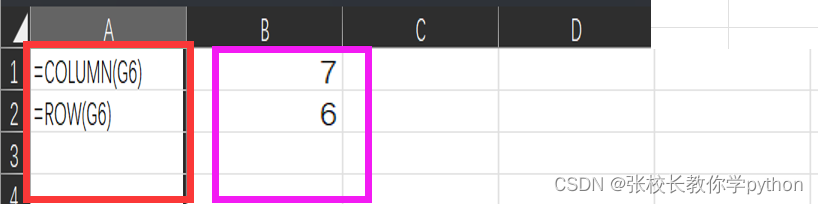
1、COLUMN(reference):返回与列号对应的数字
2、ROW(reference):返回与行号对应的数字
参数reference表示引用/参考单元格,输入后引用单元格后colimn()和row()会返回这个单元格对应的列号和行号。若参数reference没有引用单元格,返回的是当前单元格的列号和行号。
下面静下心来,细细阅读下面SORT和SORTBY的用法(写的很细):
3、SORT(array,[sort_index],[sort_order],[by_col]): 对某个区域或数组的内容进行排序
sort(要排序的数组,按照哪一行或者哪一列的数据大小进行排序,升序或者降序排序,按行或者按列排序)
= sort(要排序的数组,排序指数(常数)不是范围,排序顺序,按行或者按列排序)
参数说明:
array : 要排序的数组
[sort_index] :按照哪一行或哪一列进行排序(多行多列的数组)
[sort_order] :按升序或降序排列(1代表升序,-1代表降序)
[by_col] :TRUE按列排序,FALSE按行排序
之前说过,如果函数的参数用中括号括起来,那么这个参数可以不赋值。
(1)只对一行或一列数据进行排序
1)一列:默认将指定数据从小到大排序
解读:
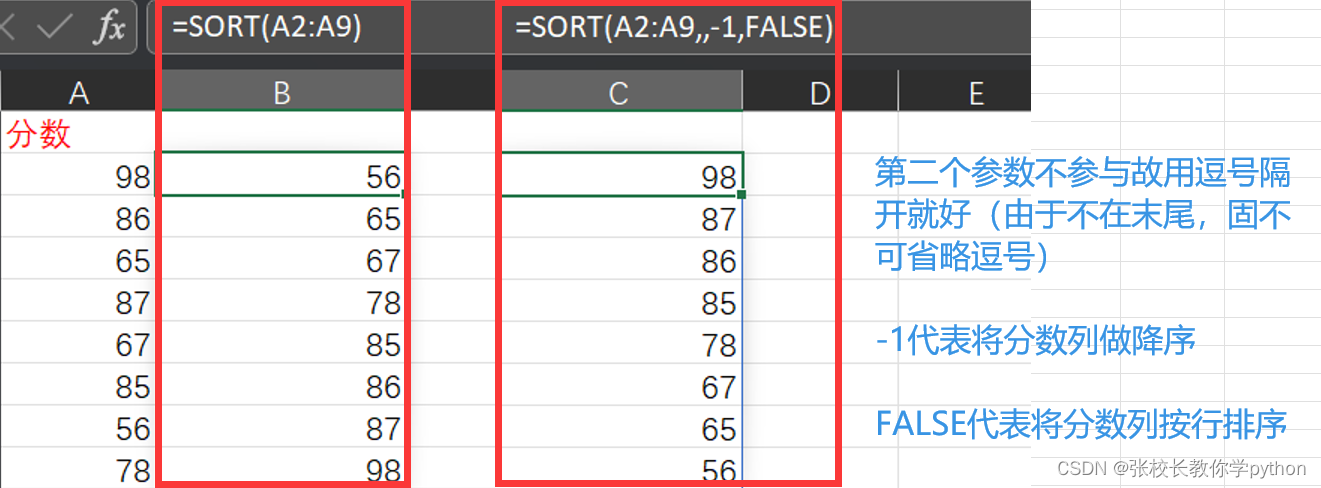
第一点: 中括号括起来的参数我们可以不赋值,例如第一列排序,array后的三个参数都未赋值,那么默认按升序排列。
第二点: 第二列排序中,给出了第三个和第四个参数,那么对于未赋值的第二参数,我们需要用逗号隔开,再输入后面参数的值(若是不想给最后一个参数赋值,不输入参数即可,不用逗号)。同样的,不给第三个参数赋值,而要给第四个参数赋值,也要用逗号隔开再输入第四个参数(因为第二个和第三个参数在中间,受位置约束)。
第三点: 第二列排序中,FALSE代表将分数按行排序(细细理解:原数组是一列数据,现将其数据排序,而每个数据在不同的行,比较不同行的数据,所以是按行排序),此处写不写FALSE都是一样的的效果。
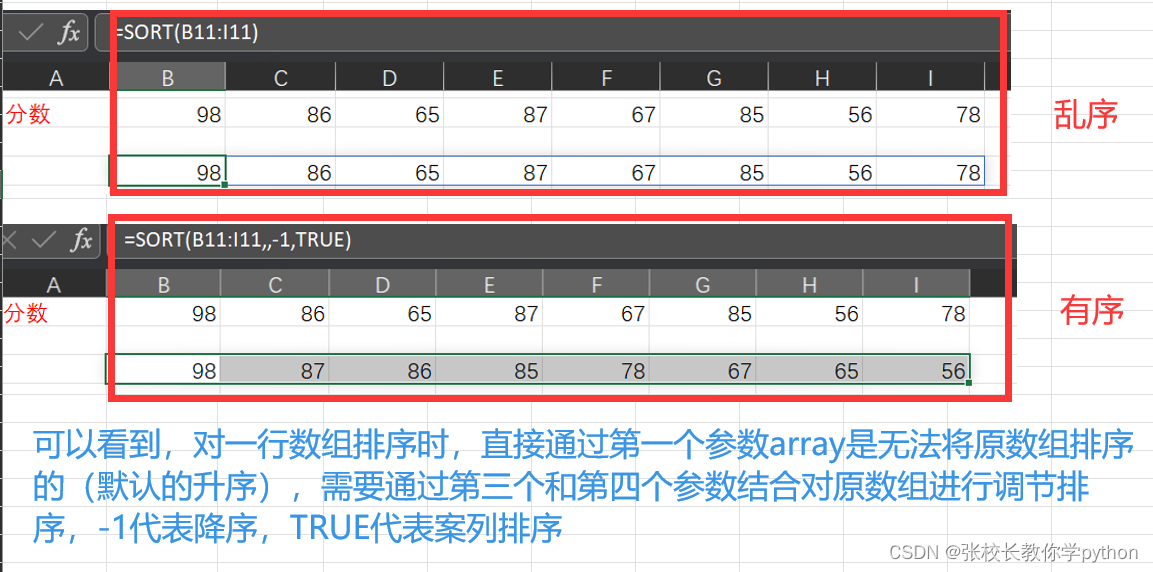
2)一行:对一行数据来说,要给出足够的参数说明,着实有点特殊,通过下面的案例进行有力说明
解读:
第一点: 对一行数组排序,不能通过参数array就能将原数组进行从小到大排序,而是得到乱序的数组,这时要借助第三个参数(指定升序还是降序)和第四个参数(指定按列排序还是按行排序)
第二点: 细细理解:原数组是一行数组,每个数据在不同的列,比较不同列的数据,故应该是TRUE按列排
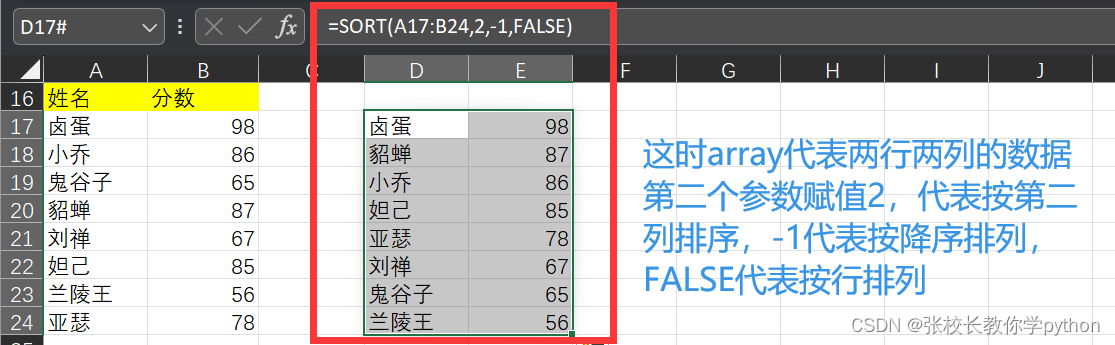
(2)对多行多列数据进行排序
1)列:
解读: 第二个参数sort_index表示按照哪一行或哪一列进行排序,参数赋值是该列或该行在整个数组中对应的列号或行号,而不是在这个数组中的范围。以下案例就是按照分数列的数据大小排序,分数列在第二列,故第二个参数为2。
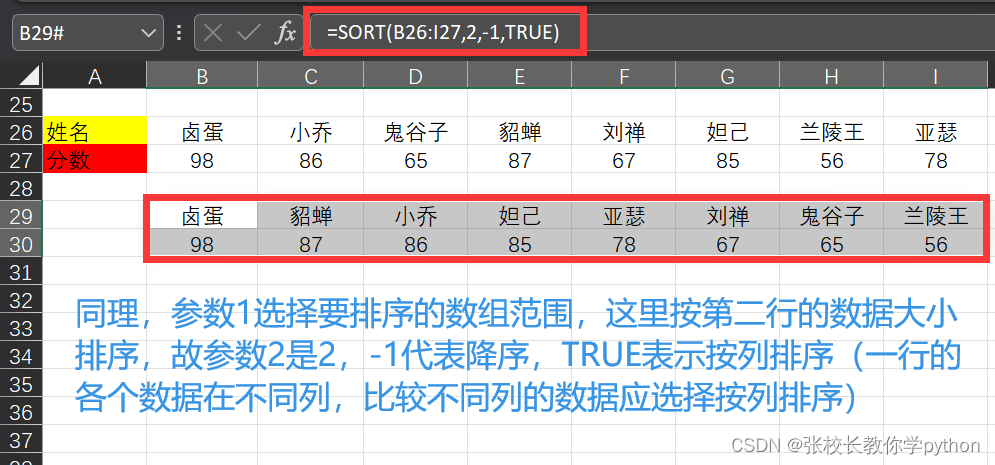
2)行:
4、SROTBY(array,by_array1,[sort_order1],…):对某个区域按照某列数据进行排序(默认升序)
sortby(要排序的数组,第一排序标准对应行或者列(范围),排序方式1(升序或降序),第二排序标准对应的行或者列(范围),排序方式2(升序或降序),…)
SORTBY()和SORT()的区别:
(1)功能差不多,但SORTBY()的强大在于有第一排序标准,第二排序标准……
(2)SORTBY()的第二个参数是一个范围(参照的行或列的范围),而SORT()是一个常数(行号或列号的值)
(3)对于行数据,SORTBY()默认按列排序,而SORT()需要对第四个参数赋值TRUE

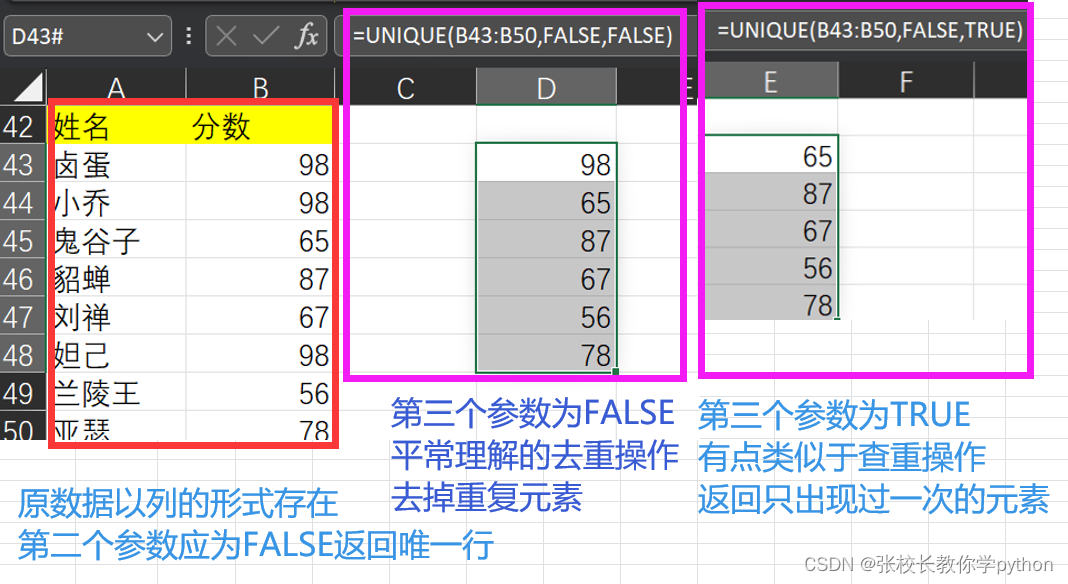
5、UNIQUE(array,[by_col],[exactly_once]):对某范围数据进行去重(从一个范围或数组返回唯一值)
参数解读:
array: 需要去重的数组
by_col: TRUE返回唯一列(原数据以行的形式存在);FALSE返回唯一行(原数据以列的形式存在)
exactly_once: TRUE返回只出现一次的项;FALSE返回每个不同的项(把重复的数据去掉,每个元素只保留一个)