83. 删除排序链表中的重复元素(简单)


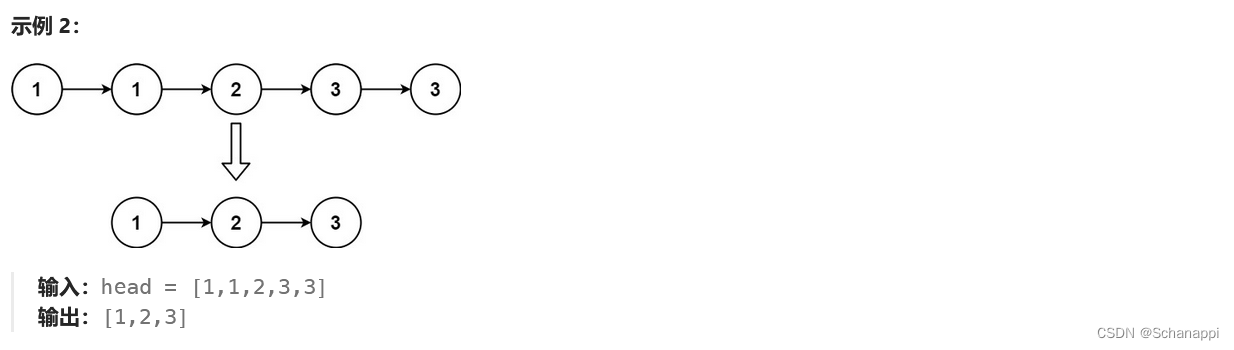

方法:一次遍历
思路
-
由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。
-
从指针 cur 指向链表的头节点,随后开始对链表进行遍历。如果当前 cur 与 cur.next 对应的元素相同,那么我们就将 cur.next 从链表中移除;否则说明链表中已经不存在其它与 cur 对应的元素相同的节点,因此可以将 cur 指向 cur.next 。
-
当遍历完整个链表之后,返回链表的头节点即可。
细节
- 当我们遍历到链表的最后一个节点时,cur.next 为空节点,如果不加以判断,访问 cur.next 对应的元素会产生运行错误。因此我们只需要遍历到链表的最后一个节点,而不需要遍历完整个链表。
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
ListNode *cur = head;
while(cur->next) {
if(cur -> val == cur -> next -> val) {
// 值重复 删除该节点
cur -> next = cur -> next -> next;
}
else{
cur = cur -> next;
}
}
return head;
}
};
参考资料
- 力扣官方题解