1 stream和parallelStream的区别
1.Stream 是在 Java8 新增的特性,普遍称其为流;它不是数据结构也不存放任何数据,其主要用于集合的逻辑处理。
2.Stream流是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值),它只是在原数据集上定义了一组操作。
3.Stream流不保存数据,Stream操作是尽可能惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
4.Stream流不会改变原有数据,想要拿到改变后的数据,要用对象接收。
串行流stream:串行处理数据,不产生异步线程。
并行流parallelStream:parallelStream提供了流的并行处理,它是Stream的另一重要特性,其底层使用Fork/Join框架实现。简单理解就是多线程异步任务的一种实现。
建议:数据量不大的情况下建议使用stream即可,不要盲目大量使用parallelStream,因为parallelStream是多线程异步的,也就是说会产生多线程,消耗内存不说,说不定还会更慢,并非一定会更快更好。
2 常用方法介绍
2.1 groupingBy方法
主要是转化数据为Map,value是符合条件的集合
List<Admin> adminList = adminMapper.selectList(null);
Map<Long, List<Admin>> adminMap = adminList.stream().collect(Collectors.groupingBy(Admin::getId));
2.2 toMap方法
主要是转化数据为Map,value是该条记录或字段值
List<Admin> adminList = adminMapper.selectList(null);
Map<Long, String> adminMap = adminList.stream().collect(Collectors.toMap(Admin::getId, Admin::getRealName, (key1, key2) -> key1));
2.3 filter方法
主要是用来筛选数据的
List<Admin> adminList = adminMapper.selectList(null);
adminList = adminList.stream().filter(admin -> admin.getAdminState() != null).collect(Collectors.toList());
2.4 anyMatch方法
用于判断数据,只要有一个条件满足即返回true
List<Admin> adminList = adminMapper.selectList(null);
boolean isAdmin = adminList.stream().anyMatch(admin -> admin.getAdminState() != null);
2.5 allMatch方法
用于判断数据,必须全部都满足才会返回true
List<Admin> adminList = adminMapper.selectList(null);
boolean isAdmin = adminList.stream().allMatch(admin -> admin.getAdminState() != null);
2.6 noneMatch方法
用于判断数据,全都不满足才会返回true
List<Admin> adminList = adminMapper.selectList(null);
boolean isAdmin = adminList.stream().noneMatch(admin -> admin.getAdminState() != null);
2.7 map方法
一般用于获取属性值
List<Admin> adminList = adminMapper.selectList(null);
List<Long> adminIdList = adminList.stream().map(Admin::getId).collect(Collectors.toList());
2.8 peek方法
一般用于改变数据,但是官方不建议使用
List<Admin> adminList = adminMapper.selectList(null);
adminList = adminList.stream().peek(admin -> admin.setAdminState(null)).collect(Collectors.toList());
3 使用parallelStream注意事项
1.parallelStream是线程不安全的。
2.parallelStream适用的场景是CPU密集型的,只是做到别浪费CPU,假如本身电脑CPU的负载很大,那还到处用并行流,那并不能起到作用。I/O密集型 磁盘I/O、网络I/O都属于I/O操作,这部分操作是较少消耗CPU资源,一般并行流中不适用于I/O密集型的操作,就比如使用并流行进行大批量的消息推送,涉及到了大量I/O,使用并行流反而慢了很多。
3.在使用并行流的时候是无法保证元素的顺序的,也就是即使你用了同步集合也只能保证元素都正确但无法保证其中的顺序。
4 实战比较
4.1 代码如下
/**
* parallelStream()和stream()执行速度测试
*/
@Test
public void test6() {
List<Integer> a = new ArrayList<>();
for (int i = 0 ; i < 1000 ; i++) {
a.add(i);
}
long b = System.currentTimeMillis();
a.parallelStream().forEach(obj->{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
log.error("出错:", e);
}
System.out.println(obj);
});
long c = System.currentTimeMillis();
long d = System.currentTimeMillis();
a.stream().forEach(obj->{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
log.error("出错:", e);
}
System.out.println(obj);
});
long e = System.currentTimeMillis();
System.out.println("并行耗时:" + (c-b));
System.out.println("串行耗时:" + (e-d));
}
4.2 执行结果
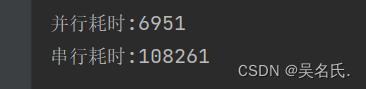
5 结论
由上述执行结果可知,parallelStream在同时执行一些耗时的方法时,执行时间要优于stream,但是使用时需要注意一些注意事项