前言
本篇博客基于 C++ - 继承_chihiro1122的博客-CSDN博客 之上列出一些例子,如果有需要请看以上博客。
继承的例子
例1

上述例子应该选择 C。
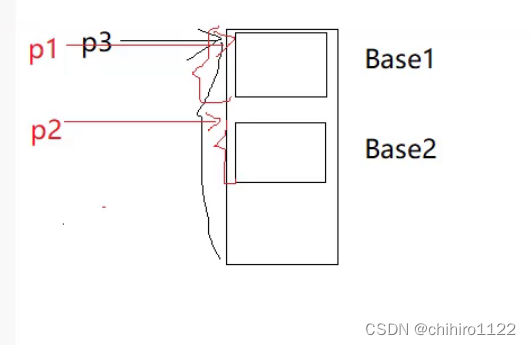
首先不用说,p3肯定是指向 d 对象的开头的;p1 也是指向 d 对象的开头的;
不同的是,p3 指向开头,p3 看到的是整个 d 对象; 而 p1 指向开头,p1 的类型是 base1* 指针的类型决定了这个指针能看多大的空间,p1 只能看 base1 个对象大的空间,那么 p1 只能看到 构造d对象之前,最先构造的 Base1 父类对象。(p1 是经典的切片)
对于 p2 ,它指向的是 在 Base1 父类对象之后创建的 Base2 父类对象的开头位置,因为 Base2 父类对象不在 &d 这个位置,但是 p2 指针的类型是 Base2* ,所以要发生偏移,指向 Base2 父类对象的开头。(p2 同样的是 切片)
具体指向如下所示:
现在我们再对上述题目进行修改,上述的 子类继承是先继承 Base1 再继承 Base2;现在我们先继承 Base2,再继承 Base1:
class Derrive : public Base2, public Base1 { public : int _d };这时候结果就不一样了,是 p2 和 p3 指向 d 对象的开头;而 p1 指向中间的 base1;
这是因为 子类在构造的时候,要先构造父类对象,而如果是多继承,就要继承的先后顺序去构造父类。
例2

上述题目,如果按照继承当中构造顺序的话(先构造父类对象,在构造子类对象),按道理 打印的是 abacad(a 代表的是 class A,以此类推)。如果这样想的话就步入误区了。
但是打印结果却是:
class A
class B
class C
class D
我们主要注意, D的构造函数当中的初始化列表:
D(const char* s1, const char* s2 , const char* s3, const char* s4)
:B(s1,s2), C(s1 , s3) , A(sa)这里的初始化列表不是先走 B 的构造,而是 A的构造;之前也说过,构造函数当中初始化列表,不是按照初始化列表的顺序初始化,而是按照声明的顺序来初始化成员。
在上述A是写在最前面的,A 就是最先声明的,就要最先被初始化(构造)。
然后再去走 B 的构造,在 B 的构造函数的初始化列表当中也有 A(s1),但是此时不会去走,因为 A(s1) 在第一步 D 的构造函数当中就已经构造了,所以就不会去走 A(s1) 这一步构造。这里是菱形继承衍生出来的编译器自己处理的结果。
以此类推,菱形继承除了之前说过的坑之外,还有很多的坑,上述就是其一,所以我们在写代码的时候要尽量避免写出菱形继承的结构。
既然在 B 和 C的构造函数的初始化列表当中的 A(s1) 不会构造,那么能不能去掉呢?
当然是不能的。因为,上述例子只是 基于 D 子类的构造的菱形继承当中没有用到,但是如果只是 B 和 C 单独的构造,就可能需要用到 A(s1)了。
为什么说是可能需要呢?因为 A 基类当中是实现了 构造函数的 ,而且这个构造函数不是默认构造函数,如果不调用编译器不会自动调用;当然如果A 的构造函数当中有默认构造函数,可以不调用。
例3
其实在官方库当中,官方就自己使用了 菱形继承这个坑,在 io 输入输出流 的库当中,就有使用了菱形继承:
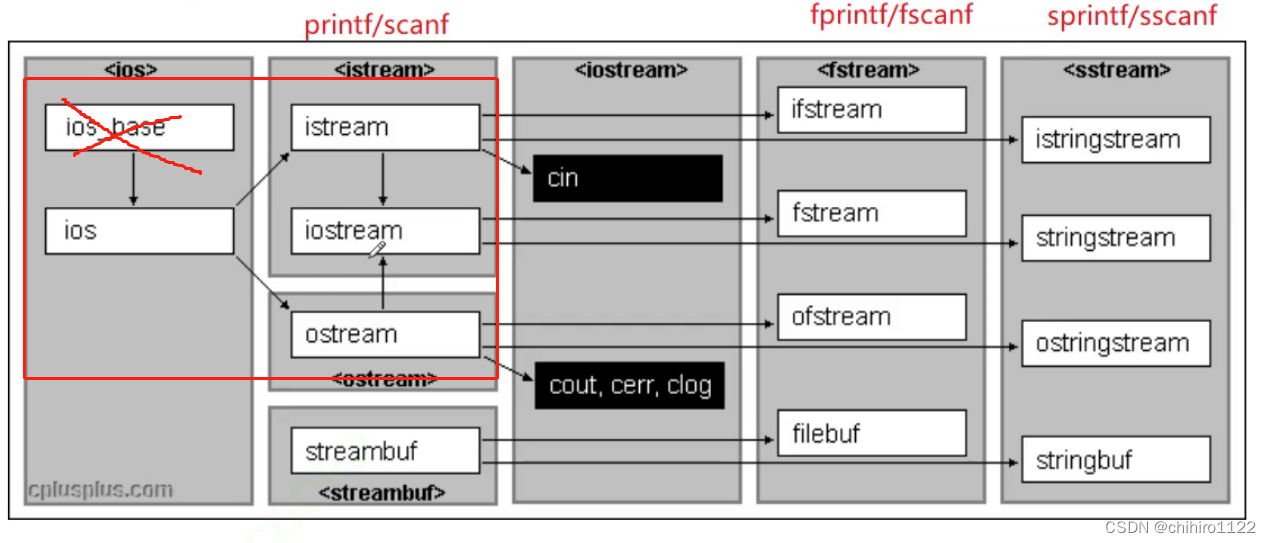
上述的 iostream 当中有些功能上想使用 istream 和 ostream 两个类当中的某些功能,就直接继承了 istream 和 ostream 这两个类。但是这个两个类 都继承了 ios 这个基类,此处就构成了 菱形继承。
虽然是菱形继承,我们在使用上还是没有问题的。
但是不是代表建议我们在需要的时候首先考虑菱形继承,菱形继承不到万不得已建议是不要使用的。
组合 和 继承
什么是组合
所谓组合就是把多个类组合在一起,当我们在一个类的成员当中,定义了一个或多个其他类的对象成员,那么这个类就和其他类构成了组合的关系。如下所示:
class A
{
// 成员变量 成员函数
};
class B
{
private:
A _aa; // 有A类对象的成员
}向上述的 A 类和B类就构成了组合关系,只要构造了 B类对象,就会在其中构造出 A类对象成员出来。
那么组合和继承都可以实现相同的效果,那么两者有什么区别呢?
继承和组合的区别
我们通常称 继承是 白箱复用;而组合是 黑箱复用;
这里的 “白” 和 “黑”,分别指的是 “看得见” 和 “看不见” 的意思。
这里就不得不衍生出两种测试了:
- 黑盒测试:测试人员看不见目标的内部实现,测试人员根据功能对目标进行测试。
- 白盒测试:测试人员可以看见目标的内部实现,测试人员根据目标的内部实现去写测试用例。
上述两种测试我们显而易见的发现,白盒测试相对于黑盒测试更加严格,在测试上也更加困难。
那么上述的 白箱复用 和 黑箱复用 也是一样的,都是看得见和看不见的问题。
如上述例子,在 B 当中组合了 A,那么 A 当中 public 修饰的成员变量 和 成员函数 都可以在 B 当中 使用 和 修改,但是 例如 private 修饰的,保护起来的 成员 就不能再 B 当中使用和 修改了,除非使用有元函数等等 ,突破权限的操作。这就是 黑箱复用。
那么 组合 和 继承的 区别也就显而易见了。
继承 和 组合 的好处和坏处
继承 当中 基类的内部实现细节 子类是可见的,这在一定程度上破坏了 我们对基类的封装。而且因为是子类直接继承父类当中的成员的关系,如果父类当中某一成员变量 或 成员函数发生了改变,这一改变对其子类的影响是很大的。对于继承来说,基类和其派生类之间的依赖关系很紧,两者之间的耦合度高。
对象组合 是 类继承之外的一种复用选择,组合同样可以实现继承的功能,但是组合对 被组合 的对象(如上述的A类)要求是有良好定义的接口。而且组合的耦合性更低。
假设 A类 当中有 100个成员,20个公有成员,80 个 私有/保护成员。对于继承来说,修改 A类 当中 100个成员当中的任意一个都会对 其派生类 B类有影响;但是对于组合来说,只要不修改 20个公有成员,对 B类影响都不大。对于组合来说 公有的越少,耦合度就越低,但是对于继承来说不管公有多少个,两者都有很大的耦合度。
在现实编程当中,我们尽量能使用组合就使用组合,因为组合的耦合度低,而且也可以达到继承的功能;但是不能为了使用组合而使用组合,因为继承还是有很多适用场景的,适合用继承就使用继承,而且多态的使用是必须使用继承的,组合是不能实现多态的。
那么现实当中我们该如何更好的分辨我们该如何使用 组合 和 继承呢?
其实,public:继承,是一种 is-a 的关系,is-a 意思是:一个子类就是一个父类; 比如:一个老师是一个人,一个学生也是一个人·····
而 组合 是一种 has-a 的关系,has-a 意思是:假设B组合了A,那么每一个 B 对象当中都有一个 A 对象。