上一篇博客 nsq中diskqueue详解 - 第一篇_YZF_Kevin的博客-CSDN博客 中我们讲了diskqueue是什么,为什么需要它,它的整体架构流程,以及对外接口等等,如果你还没了解过,强烈建议先看一下,不然直接看这篇博客的话可能会有点儿懵
这篇博客开始,我们从源码角度分析disqueue是怎么实现的。为了避免纯代码分析的枯燥性,我会尽量把内容讲解占一大部分,纯代码分析占一小部分
1、diskqueue的文件存储
diskqueue的文件分为两种类型:元数据文件,消息数据文件
1.1 元数据文件
也叫描述数据,记载了disqueue的整体信息,文件格式为 xxxx.diskqueue.meta.dat,其中的xxxx即队列名字。之所以要求队列名字相互不重复,也是为了防止元数据文件重名的问题。注意:一个diskqueue只会有一个元数据文件
文件一共只有3行
第一行 -> 总消息数
第二行 -> 当前读的文件编号,读的位置
第三行 -> 当前写的文件编号,写的位置
diskqueue在初始化的时候,会尝试从磁盘中加载元数据文件
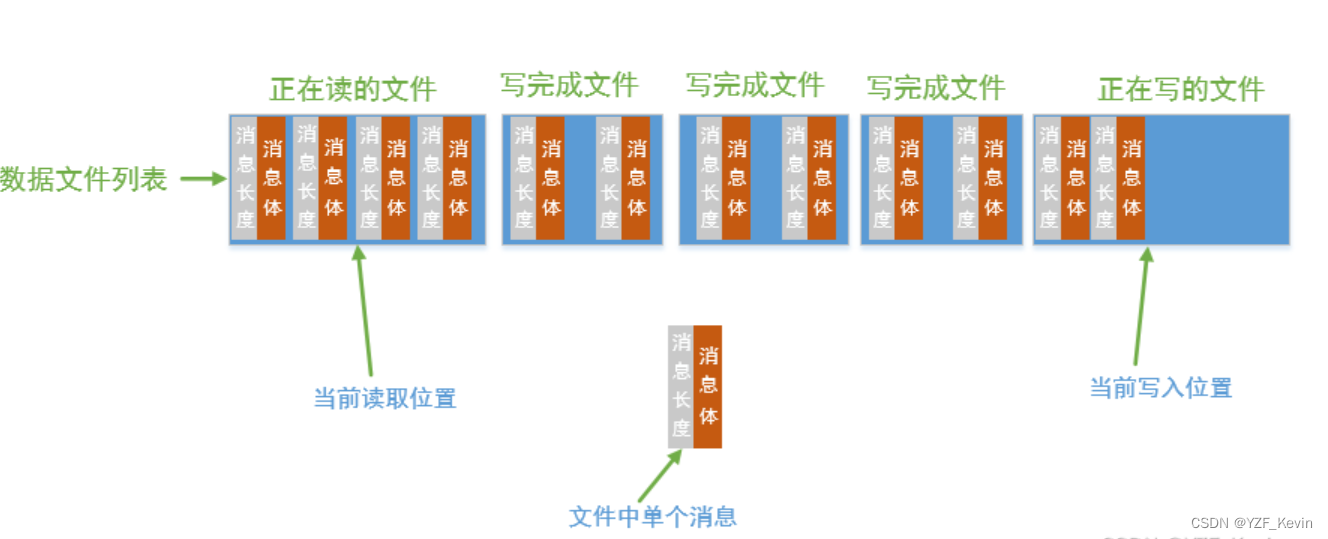
1.2 消息数据文件
存储了所有未处理的消息,文件格式为xxxx.00000n.dat,其中的xxxx即队列名字,n表第几个文件。一个diskqueue至少有一个消息数据文件,也可能有多个
文件内只有消息数据,所有消息紧密排列;每个消息的格式为:消息长度(4字节) + 消息体数据;
如下图
2. diskqueue的启动入口
diskquque对外提供的启动入口是New()函数,使用者需通过调用diskqueue.New(xxx,...)来创建一个diskqueue对象
举例:nsq中创建topic对象后就会调用diskqueue.New()函数来创建topic的持久化队列,如下
// 新创建topic
func NewTopic(topicName string, nsqd *NSQD, deleteCallback func(*Topic)) *Topic {
// 省略无关代码......
t.backend = diskqueue.New( // 永久topic的持久化队列
topicName,
nsqd.getOpts().DataPath,
nsqd.getOpts().MaxBytesPerFile,
int32(minValidMsgLength),
int32(nsqd.getOpts().MaxMsgSize)+minValidMsgLength,
nsqd.getOpts().SyncEvery,
nsqd.getOpts().SyncTimeout,
dqLogf,
)
// 省略无关代码......
}可以看到,调用diskqueue.New()函数时需要传入一些参数:队列名字,数据存储目录,单个数据文件最大等等
现在我们看下diskqueue.New()函数源码,如下(已添加详细注释)
// 新建一个diskQueue的实例
// name : 队列名字,需唯一
// dataPath : 保存文件时的路径
// maxBytesPerFile : 单个文件的最大字节数
// minMsgSize : 单个msg的最小字节数
// maxMsgSize : 单个msg的最大字节数
// syncEvery : 读写多少次触发刷到磁盘
// syncTimeout : 同步到文件的间隔
// logf : 日志函数
func New(name string, dataPath string, maxBytesPerFile int64, minMsgSize int32, maxMsgSize int32, syncEvery int64, syncTimeout time.Duration, logf AppLogFunc) Interface {
d := diskQueue{
name: name, // 队列名字
dataPath: dataPath, // 目录
maxBytesPerFile: maxBytesPerFile, // 单个文件最大字节数,写满了就建下一个文件
minMsgSize: minMsgSize, // 单个msg最小字节数
maxMsgSize: maxMsgSize, // 单个msg最大字节数
readChan: make(chan []byte), // 对外的读消息通道
peekChan: make(chan []byte), // 对外的查看通道
depthChan: make(chan int64), // 无缓冲的通道
writeChan: make(chan []byte),
writeResponseChan: make(chan error),
emptyChan: make(chan int),
emptyResponseChan: make(chan error),
exitChan: make(chan int),
exitSyncChan: make(chan int),
syncEvery: syncEvery, // 读写多少次,向磁盘同步一次
syncTimeout: syncTimeout, // 每多少秒检测一次是否需同步磁盘
logf: logf, // 日志函数
}
// 从文件中恢复队列的元数据(消息个数,读文件号,读的位置,写文件号,写的位置)
err := d.retrieveMetaData()
if err != nil && !os.IsNotExist(err) { // 文件不存在的情况是正常的,其他错误需报错
d.logf(ERROR, "DISKQUEUE(%s) failed to retrieveMetaData - %s", d.name, err)
}
// 新开一个协程,专门处理读写
go d.ioLoop()
return &d
}对上面的代码解释下
1. 根据New()函数传入的参数,初始化本队列的属性,例如队列名字,数据存取的目录,单个数据文件的最大字节数,单个msg的最大最小字节数,日志函数等等。值得一提的是,diskqueue自己不提供日志函数,必须使用方传入
2. 创建diskquue对象后,调用 retrieveMetaData() 函数来读取原来的数据,注意:原数据可能存在,也可能不存在,都是正常的。比如nsq启动时可能有以前的旧数据,那么启动时就应加载再次分发。如果没有,说明消息都处理完了或者是nsq第一次启动,也属正常
3. 启动一个新协程 ioloop() ,这个ioloop()是整个diskqueue的运转核心,负责真正接收消息,文件的创建销毁,文件读写光标的移动,存盘等,后面会详细讲解
3. 元数据文件的读取
我们已经了解到diskqueue启动时会调用retrieveMetaData()函数进行元数据的读取,
前面也讲了,元数据文件的格式很简单,文件一共只有3行
第一行 -> 总消息数
第二行 -> 当前读的文件编号,读的位置
第三行 -> 当前写的文件编号,写的位置
读取元数据,函数retrieveMetaData()的代码如下(已添加详细注释)
// 从文件中恢复disQueue的元数据
func (d *diskQueue) retrieveMetaData() error {
var f *os.File
var err error
// meta文件名(带全路径)
fileName := d.metaDataFileName()
// 以只读的方式打开文件
f, err = os.OpenFile(fileName, os.O_RDONLY, 0600)
if err != nil {
return err
}
defer f.Close()
var depth int64
// 从文件中读取,文件一共三行
// 第一行格式:%d 表总的消息数量
// 第二行格式:%d,%d 表 readFileNum(当前读的文件编号),readPos(读的位置)
// 第三行格式:%d,%d 表 writeFileNum(当前写的文件编号),writePos(写的位置)
_, err = fmt.Fscanf(f, "%d\n%d,%d\n%d,%d\n",
&depth,
&d.readFileNum, &d.readPos,
&d.writeFileNum, &d.writePos)
if err != nil {
return err
}
d.depth = depth // 总的消息数
d.nextReadFileNum = d.readFileNum // 要读文件的编号
d.nextReadPos = d.readPos // 要读文件的位置,即文件读取游标
// 要写入的数据文件名(带全路径)
fileName = d.fileName(d.writeFileNum)
fileInfo, err := os.Stat(fileName) // os.Stat是获取文件的整体信息,例如大小,路径,修改时间,是否目录等
if err != nil {
return err
}
fileSize := fileInfo.Size() // 取得文件大小
// 正常情况下writePos应等于文件size;如果出现了writePos比文件size小,可能是消息数据有写入但元数据没同步,安全的做法是新开一个文件重新写,至于这个文件的内容也承认
if d.writePos < fileSize {
d.logf(WARN, "DISKQUEUE(%s) %s metadata writePos %d < file size of %d, skipping to new file", d.name, fileName, d.writePos, fileSize)
d.writeFileNum += 1 // 要写入的文件编号(后面发现writeFile指针为nil,会新建)
d.writePos = 0 // 写入位置从0开始
// 当前的写入文件关闭吧,后面建新的写入文件了
if d.writeFile != nil {
d.writeFile.Close()
d.writeFile = nil
}
}
return nil
}对上面的代码解释下
1. 调用metaDataFileName()函数,该函数内组装得到元数据文件的全路径名,然后调用os.OpenFile()函数以只读的方式打开文件,文件不存在的话err不为空就返回了
2. 调用 fmt.Fscanf(f, "%d\n%d,%d\n%d,%d\n"),读取3行数据,分别赋值给 d.depth,d.readFileNum, d.readPos,d.writeFileNum,d.writePos
3. 取得写文件的信息,正常情况下,d.writePos应该等于写文件的实际大小。如果d.writePos比文件实际大小要小,说明出错了。有可能是数据写入后,但是d.writePos没更新导致的。这个时候就新建一个写文件,写入位置重新从0开始
4. 元数据文件的写入
看完了读取元数据,再来看下元数据的写入
diskqueue会在以下几种情况下调用persistMetaData()函数进行元数据的保存
分别是:队列关闭或退出时,写入的文件写满时,读写次数达到syncEvery时
persistMetaData()的代码如下(已添加详细注释)
// 把元数据保存到文件中
func (d *diskQueue) persistMetaData() error {
var f *os.File
var err error
// 元数据的最终文件名
fileName := d.metaDataFileName()
// 元数据的临时文件名
tmpFileName := fmt.Sprintf("%s.%d.tmp", fileName, rand.Int())
// 以读写方式(没有则新建)打开文件
f, err = os.OpenFile(tmpFileName, os.O_RDWR|os.O_CREATE, 0600)
if err != nil {
return err
}
// 使用Fprintf()往文件缓冲区写
// 第一行格式:%d 存未读的消息数量
// 第二行格式:%d,%d 存 readFileNum(当前读的文件编号),readPos(读的位置)
// 第三行格式:%d,%d 存 writeFileNum(当前写的文件编号),writePos(写的位置)
_, err = fmt.Fprintf(f, "%d\n%d,%d\n%d,%d\n",
d.depth,
d.readFileNum, d.readPos,
d.writeFileNum, d.writePos)
if err != nil {
f.Close()
return err
}
f.Sync() // 刷到磁盘
f.Close() // 关闭文件
// 重命名为最终文件名
return os.Rename(tmpFileName, fileName)
}对上面的代码解释下
1. 调用metaDataFileName()函数,该函数内组装得到元数据文件的全路径名,随机一个数字,加上.tmp作为后缀,组成一个临时文件名
2. 以读写的方式,新建这个临时文件
3. 调用 fmt.Fprintf(f, "%d\n%d,%d\n%d,%d\n") 写入3行数据,依次把d.depth,d.readFileNum, d.readPos,d.writeFileNum,d.writePos写入文件,
4. 调用f.Sync()强制刷到磁盘,关闭这个临时文件
5. 最后以文件重命名的方式,改为真正的元数据文件