目录
登录
显示数据库
创建数据库
删除数据库
使用数据库
创建表
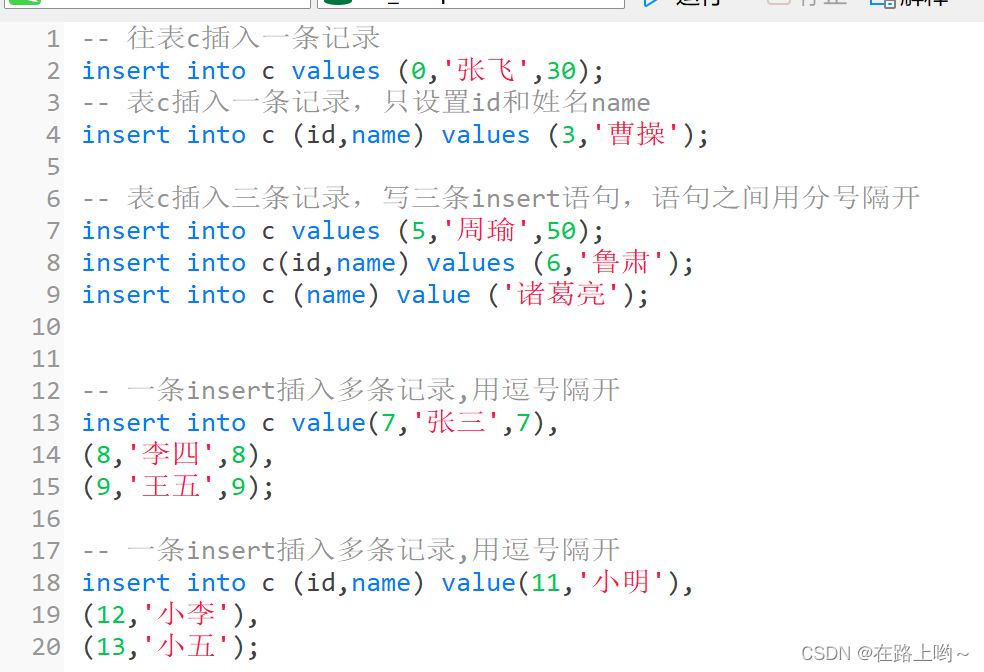
添加数据表数据
查询表
添加数据表多条数据
查询表中某数据
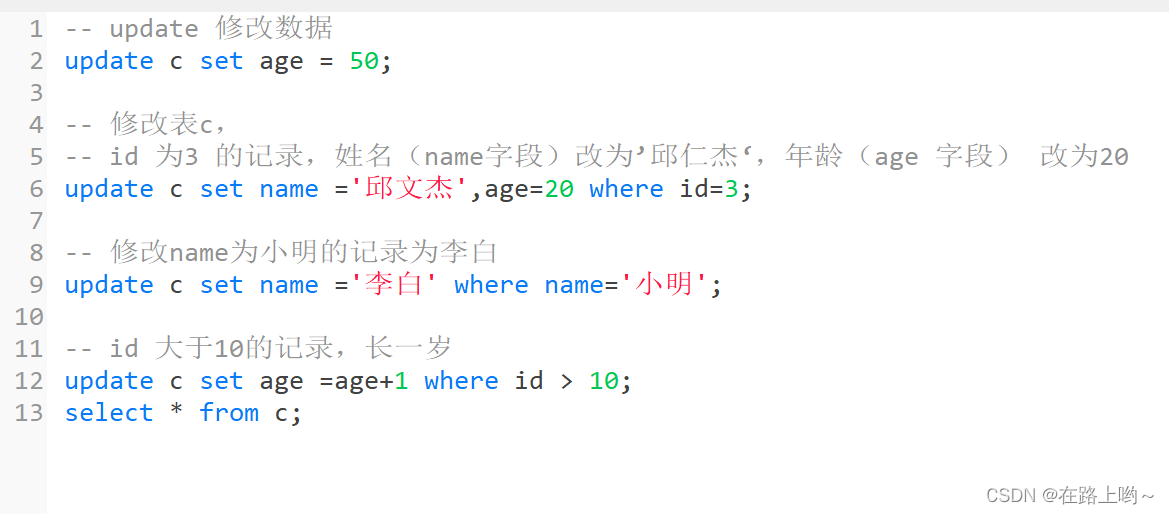
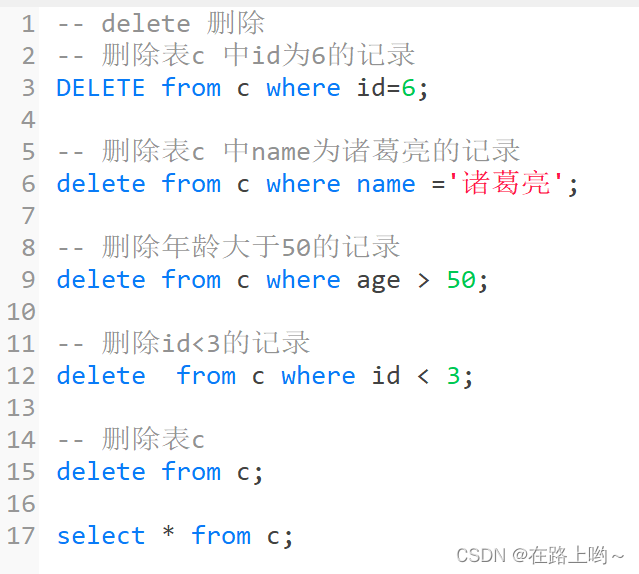
增insert 删delete 改update 查select
where
like
编辑
范围查找
order by
聚合函数
count
max
min sum avg
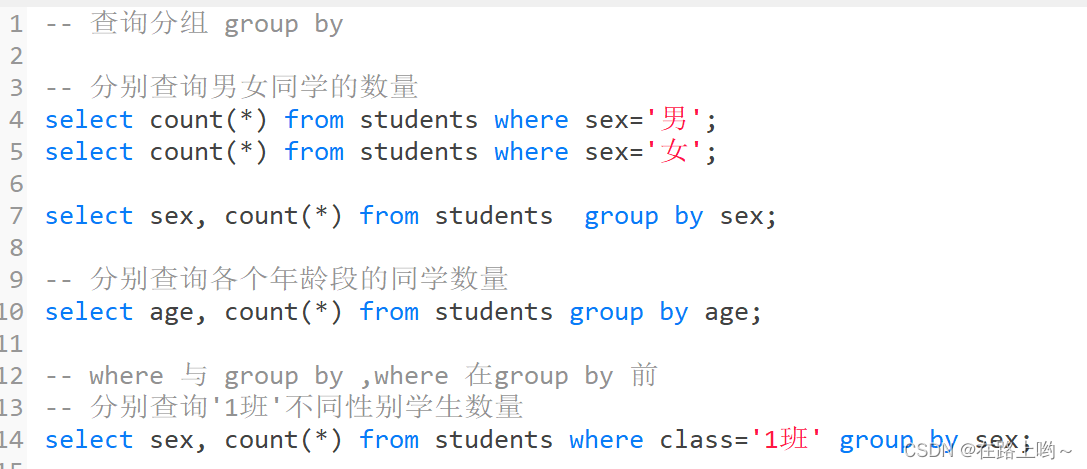
group by
having
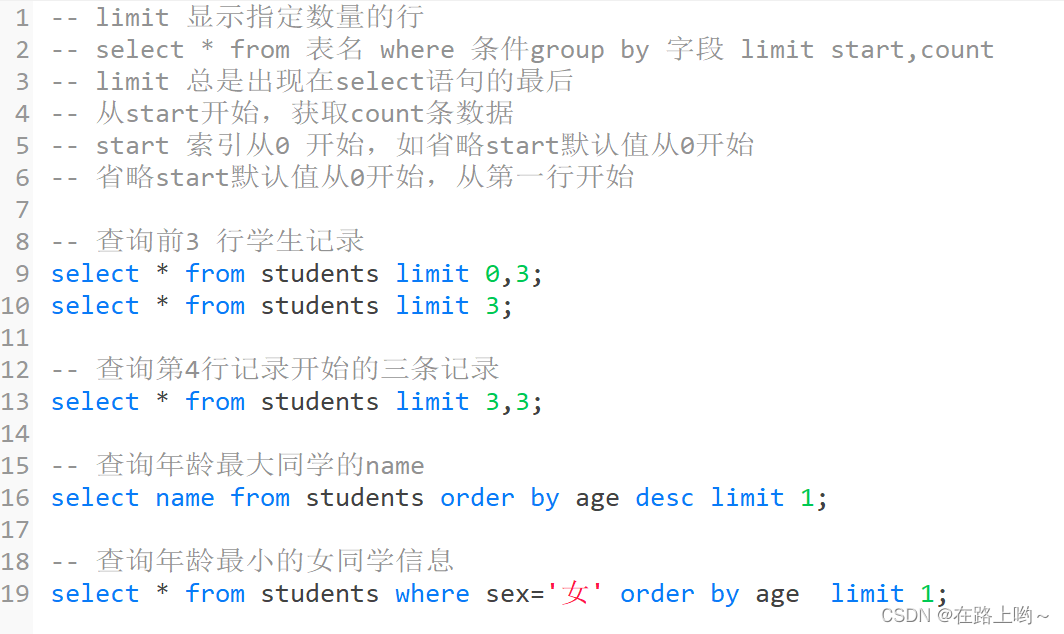
limit
空判断
视图
存储
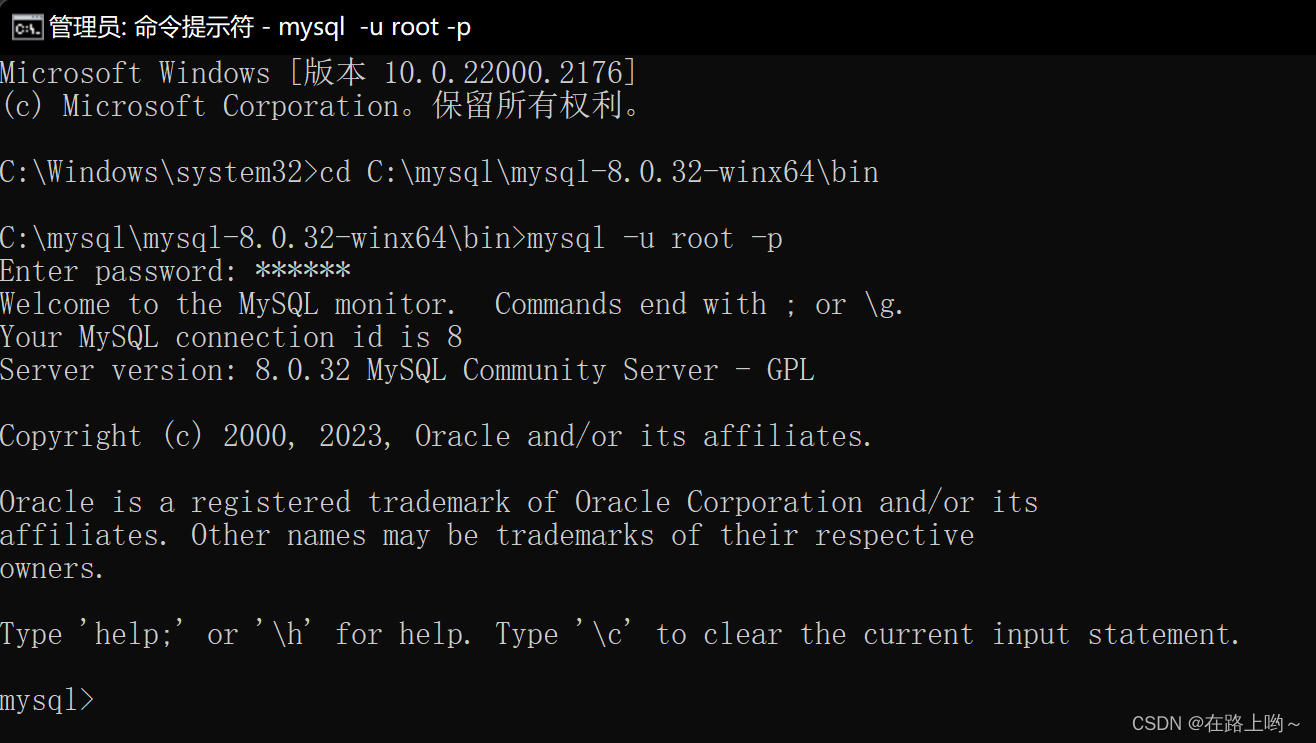
登录
mysql -u root -p
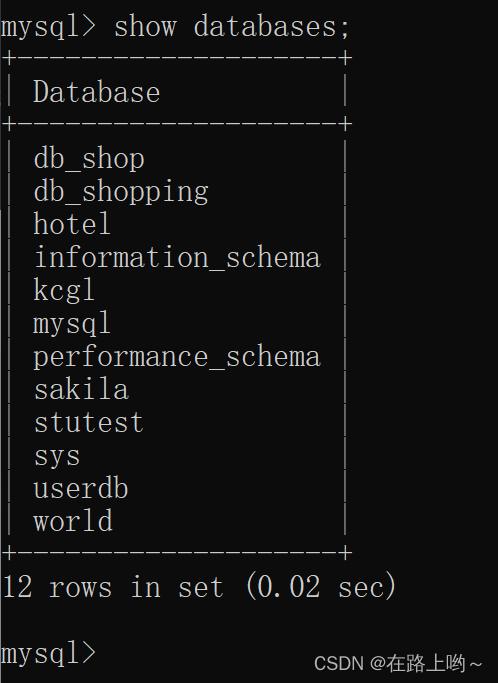
显示数据库
show databases;
创建数据库
craate database <数据库名> ;

删除数据库
drop database <数据库名> ;

使用数据库
use <数据库名>

创建表
primary key 主键
not null 非空
unique 惟一
default 默认值
auto_increment 自增长
int unsigned 无符号整数
DROP TABLE IF EXISTS staffer;
CREATE TABLE staffer (
id int NOT NULL AUTO_INCREMENT COMMENT '员工编号',
dept_id int NOT NULL COMMENT '部门编号',
staff_name varchar(10) NOT NULL COMMENT '员工名字',
sex enum('F','M') DEFAULT 'F' COMMENT '性别',
birthday date COMMENT '生日',
phone char(11) COMMENT '电话',
salary decimal(11,2) UNSIGNED DEFAULT 1.00 COMMENT '工资',
staff_memo varchar(100) COMMENT '备注',
PRIMARY KEY (id),
FOREIGN KEY (dept_id) REFERENCES department (id),
CHECK ((salary > 0) and (salary < 100000))
) AUTO_INCREMENT=10512;DROP TABLE IF EXISTS item ;
CREATE TABLE item(
item_id int AUTO_INCREMENT,
order_id int,
goods_id int,
quantity int,
total_price decimal(11, 2),
PRIMARY KEY ( item_id ),
FOREIGN KEY ( goods_id ) REFERENCES goods ( goods_id ),
FOREIGN KEY ( order_id ) REFERENCES orders ( order_id )
);添加数据表数据
INSERT INTO staffer VALUES (10501, 1, '燕南飞', 'M', '1995-09-18', '13011231890', '5000.10', '职员');
INSERT INTO staffer VALUES (10502, 2, '陈一南', 'M', '1990-09-12', '13011233333', '6000.10', '职员');
INSERT INTO staffer VALUES (10503, 4, '李思思', 'F', '1979-11-01', null, '9900.00', '总经理');
INSERT INTO staffer VALUES (10504, 1, '张燕红', 'F', '1985-06-01', '13566567456', '8000.00', '部门经理');
INSERT INTO staffer VALUES (10505, 3, '南海峰', 'M', '1986-04-01', null, '7000.00', '职员');
INSERT INTO staffer VALUES (10506, 3, '张红燕', 'F', '1982-09-21', '13823671111', '9000.00', '部门经理');
INSERT INTO staffer VALUES (10507, 2, '王南峰', 'M', '1986-04-01', '13668992222', '7000.00', '职员');
INSERT INTO staffer VALUES (10508, 5, '刘燕玲', 'F', '1981-07-01', '13823679988', '6000.00', '职员');
INSERT INTO staffer VALUES (10509, 5, '李玉燕', 'F', '1984-02-08', '13823677889', '9000.00', '部门经理');
INSERT INTO staffer VALUES (10510, 4, '王树思', 'M', '1996-04-01', '13668998888', '7000.00', '职员');
INSERT INTO staffer VALUES (10511, 1, '思灵玉', 'F', '1992-03-01', '13823679999', '6000.00', '职员');INSERT INTO item VALUES (1, 1, 1, 20, NULL);
INSERT INTO item VALUES (2, 1, 2, 2, NULL);
INSERT INTO item VALUES (3, 1, 3, 3, NULL);
INSERT INTO item VALUES (4, 2, 1, 7, NULL);
INSERT INTO item VALUES (5, 2, 2, 5, NULL);
INSERT INTO item VALUES (6, 2, 3, 6, NULL);
INSERT INTO item VALUES (7, 3, 1, 10, NULL);
INSERT INTO item VALUES (8, 3, 4, 10, NULL);
INSERT INTO item VALUES (9, 4, 1, 6, NULL);
INSERT INTO item VALUES (10, 4, 2, 3, NULL);
SET FOREIGN_KEY_CHECKS = 1;查询表
select * from staffer;添加数据表多条数据
一次性在department表中添加2条记录,分别为:(部门名称:市场部;电话:020-87993093)、
(部门名称:宣传部;电话:020-87993065)
select * from department;
insert into department (dept_name,dept_phone) values ('市场部','020-87993093'),('宣传部','020-87993065');
select * from department;查询表中某数据
在goods表中查询各商品的3件费用
-- 3件费用是商品单价*3的价格,可使用表达式计算

select goods_name,unit_price,unit_price*3 as '3件费用' from goods_; 查询goods_表第一行开始的2条记录
select * from goods_ limit 1,2;查询staffer表中姓张的员工,并显示其staff_id,staff_name,deptartment_id,sex
select staff_id,staff_name,deptartment_id,sex from staffer where staff_name like '张%';item 表,按商品和供应商分组,查询各商品的各供应商提供的销售数量和总数量
-- 分析:当汇总有2个以上字段是需要用with rollup 子句才能达到按从左到右分类的目的
select * from item;
select goods_id,order_id,sum(quantity) from item group by goods_id,order_id with rollup;增insert 删delete 改update 查select






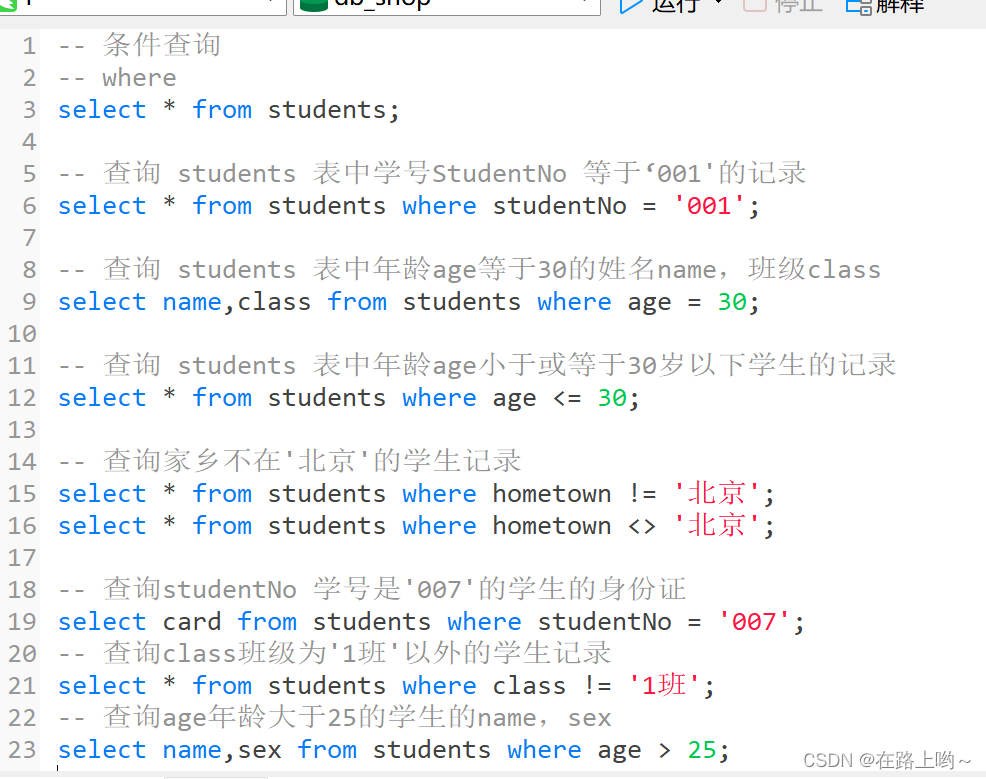
where
select 后面的"或者字段名,决定了返回什么样的字段(列):
select 中 where 子句,决定了返回什么样的记录(行);

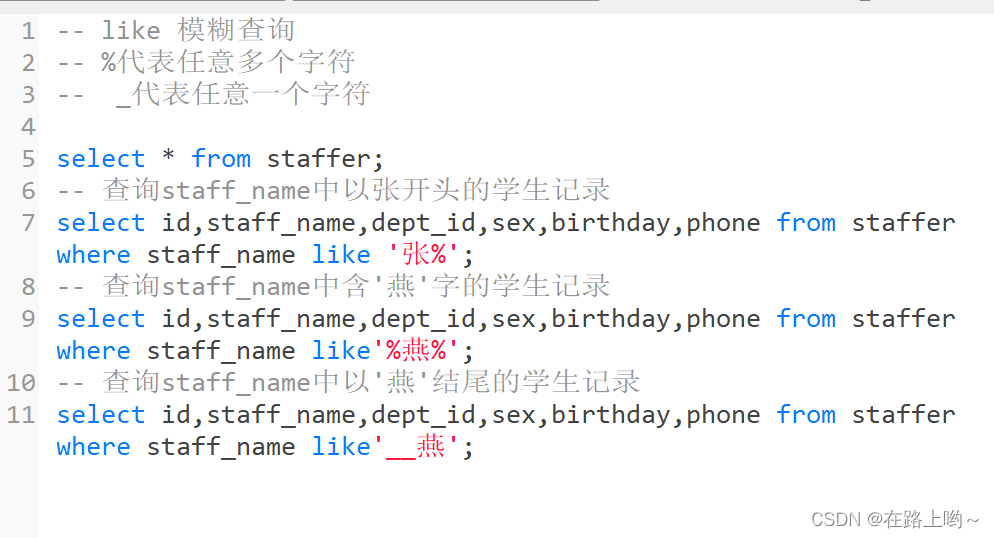
like
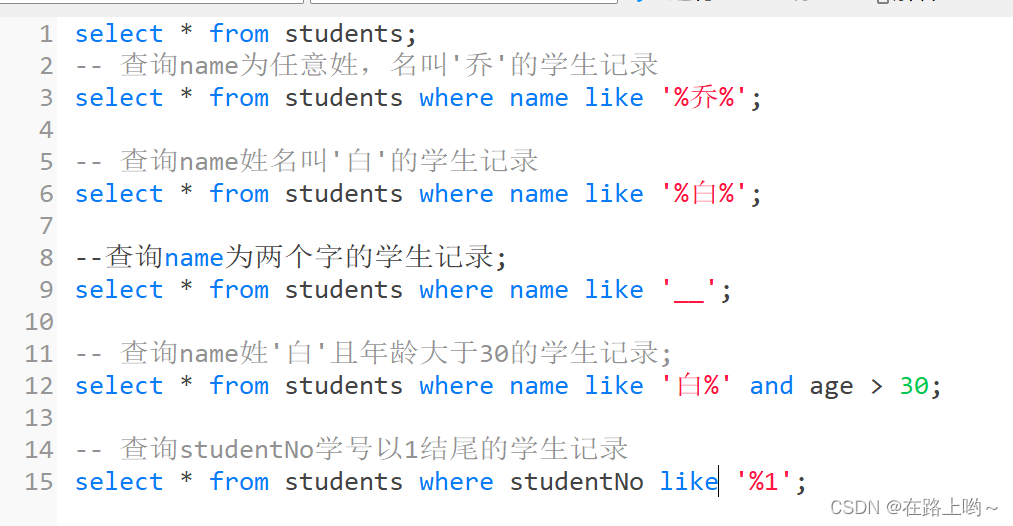
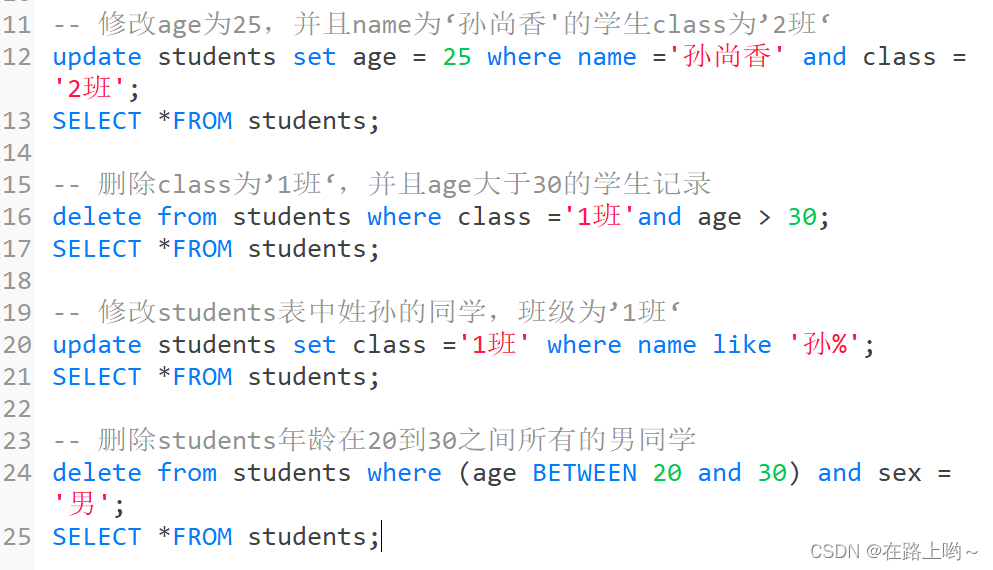
范围查找

order by
当一条select语句出现了where和order by
select * from 表名 where 条件 order by 字段1,字段2;
一定要把where写在order by前面
asc 从小到大 可以省略
desc 从大到小
默认从小到大 (asc)

聚合函数
count

max

min sum avg



group by
select 聚合函数 from 表名 where 条件 group by 字段
select 聚合函数 from 表名 group by 字段
group by就是配合聚合函数使用的
where和group by 和order by的顺序:
select * from 表名 where 条件 group by 字段 order by 字段

having
having子句
总是出现在group by之后
select * from 表名 group by 字段 having 条件
对比 where 与 having:
where 是对 from 后面指定的表进行数据筛选属于对原始数据的筛选having 是对 group by 的结果进行筛选;
having 后面的条件中可以用聚合函数,where 后面的条件不可以使用聚合函数。
having语法:
select 字段1,字段2,聚合...from 表名group by 字段1,字段2,字段3...
having 字段1,...聚合...


limit
空判断
null不是0,也不是",null在SQL里面代表空,什么也没有
null不能用比较运算符的判断
is null ---是否为null
is not null ---是否不为null
(不能用字段名 = null 字段名 != null这些都是错误的)

视图
建立部门员工视图,显示部门名称和员工对外查阅资料 | staffer 表和 department 表
select * from staffer;
select * from department;
drop view if exists v_staffer;
create view v_staffer
as select dept_name,staff_name,sex,phone from staffer
inner join department on staffer.deptartment_id=department.dept_id;
select * from v_staffer;
存储
创建带入in 参数和输出 out 参数的存储过程
-若需要从存储过程中返回一个或多个检索或统计的值,则可以使用代out关键字定义的输出参数,将返回值传回调用环境
在数据库db_shop中建立一个存储过程,能够通过部门编号统计该部门员工的人数,返回统计值,并调佣该存储过程
-- 分析:部门编号是输入参数,统计的员工人数是输出参数
drop procedure if exists p_count;
delimiter //
create procedure p_count(in id int,out n int)
BEGIN
select count(*) into n from staffer where deptartment_id=id;
end //
delimiter ;
call p_count(1,@a);
select @a as '1号部门员工数';
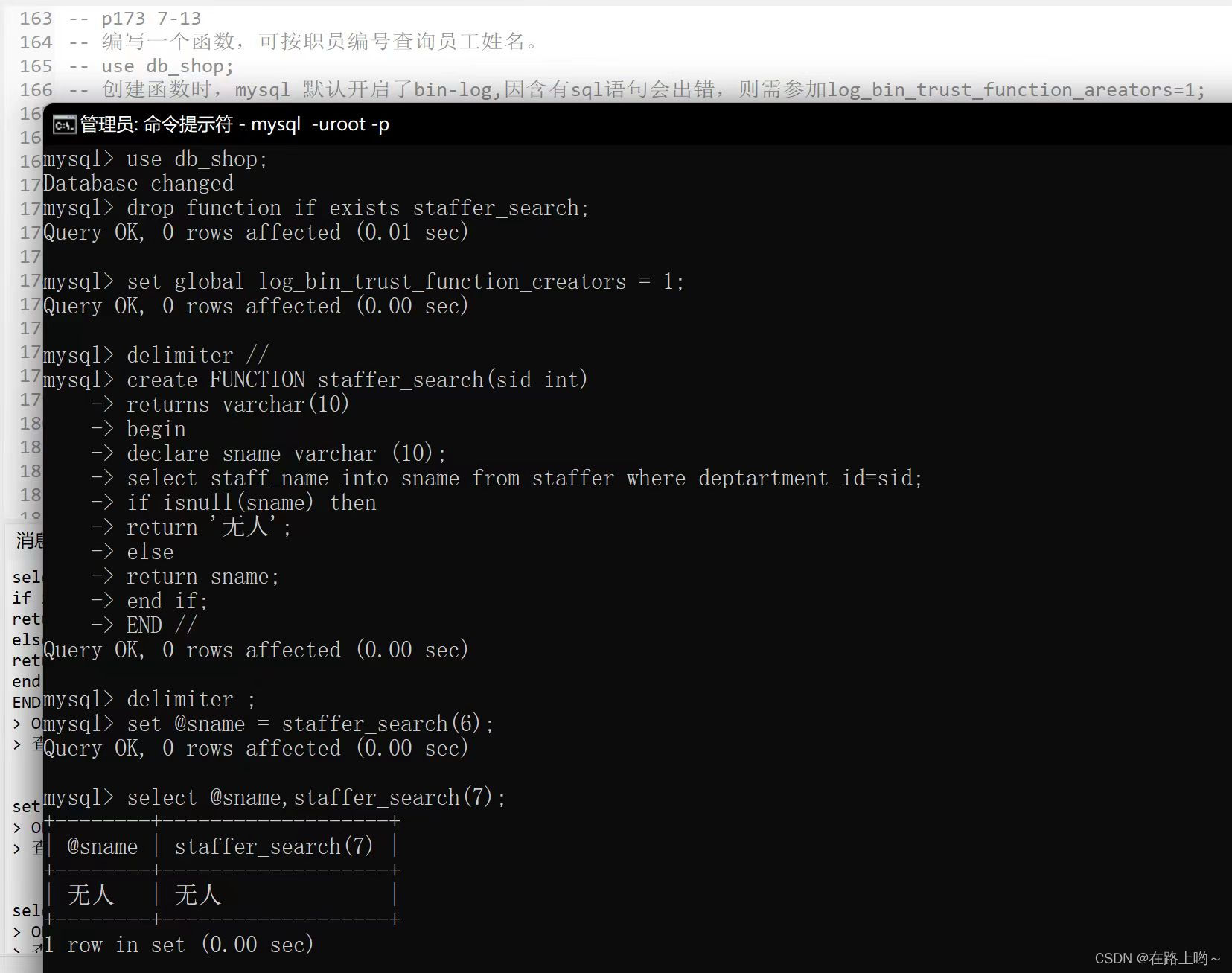
编写一个函数,可按职员编号查询员工姓名。
use db_shop;
-- 创建函数时,mysql 默认开启了bin-log,因含有sql语句会出错,则需参加
drop function if exists staffer_search;
set global log_bin_trust_function_creators = 1;
delimiter //
create FUNCTION staffer_search(sid int)
returns varchar(10)
begin
declare sname varchar (10);
select staff_name into sname from staffer where deptartment_id=sid;
if isnull(sname) then
return '无人';
else
return sname;
end if;
END //
delimiter ;
set @sname = staffer_search(6);
select @sname,staffer_search(7);