全文链接:https://tecdat.cn/?p=33550
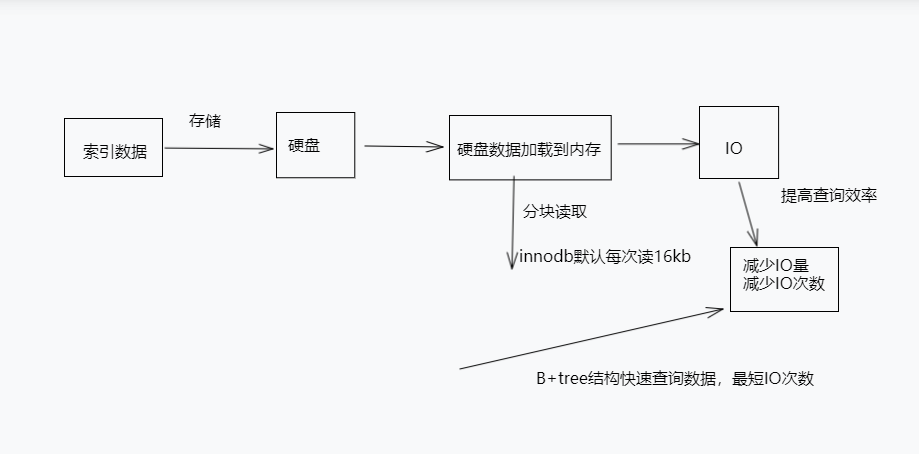
时间序列是一系列按时间顺序排列的观测数据。数据序列可以是等间隔的,具有特定频率,也可以是不规则间隔的,比如电话通话记录(点击文末“阅读原文”获取完整代码数据)。
相关视频
什么是时间序列?
在进行投资和交易研究时,对于时间序列数据及其操作要有专业的理解。本文将重点介绍如何使用Python和Pandas帮助客户进行时间序列分析来分析股票数据。
理解日期时间和时间差
在我们完全理解Python中的时间序列分析之前,了解瞬时、持续时间和时间段的差异非常重要。
| 类型 | 描述 | 例子 |
|---|---|---|
| 日期(瞬时) | 一年中的某一天 | 2019年9月30日,2019年9月30日 |
| 时间(瞬时) | 时间上的单个点 | 6小时,6.5分钟,6.09秒,6毫秒 |
| 日期时间(瞬时) | 日期和时间的组合 | 2019年9月30日06:00:00,2019年9月30日上午6:00 |
| 持续时间 | 两个瞬时之间的差异 | 2天,4小时,10秒 |
| 时间段 | 时间的分组 | 2019第3季度,一月 |
Python的Datetime模块
datetime模块提供了在简单和复杂方式下进行日期和时间操作的类。
创建瞬时
日期、日期时间和时间都是单独的类,我们可以通过多种方式创建它们,包括直接创建和通过字符串解析。
now = datetime.datetime.today()
today = datetime.date.today()
print(now)
print(today)创建持续时间
timedeltas 表示时间的持续时间。它们可以与时间点相加或相减。
python
past = now - alldelta
print(type(future))
print(future)
print(type(past))
print(past)访问日期时间属性
类和对象属性可以帮助我们分离出我们想要看到的信息。我列出了最常见的属性,但你可以在datetime模块的文档上找到详尽的列表。
| 类/对象 | 属性 | 描述 |
|---|---|---|
| 共享类属性 | class.min | 可表示的最早日期、datetime、time |
| class.max | 可表示的最晚日期、datetime、time | |
| class.resolution | 两个日期、datetimes 或 times 之间的最小差值 | |
| 日期/日期时间 | object.year | 返回年份 |
| object.month | 返回月份(1 - 12) | |
| object.day | 返回日期(1-32) | |
| 时间/日期时间 | object.hour | 返回小时(0-23) |
| object.minute | 返回分钟(0-59) | |
| object.second | 返回秒数(0-59) |
python
print(datetime.datetime.min)
print(datetime.datetime.max)
print(datetime1.microsecond)在Pandas中创建时间序列
让我们获取由Intrinio开发者沙盒提供的苹果股票历史数据。
python
apple_price_history = pd.read_csv(f)
apple_price_history[['open', 'high', 'low', 'close', 'volume']].head()
让我们查看数据框的数据类型或 dtypes,看看是否有任何日期时间信息。
让我们将数据框的 RangeIndex 更改为 DatetimeIndex。为了好看,我们将展示如何使用 read_csv 用 DatetimeIndex 读取数据。
python
apptime64)
apple_price_history.dtypes
python
print(apple_price_history[['open', 'high', 'low', 'close']].head())
apple_price_history.index[0:10]
python
import numpy as np
import urllib.request
index_col='date',
usecols=['date',
'adj_open',
'adj_high',
'adj_low',
'adj_close',
'adj_volume'])
apple_price_history.columns = names
print(apple_price_history.head())
添加日期时间字符串
通常,日期的格式可能是无法解析的。我们可以使用dt.strftime将字符串转换为日期。在创建 sp500数据集 时,我们使用了strptime。
sp500.loc[:,'date'].apply(lambda x: datetime.strptime(x,'%Y-%m-%d'))
时间序列选择
按日、月或年选择日期时间
现在我们可以使用索引和loc轻松选择和切片日期。
apple_price_history.loc['2018-6-1']
使用日期时间访问器
dt访问器具有多个日期时间属性和方法,可以应用于系列的日期时间元素上,这些元素在Series API文档中可以找到。
| 属性 | 描述 |
|---|---|
| Series.dt.date | 返回包含Python datetime.date对象的numpy数组(即,没有时区信息的时间戳的日期部分)。 |
| Series.dt.time | 返回datetime.time的numpy数组。 |
| Series.dt.timetz | 返回还包含时区信息的datetime.time的numpy数组。 |
| Series.dt.year | 日期的年份。 |
| Series.dt.month | 月份,其中一月为1,十二月为12。 |
| Series.dt.day | 日期的天数。 |
| Series.dt.hour | 时间的小时。 |
| Series.dt.minute | 时间的分钟。 |
| Series.dt.second | 时间的秒数。 |
| Series.dt.microsecond | 时间的微秒数。 |
| Series.dt.nanosecond | 时间的纳秒数。 |
| Series.dt.week | 年的星期序数。 |
| Series.dt.weekofyear | 年的星期序数。 |
| Series.dt.dayofweek | 星期几,星期一为0,星期日为6。 |
| Series.dt.weekday | 星期几,星期一为0,星期日为6。 |
| Series.dt.dayofyear | 年的第几天的序数。 |
| Series.dt.quarter | 季度。 |
| Series.dt.is_month_start | 表示日期是否为月的第一天。 |
| Series.dt.is_month_end | 表示日期是否为月的最后一天。 |
| Series.dt.is_quarter_start | 表示日期是否为季度的第一天。 |
| Series.dt.is_quarter_end | 表示日期是否为季度的最后一天。 |
| Series.dt.is_year_start | 表示日期是否为年的第一天。 |
| Series.dt.is_year_end | 表示日期是否为年的最后一天。 |
| Series.dt.is_leap_year | 表示日期是否为闰年。 |
| Series.dt.daysinmonth | 月份中的天数。 |
| Series.dt.days_in_month | 月份中的天数。 |
| Series.dt.tz | 返回时区(如果有)。 |
| Series.dt.freq |
| 方法 | 描述 |
|---|---|
| Series.dt.to_period(self, *args, **kwargs) | 将数据转换为特定频率的PeriodArray/Index。 |
| Series.dt.to_pydatetime(self) | 将数据返回为本机Python datetime对象的数组。 |
| Series.dt.tz_localize(self, *args, **kwargs) | 将时区非感知的Datetime Array/Index本地化为时区感知的Datetime Array/Index。 |
| Series.dt.tz_convert(self, *args, **kwargs) | 将时区感知的Datetime Array/Index从一个时区转换为另一个时区。 |
| Series.dt.normalize(self, *args, **kwargs) | 将时间转换为午夜。 |
| Series.dt.strftime(self, *args, **kwargs) | 使用指定的日期格式转换为索引。 |
| Series.dt.round(self, *args, **kwargs) | 对数据执行舍入操作,将其舍入到指定的频率。 |
| Series.dt.floor(self, *args, **kwargs) | 对数据执行floor操作,将其舍入到指定的频率。 |
| Series.dt.ceil(self, *args, **kwargs) | 对数据执行ceil操作,将其舍入到指定的频率。 |
| Series.dt.month_name(self, *args, **kwargs) | 返回具有指定区域设置的DateTimeIndex的月份名称。 |
| Series.dt.day_name(self, *args, **kwargs) | 返回具有指定区域设置的DateTimeIndex的星期几名称。 |
周期
print(df.dt.quarter)
print(df.dt.day_name())
DatetimeIndex包括与dt访问器大部分相同的属性和方法。
apple_price_history.index.day_name()
频率选择
当时间序列是均匀间隔的时,可以在Pandas中与频率关联起来。
pandas.date_range 是一个函数,我们可以创建一系列均匀间隔的日期。
dates = pd.date_range('2019-01-01', '2019-12-31', freq='D')
dates
除了指定开始或结束日期外,我们可以用一个周期来替代,并调整频率。
hours = pd.date_range('2019-01-01', periods=24, freq='H')
print(hours)
pandas.DataFrame.asfreq 返回具有新频率的数据帧或序列。对于数据中缺失的时刻,将添加新行并用NaN填充,或者使用我们指定的方法填充。通常需要提供偏移别名以获得所需的时间频率。
别名
| 别名 | 描述 |
|---|---|
| B | 工作日频率 |
| C | 定制的工作日频率 |
| D | 日历日频率 |
| W | 周频率 |
| M | 月底频率 |
| SM | 半月末频率(每月15日和月末) |
| BM | 工作日月末频率 |
| CBM | 定制的工作日月末频率 |
| MS | 月初频率 |
| SMS | 半月初频率(每月1日和15日) |
| BMS | 工作日月初频率 |
| CBMS | 定制的工作日月初频率 |
| Q | 季末频率 |
| BQ | 工作日季末频率 |
| QS | 季初频率 |
| BQS | 工作日季初频率 |
| A, Y | 年末频率 |
| BA, BY | 工作日年末频率 |
| AS, YS | 年初频率 |
| BAS, BYS | 工作日年初频率 |
| BH | 工作小时频率 |
| H | 小时频率 |
| T, min | 分钟频率 |
| S | 秒频率 |
| L, ms | 毫秒 |
| U, us | 微秒 |
| N | 纳秒 |
print(apple_quarterly_history.head())
填充数据
pandas.Series.asfreq 为我们提供一个填充方法来替换NaN值。
print(apple_price_history['close'].asfreq('H', method='ffill').head())
重新采样:上采样和下采样
pandas.Dataframe.resample 返回一个重新取样对象,与groupby对象非常相似,可以在其上运行各种计算。
我们经常需要降低(下采样)或增加(上采样)时间序列数据的频率。如果我们有每日或每月的销售数据,将其降采样为季度数据可能是有用的。或者,我们可能希望上采样我们的数据以匹配另一个用于进行预测的系列的频率。上采样较少见,并且需要插值。
print(apple_quarterly_history.agg({'high':'max', 'low':'min'})[:5])
现在我们可以使用我们上面发现的所有属性和方法。
print(apple_price_history.index.day_name())Index(['Friday', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday',
'Monday', 'Tuesday', 'Wednesday', 'Friday',
...
'Wednesday', 'Thursday', 'Friday', 'Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday', 'Monday', 'Tuesday'],
dtype='object', name='date', length=9789)print(datetime.to_period('Q'))
datetime.to_period('Q').end_time
滚动窗口平滑和移动平均
pandas.DataFrame.rolling 让我们将数据拆分为聚合的窗口,并应用诸如均值或总和之类的函数。
在交易中的一个典型例子是使用50天和200天的移动平均线来买入和卖出资产。
让我们计算苹果公司的这些指标。请注意,在计算滚动均值之前,我们需要有50天的数据。
apple_price_history_recent[['close', 'rolling_50', 'rolling_200']].plot(title='Apple vs. 50SMA & 200SMA', figsize=(32,18))
点击标题查阅往期内容
对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
左右滑动查看更多
01
02
03
04
使用Matplotlib可视化时间序列数据
Matplotlib使我们可以轻松地可视化Pandas时间序列数据。Seaborn添加了额外的选项,帮助我们使图表更加漂亮。我们导入matplotlib和seaborn来尝试几个基本的例子。
折线图
sns.lineplot 绘制标准折线图。它的工作方式类似于我们上面使用的dataframe.plot。
ax=ax).set_title("Apple Stock Price History")Text(0.5, 1.0, 'Apple Stock Price History')
箱线图/盒图
盒图能够帮助我们对数据进行分组和理解其分布。对于季节性数据来说往往非常有用。
python
sns.set(rc={'figure.figsize':(32, 18)})
sns.boxplot(data=apple_price_recent_history, x='quarter', y='close').s
在 Pandas 中分析时间序列数据
时间序列分析方法可以分为两类:
频域方法
时域方法
频域方法分析信号在频率带(如最后100个样本)上的变化程度。时域方法分析信号在指定时间段(如前100秒)内的变化程度。
时间序列趋势、季节性和周期性
时间序列数据可以分解为四个组成部分:
趋势
季节性
周期性
噪声
并不是所有的时间序列都具有趋势、季节性或周期性;而且必须有足够的数据支持存在季节性、周期性或趋势。
并不是所有的时间序列必须呈现趋势或模式,它们也可能完全是随机的。
除了高频变动(如季节性和噪声)外,时间序列数据通常还会呈现渐变的变异性。通过在不同时间尺度上进行滚动平均可以很容易地可视化这些趋势。让我们导入苹果公司的销售数据以研究季节性和趋势。
趋势
趋势指的是时间序列中存在上升或下降斜率的情况。亚马逊的销售增长就是上升趋势的一个例子。此外,趋势不一定是线性的。趋势可以是确定性的,是时间的函数,也可以是随机的。
季节性
季节性指的是一年内在固定时间间隔内观察到的明显重复模式,包括峰值和低谷。苹果公司的销售在第四季度达到峰值就是亚马逊收入中的一个季节性模式的例子。
周期性
周期性指的是在不规则时间间隔内观察到的明显重复模式,如商业周期。
让我们分析苹果公司的收入历史数据,看看能否进行分解。
import urllib
import pandas as pd
from scipy import stats
+ apple_revenue_history['fiscal_period'].str.upper()
slope, intercept, r_value, p_value, std_err = stats.linregress(apple_revenue_history.index,时间序列趋势图与趋势线
python
fig = plt.figure(figsize=(32,18))
ax1 = fig.add_subplot(1,1,1)
apple_revenue_history.plot(
时间序列堆叠图进行周期分析
python
fig = plt.figure(figsize=(32,18))
ax1 = fig.add_subplot(1,1,1)
lsharey=True)
ax1.legend(legend)
分解时间序列数据
statsmodel可以将时间序列统计分解为其组成部分。
python
apple_revenue_history.index = apple_revenue_history.index.to_timestamp(freq='Q')
# 加法分解
result_add = seasonal_decompose(apple_revenue_history['value'])
# 绘图
plt.rcParams.update({'figure.figsize': (32,18)})
时间序列的平稳性
时间序列与传统的分类和回归预测建模问题不同。时间序列数据是有序的,并且需要平稳性才能进行有意义的摘要统计。
平稳性是时间序列分析中许多统计过程的假设,非平稳数据经常被转化为平稳数据。
平稳性有以下几种分类:
平稳过程/模型:平稳的观察序列。
趋势平稳:不呈现趋势。
季节平稳:不呈现季节性。
严格平稳:数学定义的平稳过程。
在一个平稳的时间序列中,时间序列的均值和标准差是恒定的。此外,没有季节性、周期性或其他与时间相关的结构。通常首先查看时间序列是否平稳,以更容易理解。
python
# 平稳序列
vol = .002
df1.plot(title=
python
df2.plot(t
python
np.logspace(1,2,num=200, dtype=int))
df3.plot(title')
python
df4[0] = df4[0] + df4['cyclical']
df4[0].plot(title=')
如何检验平稳性
我们可以通过直观地检查上述图形来测试平稳性,就像之前所做的那样;将图形分成多个部分,查看均值、方差和相关性等摘要统计数据;或者使用更高级的方法,如增广迪基-富勒检验(Augmented Dickey-Fuller test)。
增广迪基-富勒测试用于测试是否存在单位根。如果时间序列有单位根,则表示存在一些时间相关结构,即时间序列不是平稳的。
统计量越负值,时间序列越有可能是平稳的。一般来说,如果 p 值 > 0.05,则数据有单位根,不是平稳的。让我们使用 statsmodel 进行检验。
python
import pandas as pd
import numpy as np
from statsmodels.tsa.stattools import adfuller
print('Critial Values:')
print(f' {key}, {value:.2f}')
上述示例运行后打印出的测试统计值分别为 0.00(平稳)和 0.88(非平稳)。
如何处理非平稳时间序列
如果时间序列中存在明显的趋势和季节性,可以对这些组成部分进行建模,将它们从观测值中剔除,然后在残差上训练模型。
去趋势化
有多种方法可以从时间序列中去除趋势成分。
减去最佳拟合直线
使用分解进行减法
使用滤波器进行减法
滤波器
使用 SciPy 进行最佳拟合直线
SciPy 的 detrend 函数可以通过减去最佳拟合直线来移除趋势。
python
detrend = signal.detrend(df[0].values)
plt.plot(detrend)
使用 StatsModels 进行分解
seasonal_decompose 函数返回一个带有季节性、趋势和残差属性的对象,我们可以从系列值中减去它们。
from statsmodels.tsa.seasonal import seasonal_decompose
from dateutil.parser import parse
df[0].plot(figsize=(32,18))
df[0] = df[0] - decompose.trend
df[0].plot(figsize=(32,18))
点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python时间序列分析苹果股票数据:分解、平稳性检验、滤波器、滚动窗口、移动平均、可视化》。
点击标题查阅往期内容
R语言ARIMA-GARCH波动率模型预测股票市场苹果公司日收益率时间序列
R语言风险价值:ARIMA,GARCH,Delta-normal法滚动估计VaR(Value at Risk)和回测分析股票数据
R语言GARCH模型对股市sp500收益率bootstrap、滚动估计预测VaR、拟合诊断和蒙特卡罗模拟可视化
R语言单变量和多变量(多元)动态条件相关系数DCC-GARCH模型分析股票收益率金融时间序列数据波动率
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
GARCH-DCC模型和DCC(MVT)建模估计
R语言预测期货波动率的实现:ARCH与HAR-RV与GARCH,ARFIMA模型比较
ARIMA、GARCH 和 VAR模型估计、预测ts 和 xts格式时间序列
PYTHON用GARCH、离散随机波动率模型DSV模拟估计股票收益时间序列与蒙特卡洛可视化
极值理论 EVT、POT超阈值、GARCH 模型分析股票指数VaR、条件CVaR:多元化投资组合预测风险测度分析
Garch波动率预测的区制转移交易策略
金融时间序列模型ARIMA 和GARCH 在股票市场预测应用
时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
R语言风险价值:ARIMA,GARCH,Delta-normal法滚动估计VaR(Value at Risk)和回测分析股票数据
R语言GARCH建模常用软件包比较、拟合标准普尔SP 500指数波动率时间序列和预测可视化
Python金融时间序列模型ARIMA 和GARCH 在股票市场预测应用
MATLAB用GARCH模型对股票市场收益率时间序列波动的拟合与预测
R语言极值理论 EVT、POT超阈值、GARCH 模型分析股票指数VaR、条件CVaR:多元化投资组合预测风险测度分析
Python 用ARIMA、GARCH模型预测分析股票市场收益率时间序列
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
R语言ARIMA-GARCH波动率模型预测股票市场苹果公司日收益率时间序列
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
R语言时间序列GARCH模型分析股市波动率
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
matlab实现MCMC的马尔可夫转换ARMA - GARCH模型估计
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
使用R语言对S&P500股票指数进行ARIMA + GARCH交易策略
R语言用多元ARMA,GARCH ,EWMA, ETS,随机波动率SV模型对金融时间序列数据建模
R语言股票市场指数:ARMA-GARCH模型和对数收益率数据探索性分析
R语言多元Copula GARCH 模型时间序列预测
R语言使用多元AR-GARCH模型衡量市场风险
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
R语言用Garch模型和回归模型对股票价格分析
GARCH(1,1),MA以及历史模拟法的VaR比较
matlab估计arma garch 条件均值和方差模型
![]()