目录
1 为什么要引入高并发
2 ExecutorCompletionService分析
2.1 原理
2.2 api调用分析
3 实操
1 为什么要引入高并发
众所周知,程序中的代码是从下往下顺序执行的,当我们需要在一个方法中同时执行多个耗时的任务时所消耗时间就会大于等于这些任务消耗的累加时间。那么有没有一种办法可以让这些耗时的任务同时执行呢?这时候就需要并发编程,让这些任务在不同的线程上分别执行,达到理论上的同步执行效果。
2 ExecutorCompletionService分析
2.1 原理
ExecutorCompletionService实现了CompletionService接口。ExecutorCompletionService将Executor和BlockingQueue功能融合在一起,使用它可以提交我们的Callable任务。这个任务委托给Executor执行,可以使用ExecutorCompletionService对象的take和poll方法获取结果。
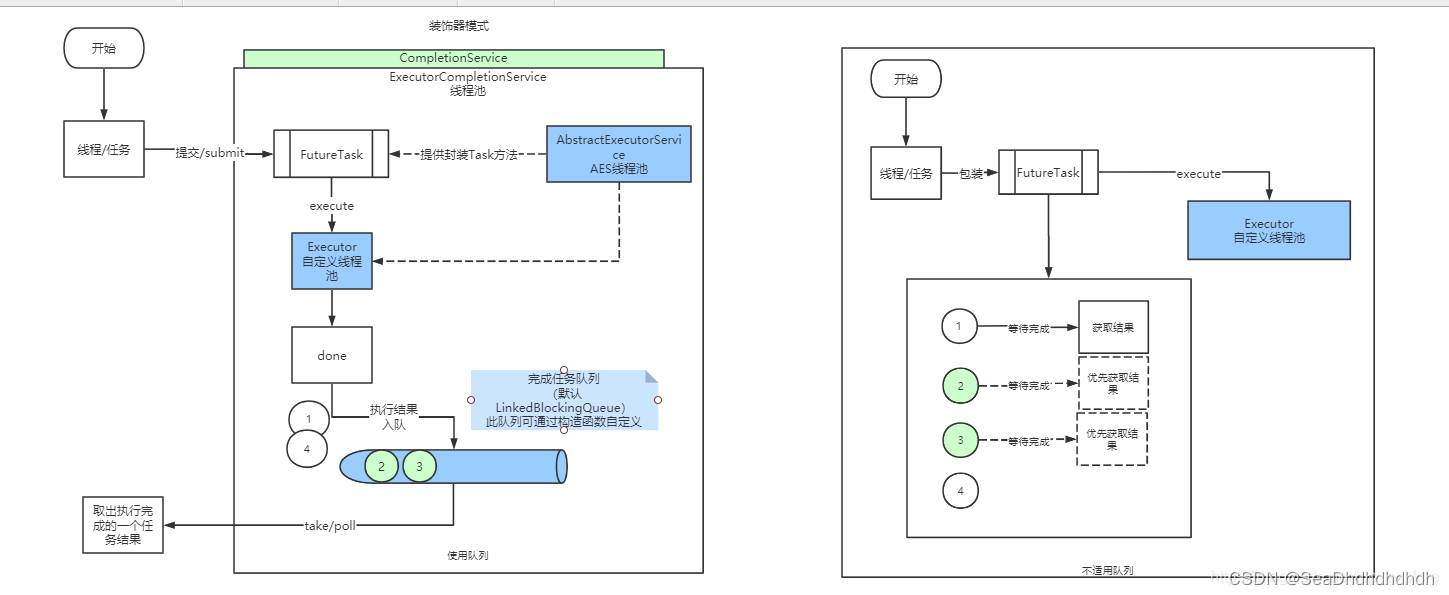
ExecutorCompletionService的设计目的在于提供一个可获取线程池执行结果的功能,这个类采用了装饰器模式,需要用户提供一个自定义的线程池,在ExecutorCompletionService内部持有该线程池进行线程执行,在原有的线程池功能基础上装饰额外的功能。
下面是ExecutorCompletionService的原理图:

在使用ExecutorCompletionService时需要提供一个自定义的线程池Executor,构造ExecutorCompletionService。同时,也可以指定一个自定义的队列作为线程执行结果的容器,当线程执行完成时,通过重写FutureTask#done()将结果压入队列中。
当用户把所有的任务都提交了以后,可通过ExecutorCompletionService#poll方法来弹出已完成的结果,这样做的好处是可以节省获取完成结果的时间。
下面是使用队列和不使用队列的流程对比,从图中我们可以看出,在使用队列的场景下,我们可以优先获取到完成的线程,当我们要汇总所有的执行结果时,这无疑会缩减我们的汇总时间。
而不使用队列时,我们需要对FutureTask进行遍历,因为我们不知道哪个线程先执行完了,只能挨个去获取结果,这样已经完成的线程会因为前面未完成的线程的耗时而无法提前进行汇总。
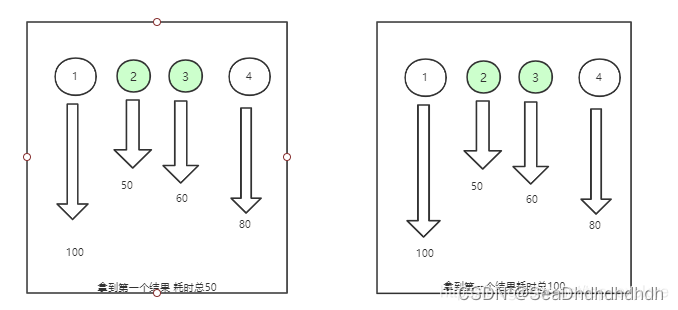
汇总结果的耗时时间 :

在使用队列的场景下,我们可以在其他任务线程执行的过程中汇总已完成的结果,节省汇总时间。不使用队列的场景下,只用等到当前的线程执行完成才能汇总。
2.2 api调用分析
ExecutorCompletionService实现了CompletionService接口,CompletionService的方法有以下:
- Future submit(Callable task):提交一个Callable类型任务,并返回该任务执行结果关联的Future;
- Future submit(Runnable task,V result):提交一个Runnable类型任务,并返回该任务执行结果关联的Future;
- Future take():从内部阻塞队列中获取并移除第一个执行完成的任务,阻塞,直到有任务完成;
- Future poll():从内部阻塞队列中获取并移除第一个执行完成的任务,获取不到则返回null,不阻塞;
- Future poll(long timeout, TimeUnit unit):从内部阻塞队列中获取并移除第一个执行完成的任务,阻塞时间为timeout,获取不到则返回null;
ExecutorCompletionService结构源码如下所示:
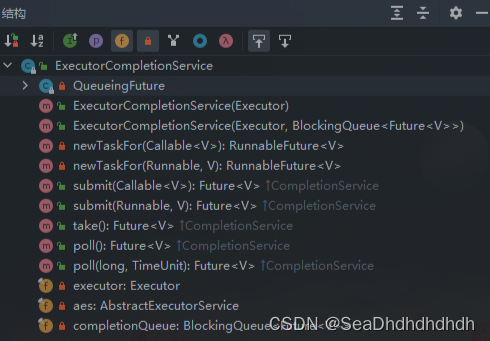
ExecutorCompletionService这两个构造方法,源码如下:
public ExecutorCompletionService(Executor executor) {
if (executor == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
this.completionQueue = new LinkedBlockingQueue<Future<V>>();
}
public ExecutorCompletionService(Executor executor,
BlockingQueue<Future<V>> completionQueue) {
if (executor == null || completionQueue == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
this.completionQueue = completionQueue;
}
也就是说新建ExecutorCompletionService实例对象的时候,可以自行指定阻塞队列的类型。
阻塞队列:在Java多线程编程中,阻塞队列是一种特殊的队列,它可以在队列为空时阻塞获取元素的线程,也可以在队列已满时阻塞插入元素的线程。这种队列通常用于实现生产者-消费者模式,其中生产者线程向队列中插入任务,消费者线程从队列中取出任务并执行。Java中提供了多种类型的阻塞队列,包括:
- ArrayBlockingQueue:基于数组实现的有界阻塞队列,按照先进先出的原则进行元素插入和移除。
- LinkedBlockingQueue:基于链表实现的可选有界阻塞队列,按照先进先出的原则进行元素插入和移除。
- PriorityBlockingQueue:基于优先级堆实现的无界阻塞队列,元素按照优先级顺序进行插入和移除。
- SynchronousQueue:一个不存储元素的阻塞队列,每个插入操作必须等待一个相应的删除操作,反之亦然。
- DelayQueue:一个基于优先级堆实现的延迟阻塞队列,其中的元素只有在其指定的延迟时间到达后才能被取出。
这些阻塞队列都是线程安全的,可以在多线程环境下使用。不同的阻塞队列适用于不同的场景,可以根据自己的需求选择合适的队列。如果新建实例对象时不指定阻塞队列类型,默认使用的是LinkedBlockingQueue。
3 实操
public class TestMain1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(5);
ExecutorCompletionService<Long> objectExecutorCompletionService = new ExecutorCompletionService<>(executor);
for (int i = 0; i < 5; i++) {
MyTask myTask = new MyTask();
objectExecutorCompletionService.submit(myTask);
}
for (int i = 0; i < 5; i++) {
Future<Long> future = objectExecutorCompletionService.poll(3,TimeUnit.MILLISECONDS);
Long result = future.get();
System.out.println("Result from Thread " + (i + 1) + ": " + result);
}
executor.shutdown();
}
}
public class MyTask implements Callable<Long> {
@Override
public Long call() throws Exception {
return Thread.currentThread().getId();
}
}
需要注意的问题
1、调用poll方法产生的空指针
调用限制时长的poll()方法时,需要合理的设定时间,否则会返回null,容易引发空指针问题
2、需要注意OOM
调用ExecutorCompletionService实例对象后,需要及时的进行take()或者poll()操作,否则执行的结果会不停的堆积在队列中,占用堆内存,最终导致oom
文章参考:初探高并发—ExecutorCompletionService_一条有梦想的咸鱼-的博客-CSDN博客