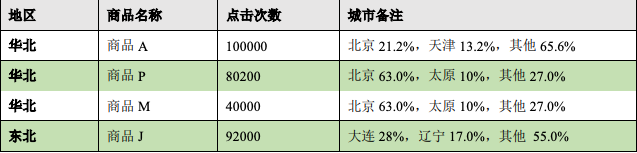
需求如下:当写入SQL语句中有任意一个字段在数据库中存在时,不可写入,并返回具体的重复字段。
使用Java Steam处理数据集循环执行SQL需要多次执行SQL,适合单条件索引的情况下使用,现状是想执行少量的SQL实现需求,固出现以下SQL思路,欢迎讨论。
模拟需求如下:当id和name有任意一个名称重复的情况下,不可写入,并返回是id重复或者name重复。
建表SQL 模拟四条数据:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for sys_user
-- ----------------------------
DROP TABLE IF EXISTS `sys_user`;
CREATE TABLE `sys_user` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of sys_user
-- ----------------------------
INSERT INTO `sys_user` VALUES (1, 'name1');
INSERT INTO `sys_user` VALUES (2, 'name2');
INSERT INTO `sys_user` VALUES (3, 'name3');
INSERT INTO `sys_user` VALUES (4, 'name4');
SET FOREIGN_KEY_CHECKS = 1;
实现思路:
使用count计算出符合or条件的命中数量,通过命中数量判断具体哪个字段命中,有可能出现多字段同时命中的情况,通过程序判断命中优先级,返回前端即可。
第一种情况:单条件命中,模拟SQL如下:
select
count(case when `name` = "name1" then 1 end ) as 命中name数量,
count(case when `id` = "5" then 1 end) as 命中id数量
from sys_user where `name` = "name1" or `id` = "5"
执行结果:
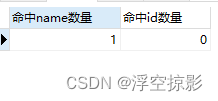
命中name1,id为5不存在,命中为0,符合预期。
第二种情况:多条件命中,模拟SQL如下:
select count(case when `name` = "name1" then 1 end ) as 命中name数量,
count(case when `id` = "4" then 1 end) as 命中id数量
from sys_user where `name` = "name1" or `id` = "4"
执行结果:

name4命中,id为4命中。由程序通过字段优先级判断返回校验结果。
第三种情况:无条件命中,模拟SQL如下:
select count(case when `name` = "name5" then 1 end ) as 命中name数量,
count(case when `id` = "5" then 1 end) as 命中id数量
from sys_user where `name` = "name5" or `id` = "5"
执行结果:

name5无命中,id为5无命中。校验通过即可。
这种SQL推荐OR条件涉及到的字段都要使用索引,否则数据量大之后效率低下。




![[强网杯 2019]Upload](https://img-blog.csdnimg.cn/91730e9a762e42f9bd84048ef1d4c09d.png)