文章目录
- 问题点
- 原因解释
碰到了,一个错误,debug才定位到问题,记录一下。
本次最大收获是,pandas果然代码逻辑复杂,一个小小的异常捕捉,处处是门道。。。。。。
希望本次浅显的代码阅读过程,给你有小小的启发,愿您多读复杂代码,提升自我。
问题点
Series.str用到list对象上,不会产生报错,而是返回一个NaN。
如下代码:
import pandas as pd
df = pd.DataFrame([1,2,3,4], columns=['test'])
df.loc[:, 'mylist'] = [[1,], [32,3], [923], [324,4444]]
df # output 1
df.mylist.str.lower() # output2
output1:
test mylist
0 1 [1]
1 2 [32, 3]
2 3 [923]
3 4 [324, 4444]
output2:
0 NaN
1 NaN
2 NaN
3 NaN
Name: mylist, dtype: float64
原因解释
- 查官网
https://pandas.pydata.org/docs/reference/api/pandas.Series.str.html#
没有查询到有用信息
- 查代码
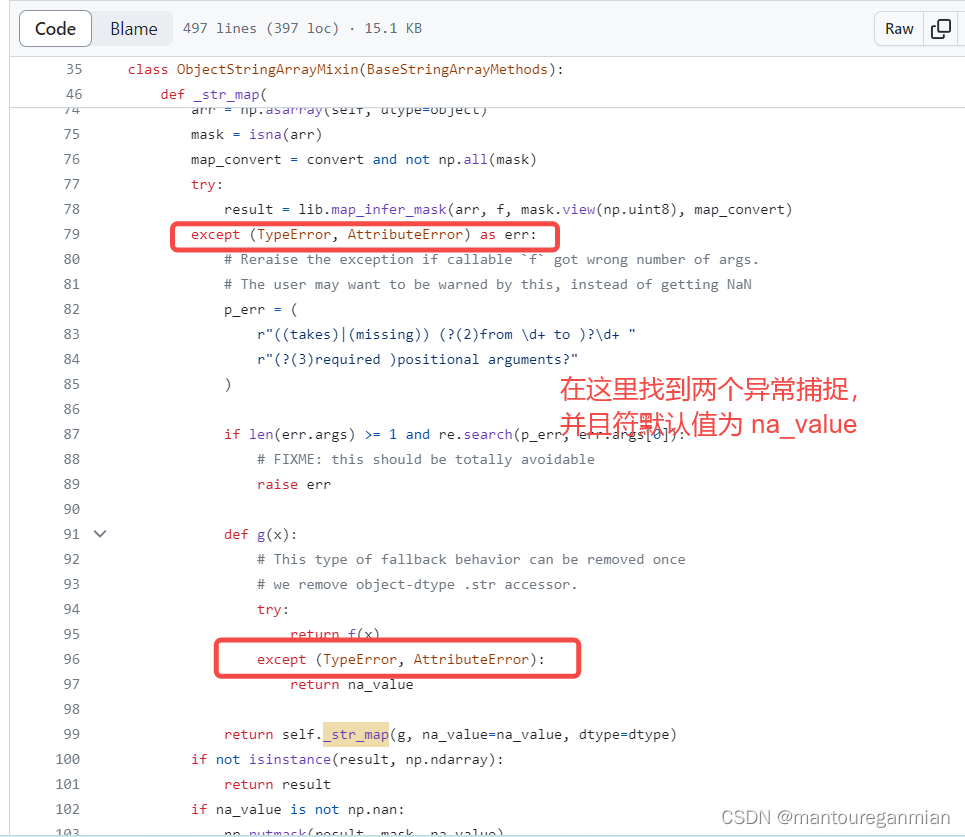
查看源代码,发现是pandas异常捕捉并给了默认值。其具体过程如下:
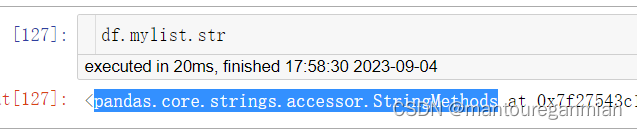
如上图所示得到对象类型,使用pandas.core.strings.accessor.StringMethods搜索到github上源代码:https://github.com/pandas-dev/pandas/blob/main/pandas/core/strings/accessor.py
@Appender(_shared_docs["casemethods"] % _doc_args["lower"])
@forbid_nonstring_types(["bytes"])
def lower(self):
result = self._data.array._str_lower()
return self._wrap_result(result)
模拟运行如下,发现有报错,猜测,正常情况
df.mylist.str._data.array._str_lower()
output:
array([nan, nan, nan, nan])
查看df.mylist.str._data.array类型为:
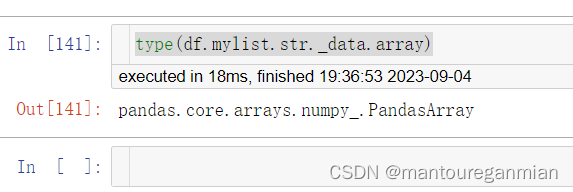
搜索类型pandas.core.arrays.numpy_.PandasArray找到其源代码:在github中找不到’PandasArray’。
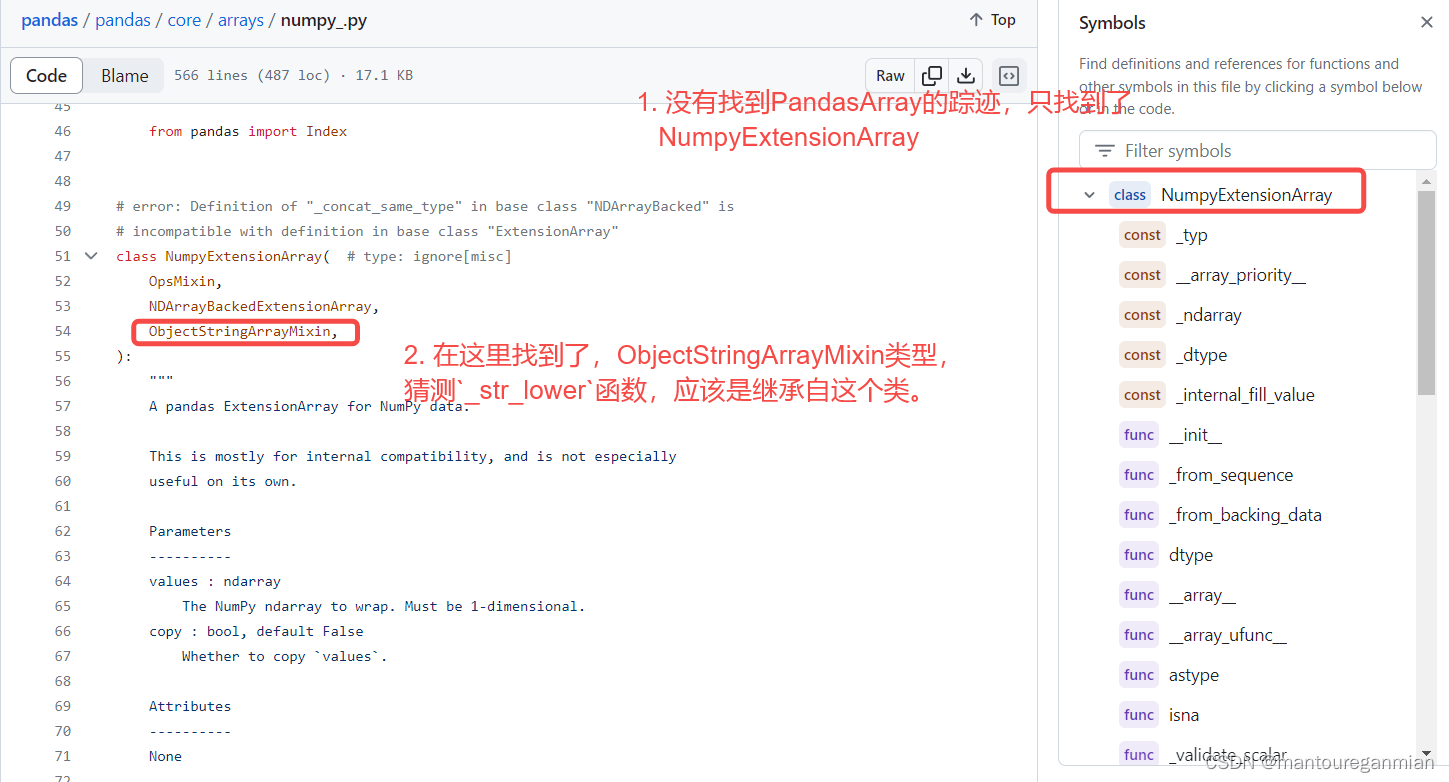
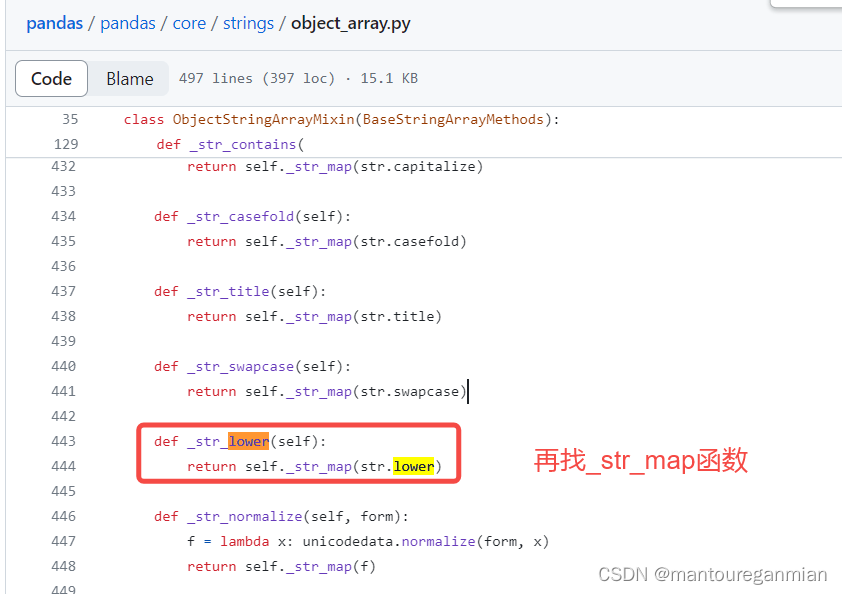
找到ObjectStringArrayMixin发现_str_lower函数,如下: