目录
- 数据集
- ChnSentiCorp
- peoples_daily_ner
- 模型
- bert-base-chinese
- hfl/rbt3
- t5-base
- opus-mt-zh-en
- Chinese_Chat_T5_Base
环境:没有代理,无法访问部分国外网络
数据集
正常情况下通过
load_dataset加载数据集;save_to_disk保存至本地;load_from_disk读取本地数据集。
但由于网络原因,load_dataset加载数据集大多数时候会失败,因此针对不同数据集需要研究如何加载。
思路主要分为
1、git lfs clone下载huggingface数据集
2、研究.py代码,获取原始数据
3、load_dataset加载,save_to_disk保存
ChnSentiCorp
用于中文情感分析,标记了每条评论的情感极性(0或1)
-
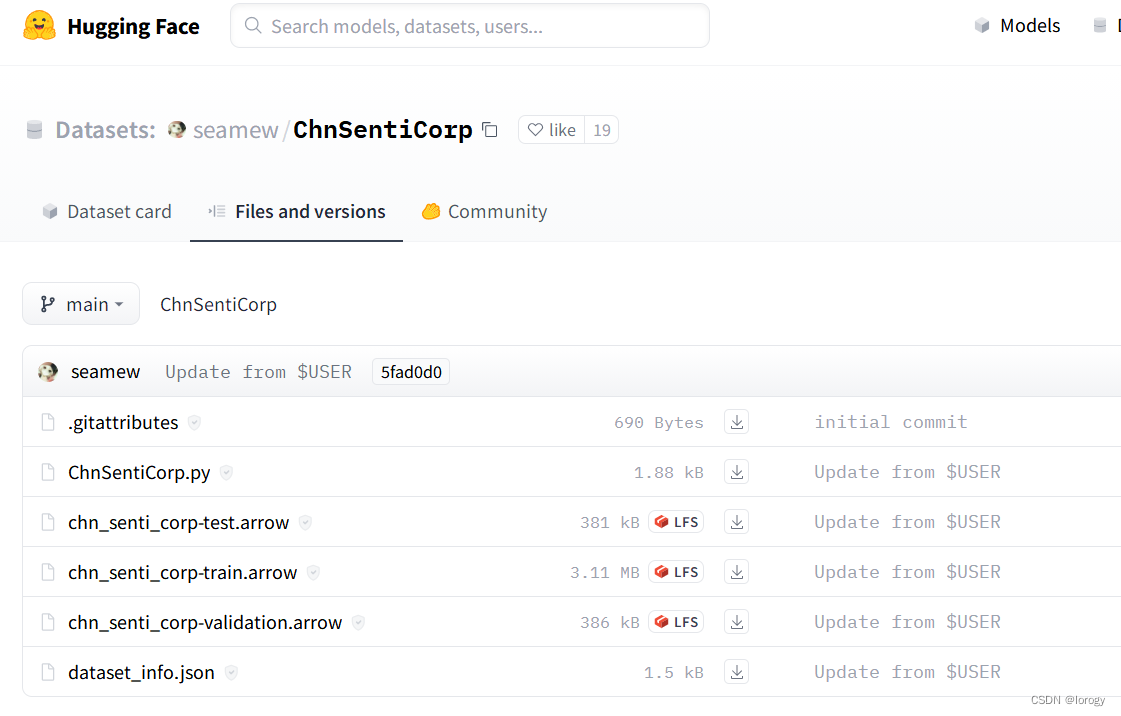
数据集地址:seamew/ChnSentiCorp,可见三个.arrow文件即为原始数据。
-
git下载数据集:
git lfs clone https://huggingface.co/datasets/seamew/ChnSentiCorp -
git下载的文件无法直接使用:
load_dataset会执行.python文件,通过https://drive.google.com下载数据导致下载失败报错load_from_disk会执行失败,因为该文件夹非dist数据集格式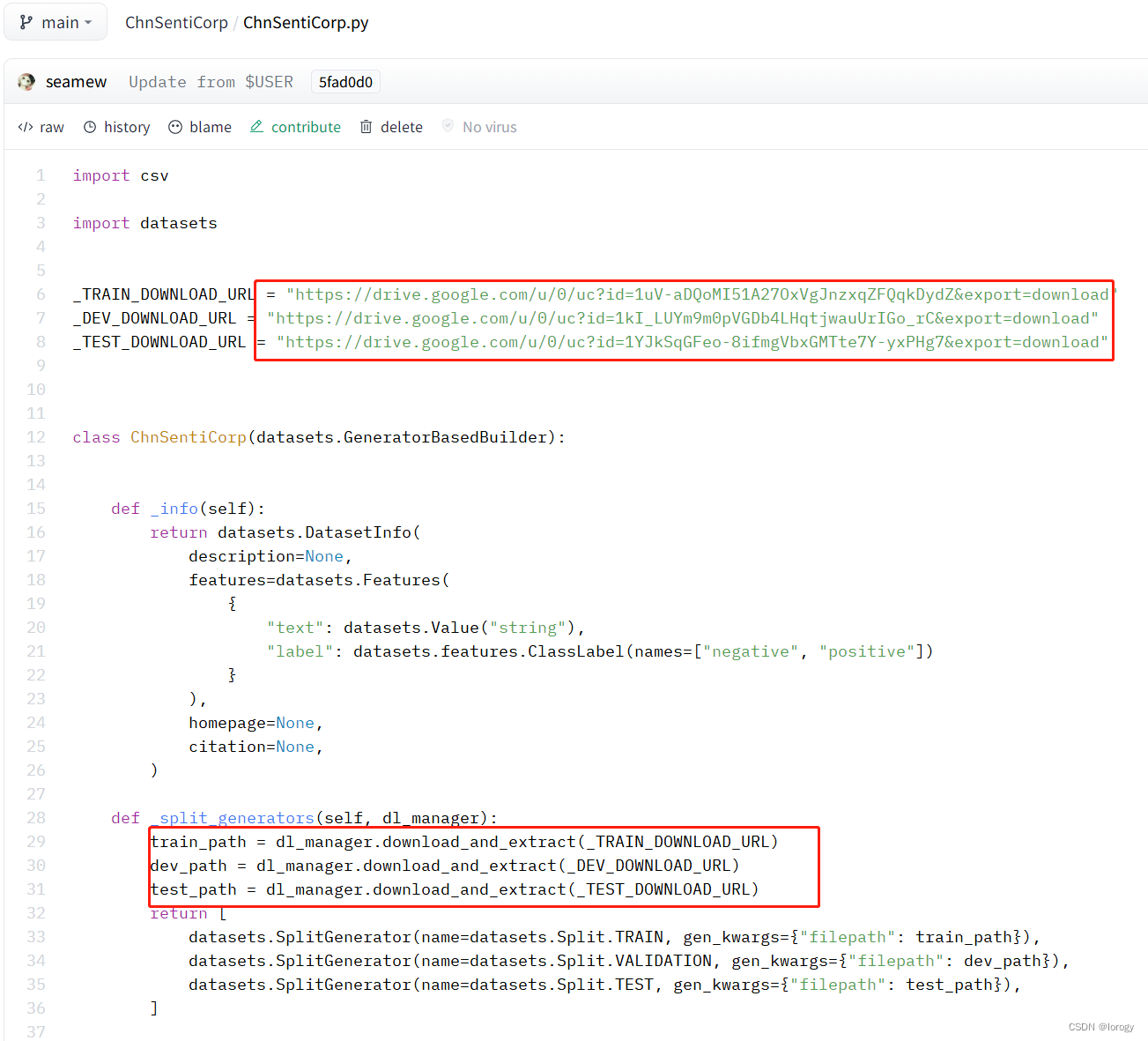
-
加载.arrow原始数据并保存
# 设置data_files data_files = { 'train': './data/ChnSentiCorp/chn_senti_corp-train.arrow', 'test': './data/ChnSentiCorp/chn_senti_corp-test.arrow', 'validation': './data/ChnSentiCorp/chn_senti_corp-validation.arrow'} # 加载arrow数据集 dataset = load_dataset('arrow', data_files=data_files) # 保存至本地 dataset.save_to_disk('./huggingface/hub/datasets/chn_senti_corp')保存在本地的数据集:

-
加载保存至本地的数据集
dataset = load_from_disk('./huggingface/hub/datasets/chn_senti_corp')
peoples_daily_ner
用于中文命名实体识别(NER),来自人民日报的文本数据,标记了人名、地名 、组织机构等
-
数据集地址:peoples_daily_ner,并无原始数据文件。
研究.py:虽然
raw.githubusercontent.com无法发访问,但可通过https://github.com/OYE93/Chinese-NLP-Corpus/tree/master/NER/People's%20Daily去下载原始数据

-
git下载数据集:
git lfs clone https://huggingface.co/datasets/peoples_daily_ner -
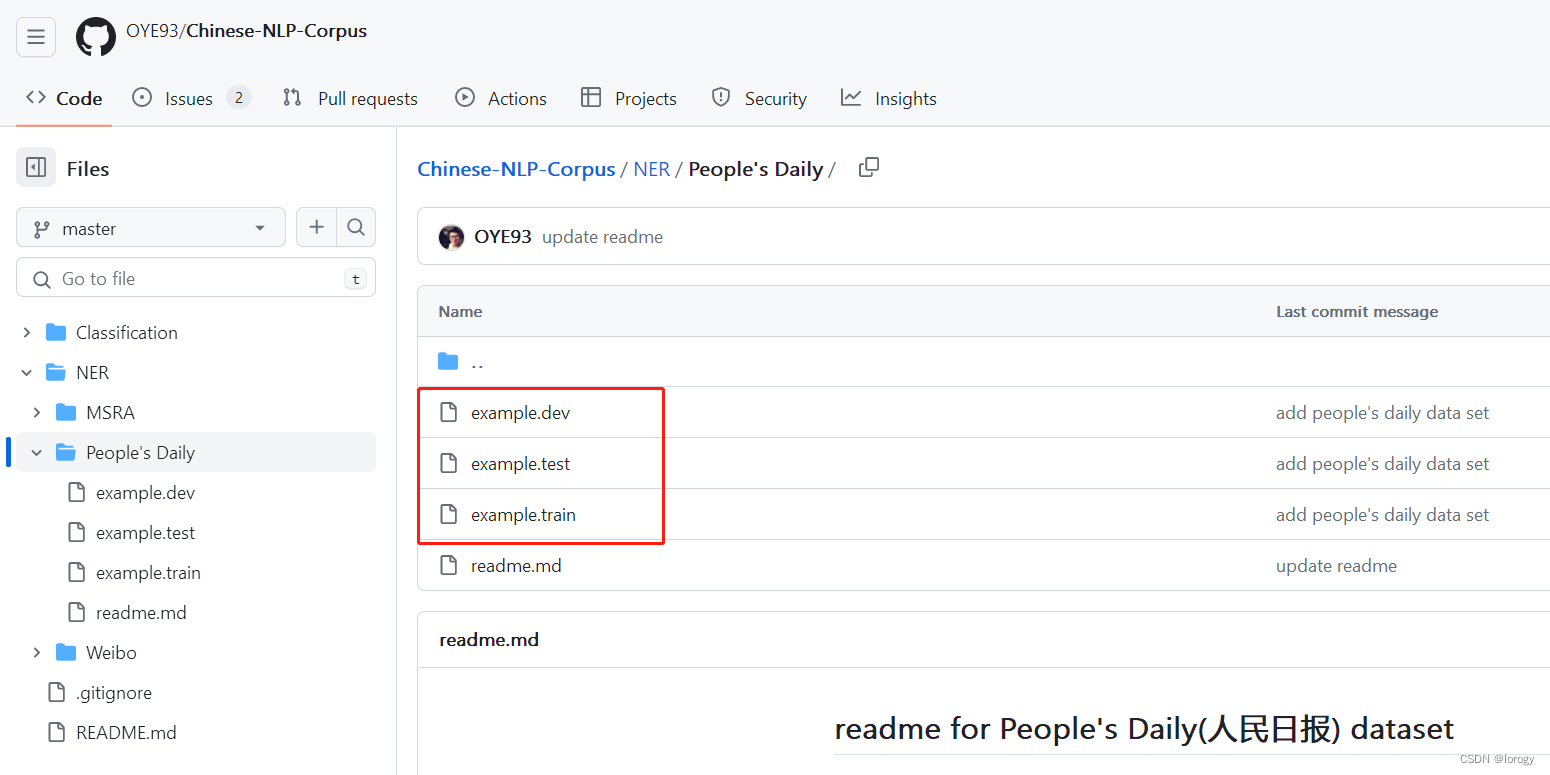
git下载原始数据:
example.train、example.dev、example.test
-
将原始数据放在huggingface数据集文件夹内,并修改.py内
_URL为本地路径

# _URL = "https://raw.githubusercontent.com/OYE93/Chinese-NLP-Corpus/master/NER/People's%20Daily/" _URL = "" _TRAINING_FILE = "example.train" _DEV_FILE = "example.dev" _TEST_FILE = "example.test" -
即可通过
load_dataset加载dataset = load_dataset('./data/peoples_daily_ner') dataset.save_to_disk('./huggingface/hub/datasets/peoples_daily_ner')
模型
模型则要简单许多,直接通过
git lfs clone下载至本地保存即可
bert-base-chinese
基于BERT架构的中文预训练模型,使用了中文维基百科进行预训练,能对中文文本进行深度的理解和分析。
git lfs clone https://huggingface.co/bert-base-chinese
from transformers import BertTokenizer,BertModel
tokenizer = BertTokenizer.from_pretrained('./huggingface/hub/models/bert-base-chinese')
pretrained= BertModel.from_pretrained('./huggingface/hub/models/bert-base-chinese')
hfl/rbt3
哈工大未来语言智能实验室(HFL)开发的中文预训练模型RBT3的版本,使用了中文维基百科和百度文库(Baidu Wenku)进行预训练。
git lfs clone https://huggingface.co/hfl/rbt3
from transformers import AutoTokenizer
from transformers import AutoModel
tokenizer = AutoTokenizer.from_pretrained('./huggingface/hub/models/hfl___rbt3')
pretrained= AutoModel.from_pretrained('./huggingface/hub/models/hfl___rbt3')
t5-base
基于T5(Text-to-Text Transfer Transformer)架构的预训练模型,使用海量的文本数据进行训练,可以用于多种自然语言处理任务。虽然这个模型并不是专门针对中文的,但也可以在中文处理任务中应用。
opus-mt-zh-en
基于神经机器翻译的中文到英语的预训练模型,由牛津大学和阿里巴巴达摩院联合开发,可以用于中文到英语的翻译任务。
Chinese_Chat_T5_Base
中文版对话机器人,在1300w+问答和对话数据上做有监督预训练。