Hadoop的概述与安装
- 一、Hadoop内部的三个核心组件
- 1、HDFS:分布式文件存储系统
- 2、YARN:分布式资源调度系统
- 3、MapReduce:分布式离线计算框架
- 4、Hadoop Common(了解即可)
- 二、Hadoop技术诞生的一个生态圈
- 数据采集存储
- 数据清洗预处理
- 数据统计分析
- 数据迁移
- 数据可视化
- zookeeper
- 三、主要围绕Apache的Hadoop发行版本来学习
- 四、Hadoop的安装的四种模式
- 五、Hadoop的伪分布安装流程
- 六、格式化HDFS集群
- 七、启动HDFS和YARN
- 八、Hadoop的完全分布式安装
- 1、克隆虚拟机
- 2、安装JDK
- 3、安装Hadoop完全分布式
- 4、格式化HDFS
- 5、启动HDFS和YARN
Hadoop技术 —— 脱自于Google的三篇论文(大数据软件一般都要求7*24小时不宕机)
把大数据中遇到的两个核心问题(海量数据的存储问题和海量数据的计算问题)全部解决了
一、Hadoop内部的三个核心组件
1、HDFS:分布式文件存储系统
分布式思想解决了海量数据的分布式存储问题
三个核心组件组成
- NameNode:主节点
- 存储整个HDFS集群的元数据(目录结构)
- 管理整个HDFS集群
- DataNode:数据节点/从节点
- 存储数据的,DataNode以Block块的形式进行文件存储
- SecondaryNameNode:小秘书
- 帮助NameNode合并日志数据的(元数据)
2、YARN:分布式资源调度系统
解决分布式计算程序的资源分配以及任务监控问题
Mesos:分布式资源管理系统(YARN的替代品)
两个核心组件组成
- ResourceManager:主节点
- 管理整个YARN集群的,同时负责整体的资源分配
- NodeManager:从节点
- 真正负责进行资源提供的
3、MapReduce:分布式离线计算框架
分布式思想解决了海量数据的分布式计算问题
4、Hadoop Common(了解即可)
二、Hadoop技术诞生的一个生态圈
数据采集存储
flume、Kafka、hbase、hdfs
数据清洗预处理
MapReduce、Spark
数据统计分析
Hive、Pig
数据迁移
sqoop
数据可视化
ercharts
zookeeper
三、主要围绕Apache的Hadoop发行版本来学习
官网:https://hadoop.apache.org
apache hadoop发行版本
- hadoop1.x
- hadoop2.x
- hadoop3.x
- hadoop3.1.4
四、Hadoop的安装的四种模式
hadoop软件中HDFS和YARN是一个系统,而且是一个分布式的系统,同时他们还是一种主从架构的软件。
第一种:本地安装模式:只能使用MapReduce,HDFS、YARN均无法使用 —— 基本不用
第二种:伪分布安装模式:hdfs和yarn的主从架构软件全部安装到同一个节点上
第三种:完全分布式安装模式:hdfs和yarn的主从架构组件安装到不同的节点上
第四种:HA高可用安装模式:hdfs和yarn的主从架构组件安装到不同节点上,同时还需要把他们的主节点多安装两三个,但是在同一时刻只能有一个主节点对外提供服务 —— 借助Zookeeper软件才能实现
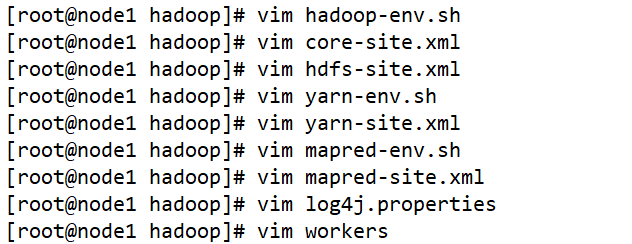
修改配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-env.sh、mapred-site.xml、yarn-site.xml、yarn-env.sh、workers、log4j.properties、capacity-scheduler.xml、dfs.hosts、dfs.hosts.exclude
五、Hadoop的伪分布安装流程
1、需要在Linux上先安装JDK,Hadoop底层是基于Java开发的
- 环境变量的配置主要有两个地方可以配置
/etc/profile:系统环境变量
~/.bash_profile:用户环境变量
环境变量配置完成必须重新加载配置文件
source 环境变量文件路径
2、配置当前主机的主机映射以及ssh免密登录
3、安装本地版本的Hadoop
- 上传 —— 使用xftp将Windows下载好的
hadoop-3.1.4.tar.gz传输到/opt/software目录下 - 解压 ——
tar -zxvf hadoop-3.1.4.tar.gz -C /opt/app - 配置环境变量
vim /etc/profileexport HADOOP_HOME=/opt/app/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
4、安装伪分布式版本的Hadoop
修改各种各样的hadoop配置文件即可
- hadoop-env.sh 配置Java的路径
vim hadoop-env.sh
#第54行
export JAVA_HOME=/opt/app/jdk1.8.0_371
#第58行
export HADOOP_HOME=/opt/app/hadoop-3.1.4
#第68行
export HADOOP_CONF_DIR=/opt/app/hadoop-3.1.4/etc/hadoop
#最后一行
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
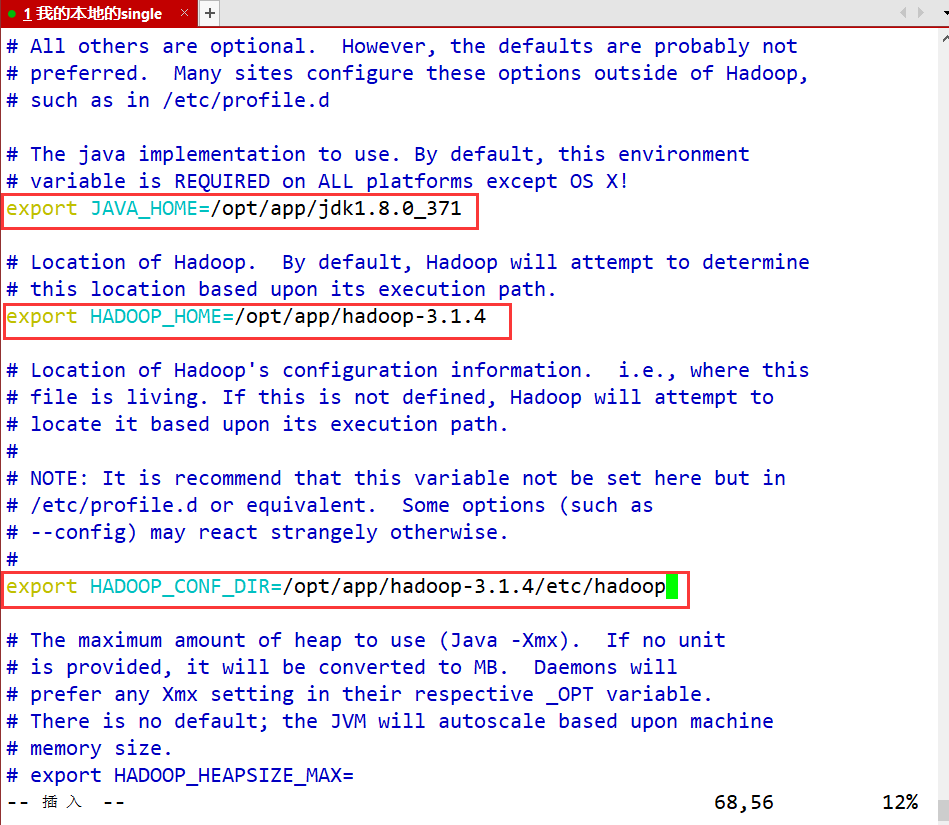
- core-site.xml 配置HDFS和YARN的一些共同的配置项
- 配置HDFS的NameNode路径
- 配置HDFS集群存储的文件路径
vim core-site.xml
<!--在configuration标签中增加如下配置-->
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://single:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 HDFS相关文件存放地址-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-3.1.4/metaData</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>

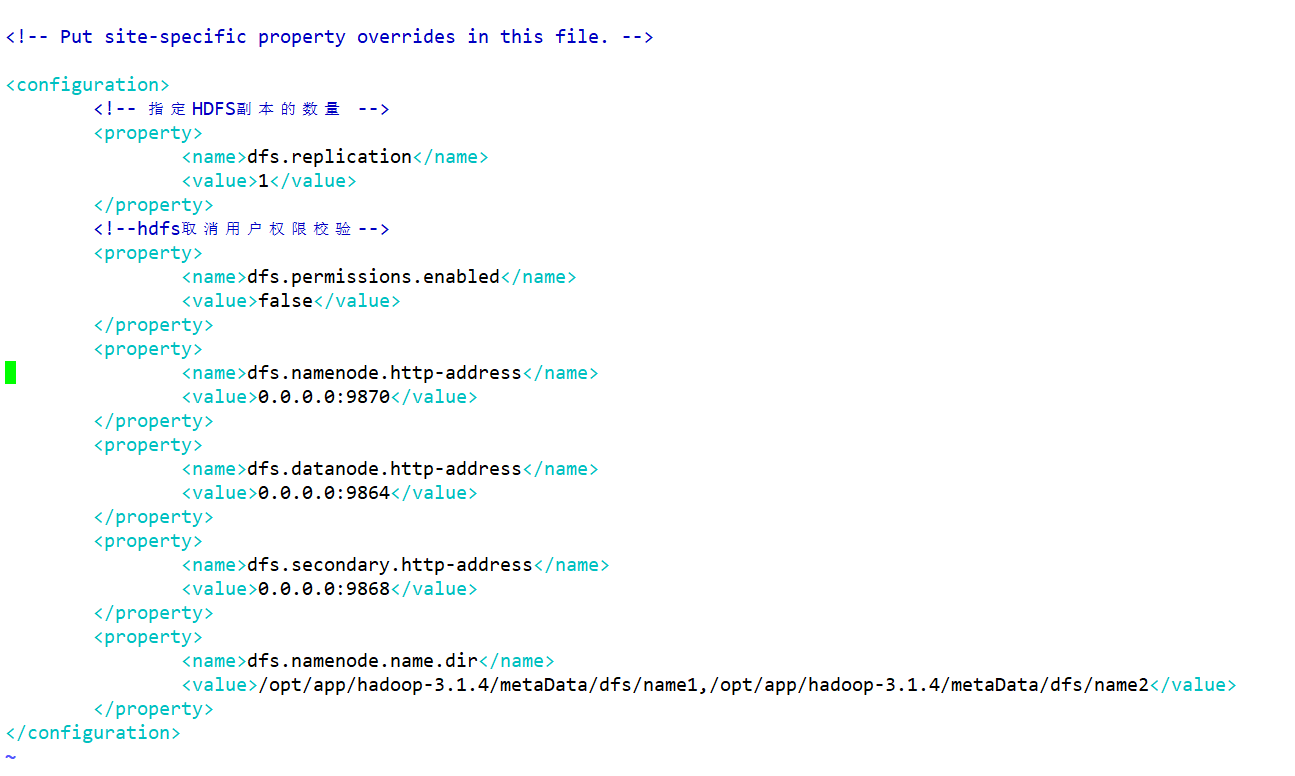
- hdfs-site.xml 配置HDFS的相关组件
- 配置NameNode的web访问路径、DN的web访问网站,SNN的web访问路径等等
vim hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<!-- hdfs的dn存储的block的备份数-->
<value>1</value>
</property>
<!--hdfs取消用户权限校验-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
<!-- 50070,9870-->
</property>
<property>
<name>dfs.datanode.http-address</name>
<value>0.0.0.0:9864</value>
<!-- 50075,9864-->
</property>
<property>
<name>dfs.secondary.http-address</name>
<value>0.0.0.0:9868</value>
<!-- 50090,9868-->
</property>
<!--用于指定NameNode的元数据存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/app/hadoop-3.1.4/metaData/dfs/name1,/opt/app/hadoop-3.1.4/metaData/dfs/name2</value>
</property>
</configuration>
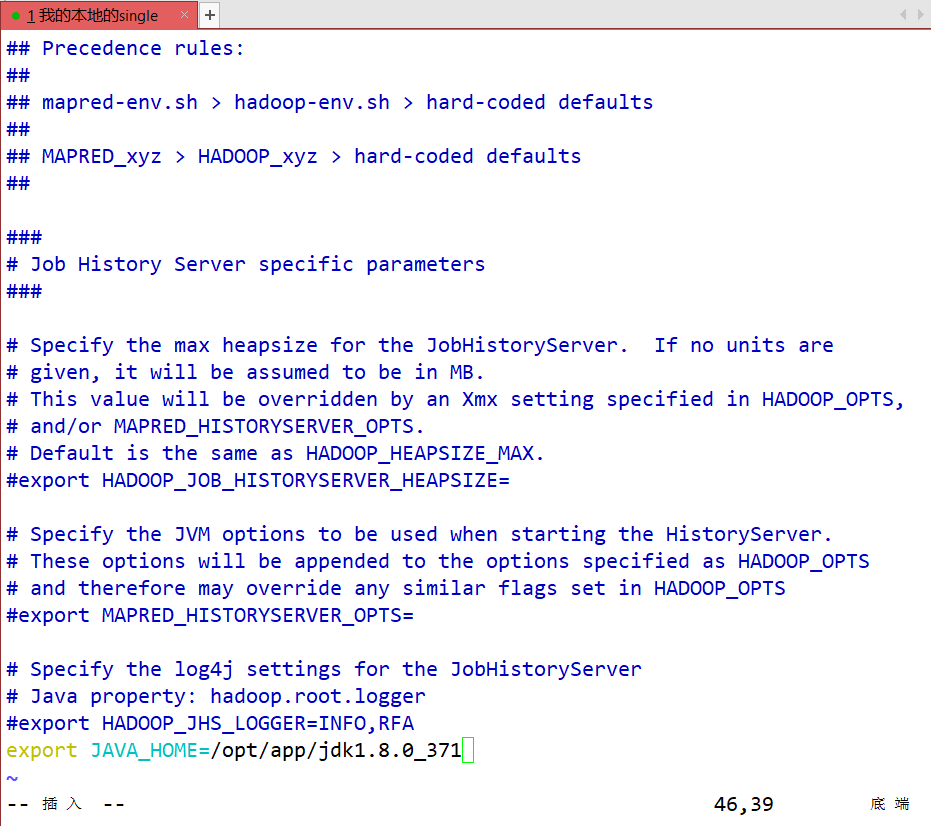
- mapred-env.sh 配置MR程序运行时的关联的软件(Java YARN)路径
vim mapred-env.sh
#最后一行
export JAVA_HOME=/opt/app/jdk1.8.0_371
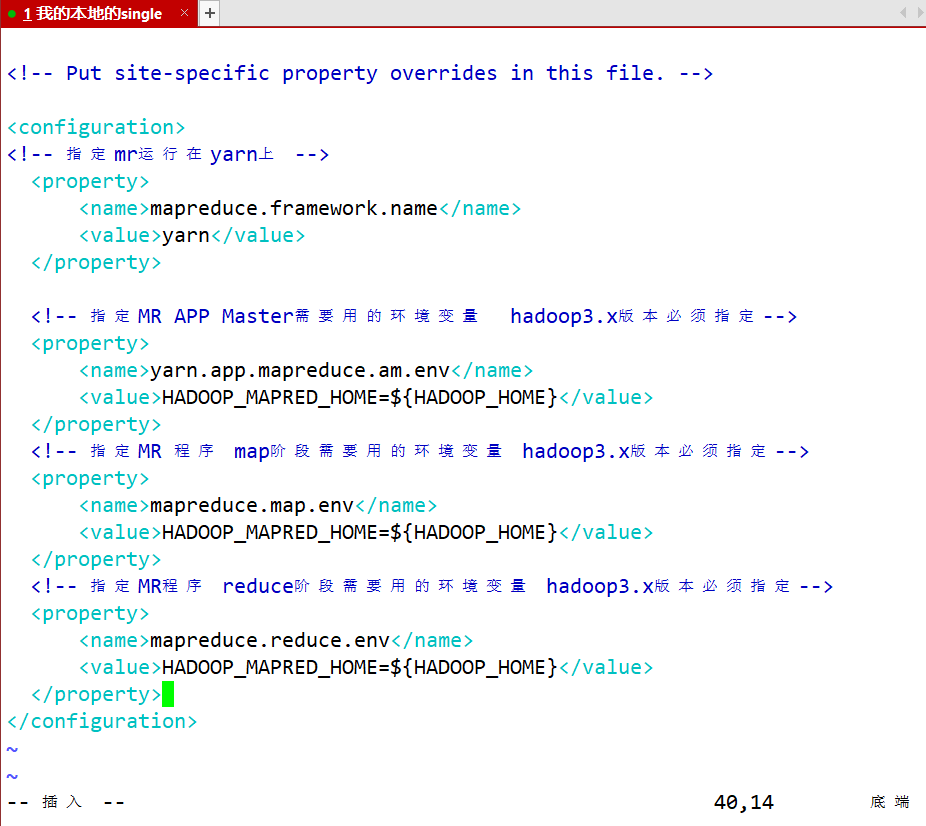
- mapred-site.xml 配置MR程序运行环境
- 配置将MR程序在YARN上运行
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定MR APP Master需要用的环境变量 hadoop3.x版本必须指定-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 指定MR 程序 map阶段需要用的环境变量 hadoop3.x版本必须指定-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 指定MR程序 reduce阶段需要用的环境变量 hadoop3.x版本必须指定-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>250</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx250M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>300</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx300M</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>single:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>single:19888</value>
</property>

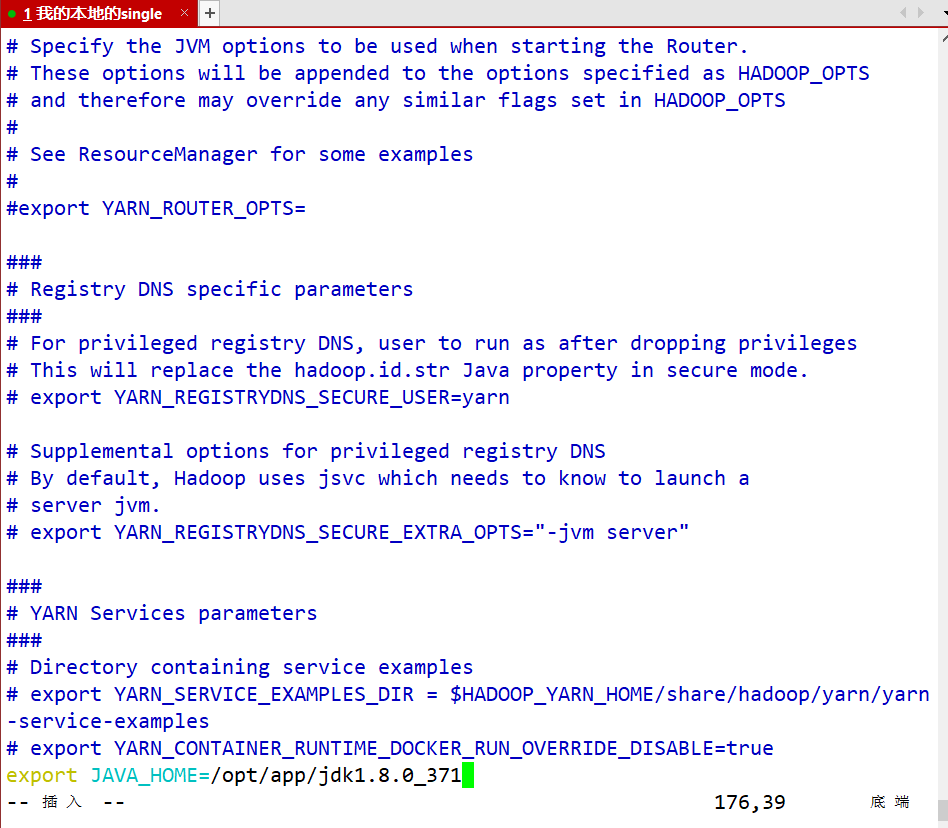
- yarn-env.sh 配置YARN关联的组件路径
vim yarn-env.sh
#最后一行
export JAVA_HOME=/opt/app/jdk1.8.0_371
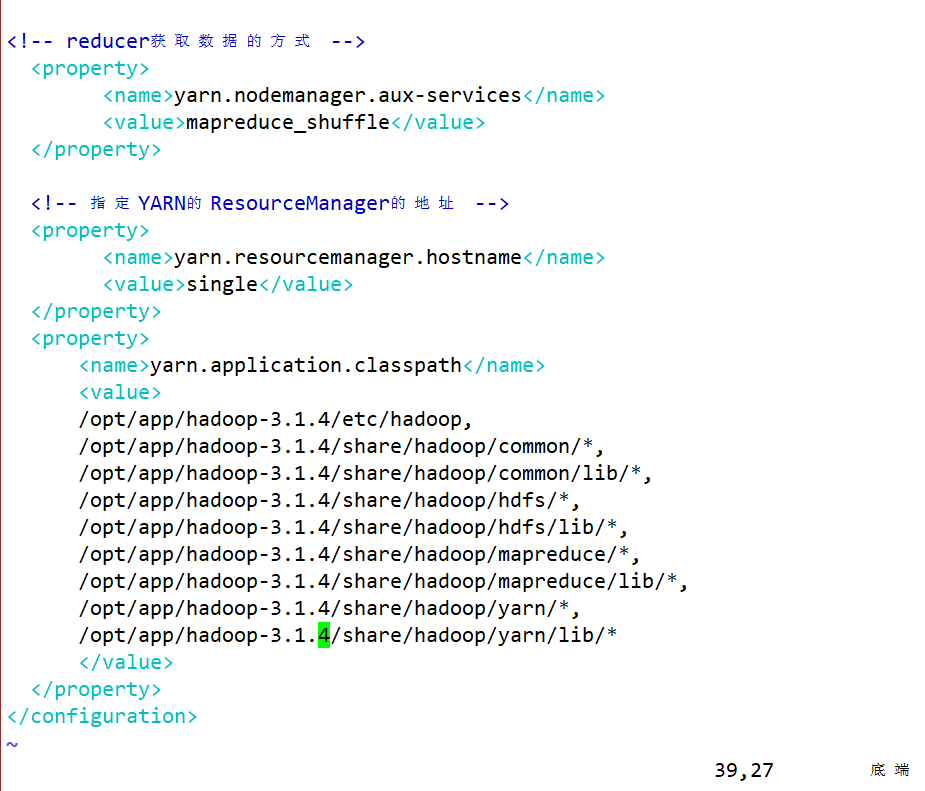
- yarn-site.xml 配置YARN的相关组件
- 配置RM、NM的web访问路径等等
vim yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 指定yarn的RM组件安装到哪个主机上-->
<value>single</value>
</property>
<property>
<name>yarn.application.classpath</name>
<!-- 指定yarn软件在运行时需要的一些环境路径-->
<value>
/opt/app/hadoop-3.1.4/etc/hadoop,
/opt/app/hadoop-3.1.4/share/hadoop/common/*,
/opt/app/hadoop-3.1.4/share/hadoop/common/lib/*,
/opt/app/hadoop-3.1.4/share/hadoop/hdfs/*,
/opt/app/hadoop-3.1.4/share/hadoop/hdfs/lib/*,
/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/*,
/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/lib/*,
/opt/app/hadoop-3.1.4/share/hadoop/yarn/*,
/opt/app/hadoop-3.1.4/share/hadoop/yarn/lib/*
</value>
</property>
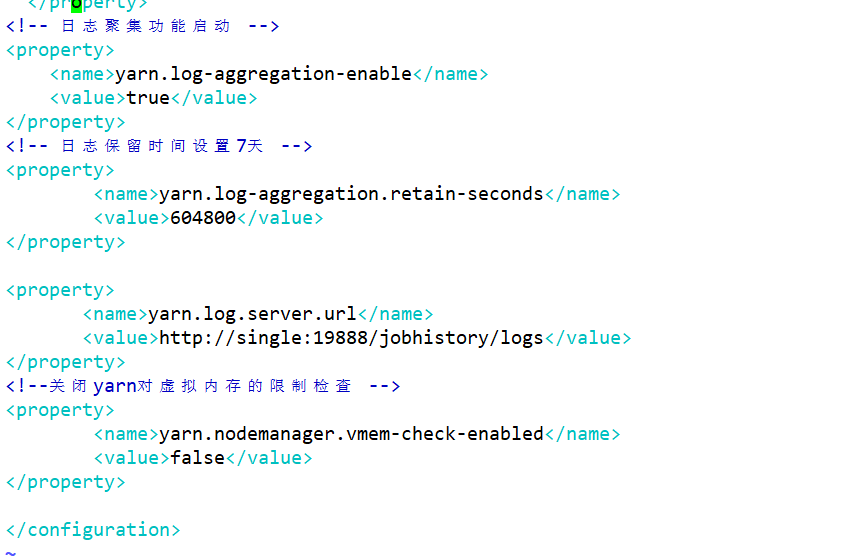
<!-- yarn.resourcemanager.webapp.address:指的是RM的web访问路径-->
<!-- 日志聚集功能启动 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://single:19888/jobhistory/logs</value>
</property>
<!--关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
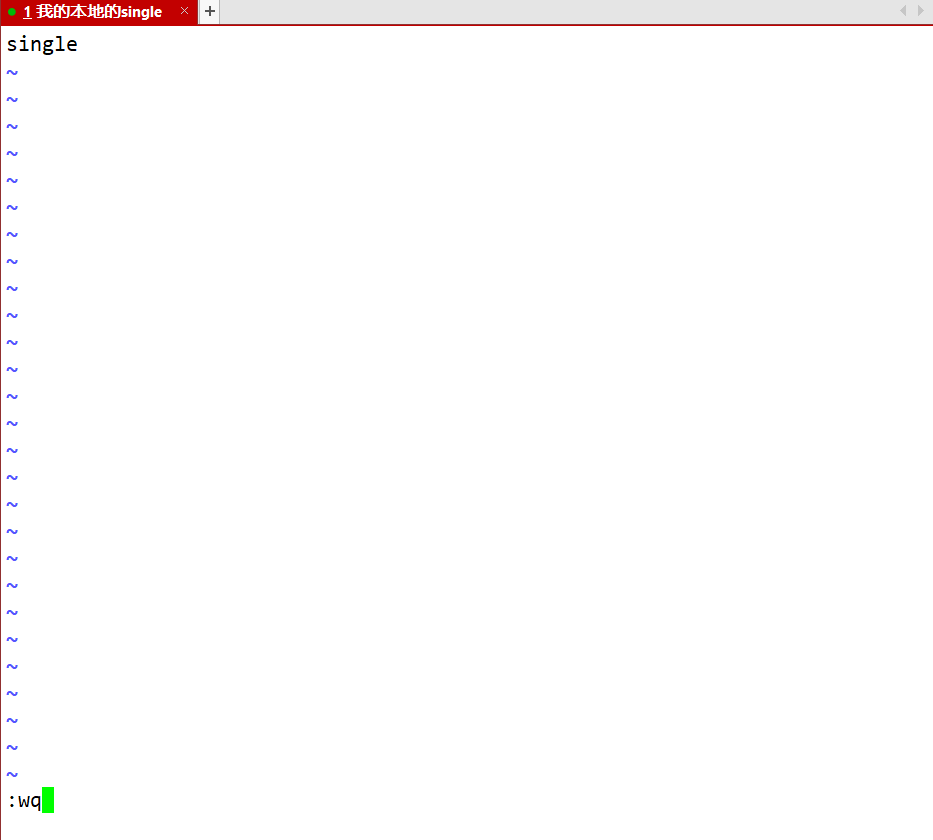
- workers/slaves 配置HDFS和YARN的从节点的主机
- 配置DN和NM在哪些节点上需要安装
vim workers
<!-- 将localhost改为single -->
single
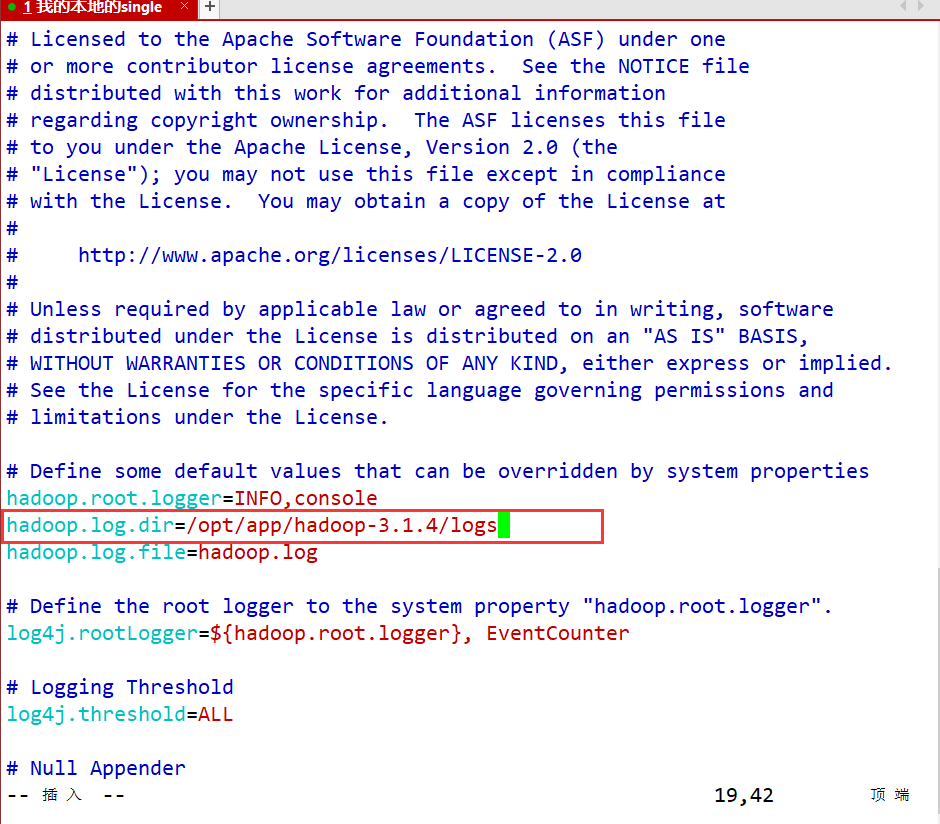
- log4j.properties —— 配置Hadoop运行过程中日志输出目录
vim log4j.properties
#第19行
hadoop.log.dir=/opt/app/hadoop-3.1.4/logs
#指定Hadoop运行过程中日志输出目录
六、格式化HDFS集群
hdfs namenode -format
七、启动HDFS和YARN
-
HDFS
- start-dfs.sh
报错
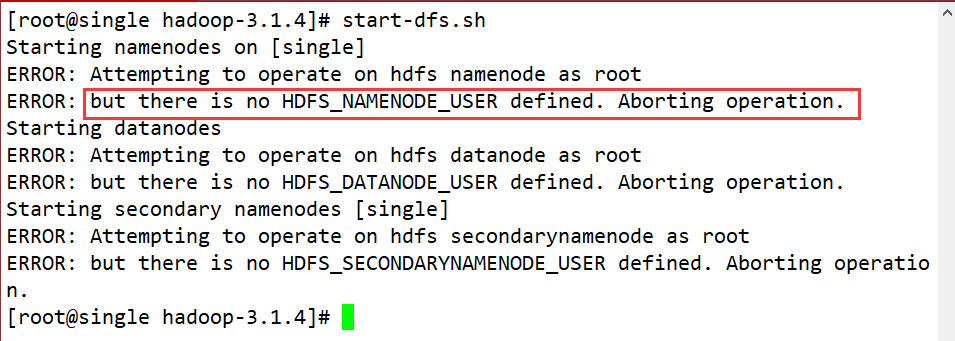
解决方案:
vim /etc/profile #在最后一行加入以下内容 # HADOOP 3.X版本还需要增加如下配置 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root #然后使配置文件生效 source /etc/profile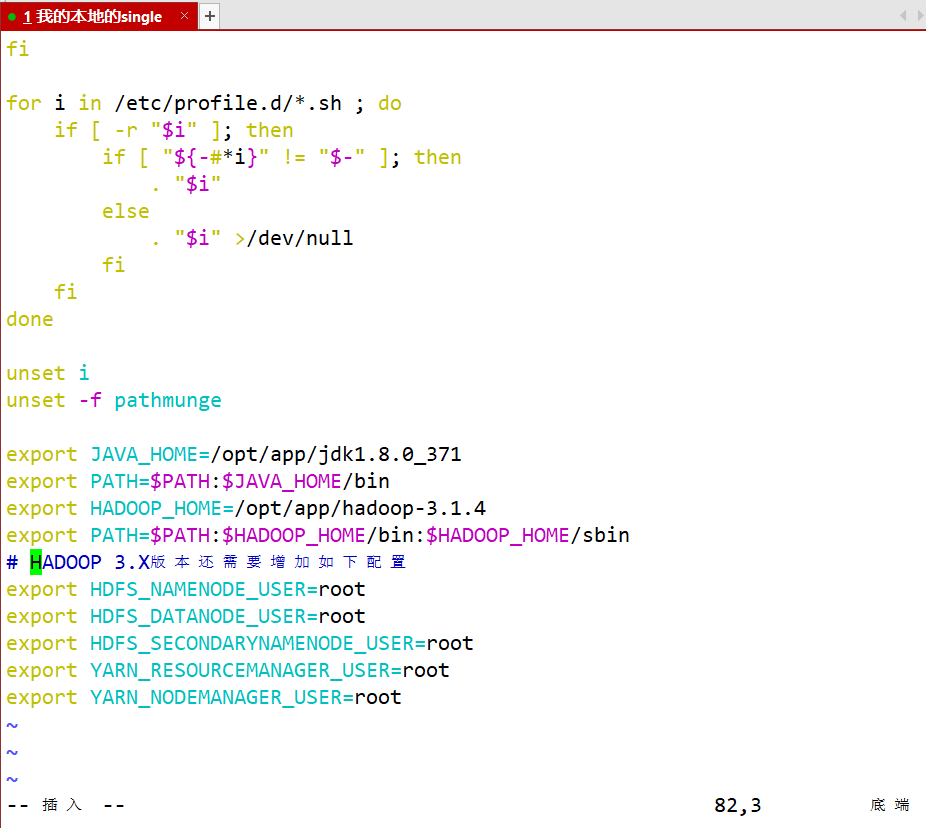
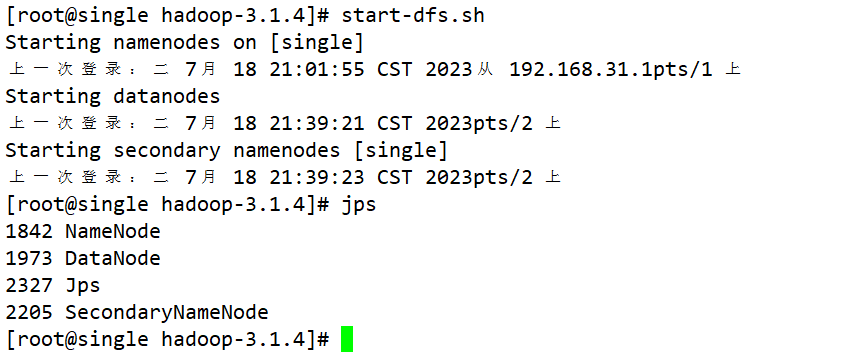
- stop-dfs.sh
- 提供了一个web访问网站,可以监控整个HDFS集群的状态信息
http://ip:9870 hadoop3.x
ip:50070 hadoop2.x
-
yarn
- start-yarn.sh
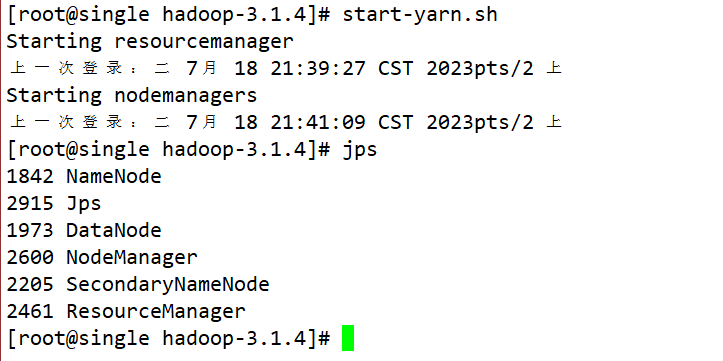
- stop-yarn.sh
- 提供了一个web网站,可以监控整个YARN集群的状态:
http://ip:8088
八、Hadoop的完全分布式安装
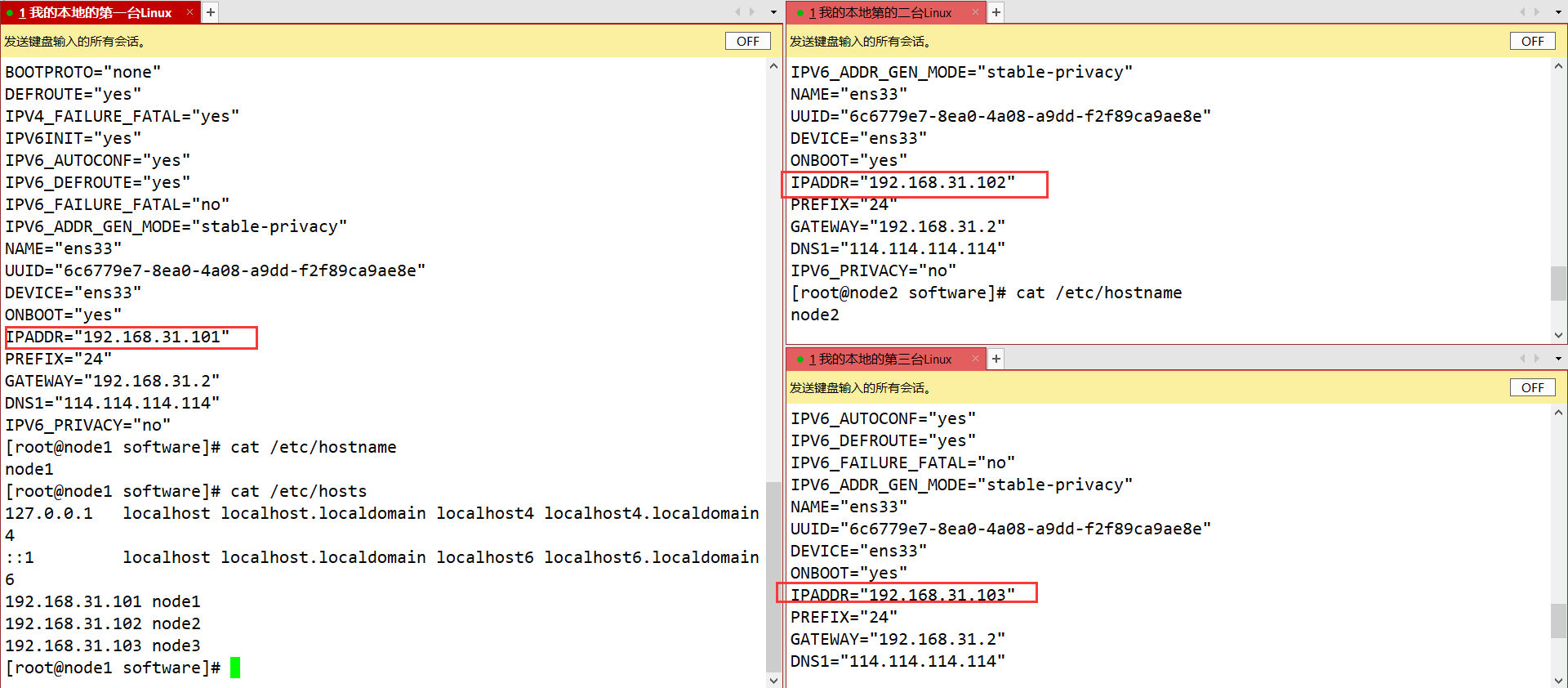
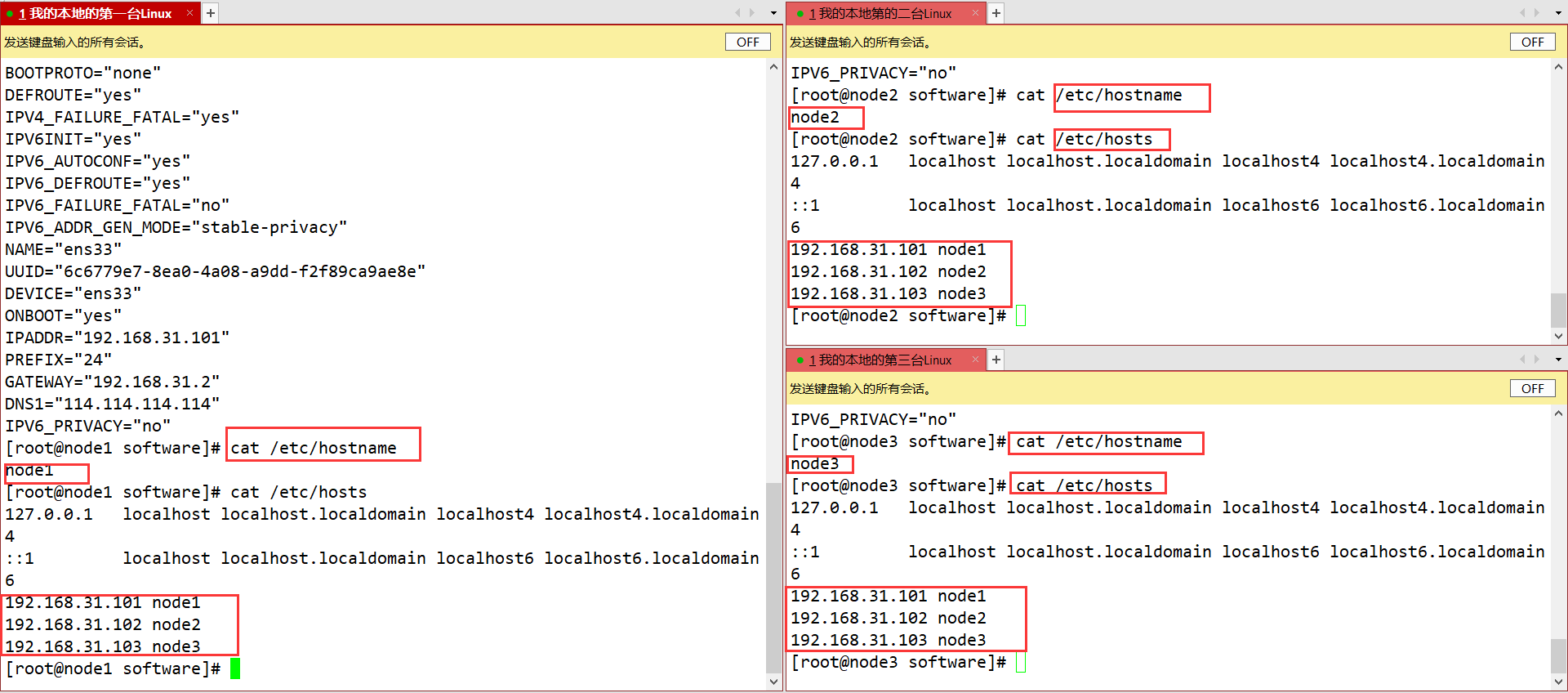
1、克隆虚拟机
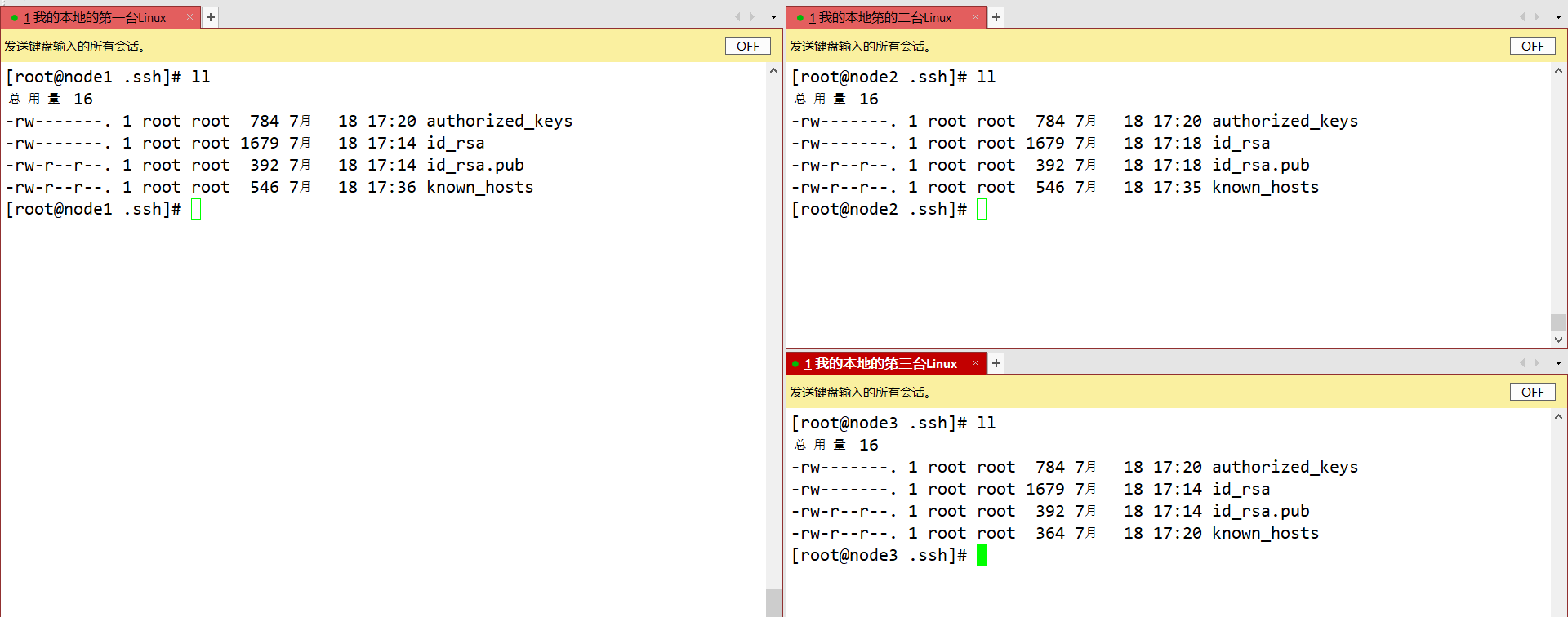
三台虚拟机需要配置IP、主机名、主机IP映射、ssh免密登录、时间服务器的安装同步、yum数据仓库更换为国内镜像源
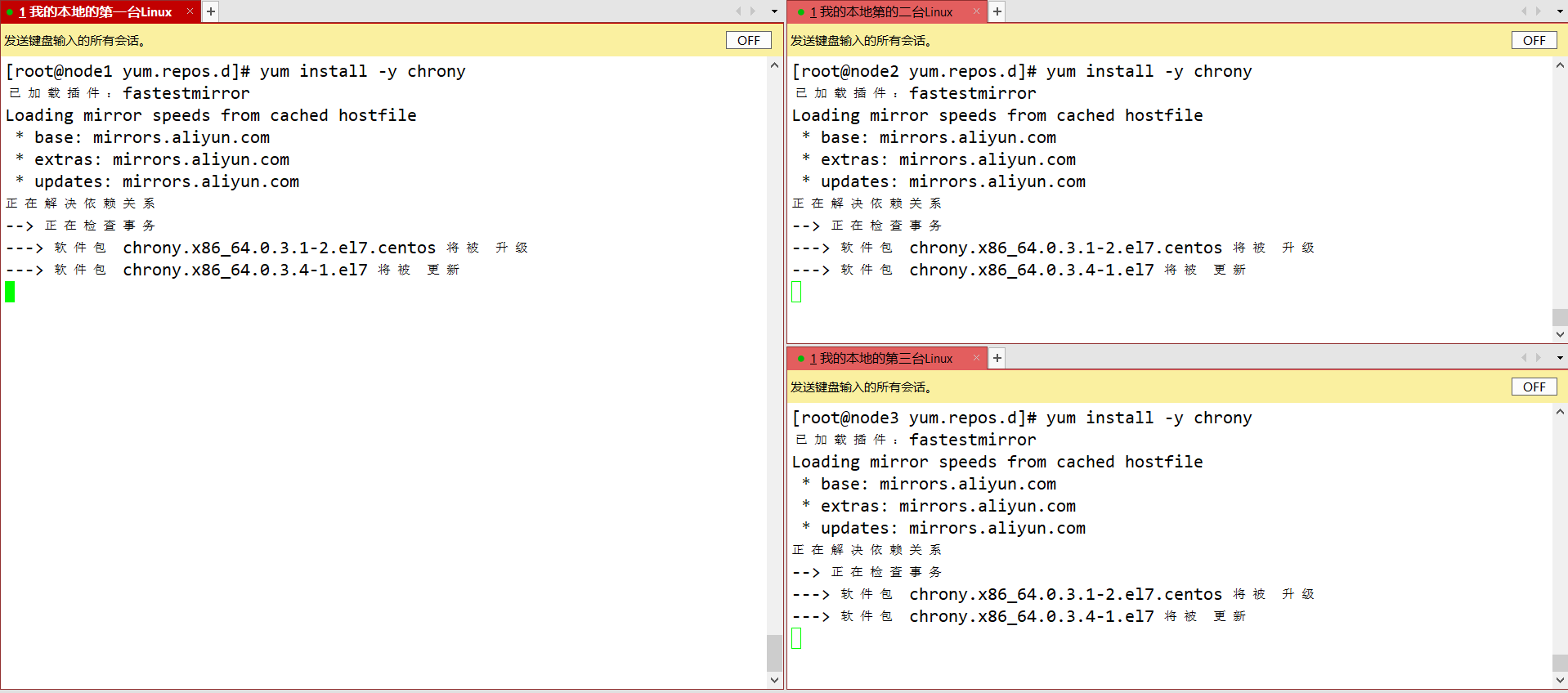
时间服务器chrony的安装同步
yum install -y chrony
先配置主服务器
vim /etc/chrony.conf
在第7行添加allow 192.168.31.0/24
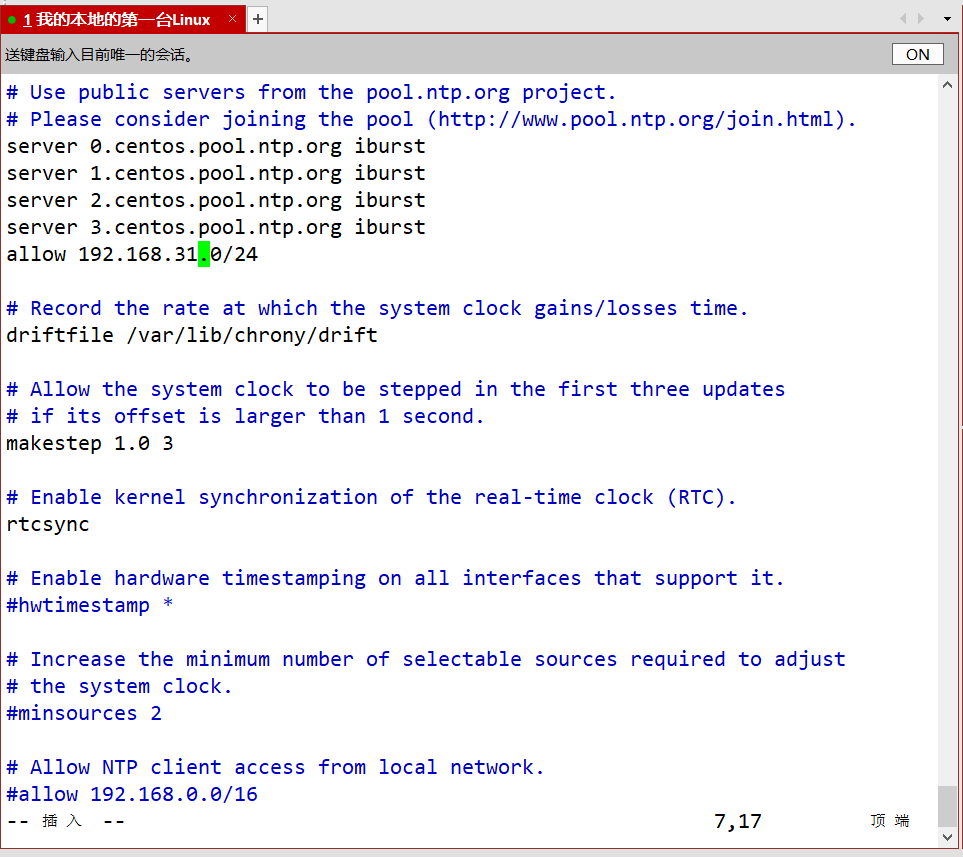
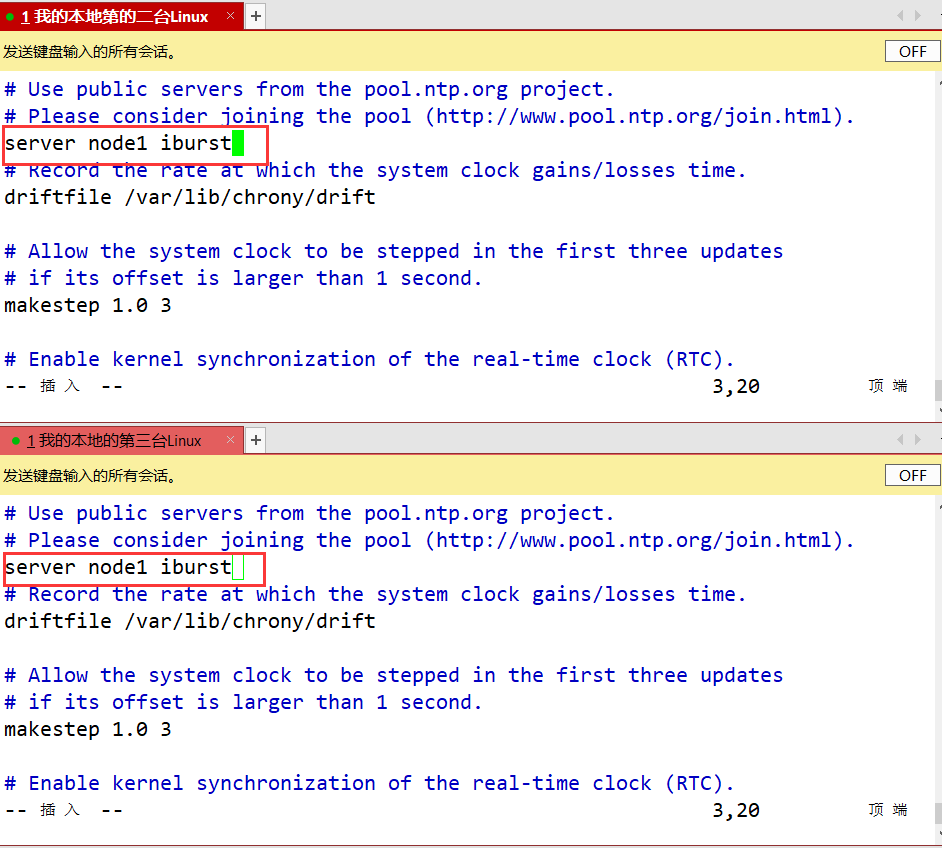
再配置两台从服务器
vim /etc/chrony.conf
就将3 - 6行的server删除后,添加一行server node1 iburst
开启服务
2、安装JDK
此处省略,如需请查看之前博客
3、安装Hadoop完全分布式
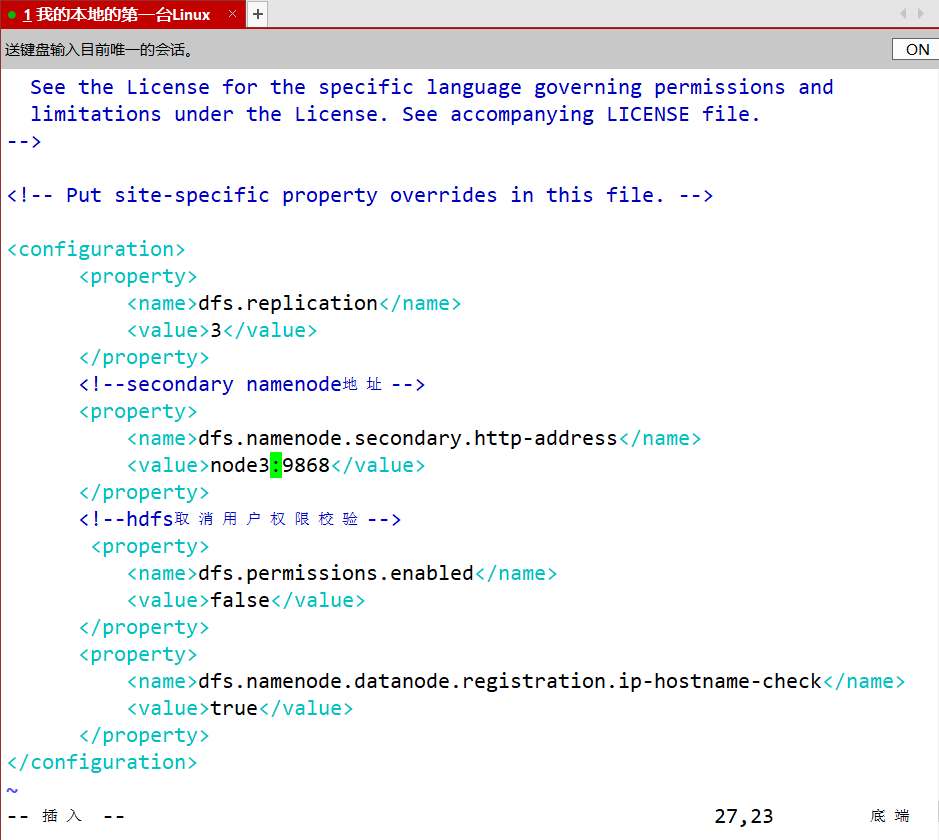
- hdfs.site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node3:9868</value>
</property>
<!--hdfs取消用户权限校验-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value> </property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>true</value>
</property>
</configuration>
- yarn.site.xml
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/opt/app/hadoop-3.1.4/etc/hadoop,
/opt/app/hadoop-3.1.4/share/hadoop/common/*,
/opt/app/hadoop-3.1.4/share/hadoop/common/lib/*,
/opt/app/hadoop-3.1.4/share/hadoop/hdfs/*,
/opt/app/hadoop-3.1.4/share/hadoop/hdfs/lib/*,
/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/*,
/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/lib/*,
/opt/app/hadoop-3.1.4/share/hadoop/yarn/*,
/opt/app/hadoop-3.1.4/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
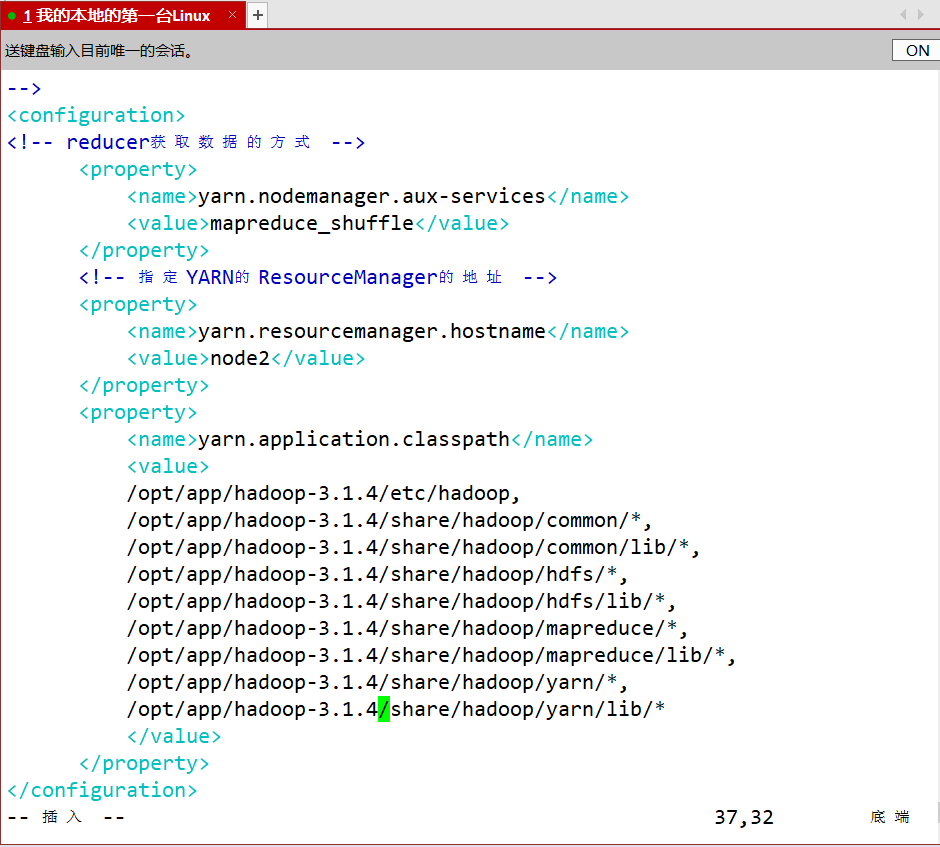
- mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
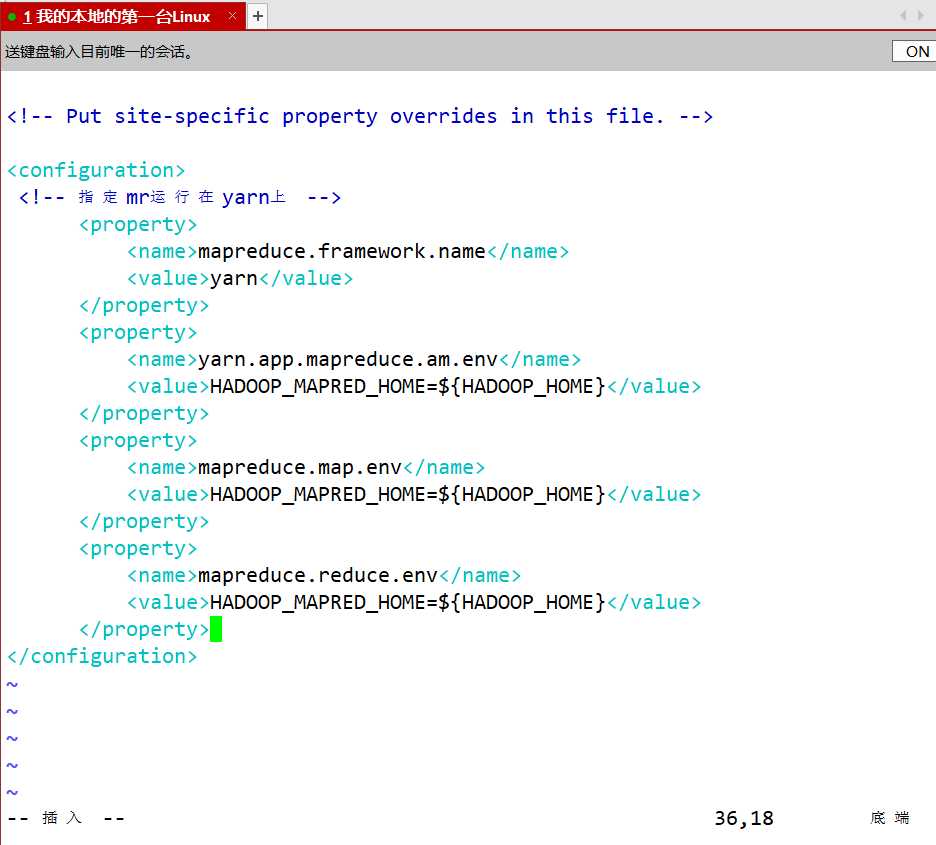
共需配置九个相关文件
然后将node1上的/opt/app发送到node2和node3节点上的/opt上
scp -r /opt/app root@node2:/opt
4、格式化HDFS
namenode所在节点格式化
hdfs namenode -format
5、启动HDFS和YARN
1、 HDFS是在namenode所在节点启动(node1)
2、YARN是在RM所在节点启动(node2)

![Nginx启动时提示nginx: [emerg] still could not bind()](https://img-blog.csdnimg.cn/1362a5dd74784b2195269c0b678984c5.png)