文件描述符fd
0&1&2
Linux 进程默认情况会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2. 0,1,2对应的物理设备一般是:键盘,显示器,显示器 所以输入输出还可以采用如下方式
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
char buf[1024];
ssize_t s = read(0, buf, sizeof(buf));
if (s > 0)
{
buf[s] = 0;
write(1, buf, strlen(buf));
write(2, buf, strlen(buf));
}
return 0;
}
文件描述符就是从
0
开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file
结构体。表示一个已经打开的文件对象。而进程执行
open
系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files,
指向一张表
files_struct,
该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
文件描述符的分配规则
我们通过一段代码来比较直接的观察
演示代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if (fd < 0)
{
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}运行结果:

因为0,1,2文件描述符都已经被占用了,直接从3开始好像挺好理解的。我们猜测文件描述符是从没有被占用的数字从小到大分配的,所以是不是呢?我们通过下面这段代码来验证一下
演示代码
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd1 = open("log1.txt", O_WRONLY | O_CREAT);
int fd2 = open("log2.txt", O_WRONLY | O_CREAT);
int fd3 = open("log3.txt", O_WRONLY | O_CREAT);
if (fd1 < 0 || fd2 < 0 || fd3 < 0)
{
perror("open");
return 1;
}
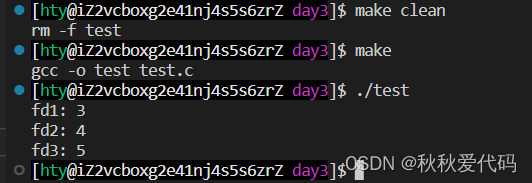
printf("fd1: %d\n", fd1);
printf("fd2: %d\n", fd2);
printf("fd3: %d\n", fd3);
close(fd1);
close(fd2);
close(fd3);
return 0;
}
运行结果
那如果我们先关掉 0,2呢(1是标准输出,为了方便观察结果,就不关闭它啦)
来看下代码
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
close(2);
int fd1 = open("log1.txt", O_WRONLY | O_CREAT);
int fd2 = open("log2.txt", O_WRONLY | O_CREAT);
int fd3 = open("log3.txt", O_WRONLY | O_CREAT);
if (fd1 < 0 || fd2 < 0 || fd3 < 0)
{
perror("open");
return 1;
}
printf("fd1: %d\n", fd1);
printf("fd2: %d\n", fd2);
printf("fd3: %d\n", fd3);
close(fd1);
close(fd2);
close(fd3);
return 0;
}运行结果
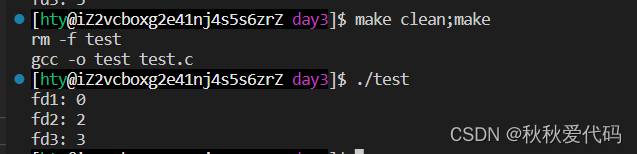
结论:文件描述符是按照未分配的数字从小到大分配的。
重定向
那如果关闭1呢?
演示代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
if (fd < 0)
{
perror("open");
return 1;
}
printf("fd: %d\n", fd);
printf("hello dear programmer");
fflush(stdout);//刷新缓冲区⭐
close(fd);
exit(0);
}
运行结果:
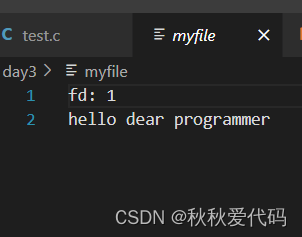
显示器上什么页没有输出,但当我们打开文件myfile发现,原本要输入到显示器的内容全部输入到文件中了,这就叫重定向。
通过这张图片,我们来了解一下重定向的本质
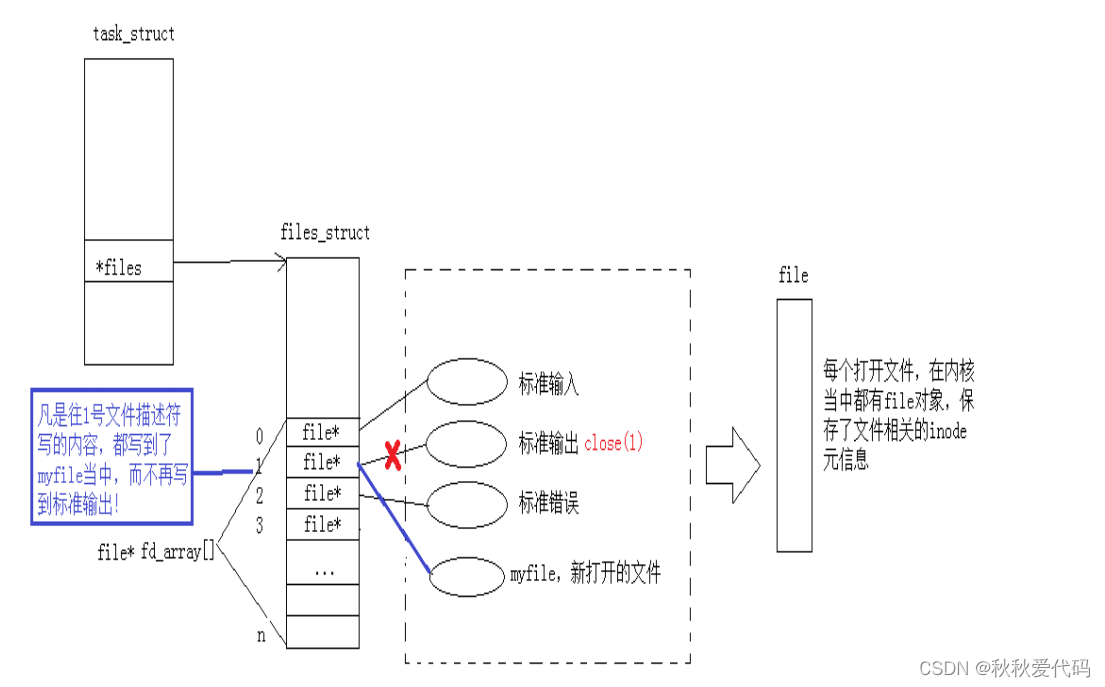 dup2系统调用
dup2系统调用
man dup2
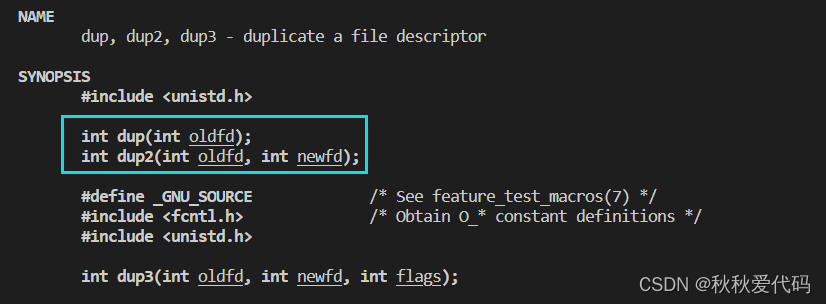
使用示例:
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
int fd = open("./log", O_CREAT | O_RDWR);
if (fd < 0)
{
perror("open");
return 1;
}
close(1);
dup2(fd, 1);
for (;;)
{
char buf[1024] = {0};
ssize_t read_size = read(0, buf, sizeof(buf) - 1);
if (read_size < 0)
{
perror("read");
break;
}
printf("%s", buf);
fflush(stdout);
}
return 0;
}运行结果:
 FILE
FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。 所以C库当中的FILE必定封装了fd。
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg0 = "hello printf\n";
const char *msg1 = "hello fwrite\n";
const char *msg2 = "hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}运行结果:
 但如果对进程实现输出重定向呢?执行 ./test > file 后,结果变成了
但如果对进程实现输出重定向呢?执行 ./test > file 后,结果变成了
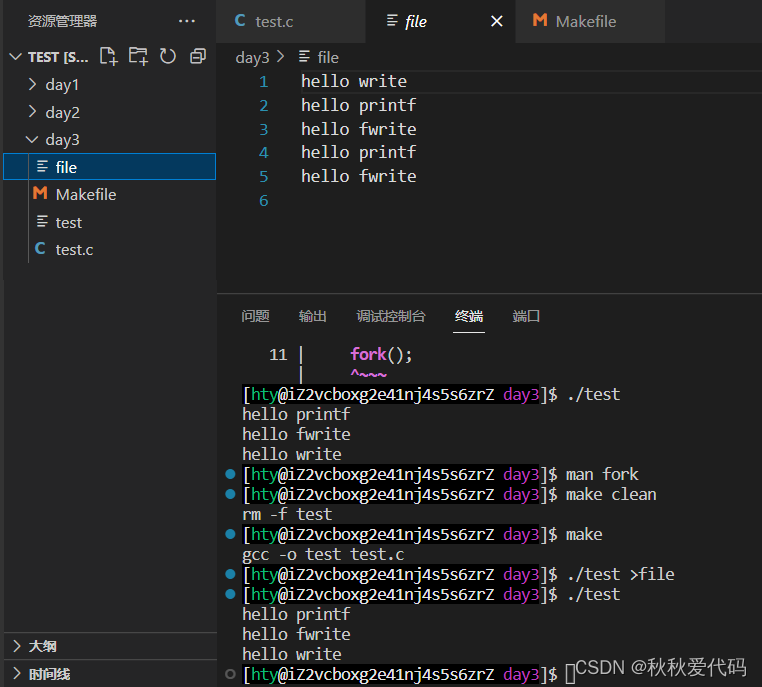
我们发现
printf
和
fwrite
(库函数)都输出了
2
次,而 write 只输出了一次(系统调用)。为什么呢?这里我们猜测可能和fork有关,通过屏蔽fork,我们发现结果是
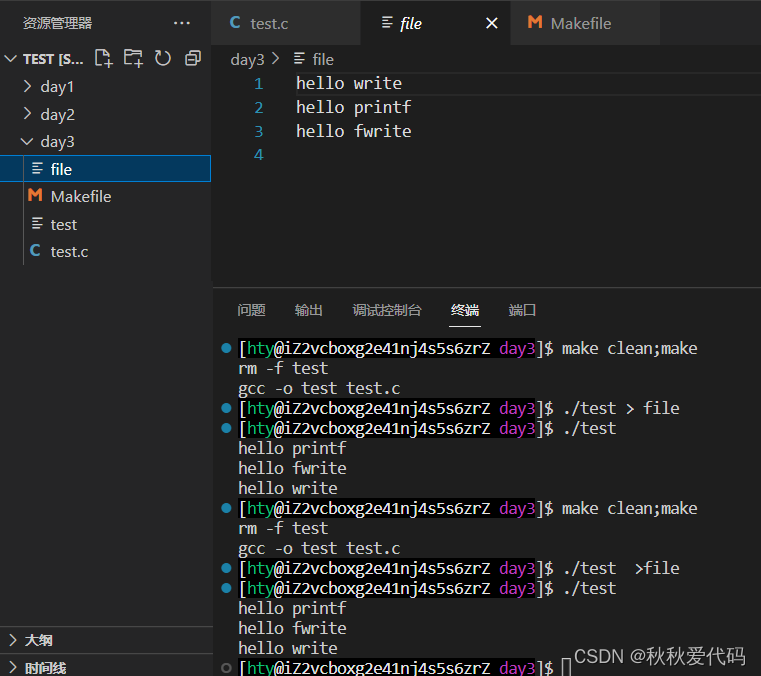
(1)一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
(2)printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据
的缓冲方式由行缓冲变成了全缓冲。
(3)我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
(4)但是进程退出之后,会统一刷新,写入文件当中。
(5)但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的
一份数据,随即产生两份数据。
(6)write 没有变化,说明没有所谓的行缓冲
综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不在我们讨论范围之内。那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
理解文件系统
我们使用
ls -l
的时候看到的除了看到文件名,还看到了文件元数据。
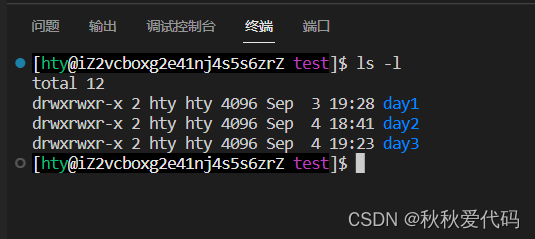
每行包含
7
列:
模式,硬链接数,文件所有者 ,组,大小文件名,最后修改时间
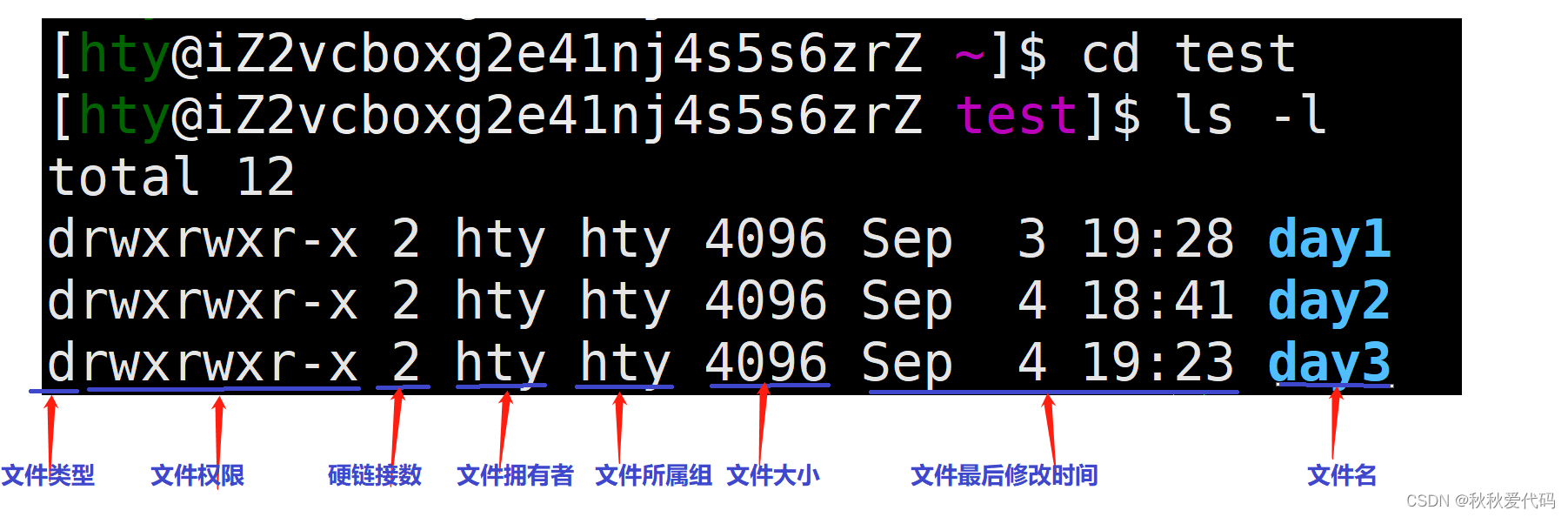
ls -l
读取存储在磁盘上的文件信息,然后显示出来
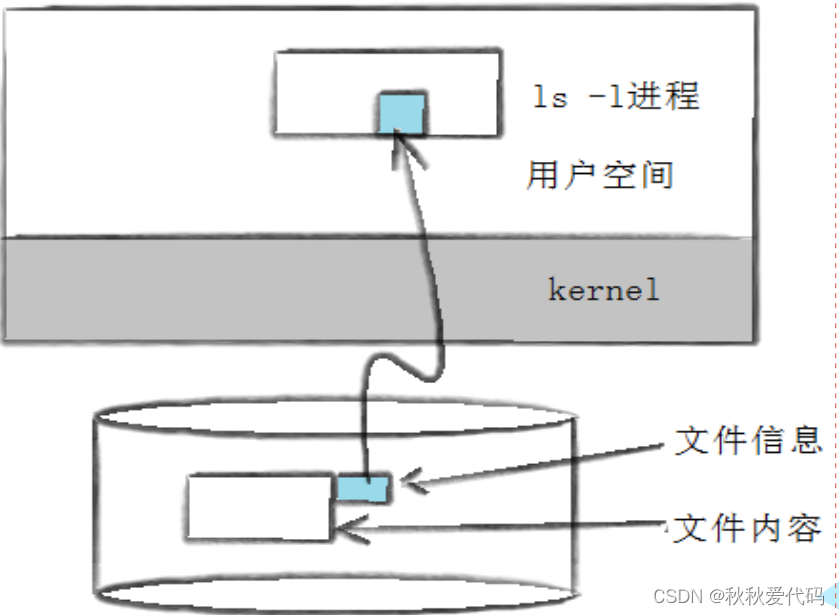
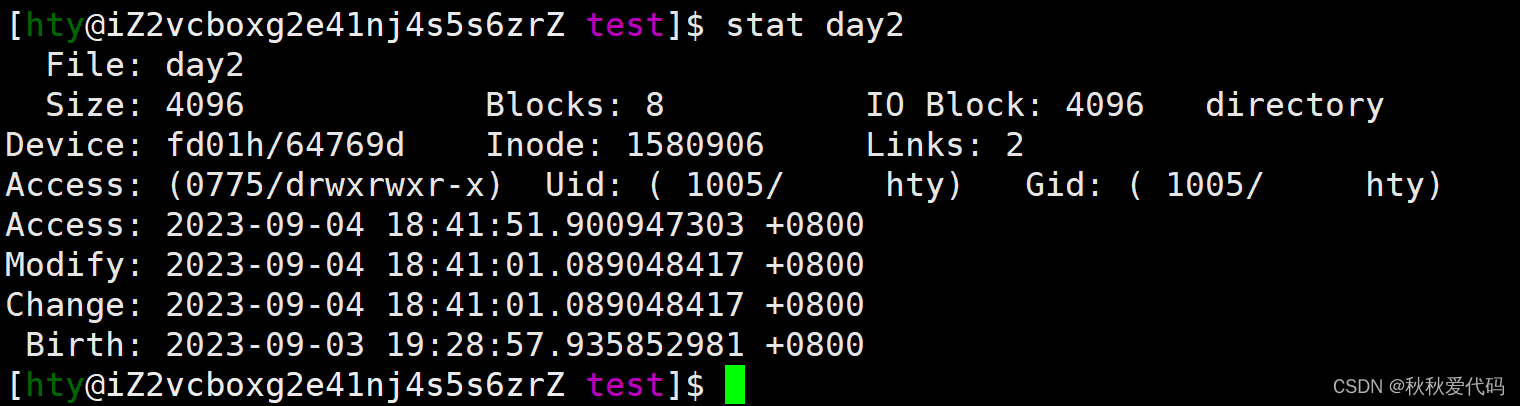
另外 stat命令也可以查看文件信息
文件系统
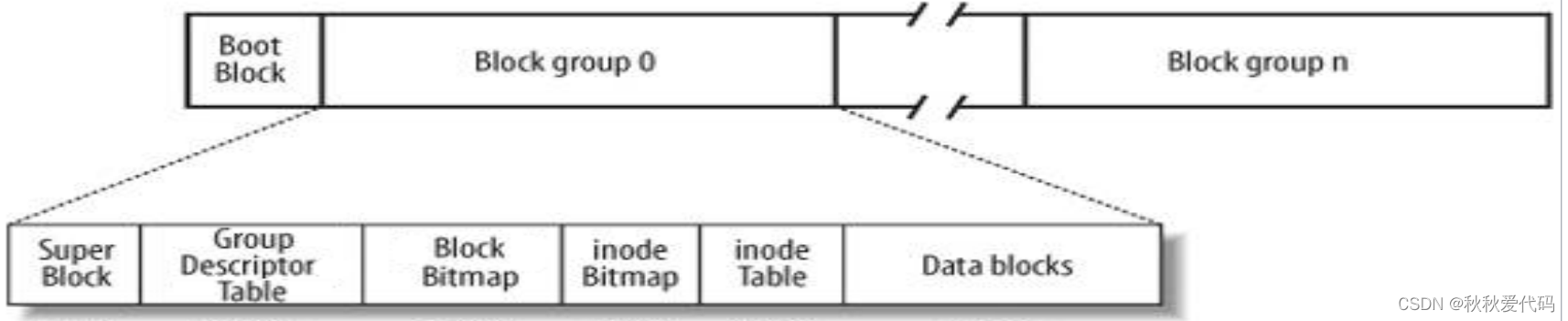
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如
mke2fs
的
-b
选项可以设定block大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了GDT,Group Descriptor Table:块组描述符,描述块组属性信息块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。i节点表:存放文件属性如文件大小,所有者,最近修改时间等数据区:存放文件内容
将属性和数据分开存放的想法看起来很简单,但实际上是如何工作的呢?我们通过touch一个新文件来看看如何工作。
[hty@iZ2vcboxg2e41nj4s5s6zrZ test]$ cd day3
[hty@iZ2vcboxg2e41nj4s5s6zrZ day3]$ touch file
[hty@iZ2vcboxg2e41nj4s5s6zrZ day3]$ ls -i file
1581596 file
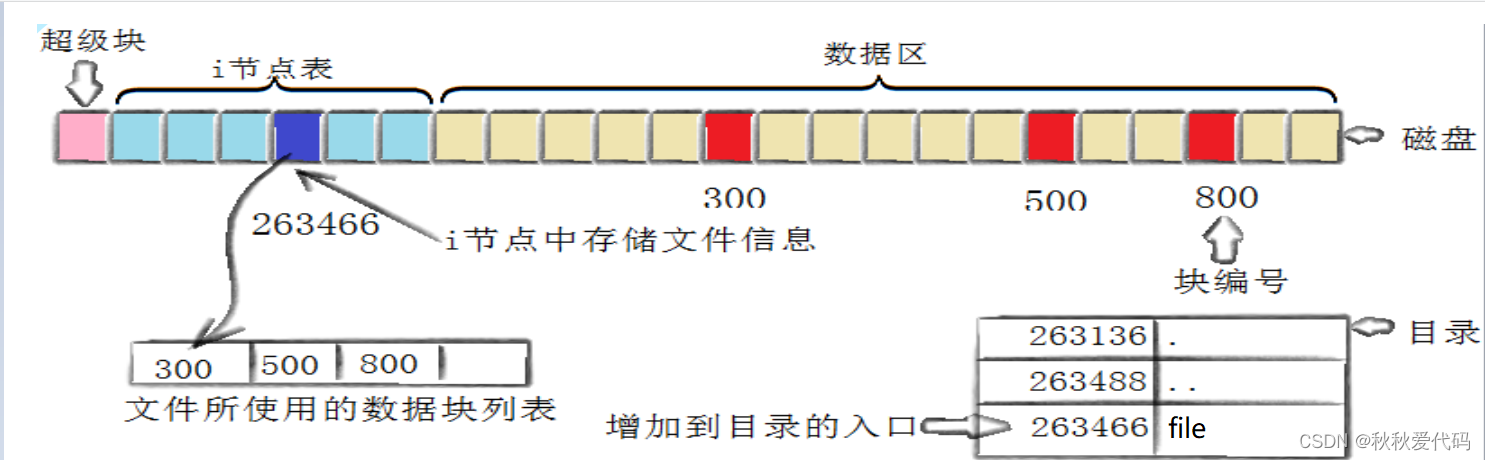
创建一个新文件主要有一下4个操作:
1. 存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。
2. 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块数据
复制到300,下一块复制到500,以此类推。
3. 记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
4. 添加文件名到目录
新的文件名abc。linux如何在当前的目录中记录这个文件,内核将入口(263466,file)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
下面解释一下文件的三个时间:
Access 最后访问时间
Modify 文件内容最后修改时间
Change 属性最后修改时间







![【java】【项目实战】[外卖十]项目优化(mysql读写分离)](https://img-blog.csdnimg.cn/3b036809c84444ddae411952e75380e5.png)