进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. with子句
1.1 定义变量
1.2 调用函数
1.3 定义子查询
1.4 在子查询中重复使用with
2. From子句
3. Sample子句
3.1 Sample factor
3.2 Sample rows
3.3 SAMPLE factor OFFSET n
4. Array Join子句
可以从官网下载官网提供的数据集hits_v1和visits_v1,对应的下载路径为:https://datasets.clickhouse.com/hits/partitions/hits_v1.tar和https://datasets.clickhouse.com/visits/partitions/visits_v1.tar,下载之后对应两个压缩包:
hits_v1.tar
visits_v1.tar将以上两个压缩包进行上传到node1节点/softwar目录下,并解压到目录”/var/lib/clickhouse”中。
[root@node1 ~]# cd /software/
[root@node1 software]# tar xvf hits_v1.tar -C /var/lib/clickhouse
[root@node1 software]# tar xvf visits_v1.tar -C /var/lib/clickhouse重启node1节点上的clickhouse,查询数据:
[root@node1 ~]# service clickhouse-server restart
[root@node1 ~]# clickhouse-client
node1 :) show databases;
┌─name─────┐
│ datasets │
│ default │
│ system │
└──────────┘
#查询表 hits_v1中的数据量
node1 :) select count(*) from datasets.hits_v1;
┌─count()─┐
│ 8873898 │
└─────────┘
#查询表 visits_v1中的数据量
node1 :) select count(*) from datasets.visits_v1;
┌─count()─┐
│ 1676861 │
└─────────┘clickhouse完全使用SQL作为查询语言,能够以Selete查询语句从数据库中查询数据,虽然clickhouse拥有优秀的查询性能,但是我们也不能滥用查询,掌握clickhouse支持的各种查询子句很有必要,使用不恰当的SQL语句进行查询不仅带来低性能,还可能带来系统不可预知的错误。例如:我们使用select * 查询数据时,通配符*对列式存储的clickhouse没有一点好处,针对一张拥有133个列的数据表hits_v1,查询2000行数据时,使用*与不使用*速度相差几乎300倍:
#使用*查询2000行数据
node1 :) select * from datasets.hits_v1 limit 2000;
2000 rows in set. Elapsed: 4.306 sec. Processed 2.00 thousand rows, 2.23 MB (464.50 rows/s., 518.76 KB/s.)
#不使用*查询2000行数据
node1 :) select WatchID from datasets.hits_v1 limit 2000;
2000 rows in set. Elapsed: 0.016 sec. Processed 2.00 thousand rows, 16.00 KB (126.48 thousand rows/s., 1.01 MB/s.)此外需要注意,clickhouse中对字段的解析大小写敏感,select a与select A表示的语义不同,下面我们学习下clickhouse中支持的查询语句。
1. with子句
clickhouse支持with子句以增强语句的表达,例如如下查询:
node1 :) SELECT pow(pow(2,2),3)
┌─pow(pow(2, 2), 3)─┐
│ 64 │
└───────────────────┘我们可以通过使用with子句进行简化,提高可读性:
node1 :) WITH pow(2,2) AS a SELECT power(a,3)
┌─pow(a, 3)─┐
│ 64 │
└───────────┘with的使用支持如下四种用法:
1.1 定义变量
可以通过with定义变量,这些变量在后续的查询子句中可以直接访问。例如:
node1 :) WITH 10 AS start
SELECT number
FROM system.numbers
WHERE number > start
LIMIT 5
┌─number─┐
│ 11 │
│ 12 │
│ 13 │
│ 14 │
│ 15 │
└────────┘1.2 调用函数
可以访问select子句中的列字段,并调用函数做进一步处理,处理之后的数据可以在select子句中继续使用。例如:
node1 :) WITH SUM(data_uncompressed_bytes) AS bytes
SELECT
database,
formatReadableSize(bytes) AS format
FROM system.columns
GROUP BY database
ORDER BY bytes DESC
┌─database─┬─format─────┐
│ datasets │ 7.40 GiB │
│ system │ 197.27 MiB │
│ default │ 0.00 B │
└──────────┴────────────┘1.3 定义子查询
可以使用with定义子查询,例如,借助子查询可以得出各database未压缩数据大小与数据总和大小的比例排名:
node1 :) WITH (
SELECT SUM(data_uncompressed_bytes)
FROM system.columns
) AS total_bytes
SELECT
database,
(SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM system.columns
GROUP BY database
ORDER BY database_disk_usage DESC
┌─database─┬─database_disk_usage─┐
│ datasets │ 97.31767735000648 │
│ system │ 2.682322649993527 │
│ default │ 0 │
└──────────┴─────────────────────┘注意:在with中使用子查询时智能返回一行数据,如果结果集大于一行则报错。
1.4 在子查询中重复使用with
在子查询中可以嵌套使用With子句,例如,在计算出各database未压缩数据大小与数据总和的比例之后,又进行取整函数操作:
node1 :) WITH round(database_disk_usage) AS database_disk_usage_v1
SELECT
database,
database_disk_usage,
database_disk_usage_v1
FROM
(
WITH (
SELECT SUM(data_uncompressed_bytes)
FROM system.columns
) AS total_bytes
SELECT
database,
(SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM system.columns
GROUP BY database
ORDER BY database_disk_usage DESC
)
┌─database─┬─database_disk_usage─┬─database_disk_usage_v1─┐
│ datasets │ 97.2911778785499 │ 97 │
│ system │ 2.7088221214500954 │ 3 │
│ default │ 0 │ 0 │
└──────────┴─────────────────────┴────────────────────────┘2. From子句
From子句表示从何处读取数据,支持2种形式,由于From比较简单,这里不再举例,2种使用方式如下:
SELECT clo1 FROM tbl;
SELECT rst FROM (SELECT sum(col1) as rst FROM tbl)from 关键字可以省略,此时会从虚拟表中取数,clickhouse中没有dual虚拟表,它的虚拟表是system.one,例如,以下两种查询等价:
SELECT 1;
SELECT 1 FROM system.one;另外,FROM 子句后还可以跟上final修饰符,可以配合COllapsingMergeTree和VersionedCollapsingMergeTree等表引擎进行查询操作,强制在查询过程中合并,由于Final修饰符会降低查询性能,所以尽量避免使用Final修饰符。
3. Sample子句
Sample子句可以实现数据采样功能,使查询仅返回采样数据而非全部数据,从而减少查询负载。Sample采样机制是幂等机制,也就是说在数据不发生变化,使用相同的采样规则总是能够返回相同的数据。
sample子句只能用于MergeTree系列表引擎,并且要求在Create Table时声明sample by 抽样表达式。
例如,创建表 tbl 声明sample by抽样表达式:
CREATE TABLE tbl(
id UInt32,
name String,
age UInt32,
birthday DATE
)ENGINE = MERGETREE()
PARTITION BY toYYYYMM(birthday)
ORDER BY (id,intHash32(age))
SAMPLE BY intHash32(age)以上创建sample by 采样表时注意:
- Sample by 所声明的表达式必须同时包含在主键的声明内。
- Sample Key 必须是Int类型,虽然在建表不报错,但是数据查询时报错。
另外,建表时没有声明Sample by,在使用sample 采样时会报错。
Sample目前支持三种语法,前面导入的datasets.hits_v1创建时指定了SAMPLE BY ,建表语句如下:
CREATE TABLE datasets.hits_v1(
`WatchID` UInt64,
`JavaEnable` UInt8,
`Title` String,
... ...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)下面就以表hits_v1为例,来讲解sample三种用法。
3.1 Sample factor
Sample factor表示按因子系数采样,factor表示采样因子,取值0-1之间的小数,表示采样总体数据的比例。如果factor 设置为0或者1,则表示不采样。使用如下:
#按10%的因子采样数据
SELECT CounterID FROM datasets.hits_v1 SAMPLE 0.1;
839889 rows in set. Elapsed: 0.114 sec. Processed 7.36 million rows, 88.30 MB (64.46 million rows/s., 773.46 MB/s.)3.2 Sample rows
Sample rows表示按照样本数量采样,其中rows表示大概采样多少行数据,是个近似值,取值必须大于1,如果rows行数大于表总数,效果等同于rows=1,即不采样。使用如下:
node1 :) SELECT count() FROM datasets.hits_v1 SAMPLE 10000;
┌─count()─┐
│ 9251 │
└─────────┘3.3 SAMPLE factor OFFSET n
SAMPLE factor OFFSET n 表示按因子系数和偏移量采样,其中factor表示采样因子,即采样总数据的百分比,n表示偏移多少数据后才开始采样,它们两个取值都是0~1之间的小数。使用如下:
#偏移量0.5并按0.4的系数采样
node1 :) SELECT CounterID FROM datasets.hits_v1 SAMPLE 0.4 OFFSET 0.5;
3589194 rows in set.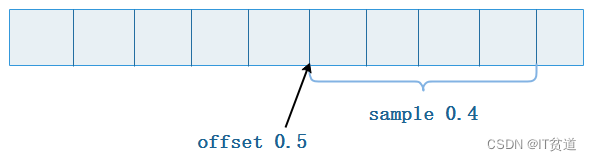
偏移量0.5并按0.4的系数采样的采样为:从数据的二分之一处开始,按总数量的0.4采样数据。如果Sample比例采样出现了溢出,则数据会被自动截断,例如:
node1 :) SELECT CounterID FROM datasets.hits_v1 SAMPLE 0.4 OFFSET 0.9;
892694 rows in set.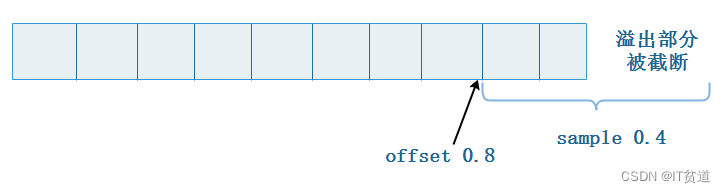
4. Array Join子句
Array join 子句允许在数据表的内部,与数组类型的字段进行join操作,从而将一行数组展开为多行。
首先我们创建一张 MergeTree引擎表并加入数据,操作如下:
#创建表 mr_tbl
node1 :) CREATE TABLE mr_tbl
(
`id` UInt8,
`name` String,
`age` Int,
`local` Array(String)
)
ENGINE = MergeTree()
ORDER BY id
#向表mr_tbl中插入数据
node1 :) insert into table mr_tbl values (1,'zs',18,['beijing','shanghai']),(2,'ls',19,['guangzhou','hangzhou']),(3,'ww',20,[]);
┌─id─┬─name─┬─age─┬─local────────────────────┐
│ 1 │ zs │ 18 │ ['beijing','shanghai'] │
│ 2 │ ls │ 19 │ ['guangzhou','hangzhou'] │
│ 3 │ ww │ 20 │ [] │
└────┴──────┴─────┴──────────────────────────┘我们可以使用array join针对以上表数组字段一条膨胀成多条数据,类似Hive中的explode函数,在clickhouse中没有explode函数,可以使用array join 达到同样效果。
在使用Array join时,一条select语句中只能存在一个Array join(使用嵌套子查询除外),目前支持INNER和LEFT两种JOIN策略:
- INNER ARRAY JOIN
Array join 默认使用的就是INNER JOIN 策略,使用如下:
node1 :) SELECT id,name,age,local FROM mr_tbl ARRAY JOIN local;
┌─id─┬─name─┬─age─┬─local─────┐
│ 1 │ zs │ 18 │ beijing │
│ 1 │ zs │ 18 │ shanghai │
│ 2 │ ls │ 19 │ guangzhou │
│ 2 │ ls │ 19 │ hangzhou │
└────┴──────┴─────┴───────────┘从以上查询结果来看,数据由原来的一行根据local列变成多行,并且排除掉了空数组对应的行。在使用Array Join时,如果我们在膨胀之后的数据结果中能够访问原有数组字段可以使用如下方式查询:
node1 :) SELECT id,name,age,local ,v FROM mr_tbl ARRAY JOIN local AS v;
┌─id─┬─name─┬─age─┬─local────────────────────┬─v─────────┐
│ 1 │ zs │ 18 │ ['beijing','shanghai'] │ beijing │
│ 1 │ zs │ 18 │ ['beijing','shanghai'] │ shanghai │
│ 2 │ ls │ 19 │ ['guangzhou','hangzhou'] │ guangzhou │
│ 2 │ ls │ 19 │ ['guangzhou','hangzhou'] │ hangzhou │
└────┴──────┴─────┴──────────────────────────┴───────────┘- LEFT ARRAY JOIN
Array Join 子句支持LEFT连接策略,Left array join不会排除空数组,执行如下语句并查看结果。
node1 :) SELECT id,name,age,local FROM mr_tbl LEFT ARRAY JOIN local;
┌─id─┬─name─┬─age─┬─local─────┐
│ 1 │ zs │ 18 │ beijing │
│ 1 │ zs │ 18 │ shanghai │
│ 2 │ ls │ 19 │ guangzhou │
│ 2 │ ls │ 19 │ hangzhou │
│ 3 │ ww │ 20 │ │
└────┴──────┴─────┴───────────┘当同时对多个数组字段进行Array join 操作时,array join 对应的多个字段的数组长度必须相等,查询的计算逻辑是按行合并并不是产生笛卡尔积,举例如下:
#创建表 mr_tbl2
node1 :) CREATE TABLE mr_tbl2
(
`id` UInt8,
`name` String,
`age` Int,
`local` Array(String),
`score` Array(UInt32)
)
ENGINE = MergeTree()
ORDER BY id
#向表mr_tbl2中插入以下数据
node1 :) insert into table mr_tbl2 values (1,'zs',18,['beijing','shanghai'],[100,200]),(2,'ls',19,['guangzhou','hangzhou'],[300,400]),(3,'ww',20,[],[]);
┌─id─┬─name─┬─age─┬─local────────────────────┬─score─────┐
│ 1 │ zs │ 18 │ ['beijing','shanghai'] │ [100,200] │
│ 2 │ ls │ 19 │ ['guangzhou','hangzhou'] │ [300,400] │
│ 3 │ ww │ 20 │ [] │ [] │
└────┴──────┴─────┴──────────────────────────┴───────────┘
#执行array join 语句,将数组中的数据一变多行
node1 :) select id,name,age,local,local2,score,score2 from mr_tbl2 left array join local as local2 ,score as score2;
👨💻如需博文中的资料请私信博主。