目录
环境:
一、mybatis-plus之sql分析日志输出
1.配置
2.验证
3.高级输出方式
二、业务日志输出到文件
1.添加log4j2依赖
2.排除logback依赖
3.新增log4j2的配置文件
4.添加配置
5.启动测试
6.给日志请求加个id
6.1、过滤器filter实现
6.2、测试
6.3、request_id检索方式
7.结束
环境:
jdk:1.8
springboot版本:2.7.15
mybatis-plus版本:3.5.3.2
一、mybatis-plus之sql分析日志输出
为了生产中更快的分析问题以及解决问题,sql输出是非常有必要的,这里第一步是将sql输出到控制台便于调试时分析问题,优化sql
1.配置
日志输出操作很简单,在application.yml中配置:
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl2.验证
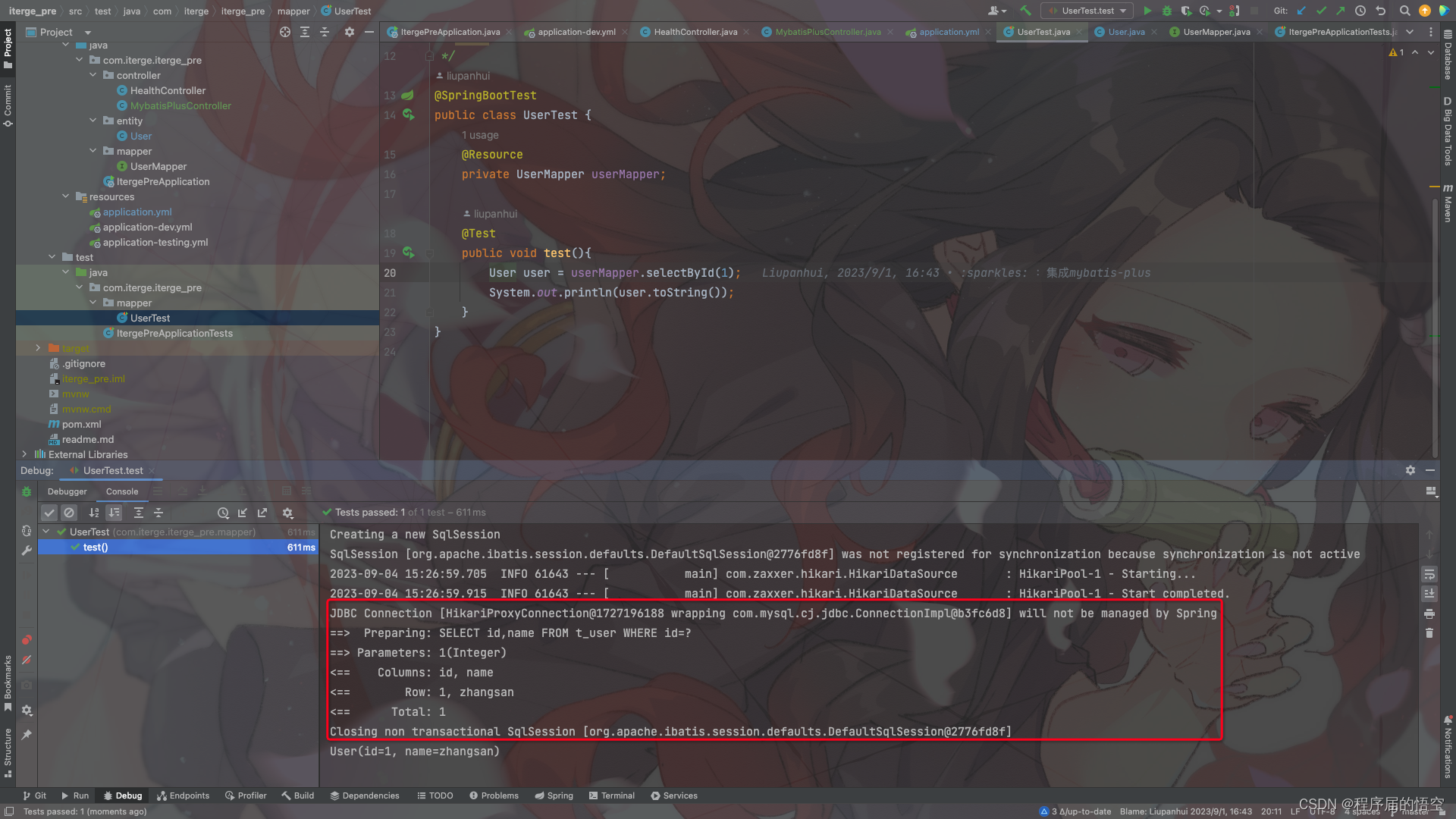
使用测试类进行测试,注意,本地调试可以使用这种方式打开日志,如果线上日志输出到文件,要用下面的高级输出方式
3.高级输出方式
使用数据库操作分析框架p6spy组件,进行sql分支,但是该组件比较消耗性能,生产环境中不建议使用,但是如果想玩玩的话,大家可以试试。
p6spy快速配置:p6spy快速配置
二、业务日志输出到文件
为什么要进行日志输出呢?
因为生产环境想要知道程序是否是按照我们的意愿正常运行的,通过日志输出是最直观最有效的方式。
日志文件输出我们一般常用日志输出框架有两种:一种是log4j2、另一种是logback。而springboot中默认使用的是logback框架,考虑到性能原因大多数生产环境使用日志框架为log4j2,所以这里也以log4j2框架进行整合和练习。
1.添加log4j2依赖
<!-- 引入log4j2依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<!-- 加上这个才能辨认到log4j2-*.yml文件 -->
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-yaml</artifactId>
</dependency>为何用jackson-dataformat-yaml包?问就是可读性好~,log4j2官方采用的是.xml,.json或者.jsn这种方式来做配置,我们既然使用了springboot那当然要用yml文件来配置了,而这个包就是为了程序启动时辨认log4j2-*.yml文件的。
2.排除logback依赖
<!-- 全局排除spring-boot-starter-logging相关所有依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
<exclusions>
<exclusion>
<groupId>*</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>3.新增log4j2的配置文件
Configuration:
#Configuration后面的status,这个用于设置log4j2自身内部的信息输出,可以不设置,当设置成trace时,你会看到log4j2内部各种详细输出
#日志级别以及优先级排序: ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
status: info
# 定义全局变量
Properties:
Property:
#日志存放路径
- name: log.path
value: /Users/liuph/dev/space/log/iterge_pre
#定义日志输出目的地,内容和格式等
Appenders:
# 控制台日志
Console:
name: console
target: SYSTEM_OUT
#输出日志的格式
PatternLayout:
Pattern: "[%X{request_id}] %-d{yyyy-MM-dd HH:mm:ss} - [%p] [%C{1}:%L %M] %m%n"
ThresholdFilter:
level: info
onMatch: ACCEPT
onMismatch: DENY
# 文件日志
RollingFile:
- name: iterge_pre
#日志存储路径
fileName: "${log.path}/info.log"
#历史日志封存路径 其中%d{yyyy-MM-dd}表示了日志的时间单位是天
filePattern: "${log.path}/iterge_pre_%d{yyyy-MM-dd}.log"
PatternLayout:
Pattern: "[%X{request_id}] %-d{yyyy-MM-dd HH:mm:ss} - [%p] [%C{1}:%L %M] %m%n"
#归档设置
Policies:
#按时间间隔归档
TimeBasedTriggeringPolicy:
#时间间隔 单位由filePattern的%d日期格式指定, 此处配置代表每一天归档一次
interval: 1
#是否对interval取模,决定了下一次触发的时间点
modulate: true
#按照日志文件的大小: size表示当前日志文件的最大size,支持单位:KB/MB/GB
#SizeBasedTriggeringPolicy:
#size: 50MB
ThresholdFilter:
level: info
onMatch: ACCEPT
onMismatch: DENY
Loggers:
Root:
level: info
#关联的Appender, 只有定义了logger并引入的appender,appender才会生效
AppenderRef:
- ref: console
- ref: iterge_pre
4.添加配置
在配置文件中添加需要生效的log4j2的配置信息,我这里生效的配置文件是application-dev.yml,所以我在application-dev.yml中加入以下配置代码:
#这里配置日志生效文件,用于多环境部署时切换(通常部署会有三个环境:线上、测试、开发)
logging:
config: classpath:log4j2/log4j2-dev.yml项目配置文件目录:
5.启动测试

如上图:日志打印格式已经按照我们配置的打印了,这里大家可能问这个“[]”是什么含义?接着往下看。
6.给日志请求加个id
为什么给日志请求加个id?这里当然是为了方便了,举个例子:当你在线上查询问题时,一段代码你你可能加了10个日志输出点,而线上业务日志又有很多的情况下,你难道要一行一行的检索日志来看吗?这时候当然请求id检索更香啊!
6.1、过滤器filter实现
新建过滤器LogTraceFilter,代码中的“request_id”要和log4j2的配置文件中设置的一致!!!
(这里通过拦截器实现也是可以的)
@WebFilter(filterName = "LogTraceFilter", urlPatterns = "/*")
@Component
public class LogTraceFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
MDC.put("request_id", UUID.randomUUID().toString().replace("-", ""));
filterChain.doFilter(servletRequest, servletResponse);
MDC.remove("request_id");
}
}6.2、测试
controller代码:
@GetMapping("/test/get")
public User getUser(Integer id){
log.info("请求入参:{}",id);
User user = userMapper.selectById(id);
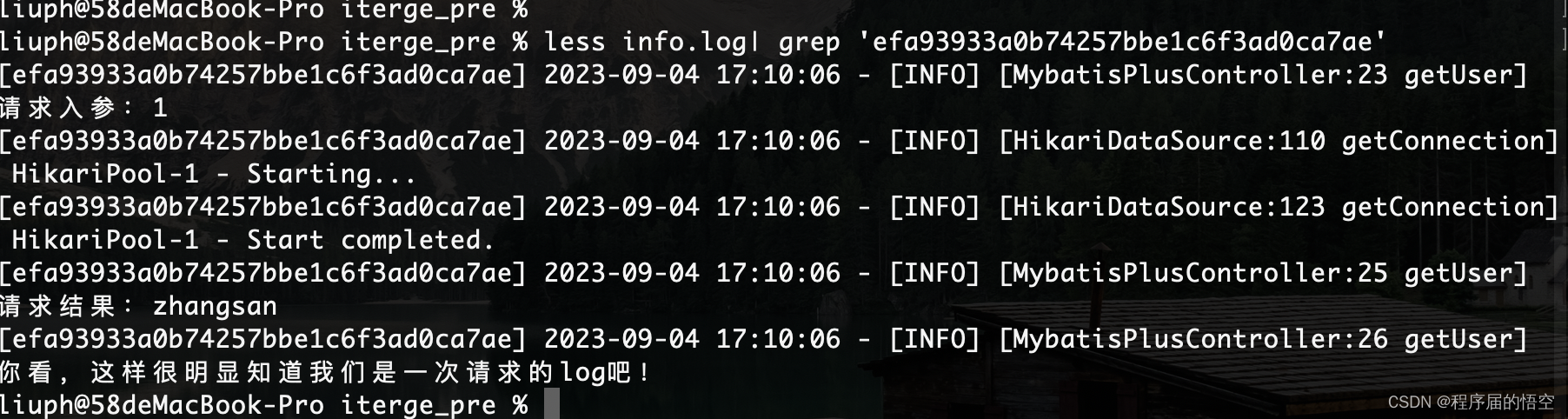
log.info("请求结果:{}",user.getName());
log.info("你看,这样很明显知道我们是一次请求的log吧!");
return user;
}运行结果:

由此可以看出同一个请求的日志id都是相同的。
6.3、request_id检索方式