator i = c.begin(); i != c.end(); ) {
if (badValue(*i)){
logFile << "Erasing " << *i << '\n';
c.erase(i++); // 注意这里要使用后缀自增, 防止迭代器失效
}
else ++i;
}
了解内存分配器(allocator)
内存分配器是为了内存模型的抽象而产生的,它会负责内存的分配和释放,还负责对象的构造和析构。
这里太抽象了,现在看不懂。
STL的线程安全性
STL能满足的:
- 多个线程读是安全的。多个线程可以同时读同一个容器中的内容,并且保证是正确的
- 多个线程对不同的容器进行写操作是安全的



![java八股文面试[数据库]——自适应哈希索引](https://img-blog.csdnimg.cn/baf498c854184fe1be9b9debef316390.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAc3RvbmVfbWlu,size_20,color_FFFFFF,t_70,g_se,x_16)