在设计缓存系统时需要考虑不同缓存策略的优缺点和适用场景,通过了解和应用这些策略,可以优化缓存系统的性能和效率。原文: 6-Caching Strategies to Remember while designing Cache System
前言
缓存的目标是减少从原始数据源获取数据的次数,从而加快处理速度并减少延迟。
缓存可以在不同体系架构级别上实现,包括内存缓存、磁盘缓存、数据库缓存和CDN缓存。
可以用不同的技术缓存数据,每种技术都有其优缺点。比如内存缓存将数据存储在计算机主内存中,与磁盘缓存相比,可以实现更快的访问速度。
另一方面,磁盘缓存将数据存储在硬盘上,速度比内存慢,但相对访问远程数据源的速度还是要快得多。
使用数据库缓存,将频繁访问的数据存储在数据库中,从而减少从外部存储检索数据的需要。
最后,CDN缓存将数据存储在分布式服务网络中,从而减少访问远程数据的时延。
目录
-
缓存系统关键性能指标 -
读密集型应用缓存 -
写密集型应用缓存 -
缓存失效方法 -
结论
缓存系统关键性能指标
为了提高缓存系统的效率和性能,非常重要的一点是需要监控各种指标,从而根据指标做出有关缓存系统的重要业务决策。
需要考虑的参数有:
-
缓存命中率: 该指标衡量请求项在缓存中被找到次数的百分比。较高的缓存命中率意味着缓存可以提供更多数据,从而减少访问外部存储并提高性能。 -
时延: 时延是指访问数据所需时间。在缓存系统中,较低的时延意味着数据服务速度更快,从而提高整体性能。 -
吞吐量: 吞吐量度量在给定时间范围内可以处理的数据量。高吞吐量的缓存系统可以处理更多请求,提供更多数据,从而提高整体性能。 -
缓存大小: 缓存大小是为缓存分配的内存或存储的容量。缓存大小会影响缓存命中率,较大的缓存可以提高命中率,但也会增加缓存解决方案的成本和复杂性。 -
缓存未命中率: 此指标度量请求项在缓存中找不到并且需要从外部存储中获取的次数百分比。高缓存未命中率意味着需要从外部存储获取更多数据,从而对性能造成影响。
如果一直监控这些性能指标,就可以据此优化缓存系统,以获得更高的吞吐量和更低的时延。
读密集型应用缓存
读密集型应用(如Wordpress/静态图像网站)需要设计缓存系统,以支持更多的读缓存。
下面是一些有用的方法:
-
Cache-aside -
Cache-through -
Refresh-ahead
1. Cache-Aside
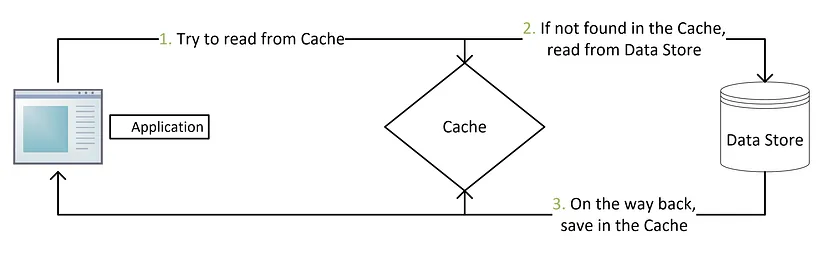
Cache-aside方法是最常用的缓存策略之一。
方法
-
每当应用发送请求,首先检查缓存中是否有请求的数据。 -
如果有,返回缓存的数据。 -
否则,应用程序从数据库查询数据,并在返回途中更新缓存,然后返回数据。
优缺点
-
每次缓存未命中都会导致三次访问,可能会造成明显的时延。 -
如果有人更新数据库而不写入缓存,可能会读到过期数据。(因此,Cache-aside通常与其他策略一起使用)。
2. Read-through
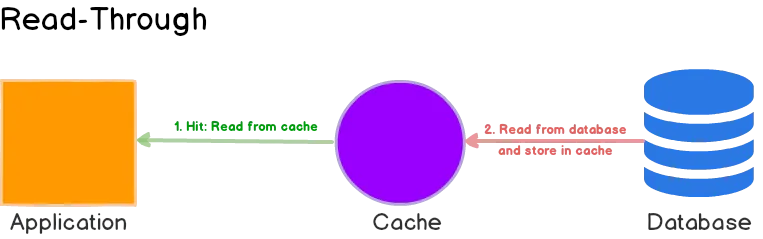
在read-through方法中,缓存对数据库进行读取/查询操作,然后更新自己并将请求数据返回给最终用户。
方法
-
应用程序每次都从缓存中查询数据。 -
如果数据不在缓存中,则 缓存查询数据库并更新自己。 -
缓存将数据返回给最终用户。
优缺点
-
简化应用程序代码,read-through策略确保将数据获取逻辑转移到缓存中,从而简化了应用程序代码。 -
更好的读取可伸缩性。当某个key在Cache-aside中过期时,并发请求可能会触发多次数据库查询相同的数据。在Read-through中,缓存确保只向数据库发送一个查询。
3. Refresh-ahead
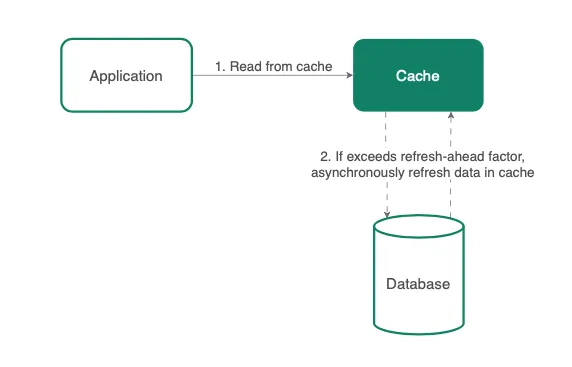
Refresh-ahead策略是在过期之前刷新缓存数据,该方法适用于热数据,即预计在不久的将来会被请求的数据。
方法
-
假设缓存数据的过期时间为60秒,刷新提前系数为0.5。 -
如果缓存数据在60秒后被访问,将从缓存存储执行同步读取以刷新其值。 -
如果缓存数据在30秒后被访问,比如第35秒,缓存将直接返回数据,并异步刷新数据。
优缺点
因此,refresh-ahead缓存本质上是在下一次可能的缓存访问之前以配置的间隔刷新缓存。在这种读流量非常高的系统中,几毫秒内可能会发生几千个读操作。
写密集型应用缓存
任何写密集型应用程序都需要缓存策略,例如:
1. Write-Through
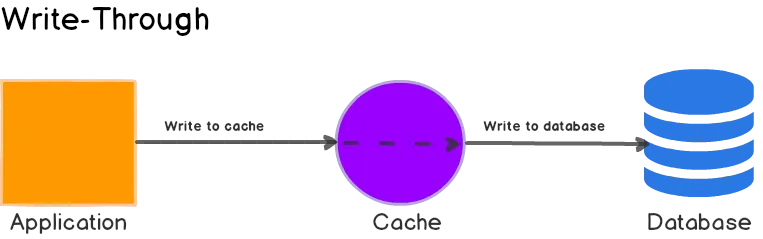
Write-Through策略将缓存作为其主数据存储,即首先在缓存中更新数据,然后才在数据库中更新数据。
下面是应用想要写入数据或更新值时发生的情况:
-
应用程序将数据直接写入缓存。 -
缓存更新主数据库中的数据。当写操作完成时,缓存和数据库都具有相同的值,并且始终保持一致。
优缺点
当与read-through配合使用时,在网络调用中非常有效,数据首先被读/写到缓存中,使得几乎不会发生缓存无效的情况。由于所有数据都是新的和经常访问的数据,而且所有对数据库的写入都是通过缓存完成,使得数据库和缓存几乎始终保持一致。
2. Write-back
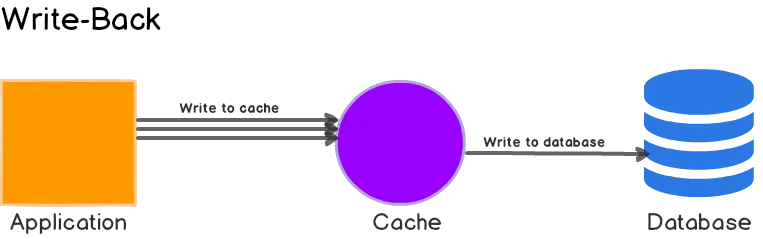
Write-back方法与write-through非常相似,只是数据库写调用是异步的。
优缺点
-
Write-back缓存可以提高写性能,非常适合涉及大量写操作的工作负载。当与read-through结合使用时,也非常适合混合工作负载,可以确保最近更新访问的数据始终在缓存中可用。 -
降低网络成本: 如果使用批处理调用,还可以减少对数据库的总体写操作,从而减少负载并降低成本,特别是当数据库按请求数量收费时(例如DynamoDB)。 -
缓存使用效率低下: 不经常被请求的数据也会被写入缓存。这点可以通过TTL进行优化。
3. Write-around
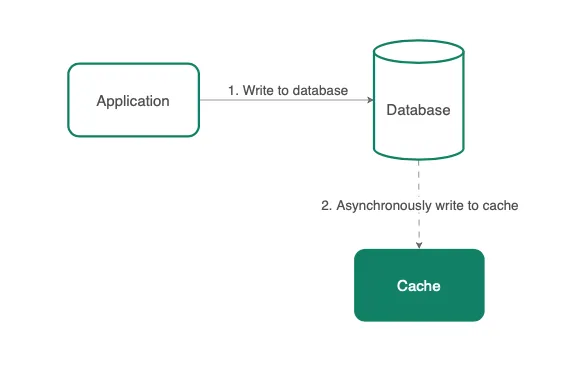
在Write-around方法中,首先将数据更新到数据库,然后数据库对缓存进行异步调用以更新key。
方法
-
当收到写请求时,应用程序更新数据库中的记录。 -
数据库异步更新/删除缓存中的键。
优缺点
Write-around可以与read-through结合使用,在数据只写入一次,读取频率较低或从不读取的情况下提供良好的性能(例如实时日志或聊天室)。同样,这种模式也可以与cache-aside结合使用。
缓存失效方法
缓存失效是从缓存中删除陈旧或过时数据的过程,以确保只保留最新的可用数据。缓存失效策略有:
-
基于时间失效(TTL): 在此策略中,缓存数据在经过一段时间后失效。这是一个简单而有效的策略,易于实施,但可能并不适用于所有用例,因为有些数据可能比其他数据更容易过时。 -
基于事件失效: 在此策略中,缓存数据将根据发生的特定事件(如底层数据源更改或其他相关事件)失效。这是一种更有针对性的失效方法,可确保数据仅在必要时失效,但需要与应用和底层数据源进行更层次的集成。 -
基于版本失效: 在此策略中,为缓存中的每个数据块分配一个版本号,该版本号在每次数据更改时递增。当数据失效时,将在缓存中更新版本号,以确保仅使用数据的最新版本。这种策略对于频繁更改的数据效果很好,但需要额外的开销来管理版本号。 -
最近最少使用(Least recently used, LRU)失效: 在此策略中,当缓存达到容量限制时,缓存中最近最少使用的数据将失效,从而确保在缓存中保留最常用的数据,降低存储陈旧数据的风险。然而,该机制可能并不适合所有用例,因为有些数据可能不被经常访问,但仍然需要缓存。 -
手动失效: 在此策略中,失效由应用程序或管理员手动触发。该机制提供了最大的灵活性和对缓存的控制,但需要更多开销来管理失效过程。
具体失效方法包括清除、禁止、刷新等。
结论
总之,上文提到的策略永远不会单独或孤立的起作用,而总是组合工作。例如,Write-around策略可以与Cache-aside策略一起实现,以确保数据一致性。更重要的是,应该了解应用程序的读/写访问模式,因为选择错误的组合可能无法带来最好的结果。
例如,如果在实际应该使用write-around/read-through(写入的数据访问频率较低)时选择了write-through/read-through,那么缓存中就会有无用的垃圾。
- END -你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!
本文由 mdnice 多平台发布