企业场景篇
设计模式
简单工厂模式
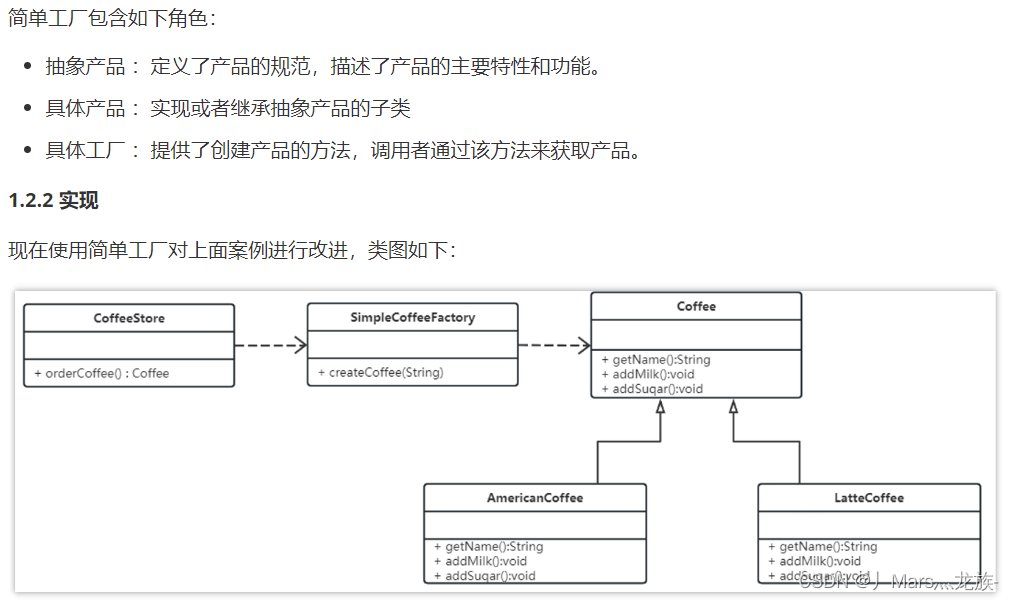
工厂(factory)处理创建对象的细节,一旦有了SimpleCoffeeFactory,CoffeeStore类中的orderCoffee()就变成此对象的客户,后期如果需要Coffee对象直接从工厂中获取即可。这样也就解除了和Coffee实现类的耦合,同时又产生了新的耦合,CoffeeStore对象和SimpleCoffeeFactory工厂对象的耦合,工厂对象和商品对象的耦合。
后期如果再加新品种的咖啡,我们势必要需求修改SimpleCoffeeFactory的代码,违反了开闭原则。工厂类的客户端可能有很多,比如创建美团外卖等,这样只需要修改工厂类的代码,省去其他的修改操作。
工厂方法模式
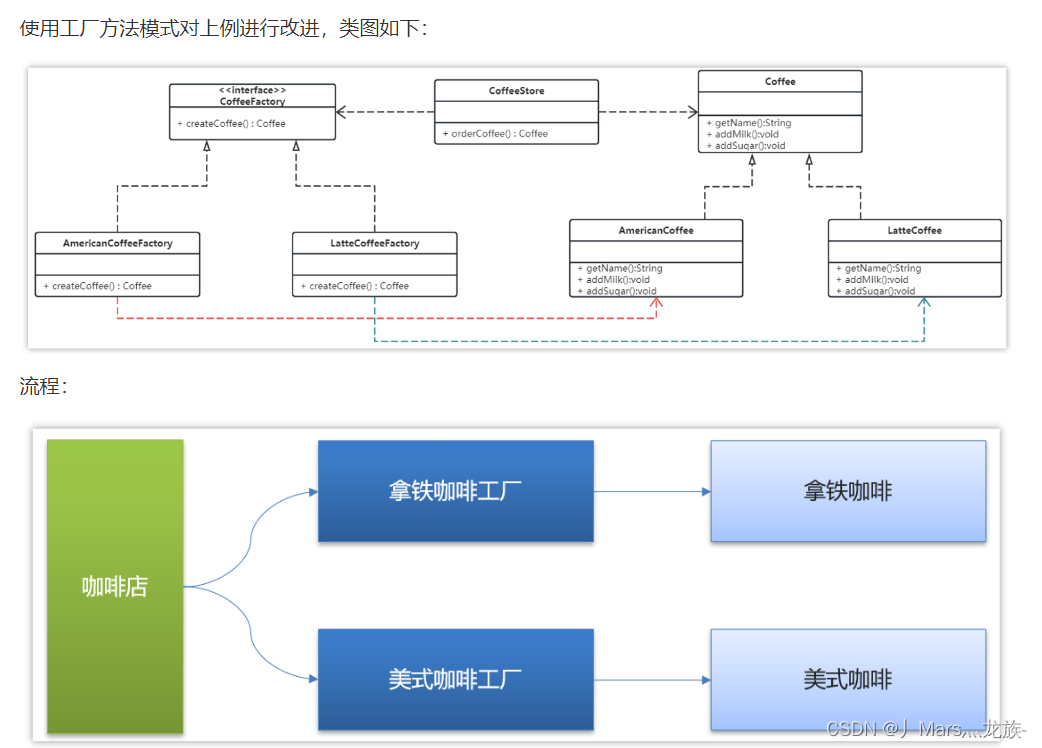
要增加产品类时也要相应地增加工厂类,不需要修改工厂类的代码了,这样就解决了简单工厂模式的缺点。
工厂方法模式是简单工厂模式的进一步抽象。由于使用了多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
优点:
- 用户只需要知道具体工厂的名称就可得到所要的产品,无需知道产品的具体创建过程;
- 在系统增加新的产品时只需要添加具体产品类和对应的具体工厂类,无须对原工厂进行任何修改,满足开闭原则;
缺点:
- 每增加一个产品就要增加一个具体产品类和一个对应的具体工厂类,这增加了系统的复杂度。
抽象工厂模式
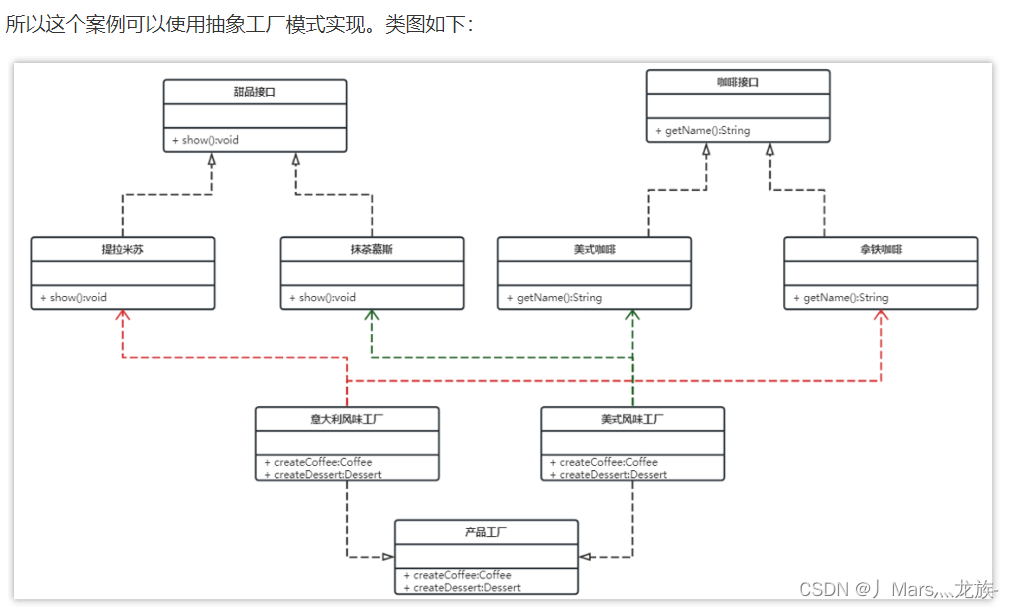
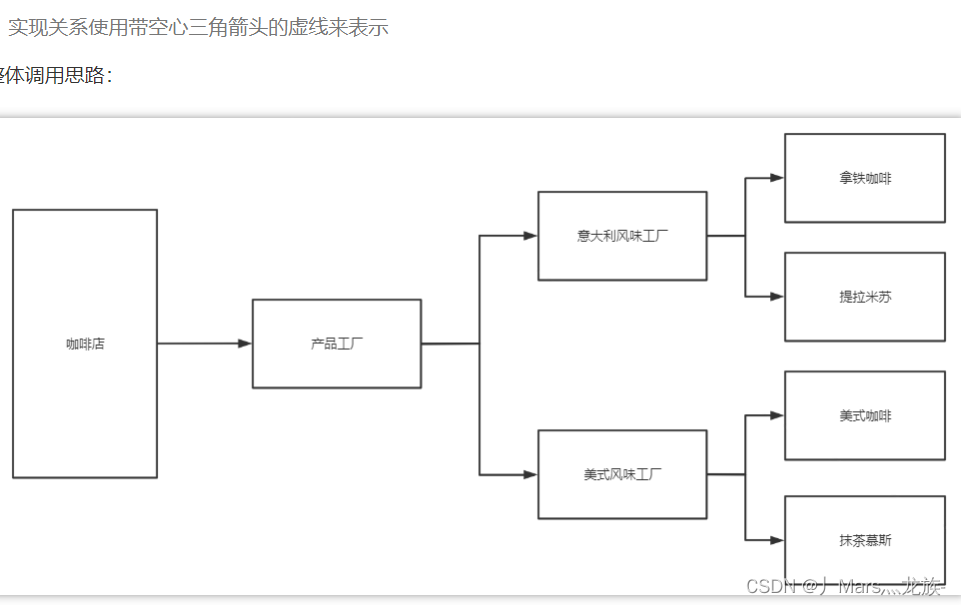
优点:
当一个产品族的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点:
当产品族中只需要增加一个新的产品时,所有的工厂类都需要进行修改。
使用场景
- 当需要创建的对象是一系列相互关联或相互依赖的产品族时,如电器工厂中的电视机、洗衣机、空调等。
- 系统中有多个产品族,但每次只使用其中的某一族产品。如有人只喜欢穿某一个品牌的衣服和鞋。
- 系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
如:输入法皮肤,一整套一起换。生成不同操作系统的程序。
策略模式
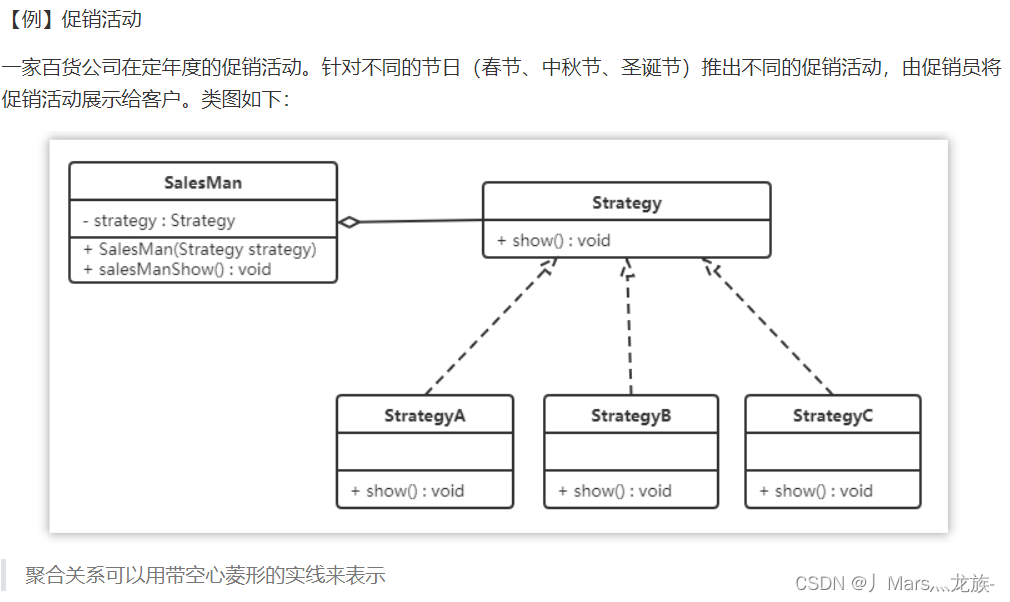
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
综合案例

如果后期有新的需求改动,比如加入了QQ登录,我们只需要添加对应的策略就可以,无需再改动业务层代码。
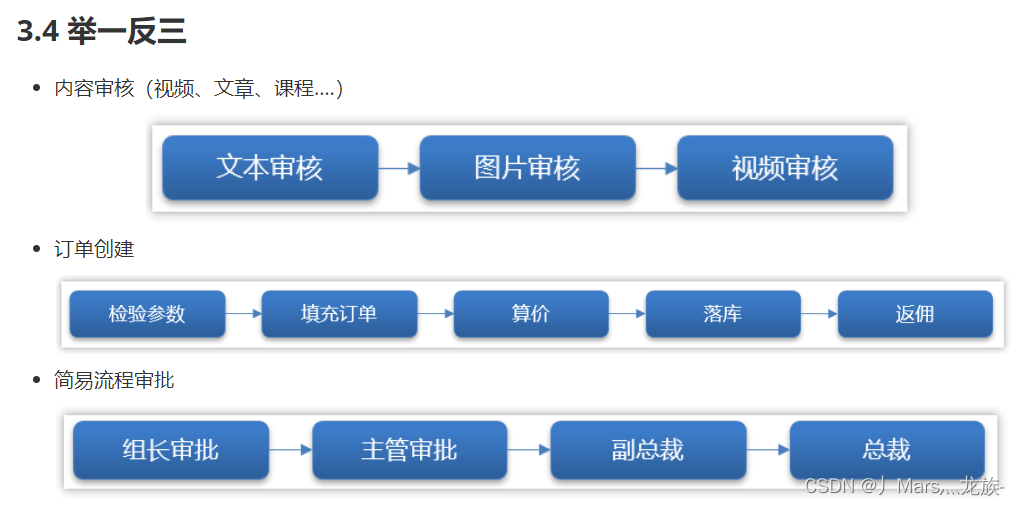
其实像这样的需求,在日常开发中非常,常见场景有很多,以下的情景都可以使用工厂模式+策略模式解决比如:
- 订单的支付策略
- 支付宝支付
- 微信支付
- 银行卡支付
- 现金支付
- 解析不同类型excel
- xls格式
- xlsx格式
- 打折促销
- 满300元9折
- 满500元8折
- 满1000元7折
- 物流运费阶梯计算
- 5kg以下
- 5kg-10kg
- 10kg-20kg
- 20kg以上
一句话总结:只要代码中有冗长的 if-else 或 switch 分支判断都可以采用策略模式优化
责任链模式
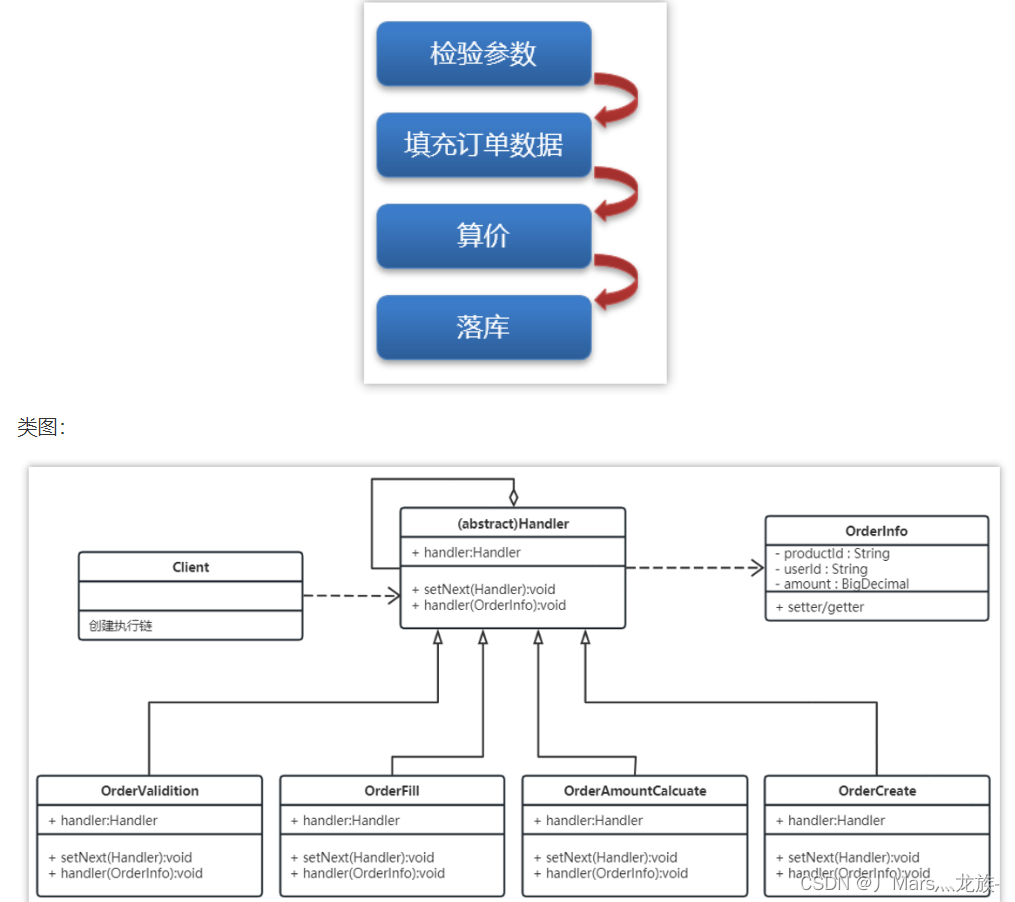
优点
-
降低了对象之间的耦合度
-
增强了系统的可扩展性
-
增强了给对象指派职责的灵活性
-
责任链简化了对象之间的连接
-
责任分担
缺点:
- 不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
- 对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
技术场景
单点登录这块怎么实现的
面试官: 单点登录这块怎么实现的?
候选人:
-
先解释什么是单点登录—单点登录的英文名叫做:Single Sign Sn(简称SSO)
-
介绍自己项目中涉及到的单点登录(即使没涉及过,也可以说实现的思路)
-
介绍单点登录的解决方案,以JWT为例
I.用户访问其他系统,会在网关判断token是否有效
II.如果token无效则会返回401(认证失败),前端跳转到登录页面
III.用户发送登录请求,返回浏览器一个token,浏览器把token保存到cookie
IV. 再去访问其他服务的时候,都需要携带token,由网关统一验证后路由到目标服务
权限认证是如何实现的
面试官: 权限认证是如何实现的?
候选人:
- 后台管理系统的开发经验
- 介绍RBAC权限模型5张表的关系(用户、角色、权限)
- 权限框架:Spring security(推荐)、Apache Shiro
上传数据的安全性你们怎么控制
面试官: 上传数据的安全性你们怎么控制?
候选人:
使用非对称加密(或对称加密),给前端一个公钥让他把数据加密后传到后台,后台负责解密后处理数据
- 文件很大建议使用对称加密,不过不能保存敏感信息
- 文件较小,要求安全性较高,建议使用非对称加密
遇到了哪些棘手的问题,怎么解决的
面试官: 你负责项目的时候遇到了哪些棘手的问题,怎么解决的?
候选人:
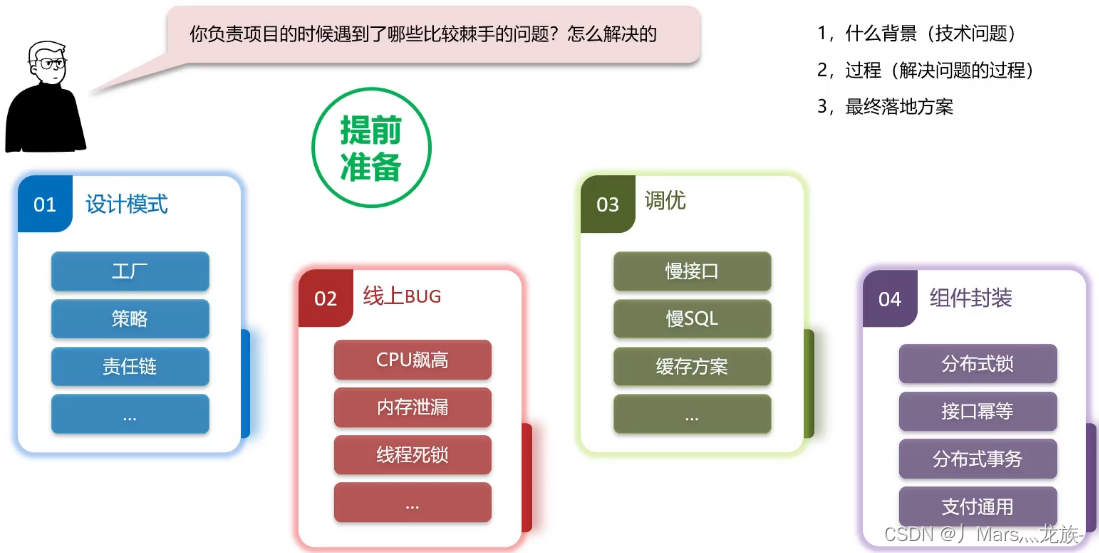
01举例:
①:介绍登录业务(一开始没有用设计模式,所有的登录方式都柔和在一个业务类中,不过,发现需求经常改)
②:登录方式经常会增加或更换,每次都要修改业务层代码,所以,经过我的设计,使用了工厂设计模式和策略模式,解决了经常修改业务层代码的问题
③:详细介绍一下工厂模式和策略模式(参考前面设计模式的课程)
02举例:
回答方式参考上面的回答思路,具体问题可以参考前面的课程(JVM和多线程相关的面试题)
你们项目中日志怎么采集的
面试官: 你们项目中日志怎么采集的?
候选人:
我们搭建了ELK日志采集系统:
- Elasticsearch是全文搜索分析引擎,可以对数据存储、搜索、分析
- Logstash是一个数据收集引擎,可以动态收集数据,可以对数据进行过滤、分析,将数据存储到指定的位置
- Kibana是一个数据分析和可视化平台,配合Elasticsearch对数据进行搜索,分析,图表化展示
常见日志的命令
面试官: 常见日志的命令?
候选人:
-
实时监控日志的变化
实时监控某一个日志文件的变化:tail -f xx.log;实时监控日志最后100行日志: tail –n 100 -f xx.log
-
按照行号查询
-
查询日志尾部最后100行日志:tail – n 100 xx.log
-
查询日志头部开始100行日志:head –n 100 xx.log
-
查询某一个日志行号区间:cat -n xx.log | tail -n +100 | head -n 100 (查询100行至200行的日志)
-
-
按照关键字找日志的信息
查询日志文件中包含debug的日志行号:cat -n xx.log | grep “debug”
-
按照日期查询
sed -n '/2023-05-18 14:22:31.070/,/ 2023-05-18 14:27:14.158/p’xx.log
-
日志太多,处理方式
-
分页查询日志信息:cat -n xx.log |grep “debug” | more
-
筛选过滤以后,输出到一个文件:cat -n xx.log | grep “debug” >debug.txt
-
生产问题怎么排查
面试官: 生产问题怎么排查?
候选人:
已经上线的bug排查的思路:
- 先分析日志,通常在业务中都会有日志的记录,或者查看系统日志,或者查看日志文件,然后定位问题
- 远程debug(通常公司的正式环境(生产环境)是不允许远程debug的。一般远程debug都是公司的测试环境,方便调试代码)
怎么快速定位系统的瓶颈
面试官: 怎么快速定位系统的瓶颈?
候选人:
- 压测(性能测试),项目上线之前测评系统的压力
- 压测目的:给出系统当前的性能状况;定位系统性能瓶颈或潜在性能瓶颈
- 指标:响应时间、 QPS、并发数、吞吐量、 CPU利用率、内存使用率、磁盘IO、错误率
- 压测工具:LoadRunner、Apache Jmeter …
- 后端工程师:根据压测的结果进行解决或调优(接口慢、代码报错、并发达不到要求…)
- 监控工具、链路追踪工具,项目上线之后监控
- 监控工具: Prometheus+Grafana
- 链路追踪工具:skywalking、Zipkin
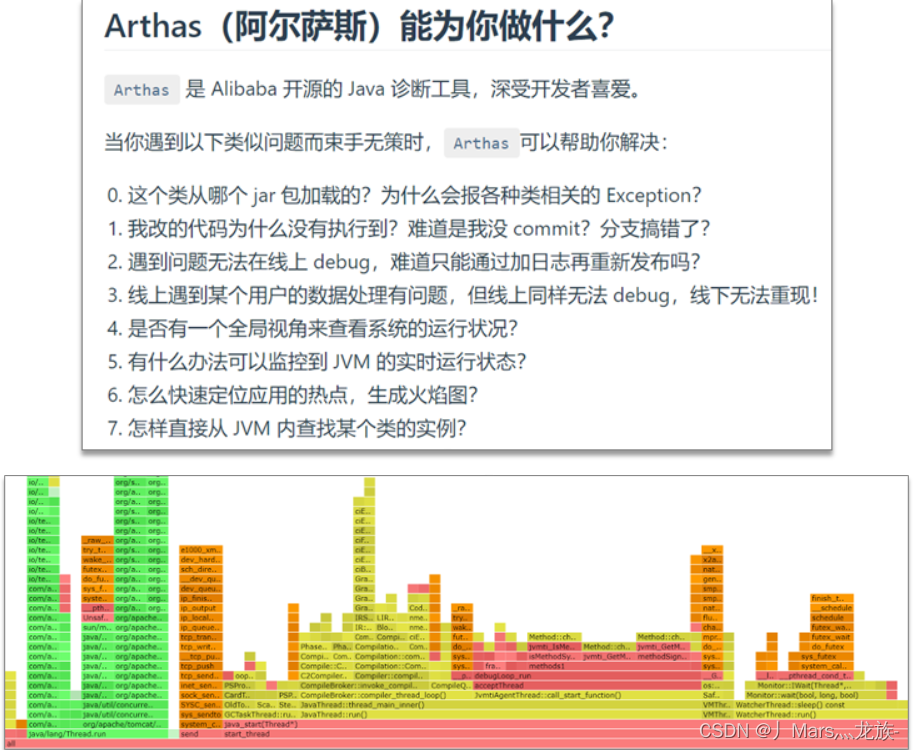
- 线上诊断工具Arthas(阿尔萨斯),项目上线之后监控、排查
- 官网:https://arthas.aliyun.com/
- 核心功能: