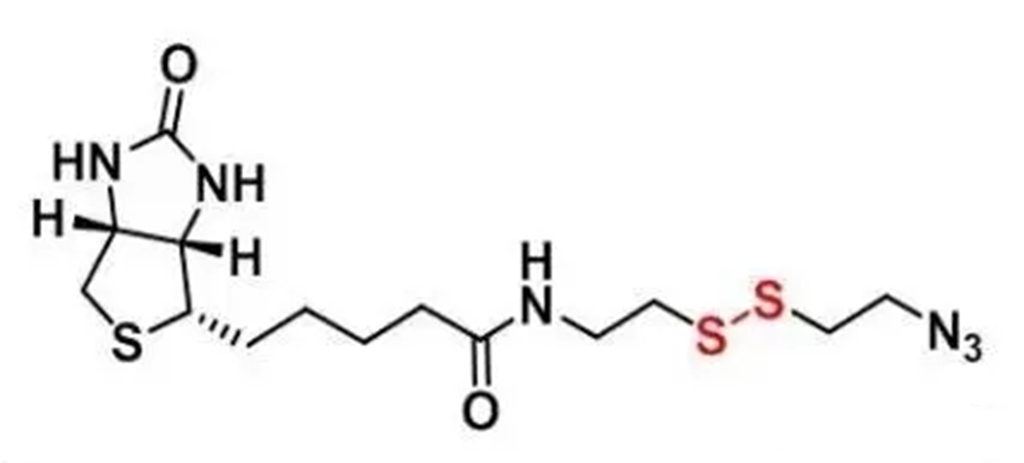
论文地址:https://onlinelibrary.wiley.com/doi/full/10.1002/rob.21609?saml_referrer
(机翻,自己保存观看的)
Abstract:
野外自动驾驶陆地车辆(ALV)的负障碍是指沟渠、坑或具有负坡度的地形,这会给行驶中的车辆带来风险。 本文提出了一种基于特征融合的算法 (FFA),用于使用 LiDAR 传感器进行负障碍物检测。 本文的主要贡献有四个方面:(1) 提出了一种新颖的三维 (3-D) LiDAR 设置。 通过这种设置,车辆周围的盲区大大减少,LiDAR 数据的密度大大提高,这对 ALV 至关重要。 (2) 在提出的设置的基础上,推导了单条扫描线点分布的数学模型,用于生成理想扫描线。 (3) 利用数学模型,提出了一种基于自适应匹配滤波器的算法(AMFA)来实现负障碍物检测。 利用每条扫描线上模拟障碍物的特征来检测真实的负障碍物。 它们应该与潜在的真实障碍物的特征相匹配。 (4)在AMFA算法的基础上,提出了一种基于特征融合的算法。 FFA 算法融合了不同 LiDAR 生成或在不同帧捕获的所有特征。 采用贝叶斯法则估计每个特征的权重。 实验结果表明,该算法具有鲁棒性和稳定性。 与最先进的技术相比,检测范围提高了 20%,计算时间减少了两个数量级。 所提出的算法已成功应用于两辆ALV,在中国“克服危险2014”地面无人车挑战赛中获得冠亚军。
1. Introduction:
野外自主陆地车辆 (ALV) 是一种无需人工指导即可在野外环境中执行所需任务的机器人。 为了安全驾驶,车辆应尽可能检测到正面和负面障碍物(Zhou et al., 2012)。 障碍物检测和地形分析已经引起了很多关注(Shang, Li, Ye, & He, 2013; Chen Tongtong, Dai Bin, & Daxue, 2013),但仍然很少有 ALV 能够在野外环境中良好行驶。 积极的障碍物检测问题被广泛研究,并且出现了许多杰出的检测算法(Pedro Santana&Barata,2010)。 车辆负障碍是指沟渠、坑坑洼洼或具有负坡度的地形,这些都是行车中的危险因素。 由于其负面特性,从远处进行负面障碍物检测仍然是一个很大的挑战:因为负面障碍物在地面以下,因此很难被车辆的传感器看到。
根据任务中使用的传感器,负面障碍物检测在文献中通常分为三种主要类型。 在第一种中,使用了红外热像仪。 在第二种情况下,引入两个相机来创建三维 (3-D) 立体视觉 (Wu & He, 2011)。 在第三类中,激光雷达被用于正障碍物检测和负障碍物检测(Larson & Trivedi, 2011; Heckman, Lalonde, Vandapel, & Hebert, 2007)。
在传统的障碍物检测方法中(Thrun et al., 2006; Kammel et al., 2008),LiDAR 数据首先被映射到网格地图上(为了将 3-D 点云缩减为 2.5-D 地图),在 在每个网格中计算并标记最大值、最小值和中值。 通过比较标记值或分析相邻网格之间的关系,可以检测每个网格单元中的潜在障碍物。 然而,在野外环境中,地形可能并不平坦,机载传感器只能看到负面障碍物的一小部分。 网格图中负障碍物的深度不会很突出。 因此,传统的基于网格图的方法不足以在野外环境中进行检测。 本文采用同一扫描线上相邻扫描点之间的关系。 有两个好处:第一,相邻扫描点之间的关系不会受到地面高低不平的影响; 其次,该算法不是从整个网格地图中检测障碍物,而是降低了计算复杂度。
本文提出了一种基于 LiDAR 特征融合的算法 (FFA) 来实现野外 ALV 的负障碍物检测。 首先,提出了一种新颖的 LiDAR 设置方法:两个紧凑型 3-D LiDAR 安装在车顶两侧,如图 1 所示。所提出的新设置有两个优点:(1) 车辆周围的盲区 大大降低,这对于在狭窄道路上行驶或转弯的野外ALV非常重要。 (2) 与传统直立设置相比,LiDAR 数据密度大大提高,非常有利于检测正负障碍物。 基于新颖的设置,推导了单条扫描线的点分布的数学模型。 然后,在数学模型上提出了两种负障碍物检测算法,一种基于自适应匹配滤波器的算法(AMFA)和一种基于特征融合的算法。 实验结果表明,所提算法是有效和可靠的。 该算法已成功应用在中国“克服危险2014”地面无人车挑战赛的两辆ALV上,分别获得冠军和亚军(图1为我们夺冠的ALV,背景为挑战现场 ).

图一:在我们的 ALV 平台上建议的 3-D 激光雷达设置:两个紧凑型 HDL-32 激光雷达以相同的固定角度安装在车辆顶部的两侧(用红色圆圈标记); 另一台HDL-64 LiDAR直立安装在车顶中间位置进行对比(蓝色圆圈标注)。 该车在中国“克服危险2014”地面无人车挑战赛中获得冠军,背景为挑战现场。
本文的其余部分安排如下。 第 2 节回顾了一些关于负面障碍物检测的相关工作。 第 3 节讨论了传统设置的缺点,并描述了所提出的设置方法的细节。 第四节推导了单条扫描线点分布的数学模型,用于生成理想扫描线来模拟真实扫描线。 在第 5 节中,提出了 AMFA。 在第6节中,基于AMFA算法,引入FFA来提高检测性能。 在第 7 节中,实验结果表明所提出的算法具有鲁棒性和稳定性。 第 8 节总结了本文。
2. RELATED WORKS
负障碍物检测是现场ALV中的关键模块,受到了广泛关注。 如介绍中所述,始终执行三种方式来实现负障碍物检测。 第一个是使用红外热像仪 (Matthies & Rankin, 2003)。 原则是负障碍物在夜间往往比周围地形温暖。 通过检测热图像中较暖的区域,可以检测到潜在的负面障碍物。 局限性在于它只能在夜间工作,而且地形温度往往会受到天气条件的影响 (A. Rankin & Matthies, 2007)。 此外,障碍物附近的动物或树叶等生物体也可能导致温度升高。
第二种方法是从图像或立体视觉中分析负障碍物的几何特征。 论文 (Wu & He, 2011) 提出了一种基于图像序列的负障碍物检测算法,其中颜色外观模型和几何线索都被提取用于检测。 在该算法中,当负面障碍物远离车辆时,颜色外观模型被用作检测的主要线索; 当负面障碍物靠近时,从立体视觉中提取几何线索进行检测。 论文 (Fazli, Dehnavi, & Moallem, 2011) 还开发了一种基于立体视觉技术的负障碍物检测计算机视觉算法。 基于视觉的算法的局限性在于相机很容易被照明干扰。 另外,野外环境的复杂纹理会给图像的特征检测带来很大的麻烦。
最近激光雷达被广泛应用于障碍物检测,因为它们可以准确地获取距离信息(Larson & Trivedi, 2011; Han et al., 2012)。 TerraMax 车辆是 2005 年成功完成 DARPA 大挑战沙漠赛跑的五辆车辆之一(Braid、Broggi 和 Schmiedel,2006 年),它使用两个单线 LiDAR 来检测负面障碍物。 在他们的任务中,负面障碍物主要表现为负面的道路边缘或悬崖边缘,因为路面上的小沟或坑不会给 TerraMax 车辆带来风险。 他们检测负道路边缘的算法设计如下:将 LiDAR 数据转换为局部坐标并比较相邻扫描点的相对高度。 在此过程中,扫描数据的历史记录保存在数据库中(类似于全球地图)。 检测操作是在该数据库中实施的,数据库中的这些负高度不连续性将被视为潜在的负障碍。 为了提高检测性能,还广泛采用了不同类型传感器的多线索检测方法(A. Rankin 和 Matthies,2007 年;Manduchi、Castano、Talukder 和 Matthies,2005 年;Dima、Vandapel 和 Hebert,2004 年)。 在论文(A. Rankin 和 Matthies,2007 年)中,立体范围数据中基于几何的线索和热红外图像中基于热特征的线索都被应用于负障碍物检测。 Paper (Manduchi et al., 2005) 试图结合两个传感器,一个彩色立体相机和一个单线激光雷达,来实现检测。 在该算法中,它分析了由彩色立体相机生成的车辆前方每个表面块的斜率; 那么那些识别出的补丁代表了车辆的障碍。 论文 (Dima et al., 2004) 将障碍物检测视为推理问题,因为没有传感器可以直接测量“障碍物”:传感器需要从颜色、温度或形状的测量中推断出有关障碍物的信息。 因此,他们将彩色和红外 (IR) 图像与来自单线 LiDAR 的距离信息相结合,用于障碍物检测。
如今,多线激光雷达在正负障碍物检测中越来越受欢迎。 论文 (Larson & Trivedi, 2011) 介绍了一种基于负障碍物检测器 (NODR) 的算法,其中选择了 HDL-64 LiDAR 作为机载传感器。 该算法“在慷慨地检测负面障碍方面犯了错误”,然后将它们标记为潜在的负面障碍。 然后,NODR 通过检测间隙、数据缺失对这些潜在的负面障碍进行分类,其中可能存在真正的沟渠、坑、悬崖或负斜坡。
LiDAR 地面分割方法是障碍物检测的另一种选择。 在论文(Larson, Trivedi, & Bruch, 2011)中,首先根据 3-D LiDAR 产生的点云分析越野地形,然后确定地上或地下的潜在危险。 论文 (Morton & Olson, 2011) 还描述了一种高度-长度-密度 (HLD) 地形分类器,它概括了一些先前的方法,并为正负障碍物检测提供了统一的机制。 我们的团队也进行了类似的工作 (Chen et al., 2013):提出了一种实时分割各种地形 3-D 扫描的算法。 然而,基于地面分割的方法在野外环境中是不够的。 例如,当激光雷达固定在高度H=2m,坑与车辆的距离D=8m。 假设这个坑的宽度是0.6m。 在理想情况下,LiDAR 可以看到深达 0.15 米的坑。 但在野外环境中地面地面通常存在0.15m的凹凸不平。 因此,基于地面分割的算法无法在野外环境中运行。
为了改进传统的基于网格地图的算法,论文 (Montemerlo & Thrun, 2006) 提出了一种多网格表示方法,通过组合不同分辨率的地图来检测负面障碍物。 为每次检测选择的地图取决于整体范围:检测点越远,相应的网格越粗糙。 这种方法的关键是拥有这样一个由同时定位和映射 (SLAM) 算法生成的信息解决方案地图。 不幸的是,SLAM 本身在野外环境中是一个难题。
辛哈等人。 最近成功地将他们的间隙检测方法应用于城市搜索和救援机器人(Sinha & Papadakis,2013)。 该论文的主要贡献是使用 2-D 图像算法处理 3-D 范围数据:(第 1 页)“所提出的方法基于应用有效的图像形态学操作来进行降噪和边界检测和分组之后 差距。” 所提出方法的能力主要取决于用于生成 3-D 点云的 LiDAR 数据密度。 但是,这篇论文没有解释如何生成 LiDAR 云及其密度。
在这篇论文中,三维激光雷达也被用于负障碍物检测。 考虑到地面在野外环境中可能是颠簸的,而不是传统的网格地图,所提出的算法采用相邻点生成的特征。 首次引入了一种新颖的 3-D LiDAR 设置以提高 LiDAR 数据密度。 在这种设置下,激光雷达的扫描线变得更加密集,这对检测非常有利。 基于此设置,推导了单扫描线点分布的数学模型。 利用该数学模型,提出了一种AMFA算法和一种FFA算法用于负障碍物检测。 实验结果表明,所提算法具有鲁棒性和稳定性。
3. A NOVEL SETUP METHOD OF 3-D LIDARS
三维 LiDAR 广泛应用于 ALV 的障碍物检测。 一种velodyne HDL-64E LiDAR广泛应用于主流ALV,如谷歌自动驾驶汽车、KIT的AnnieWAY (Kammel et al., 2008)、斯坦福的Junior (Montemerlo et al., 2008)、纸上车辆 (Häselich et al., 2012),以及我们自己团队中的车辆 (Chen et al., 2013)(如图 2 所示)。

3.1. Drawbacks of the Traditional Upright Setup( 传统直立设置的缺点)
文献中的三维激光雷达通常直立安装在车顶上。 直立设置有两个缺点:首先,车辆周围会产生较大的盲区。 在结构平坦的环境中行驶时,盲区对 ALV 可能不是致命的,因为这些环境中的道路足够宽,两侧的边界有助于保持车辆安全(Chris Urmson 等人,2008 年)。 然而,在野外环境中,盲区会给车辆带来致命的风险,因为野外道路通常狭窄且杂乱无章,沟渠坑坑洼洼。 在传统的直立设置下,车辆周围的盲区可以分析如下(图3):盲区到车辆侧面的距离为B1=W1x(H1+H2)/H1-W1,其中W1 为整车半宽,H1为搭载激光雷达的高度,H2为整车高度。 车辆前方盲区大小为B2=W2x(H1+H2)/H1-W2,其中W2为激光雷达到车辆头部的距离。 盲区如图3所示。
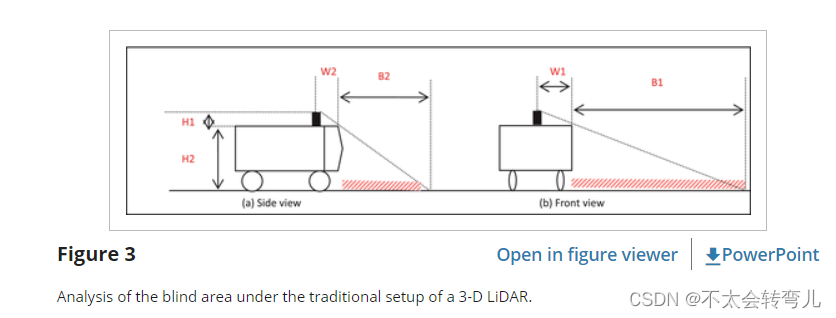
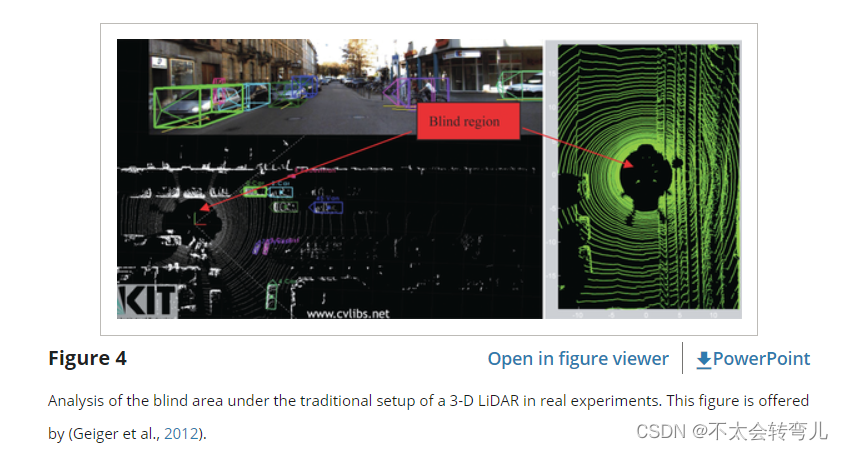
传统设置下实验产生的盲区如图 4 所示。图 4 显示了 LiDAR 传感器对 ALV 的可见区域。 图 4 中的结果由 (Geiger, Lenz, & Urtasun, 2012) 提供,其中 AnnieWAY 的宽度约为 2.2m,而盲区的直径超过 8m。 如果该区域出现障碍物或 ALV 转弯,则非常危险。 此外,当传感器头旋转时,每个激光水平生成高密度点,但相邻扫描线之间的间距随着与传感器的距离增加而变得更稀疏 (W. Shane Grant & Itti, 2013)。 如图4所示,当扫描线距离车辆10m时,两条扫描线之间的距离稀疏至0.5m。 当障碍物宽度小于0.5m时,几乎无法识别障碍物。
3.2. Details of the Novel Setup of 3-D LiDAR
关于传统直立设置的缺点,本文提出了一种新颖的 3-D LiDAR 设置来克服这些缺点。 拟议的 3-D LiDAR 设置如图 1 所示。两个 LiDAR 安装在车辆顶部的两侧:一个在左侧,另一个在右侧。 两者都同样向前倾斜。
在此设置中需要遵守三个规则:(1) 确保两个 LIDAR 的激光不会直接相互照射; 否则会损坏传感器; (2) 车辆周围的可视范围取决于 θ (图 5(a)); (3) 车辆前方的可视范围和重叠扫描区域取决于 ϕ(图 5(b))。 建议设置的视觉范围如图 5 所示,其中角度及其相应的视觉范围显示在两个视点上:前视图和俯视图。 图 5(b) 中标记的重叠区域大大提高了检测能力。
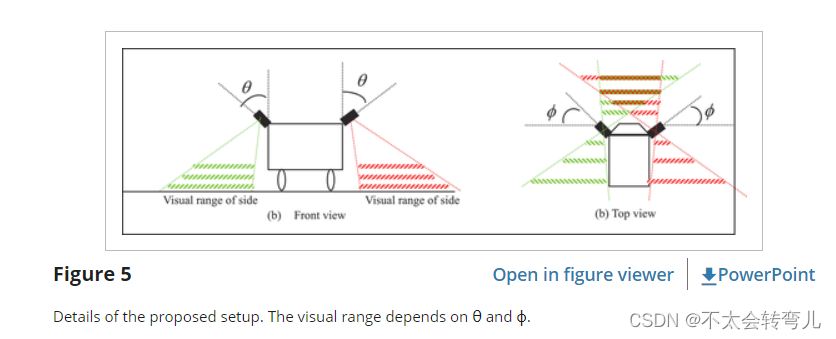
从图 5(b) 中,我们可以看到车辆周围的盲区随着新颖的设置而显着减少。 相关激光雷达现在可以看到两侧的区域。 前方区域由两颗激光雷达扫描,大大提升了分辨率,提升了场景理解能力。 在这种设置下,LiDAR 数据中负障碍物的几何特征比传统方式下变得更加清晰。 通过这种新设置,负面障碍物检测变得更加可靠。
3.3. Comparison
实验旨在评估所提议设置的好处。 在我们的 ALV 平台上的建议设置下,选择了一对 HDL-32E 紧凑型 LiDAR(图 1)。 另一台 HDL-64 LiDAR 竖立固定在车顶中央,用于对比(图 1)。 将 15 个高度相同的 0.5m 物体散布在车辆周围,以检查所有 LiDAR 的可视范围(如图 6 所示)。
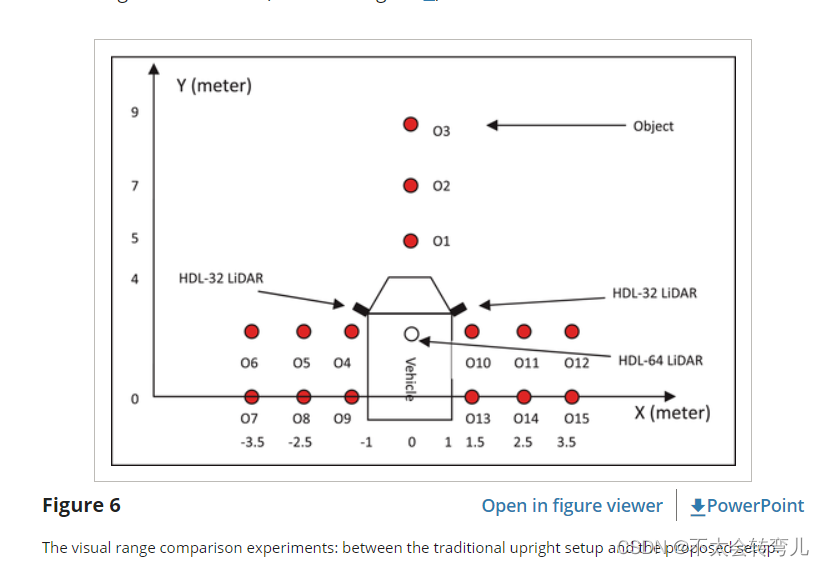
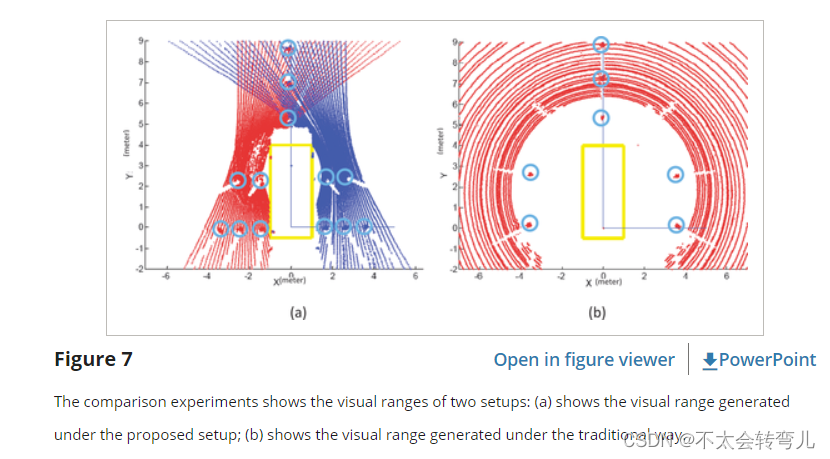
图 7(a) 显示了两个 HDL-32 LiDAR 在建议设置下生成的可视范围,图 7(b) 显示了 HDL-64 LiDAR 在传统直立设置下生成的可视范围。 LiDAR 和物体的分布如图 6 所示。发现在建议的设置下,大多数物体都可以被 LiDAR 看到,而许多物体在比较视图中丢失了。 这些物体会给 ALV 带来风险,尤其是在野外环境中。 可以推断,所提议的设置实际上可以使 ALV 受益。
建议设置的另一个优点是扫描线在感兴趣范围 (ROI) 中更密集。 有了这个新设置,车辆前方的扫描范围在实验中重叠,这意味着更多的点分布在这个区域。 因此,所提出的设置提高了用于障碍物检测的 LiDAR 的分辨率。 另一个实验是专门为证明这种改进而设计的(图 8)。 车辆前方有两个障碍物(其中一个是人):一个距离车辆6米,标记为O1; 另一个在 9 米外,标记为 O2。 三个 LiDAR 都可以看到这两个障碍物。
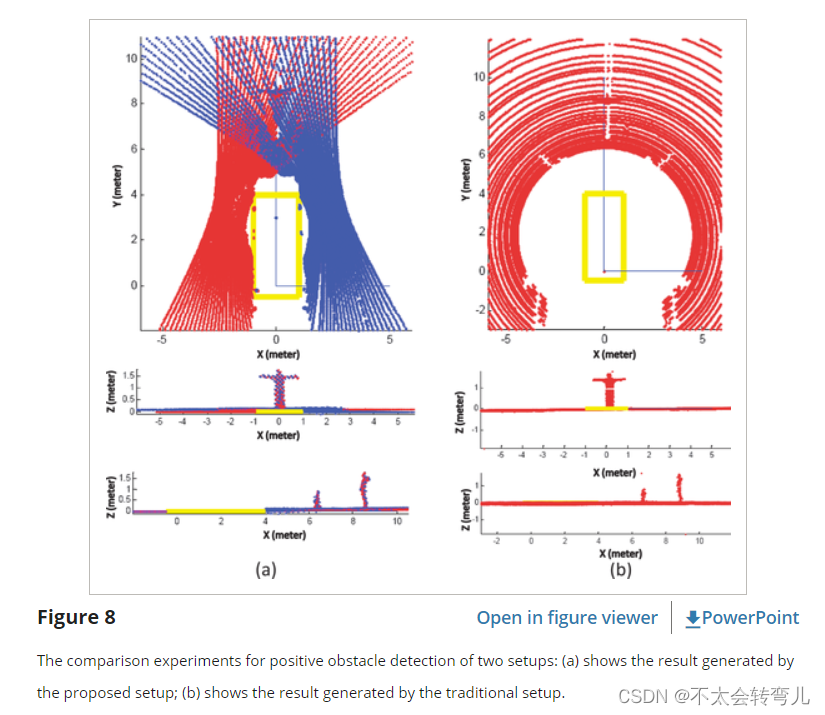
为了证明所提出的设置的好处,分布在障碍物上的 LiDAR 点数列于表 I。从表 I 中,我们可以看出障碍物在所提出的设置下获得更多的分布式 LiDAR 点,这意味着两个障碍物更容易 被检测到。

4. THE MATHEMATICAL MODEL OF THE PROPOSED SETUP
通过所提出的设置,3-D 数据密度显着提高,负障碍物的几何特征比传统设置更加突出。 通过这种新颖的设置,可以推导出单条扫描线的点分布的数学模型。 将推导出的数学模型应用到下面的AMFA算法和FFA算法中。
4.1. Difference Between the Scan Point Distributions Under Two Setups(两种设置下扫描点分布的差异)
典型负障碍物的几何特征如图 9(a) 所示。 L 指定障碍物的宽度,H 指定安装的 LiDAR 的高度。 扫描线分布在障碍物上,D 指定 LiDAR 与障碍物之间的距离。
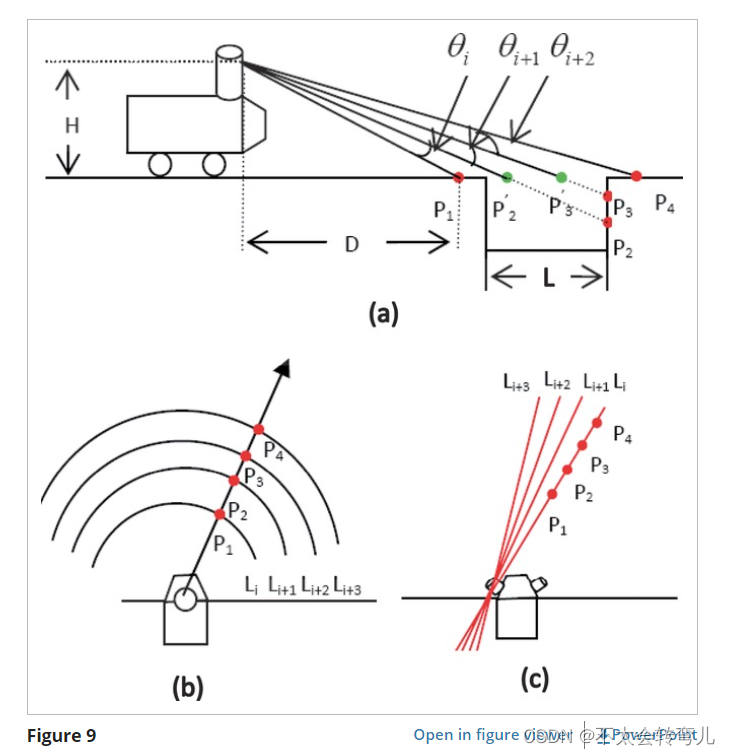
图九:分析传统直立设置和提出的设置下负障碍检测的几何特征:(a)显示典型负障碍的几何特征; (b) 显示了直立固定激光雷达产生的扫描点; © 显示了建议的设置 LiDAR 生成的扫描点。
负面障碍物检测中广泛采用了两种线索。 一是两个相邻扫描点之间的距离。 如果出现负面障碍物,障碍物上的扫描点之间的距离将变得更长。 如图 9(a) 所示,当 LiDAR 扫描线扫描到凹坑时,d(r1r2) 远大于 d(r1r2’)。 此外,后续扫描点之间的距离将变得比平时更短。 例如,d(r2r3) 比 d(r2r3’) 小得多。 这是使用 LiDAR 传感器的负面障碍物的主要几何特征。 另一个线索是沟渠上侧(背面)的坡度。 在 Z 轴上总是有几个扫描点低于其他扫描点(例如,P2、P3 低于 P1、P4)。 这两个线索都被用作我们 算法中的特征。
激光雷达直立安装时,扫描线分布如图9(b)所示。 散布在障碍物上的扫描点(P1、P2、P3、P4)位于不同的扫描线上。 每两条相邻扫描线之间的角度取决于激光雷达的固有参数。 相比之下,通过在建议的设置下设置 LiDAR,扫描点(P1、P2、P3、P4)由同一扫描线生成,如图 9© 所示。 这种新设置的好处是这些扫描点更密集,并且每两点之间的角度是固定的。
从HDL-32E激光雷达(Velodyne LiDAR, 2012)的固有参数可知,32条扫描线覆盖了41.3°的垂直视场,即每两条相邻扫描线的θi平均夹角约为1.29° . 此外,2000个扫描点覆盖了总共360°的水平视场,这意味着同一扫描线的每两个相邻扫描点之间的夹角θi(应该是水平分辨率)为0.18°。 假设激光雷达安装在H=2m的高度,距离车辆D=10m处有一个负障碍物,则根据Eq.2,d(r1r2’)=1.32m时 激光雷达传统上是直立固定的,而当激光雷达在建议的设置下固定时,d(r1r2’)=0.17m。 由于直立设置下地面点间距为 1.32m,因此无法检测到小于或等于此尺寸的坑。 建议的设置将此距离减少到 0.17 m; 因此,在建议的设置下可以检测到相同的坑。
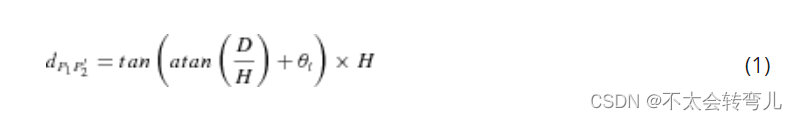
4.2. The Mathematical Model of the Point Distribution of a Single Scan Line
当激光雷达安装在建议的设置下并校准到车辆坐标系上时**(校准方法可以在我们之前的工作中找到(Shang et al., 2014)**),扫描点分布如下所示:
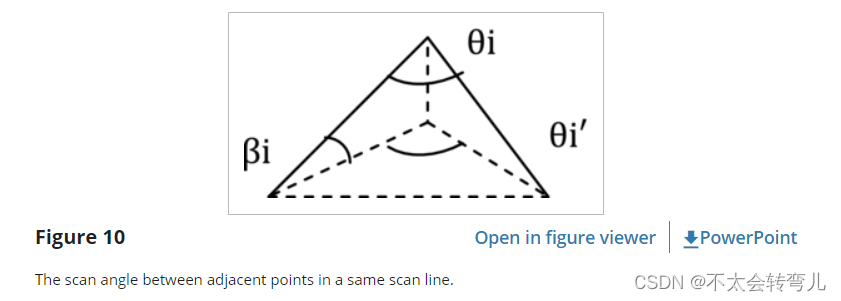
1)每两个相邻点之间的夹角是一个固定的角度θi(图10),可以通过等式2计算出来。
图 10 中,θi’ 取决于扫描线作圆周时的数 M。 因此,θi’ = 360°/M,其中 M 是固定参数。 βi 也是 LiDAR 的固定固有参数。

2) D 和 t 之间的关系可以表示为等式3所示,其中t表示车辆到障碍物的扫描点数,D表示车辆到障碍物的水平距离,H表示搭载激光雷达的高度。

3)每两个相邻扫描点之间的距离可以表示为W=P(t+1)-P(t),其中P(t)=D,P(t+1)可以通过等式4估算。
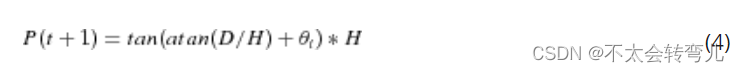
4)负障碍物上的扫描点数Num可以表示为等式5:

5)单条扫描线上负障碍物的数学模型可以表示为:

其中x表示车辆与障碍物之间的距离,y表示每个扫描点的高度。
根据负障碍物的数学模型(式6),当设置负障碍物的参数时,可以生成一条扫描线。 由数学模型和真实激光雷达生成的扫描线如图 11 所示。图 11(a) 是车辆前方有障碍物的图像场景。 图 11(b) 显示了数学模型生成的扫描线。 图 11© 显示了单个扫描线中障碍物的宽度和高度特征。 图 11(d) 显示了机载 LiDAR 生成的真实扫描线。 图 11(e) 显示了真实障碍物的宽度特征和高度特征。 可以发现,数学模型生成的扫描线与真实扫描线非常相似。
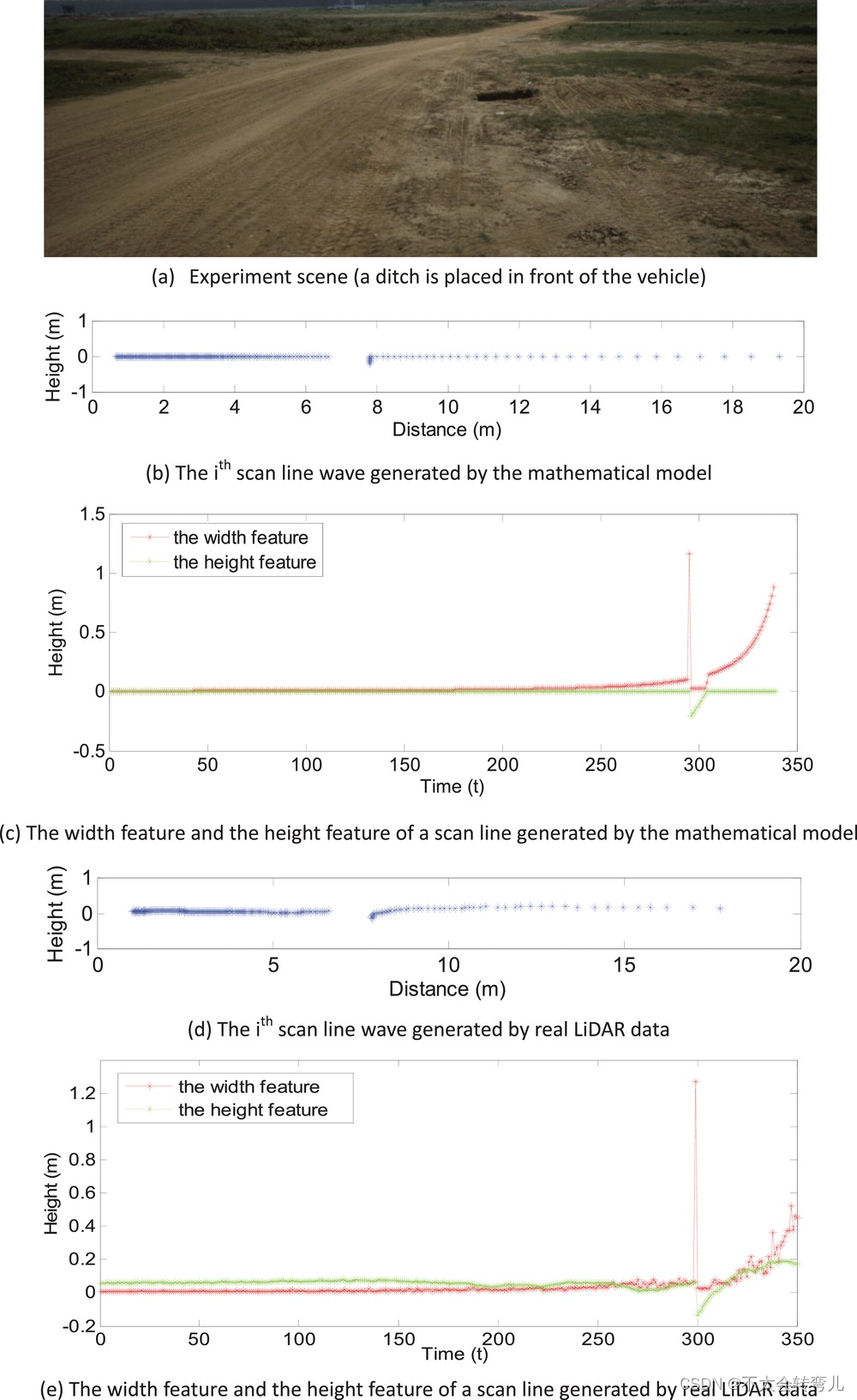
图十一:由数学模型生成和由真实扫描线生成的扫描线及其特征。
5. ADAPTIVE MATCHING FILTER BASED ALGORITHM (AMFA) FOR NEGATIVE OBSTACLE DETECTION( 用于负障碍物检测的基于自适应匹配滤波器的算法(AMFA))
从图11可以看出,当扫描线出现障碍物时,宽度和高度是有区别的。 因此,可以通过分析每条扫描线中的两个特征来检测障碍物。 每条扫描线也可以看作是一个信号波。 因此,障碍物检测问题可以转化为每个波中的信号检测问题。 障碍物的数学模型可以描述为F(H, D, L, i) 其中H表示搭载的LiDAR的高度,D表示障碍物与车辆的距离,L表示障碍物的宽度, i 表示该数学模型由第 i 条扫描线生成。
AMFA算法的思想是首先通过数学模型生成不同位置、不同大小的模拟障碍物; 然后,将这些模拟障碍物的特征用作自适应滤波器以与真实扫描线匹配。 如果模拟障碍物的特征与真实扫描线相匹配,则潜在障碍物被识别出来,并在扫描线的相关位置出现一个峰值。
这种方法可以总结为算法 1。

算法 1. 基于自适应匹配滤波器的负障碍物检测算法。
需要:
扫描线的数学模型F(H, D, L, i);
1:遍历距离参数D,其中D∈[RangeD1,RangeD2]。 RangeD1和RangeD2表示本算法中障碍物检测的距离范围;
2:遍历宽度参数L,其中L∈[RangeL1,RangeL2]。 RangeL1 和 RangeL2 表示该算法的宽度范围;
3:通过改变D和L,由数学模型F(H, D, L, i)生成一系列理想的障碍物信号,记为FDL;
4:将真实扫描线Wi转化为特征波Pi,如宽度特征或高度特征;
5:将理想障碍物信号FDL转化为对应的特征波PDL;
6:将所有PDL与真实波Pi进行匹配,并将结果累加到D-L二维参数空间;
7:在参数空间中找到峰值。 如果存在潜在的障碍物,相关位置将根据参数DR和LR在参数空间中产生一个峰值; 潜在障碍物的参数(DR,LR)。
8:返回潜在障碍物的参数(DR,LR)。
图 12 列出了由算法 1 中的步骤 5 生成的一些典型的理想障碍物特征波 PDL。与算法 1 一样,宽度参数 L 和距离参数 D 都在其范围内以固定步长遍历。 因此,可以生成一系列理想障碍信号,如步骤 3 所述。然后,将这些理想障碍信号转换为不同的特征波 PDL,如图 12 所示。所有波 PDL 都用于与真实波匹配( 如图 11(e))。 因此,在 D-L 二维参数空间中潜在障碍物的位置会出现一个峰值。
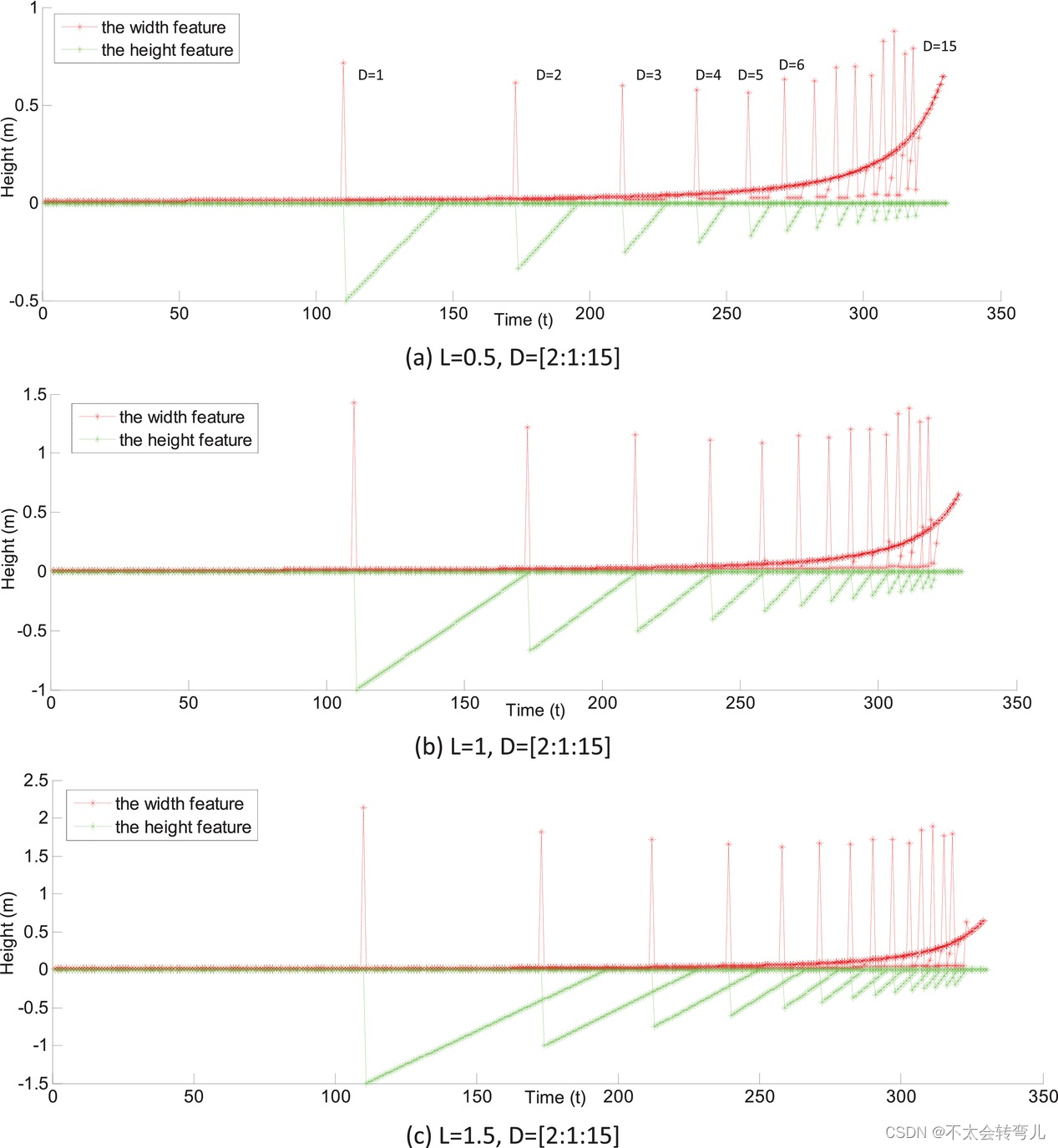
图十二:一些典型的理想障碍物特征波PDL
在我们的应用中,距离参数 D ∈ [2 m, 25 m],宽度参数 L ∈ [0.5 m, 5 m],这意味着我们的算法只能检测车辆前方 2 m 到 25 m 的负障碍物 离开,宽度从 0.5 m 到 5 m。 为了减少滤波器数量,D和L的步长都设置为0.5 m。 因此,二维参数空间 [DR,LR] 的大小为 46 × 9,并设置一个简单的阈值来找到最大位置。 在实验过程中,发现D的步长比L的步长对检测结果更敏感,因为宽度特征只捕获一个可能在相关位置不匹配的像素。 因此,D 的稀疏步骤会严重影响检测能力。 我们实验中的一个解决方案是预先用高斯滤波器对宽度特征波进行滤波。
为了验证所提出的 AMFA 算法,在一些 ALV 平台上进行了一系列户外实验。 激光雷达配备在不同的高度(H=1.4m 和 H=2m)。 在非结构化环境中放置各种负面障碍来验证所提出算法的能力。 一些典型的实验结果如图13所示: 图13(a)为放置障碍物的场景; 图 13(b) 列出了两种激光雷达的结果,其中绿线表示检测到的障碍物的位置。 在不同距离的不同类型的负障碍物上的实验结果表明,所提出的AMFA算法是有效的。
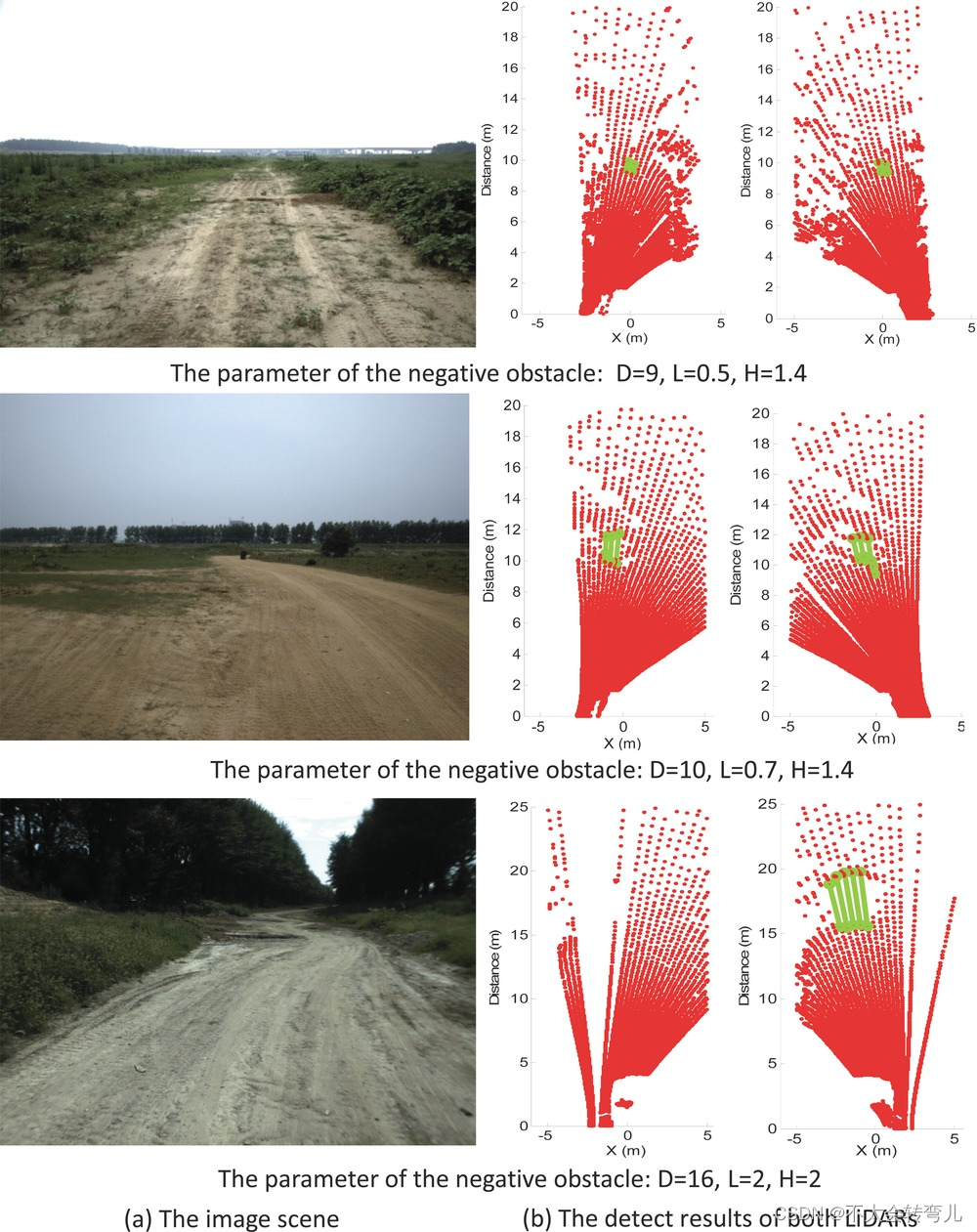
图13
图 13 的第三行演示了 LiDAR 在错误模式下工作的情况:一些扫描线不存在。 在这种情况下,建议的 AMFA 算法无法正常运行(第三行左侧的 LiDAR),因为建议的算法是基于每条扫描线。
6. FEATURE FUSION BASED ALGORITHM (FFA) FOR NEGATIVE OBSTACLE DETECTION(用于负障碍物检测的基于特征融合的算法(FFA))
尽管所提出的 AMFA 算法在大多数情况下都是有效的,但仍然存在一些缺点:
1)AMFA算法在每条扫描线上检测障碍物,在复杂环境下会误报。
2)AMFA算法会因为LiDAR传感器故障而受到严重影响。
3)每条扫描线的检测结果是独立的,只是在最后一步融合。 融合效率低。
在AMFA算法的基础上,引入了另一种障碍物检测算法。 修改后的算法融合了 AMFA 算法根据 GPS 信息从两个 LiDAR 生成的所有特征到全局地图中。 因此,在这个全局地图中积累了检测到的特征的历史。 在累积过程中,每个检测到的特征将被分配不同的权重以显示其置信度,这是由贝叶斯规则估计的。 为了检测障碍物,将全局地图转换为当前地图。 最终从当前地图中检测到潜在的负面障碍物。
FFA 算法的框架可以总结在图 14 中。如图 14 所示,AMFA 算法从不同的 LiDAR 检测到的或在不同帧捕获的所有特征都被累积到一个全局地图中。 这张全局地图还包括所有历史特征。 在累加过程中,采用贝叶斯规则估计每个特征的权重。 GPS信息用于估计当前地图与全球地图之间的关系。 然后,全局地图再次变为车辆坐标系中的当前地图。 最后,实施过滤器并从该当前地图中检测到峰值,该地图表示检测到的障碍物的相应位置。
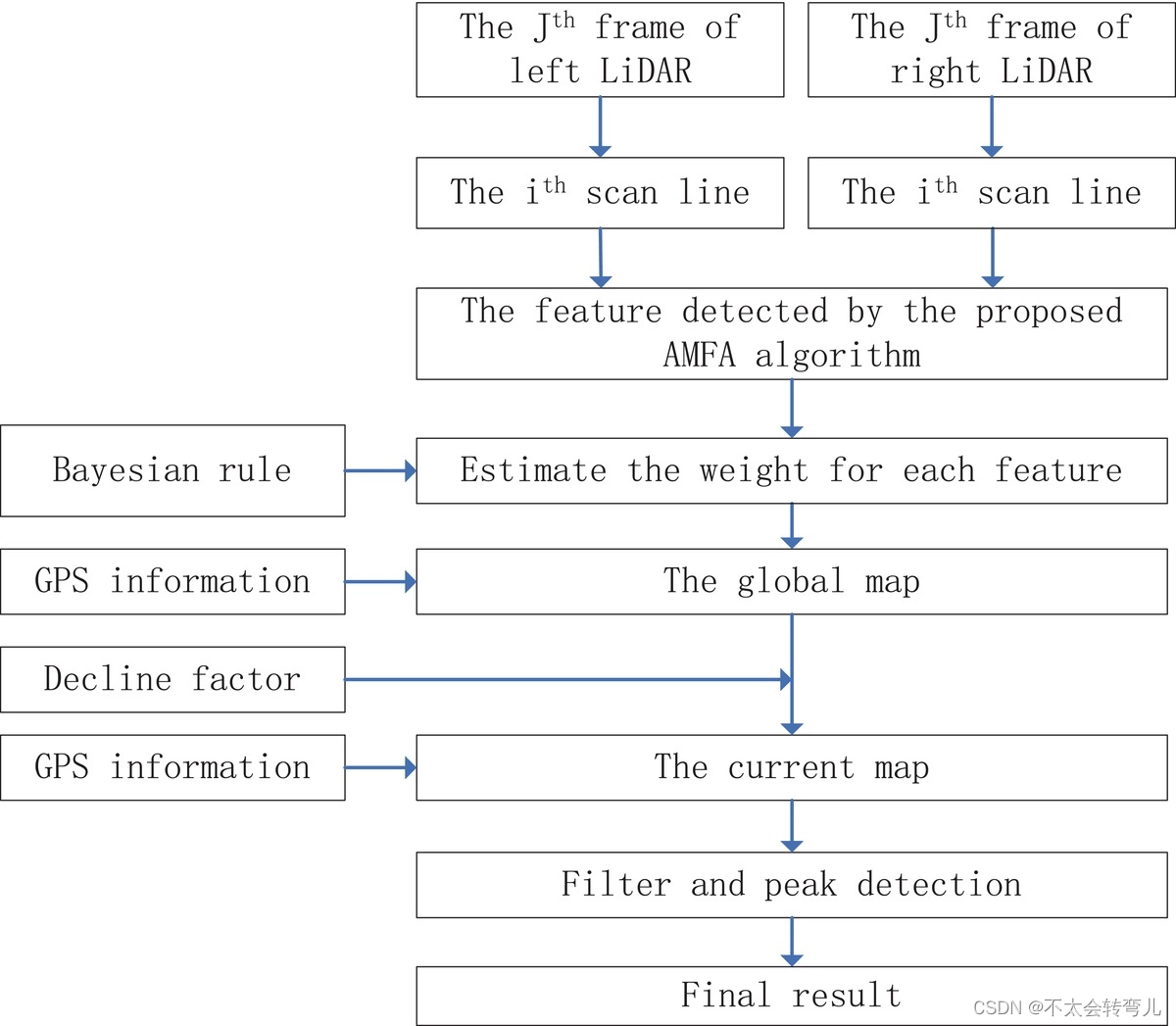
图14 :基于特征融合的算法框架
为了更清楚地描述 FFA 算法的细节,图 15 说明了实现所提出算法的整个过程。 图 15(a) 是存在两个负面障碍物的图像场景。 图 15(b) 和图 15© 是两个激光雷达生成的扫描点,其中 AMFA 算法检测到的潜在障碍物用绿线标记。 AMFA 算法检测到真实和虚假的障碍物。 这些特征根据 GPS 信息转化为全球地图。 全球地图如图15(d)所示。 在其累积过程中,来自同一帧时间的不同特征将分配不同的权重,这些权重由贝叶斯规则估计。 图 15(d) 列出了固定区域中所有检测到的特征。 为了更方便地检测障碍物,我们再次将全局地图更改为车辆坐标系中的当前地图,如图15(e)所示。 图15(f)是相应的参数空间,累积了这些特征的所有权重。 图 15(f) 中检测到峰值,最终结果显示在图 15(g) 中。
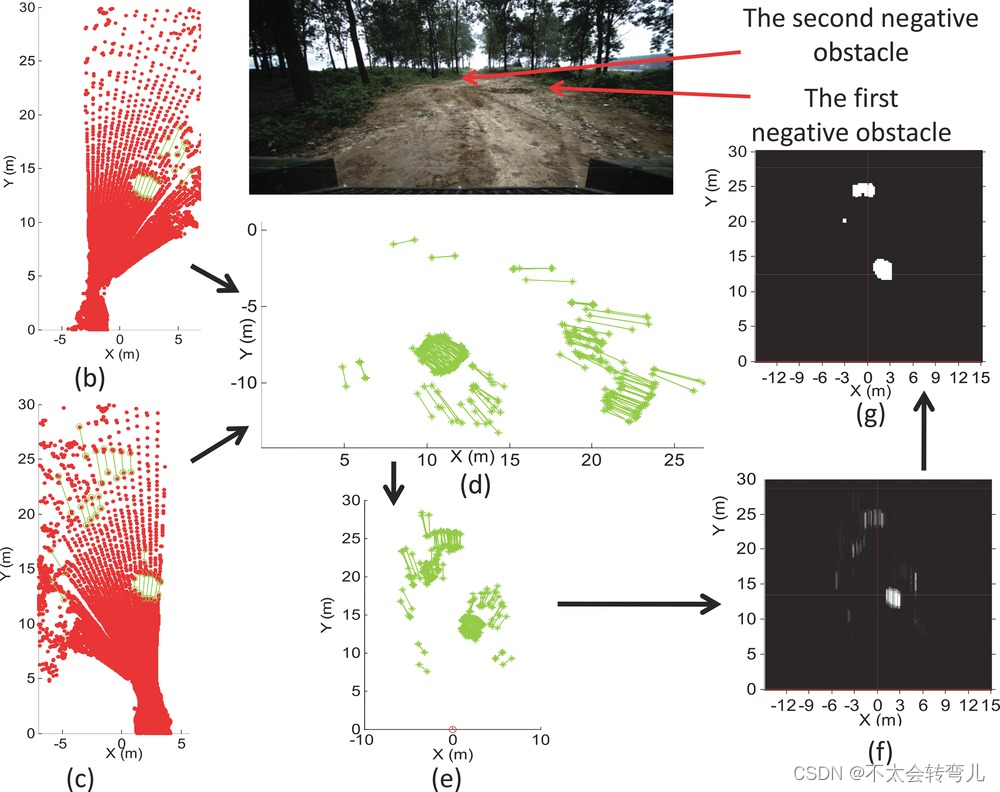
图15:提出的FFA算法的过程。 (a) 场景包含两个负面障碍物; (b) 和 © 两个 LiDAR 生成的扫描点; (d) 全局地图,其中所有特征由AMFA算法生成; (e) 车辆坐标系下的当前地图,根据GPS信息从全球地图平移而来; (f) 根据贝叶斯规则累积所有特征的参数空间。 在 (f) 中检测到峰值,最终结果显示在 (g) 中。
所提出的 FFA 算法具有以下两个优点:首先,在峰值检测之前将滤波器响应(AMFA 算法检测到的特征)融合在全局图中。 这些特征由不同的 LiDAR 生成或在不同的帧捕获。 因此,这些 LiDAR 不需要同步。 其次,采用贝叶斯规则来估计这些特征的每个权重,这对于在参数空间中积累峰值非常重要。
贝叶斯规则可以描述如下:

当有多个线索时,Eq7可以转化为Eq8,
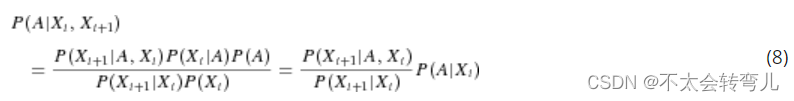
据概率规则,Eq8可以改写为Eq9,
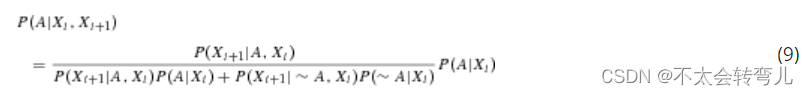
检测过程可以是多条扫描线,用于独立检测潜在目标。 因此,P(Xi+1|A, Xi) = P(Xi+1|A)。 因此,等式(9)可以转化为等式 (10),
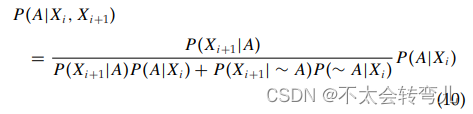
应用贝叶斯规则的关键步骤是迭代全局地图中的概率。 式(10)中的参数可以解释如下: Xi 指定 AMFA 算法检测到的特征。 A 指定存在障碍物的特征。 P(A|Xi) 指定是全局地图中存储的障碍物的概率。 P(Xi+1|A)表示是当前帧(Xi+1)检测产生的障碍物的概率。 P(Xi+1|∼A)是似然概率,表示根据扫描线模型不是障碍物的概率。(贝叶斯我始终看不明白)
所提出的 FFA 算法中的贝叶斯规则应用如下:
步骤一:在传统的 AMFA 算法中,每个检测到的特征都被分配为“0”,这意味着没有障碍物; 或指定“1”,这意味着先前阈值的潜在障碍。 现在它根据 AMFA 算法中的匹配级别输出概率 Pi 而不是“0”或“1”,其中 Pi ∈ [0, 1]。
步骤二:在将概率 Pi 映射到全局地图之前,在相邻位置之间进行泛化。
步骤三:读取全局地图中存储的概率Pi,根据式(10)迭代生成新的概率Pi+1。
步骤四:将值 Pi+1 写回全局映射。
假设每个检测到的特征的概率 P(Xi+1|A) = 0.7 是障碍物,先验概率 P(Xi+1| ∼ A) = 0.1,整个全局地图的初始值(先验概率 , 对检测过程不敏感)设置 P(A) = P(A|X0) = 0.01。 根据式(10),迭代过程如式(11)所示:
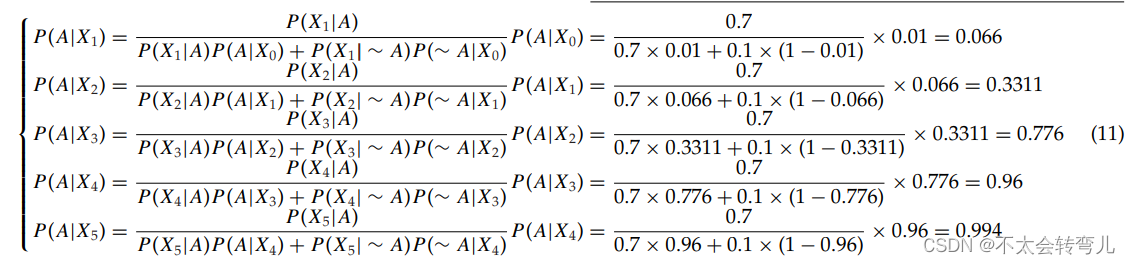
根据式(11),当5条扫描线在同一位置独立检测到一个潜在障碍物时,根据该算法为真正障碍物的概率达到99.4%。 因此,所提出的 FFA 算法可以通过检查全局地图中的概率来检测障碍物。
图 16 说明了在实验中将贝叶斯规则应用于 FFA 算法的过程。 图 16(a) 是车辆前方放置负障碍物的场景。 图16(b1-f1)是AMFA算法检测的结果。 图 16(b2-f2) 显示了根据贝叶斯规则累积权重的相应映射。 图 16(b1) 和 (b2) 是左侧 LiDAR 在单帧生成的结果,而 (c1) 和 (c2) 是右侧 LiDAR 在单帧生成的结果。 图 16(d1) 和 (d2) 是两个 LiDAR 在单个帧上生成的结果。 图16(e1)和(e2)是两台激光雷达累加两个系列帧的结果,图16(f1)和(f2)是两台激光雷达累加五个系列帧的结果。 可以发现图16(f2)中存在真实障碍物的概率几乎达到了100%。 因此,通过为FFA算法设置一个阈值来检测障碍物是非常有效的。

图16:在提出的 FFA 算法中应用贝叶斯规则的过程: (a) 进行实验的场景; (b1-f1) 所提出的 AMFA 算法检测到的特征; (b2-f2)根据贝叶斯规则累加权重的对应图; (b1)和(b2)左侧激光雷达单帧生成的结果; (c1) 和 (c2) 右侧 LiDAR 在单帧生成的结果; (d1) 和 (d2) 两个 LiDAR 在单帧生成的结果; (e1) 和 (e2) 两个激光雷达在两个累积系列帧上生成的结果; (f1) 和 (f2) 是两个 LiDAR 在五个累积系列帧上生成的结果。
7. EXPERIMENTAL RESULTS AND ANALYSIS(实验结果与分析)
为了评估所提出的算法,在结构化环境和野外环境中都进行了实验。 我们的实验由四个部分组成:第一部分详细介绍了测试环境和负面障碍物的种类。第二部分分析了所提算法的检测精度和最大检测距离。 在第三部分中,描述了不同场景下的检测性能,并讨论了与最先进算法的一些比较。 在第四部分中,讨论了一些误报情况。
7.1. Part I: Description of the Testing Environments and Negative Obstacles(第一部分:测试环境和负面障碍的描述)
采用两条结构化道路和六条充满负障碍的非结构化道路来验证所提出的算法。 图 17 列出了不同类型的负面障碍物(我们准备了大约 25 个不同的负面障碍物,标记为 O1 到 O25,其中大部分是由体力劳动者挖掘的)。 障碍物大小从0.5m到3m不等,深度大于0.5m。 两条结构化道路标记为 S1 和 S2。 两条路各挖一个坑。 6条非结构化道路分为五种类型:草地车道,标记为U1; 两条土路,标记为 U2 和 U3; 高地公路,路面严重颠簸,标记为U4; 森林中的一条路径,标记为 U5; 中国“战胜危险2014”地面无人车挑战赛赛道,U6。 表二列出了障碍物分布的细节。 大多数测试道路的建设不仅是为了验证所提出的算法,也是为了检查自动驾驶的全过程,如导航、正向障碍物检测、路径规划等。

图17:结构化和非结构化环境中的各种负面障碍。
表二:测试道路和负面障碍的详细描述
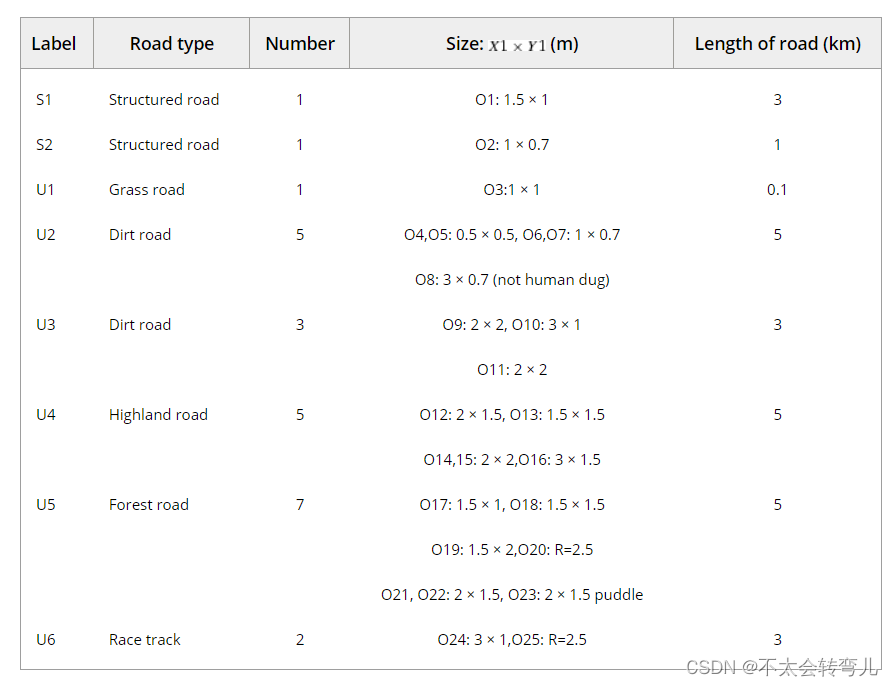
右手坐标系定义如下:X 在车辆右侧,Y 测量前方,Z 从地平面出来。 障碍物的尺寸定义为X1 × Y1 ,其中X1 表示X 轴的长度,Y1 表示Y 轴的长度。 能否安全过沟主要取决于车轮的直径和Y1 的长度。因此,本文选择Y1 来描述负障碍物的大小。
野外环境中的大部分测试道路都是颠簸的。 图 18 显示了两条典型的崎岖道路 U4 和 U5,它们是根据 GPS 信息绘制的。 障碍物的位置也标记在轨迹中。 在图 18 中,Z 轴测量测试道路的颠簸程度。 大多数测试障碍物都放置在最颠簸的地方。
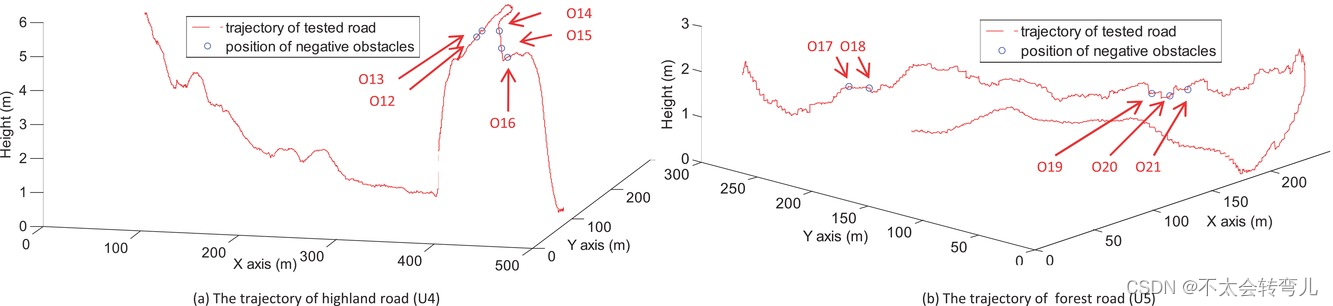
图18:两条测试道路的轨迹及对应负障碍物的位置
7.2. Part II: Analysis of the Detection Accuracy and the Maximal Detection Distance of the Proposed Algorithm(分析所提算法的检测精度和最大检测距离)
本部分首先介绍实验结果的界面,如图19所示。图19(a)为激光雷达视图,其中左侧激光雷达的点标记为蓝色,右侧激光雷达的点标记为红色。 检测到的负面障碍物在图(a)中用绿点标记。 图19(b)为车辆坐标系下的网格图,每个网格为0.2m×0.2m。 原点位于两条蓝线的交叉点。 两个绿色柱子距离原点 2m。 网格图中每行绿线之间的距离为5m。 检测到的障碍物在地图中被标记为红色,如图19(b)所示。 这张图是负障碍物检测模块的最终结果,会实时发送给ALV的其他模块。 图 19© 显示了所提出算法的控制平台,帧号显示在该平台上。图 19(d) 显示了进行实验的场景和负障碍物的位置。 根据图像坐标与车辆坐标的关系,检测结果在该场景图像中用红线标注。 摄像机用于为观察者呈现负面障碍物的可视化视图。 摄像头与 LiDAR 并不严格同步。 这就是为什么图像中标记的检测结果与实际位置不一致的原因。 两个 LiDAR 也不是严格同步的,这在我们提出的算法中不是必需的。
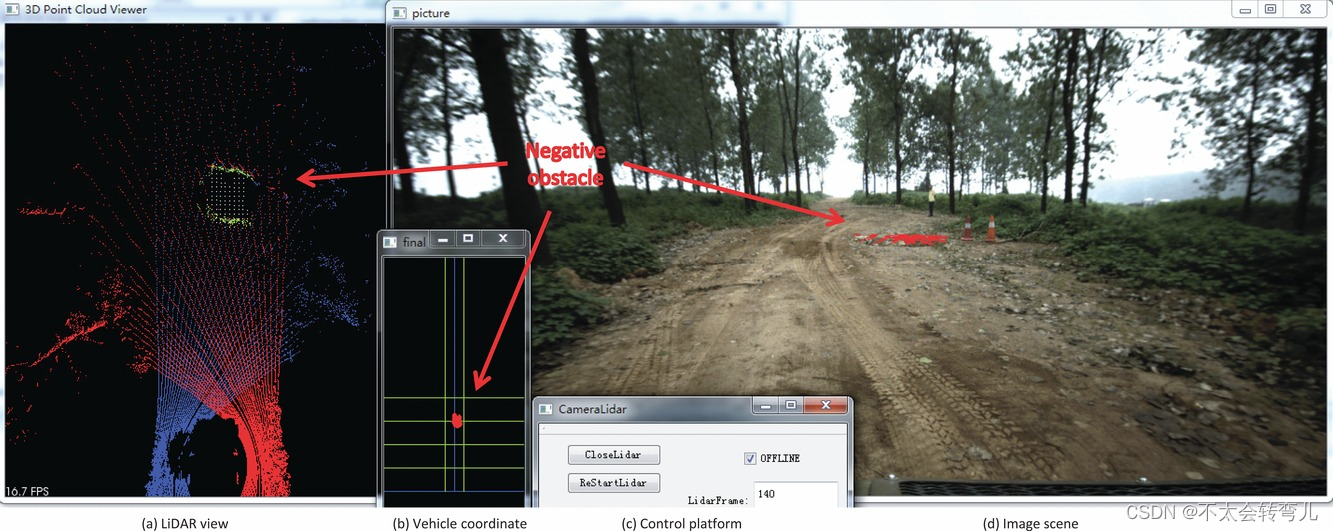
图19:实验结果界面窗口:(a) 显示激光雷达数据; (b) 车辆坐标系中的网格图; © 控制平台; (d) 相应的场景图像。
整个检测过程的细节如图 20 和图 21 所示。采用负障碍物 (O7) 来说明此过程。 实验设计如下:车辆驶向障碍物。 图 21 列出了一系列检测结果帧,它描述了车辆接近目标的过程。 我们可以看到,当车辆接近目标时,目标被检测到的越来越精确。
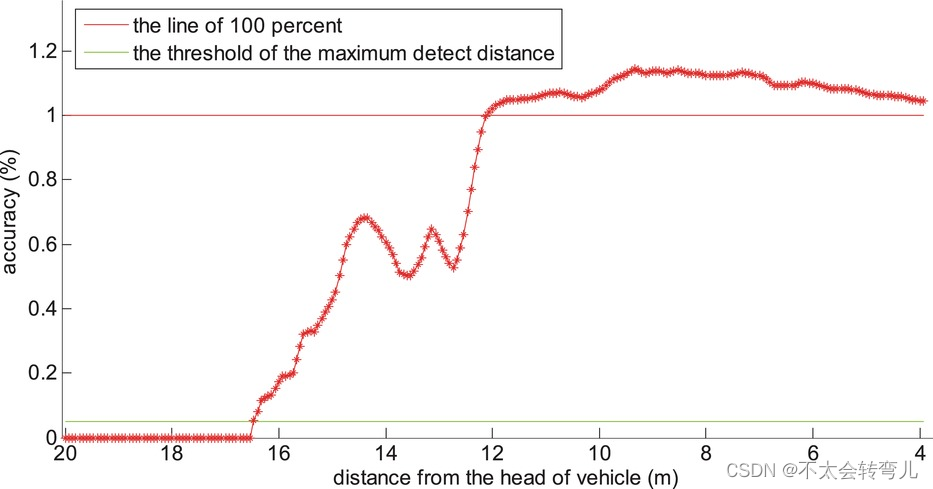
图20:分析车辆接近负障碍物时的检测精度。

图21:检测过程:当车辆接近负障碍物时,检测结果的序列帧。
在检测过程中,当车辆靠近时,检测结果会近似于真实的障碍物,如图20所示。当车辆驶向障碍物时,网格图中的检测结果(图19(b))被记录下来 . 因此,在整个过程中每次检测到的障碍物的大小都是已知的,如图 20 所示。图 20 中的 X 轴描述了车辆到目标的距离,Y 轴表示所提出算法的检测精度。 精度定义如下:acc = Adetected/Astandard × 100%,其中Adetected为算法检测到的目标所占的面积,Astandard为目标障碍物的真实大小。 在图 20 中,当障碍物位于距离车辆 16.5m 处时,首先检测到障碍物(障碍物的一部分),这意味着该目标出现在网格图中。 当车辆靠近时,检测到的区域越来越大。 当距离小于 12m 时,检测区域会变得比标准区域大(acc>100%)。 造成这种结果的原因有几个:(1)GPS 信号甚至在相邻帧之间漂移,用于将检测到的障碍物的位置转换到全局地图上。 (2)激光雷达坐标与车辆坐标存在标定误差。
在实际应用中,允许检测比真实障碍物稍大的潜在障碍物,但禁止检测比真实障碍物小的潜在障碍物。 如果检测到的障碍物比实际障碍物小,车辆在越过障碍物时就会遇到危险。 所提出的算法已考虑到这一方面。
最大检测距离用于评价所提出算法的性能,其定义如下:当检测到的目标尺寸大于固定阈值时,车辆与目标之间的对应距离为最大检测距离。 在实际应用中,在将检测结果映射到最终的栅格地图之前,会进行一个滤波器操作,因此,太小区域的检测结果会被认为是噪声而被过滤掉。 一旦障碍物出现在网格图中,车辆与障碍物之间的相应距离被定义为我们实验中的最大检测距离。
7.3. Part III: Adaptability Analysis and the Comparison( 第三部分:适应性分析与比较)
在不同的实验中采用了不同的负障碍来验证该部分算法的适应性。 实验中使用了两个激光雷达设置在不同高度(H=1.4m 和 H=2m)的车辆平台。 对于每辆车,在车顶两侧配备了两个紧凑型 HDL-32 激光雷达,如图 1 所示。一些典型的实验结果如图 22、图 23 和图 24 所示。在这些实验结果中, 检测到的障碍物在 LiDAR 数据、栅格地图和图像中标记。 障碍物旁边也标注了当前时刻车辆与障碍物的距离(不是最大检测距离)。 实验结果说明了所提算法的高性能。 不同负障碍物检测的实验结果的更多细节可以在https://pan.baidu.com/s/1hqtKcnU?at=1671269007232 和 https://yunpan.360.cn/cy5FLHpVgNPzI 中。(云盘结果已经无了)

图22:所提算法在不同场景下的典型实验结果(一)。

图23:所提算法在不同场景下的典型实验结果(二)。

图24:所提算法在不同场景下的典型实验结果(三)。
AMFA算法和FFA算法均通过检测不同种类的负面障碍物进行验证。 最大检测距离用于评估所提出算法的能力。 潜在障碍物的位置是手动选择的。 因此,路边或其他正面障碍物产生的误报不会影响最大检测距离。 当车辆以不同的方向、不同的速度、或颠簸的车辆接近目标时,最大检测距离会发生变化。 因此,采用 10 个结果的平均值来测量负障碍物的最终最大检测距离。
另外,放置在不同道路上的相同大小的不同障碍物的最大检测距离也不同。 例如,当障碍物放置在结构化环境中时,最大检测距离比放置在非结构化环境中时更大。 因此,对于相同大小的障碍物,最大检测距离的平均值用于衡量所提出算法的能力。 表 III 列出了所有障碍物的最大检测距离。 表III中所有的最大检测距离均为重复实验的平均值。
表三。 所提算法对一些典型负障碍物的最大检测距离
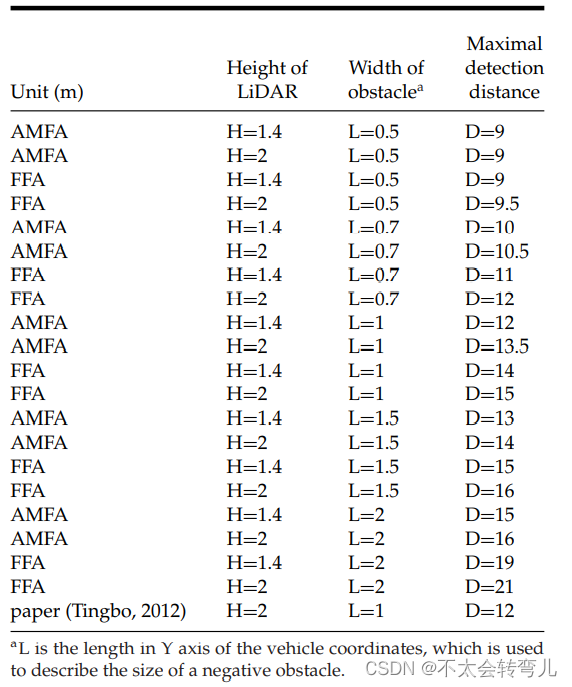
L为车辆坐标在Y轴上的长度,用于描述负障碍物的大小。
不幸的是,据作者所知,没有专门针对负面障碍的公共数据库,因为负面障碍的形状各不相同,负面障碍的定义也很难确定。 此外,障碍物放置的环境也会影响接近的检测距离。 因此,将所提出的算法与其他最先进的方法进行直接比较似乎是不可行的。
胡廷波是本文的合著者,因此他们之前的工作(廷波,2012;Wu & He,2011)适合进行比较。 在他们之前的工作中,两个摄像头被用来生成一个 3-D 场景,颜色信息和几何特征都被用作线索来扩大检测距离。 他们的方法也检测到了图 17 中提到的一些典型的负面障碍。 最大检测距离也列在表三中。 结果表明,如果传感器安装在相同的高度(H=2m),检测相同的障碍物(L=1m),与方法相比,所提出的FFA算法的最大检测距离可以提高20%。 在(廷波,2012)。 在相同的距离(D=12m)下,所提出的FFA算法可以检测到更小的沟渠(L=0.7m)。
Larson 等人(Larson & Trivedi,2011;Larson 等人,2011)使用 HDL-64 LiDAR 进行负障碍物检测,如相关工作中所述。 在他们的论文中,(第 5 页)“创建了多个模拟场景,充满了负面障碍物”,但没有描述负面障碍物的大小信息。 在他们的工作中,给出的结果如下:当目标距离为50m时,检测率为31%,当目标距离为16m-20m时,检测率为89%。 此外,Larson 还指出,他们的系统检测斜坡的实际检测范围在 4.76 米到 5.91 米之间。
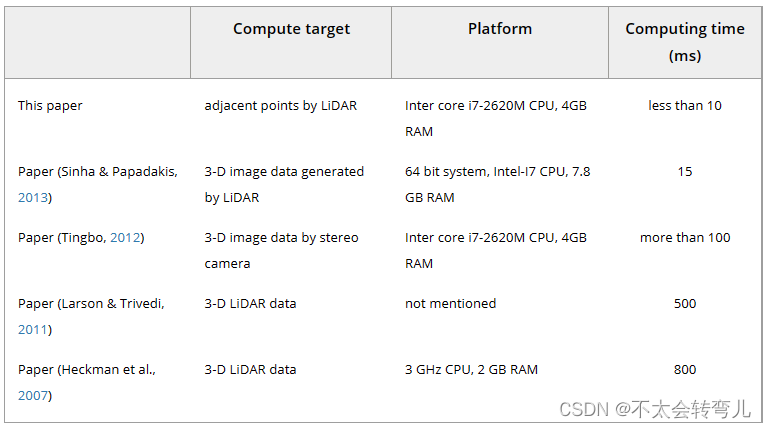
检测算法的另一个性能标准是计算时间。 所提出的 FFA 算法基于所提出的 AMFA 算法,其中所有计算操作都基于相邻点。 使用 Inter core i7-2620M CPU 和 4GB RAM 计算机,建议的 FFA 的计算时间小于 10ms。 使用同一台计算机在论文(Tingbo,2012)中的计算时间超过 100 毫秒。 因此,与(Tingbo,2012)中的算法相比,计算时间减少了两个数量级。 论文 (Larson & Trivedi, 2011) 中也提到了计算时间,其中该方法的平均速率为 2 Hz。 论文中也使用了激光雷达 (Heckman et al., 2007),其中计算操作是在 3-D 数据累积图上进行的,以 1 Hz 的慢帧速率运行。 论文 (Sinha & Papadakis, 2013) 也指出了他们的方法的计算时间,但检测范围并未公开:在 64 位系统、Intel-I7 CPU 和 7.8 GB 内存中,平均计算时间为 15 毫秒。 计算时间列于表四。 据作者所知,所提出的算法是现有负障碍检测算法中最快的。
表四:计算时间与最先进算法的比较
7.4. Part IV: False Alarm Analysis(误报分析)
负障碍物检测算法的另一个性能标准是误报率。 与定义负面障碍一样困难,定义错误警报以及如何权衡它也很困难。 一方面,环境是一个开放的聚合体,每一个新场景或新道路都可能给算法带来潜在的误报。 另一方面,判断是否为误报则更难,因为负面障碍本身就很难界定。 例如,在非结构化环境中,道路两侧通常低于路面。 在这种情况下,很难将错误警报与真正的负面障碍区分开来。 图 25 显示了一个典型的场景,其中真实的负障碍物和伪负障碍物都被所提出的算法检测到。 在图 25 中,检测到四个目标,标记为 T1、T2、T3、T4。 这四个目标中,T1和T2是路面上的真实坑; T3、T4为路边,低于路面。 但是,T3和T4如果在上面行驶,也会给车辆带来严重的风险。 因此,很难定义 T3 和 T4 是虚警还是真正的负障碍。** 当 LiDAR 有两个正面障碍物时,就会出现类似的“误报”。 两个正障碍物之间的区域低于正障碍物,**因此算法会将其视为沟渠。 崎岖不平的道路偶尔会导致误报。 更多关于所提出算法产生的误报的实验结果,请访问http://pan.baidu.com/s/1hqtKcnU,或http://yunpan.cn/cy5FLHpVgNPzI,其中提供了一些实验结果视频。 在这些视频中,记录了负面障碍物检测以及生成的误报。 到目前为止,所提出的 FFA 算法已成功应用于四种以上不同领域的 ALV。 去年,这些现场 ALV 在结构化环境和自主模式下的现场环境中行驶了数千英里。 在自主模式下行驶时,所提出的算法产生的误报不会给我们的 ALV 带来麻烦。
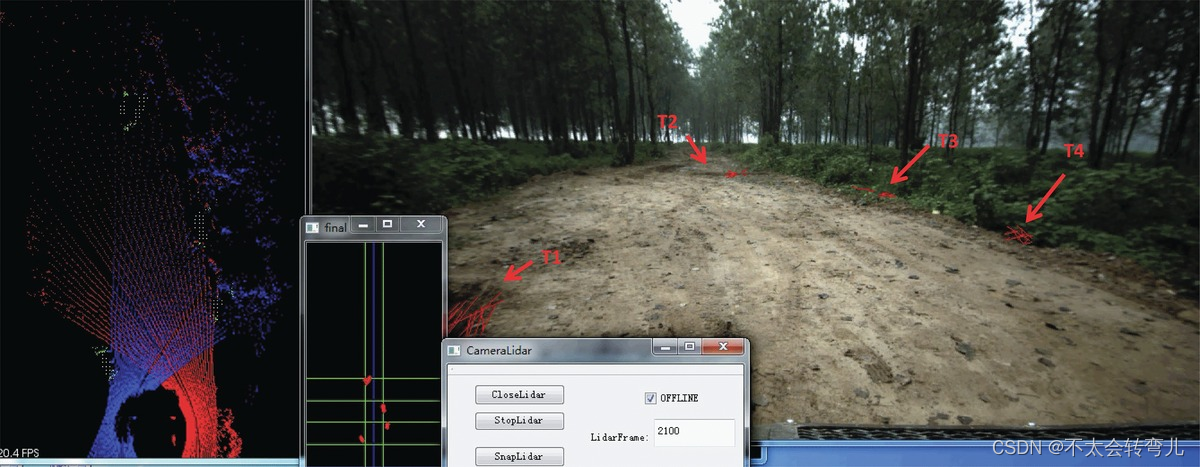
图像25:很难将误报与真正的潜在负面障碍区分开来。
8. CONCLUSION
本文通过为现场 ALV 设计一种新颖的 3-D LiDAR 设置,介绍了一种基于 LiDAR 的负障碍物检测算法。 与传统的直立设置不同,该设置在车辆顶部的两侧布置了两个 3-D LiDAR,以减少车辆周围的盲区并提高扫描线的密度。 在此新设置的基础上,推导了单扫描线点分布的数学模型。 理想的扫描线是通过数学模型来模拟真实的扫描线。 通过数学模型,提出了AMFA和FFA。 进行了大量的实验,实验结果表明了该方法的有效性和高性能。 与最先进的技术相比,检测范围扩大了 20%,计算时间减少了两个数量级。 所提出的FFA算法已成功应用于两款ALV,在中国“Overcome Danger 2014”地面无人车挑战赛中获得冠亚军,负障碍物检测任务得分为14.4%。
此外,对于现场 ALV,使用两个 HDL-32 LiDAR 代替 HDL-64 LiDAR 是一个有价值的选择。 首先,与 HDL-64 LiDAR 相比,两个 HDL-32 LiDAR 的成本几乎相同。 其次,与直立式 HDL-64 激光雷达相比,两个 HDL-32 激光雷达产生的可视范围更适合野外 ALV。 第三,ROI 中的密度在新设置下更加密集,这对于正障碍物检测和负障碍物检测都非常有用。 第四,如本文所讨论的,可以更好的检测负面障碍。 通过相邻点处理障碍物检测的思想也可以应用于检测正障碍物。 这个想法的最大优势是实时实施,因为车辆上的所有分布式处理都必须具有实时能力。 融合来自不同传感器或不同帧的特征并通过贝叶斯规则迭代概率也是本文的贡献。 总而言之,我们希望我们的工作有助于提高现场 ALV 的能力。
Acknowledge
这项工作得到了中国国家自然科学基金 61473303、91220301 的部分支持。