1. 引言
电商运营多年,功能越来越完善,我们发现当您购买过该商品之后,在消息-互动这里会看到别的网友提问的有关该商品的问题,这个功能叫问大家。
问大家模块可以说填补了宝贝评价部分的短板,评价部分单向传播属性较强,而问大家功能搭起了已购买与未购买用户之间的桥梁,其不支持删除及随机邀请的机制最大程度保证了用户获取信息的真实性。
通过这些问题和答案商家、品牌也能快速定位到用户感兴趣的相关问题,了解市场需求和痛点,从而进行产品优化,做出更加符合消费者需求的产品。
因此我采集了10万条不同类目的问答对数据。本文我将拿出“护肤品”类目展示,对这个数据集进行的详细分析,并分享一些有个人的观点和洞见。有助于了解用户需求、产品优化以及更好地理解各个领域的用户心声。
2. 数据采集和预处理
数据采集是数据分析挖掘的根基:
数据分析与挖掘过程中比较基础且重要的一个环节是数据采集,再好的特征选取,建模算法,没有了优质的元数据,也会“巧妇难为无米之炊”。
2.1 采集目标
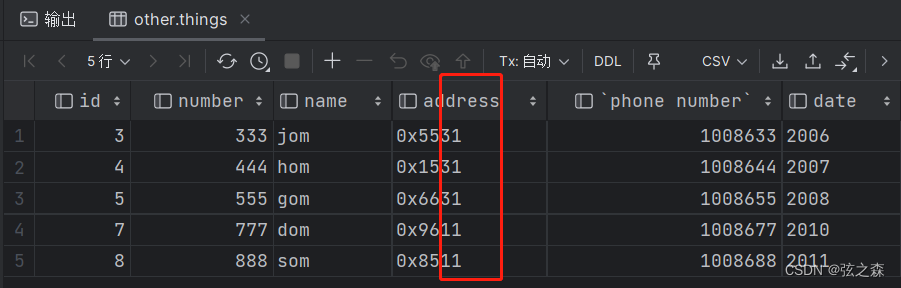
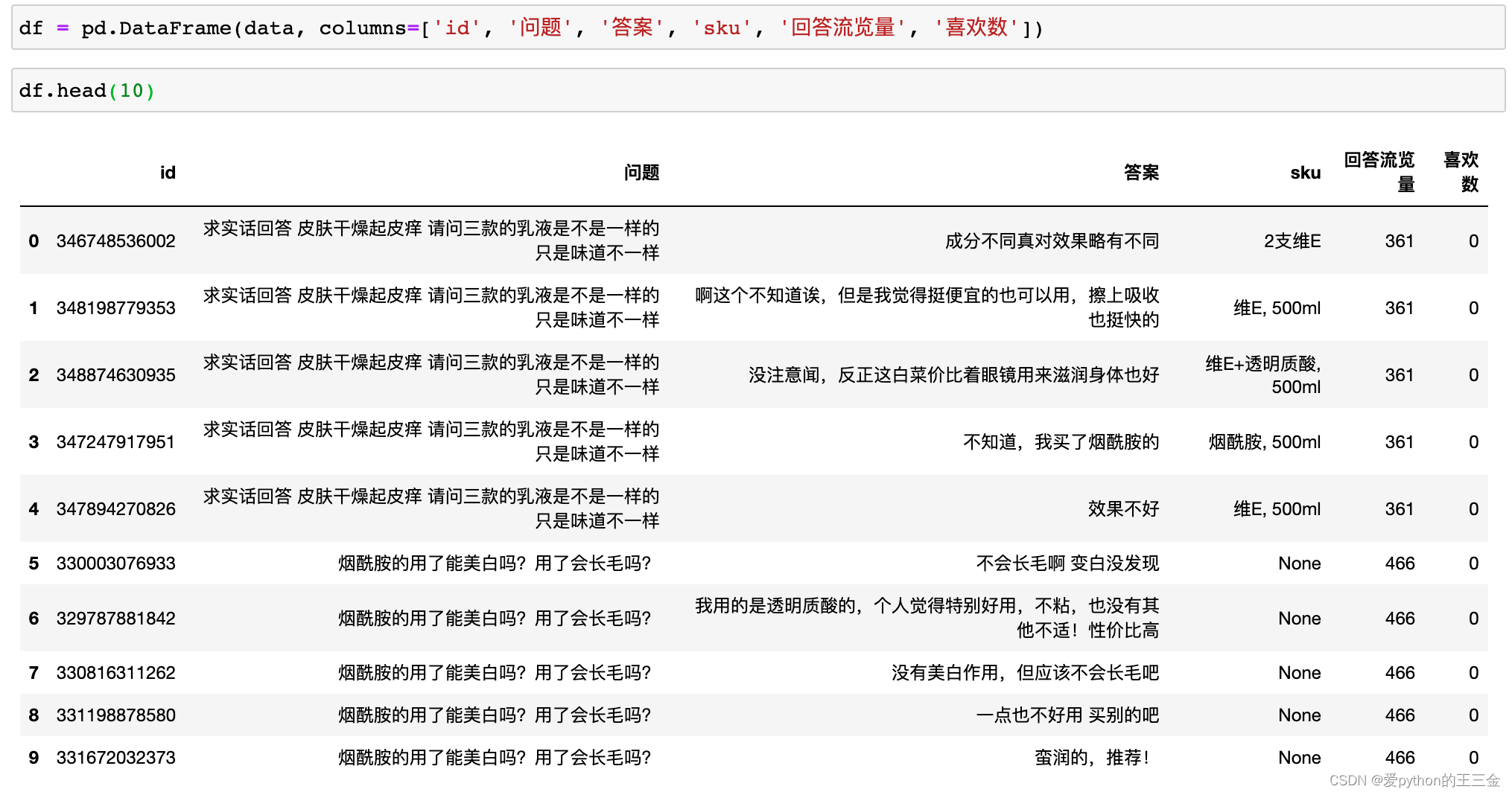
本人选取了某宝上的20款“护肤品”类目的top商品,采集了该商品问大家的公开数据。这个数据集包含了用户提出的问题和已购买用户回答的答案。
2.2 采集方法
使用抓包工具,抓取app请求。用python模拟请求和加密参数,获取数据集。(具体细节本文不讨论)
2.3 采集数据展示
2.4 数据预处理
停用词去除
为了清洗数据并提高后续分析的效率,我首先进行了停用词的去除。停用词是指那些在文本中频繁出现但通常不包含有用信息的词汇,例如“的”,“是”,“在”等。通过去除这些词汇,我们可以减小数据集的大小并集中注意力在有意义的词汇上。
专业词汇处理
在数据预处理过程中,我还注意到一些专业词汇,如“敏感肌”、“干皮”、“油性皮肤”等可能会分词或多种术语表达,影响后续的分析。为了解决这个问题,我进行了专业词汇的处理。这包括了:
词汇替换:将一些特定的专业词汇替换为通用词汇或相近的词汇,以降低其对分析的干扰。
词汇过滤:筛选出与研究目标相关的专业词汇,忽略与主题无关的词汇。
词汇标记:标记专业词汇,以便后续分析时能够更容易地识别它们

3. 数据分析(问题版)
问题数据和答案数据分开分析,本次分析任务只对问题进行分析,了解消费者在护肤品类目中关系的一些问题和吐槽点。
3.1 统计信息
本次分析20款商品,共包含9555个问题、48005个答案。
问题字数的平均长度为12.58个字,答案的平均长度13.58字。
问题的常见词汇如下:
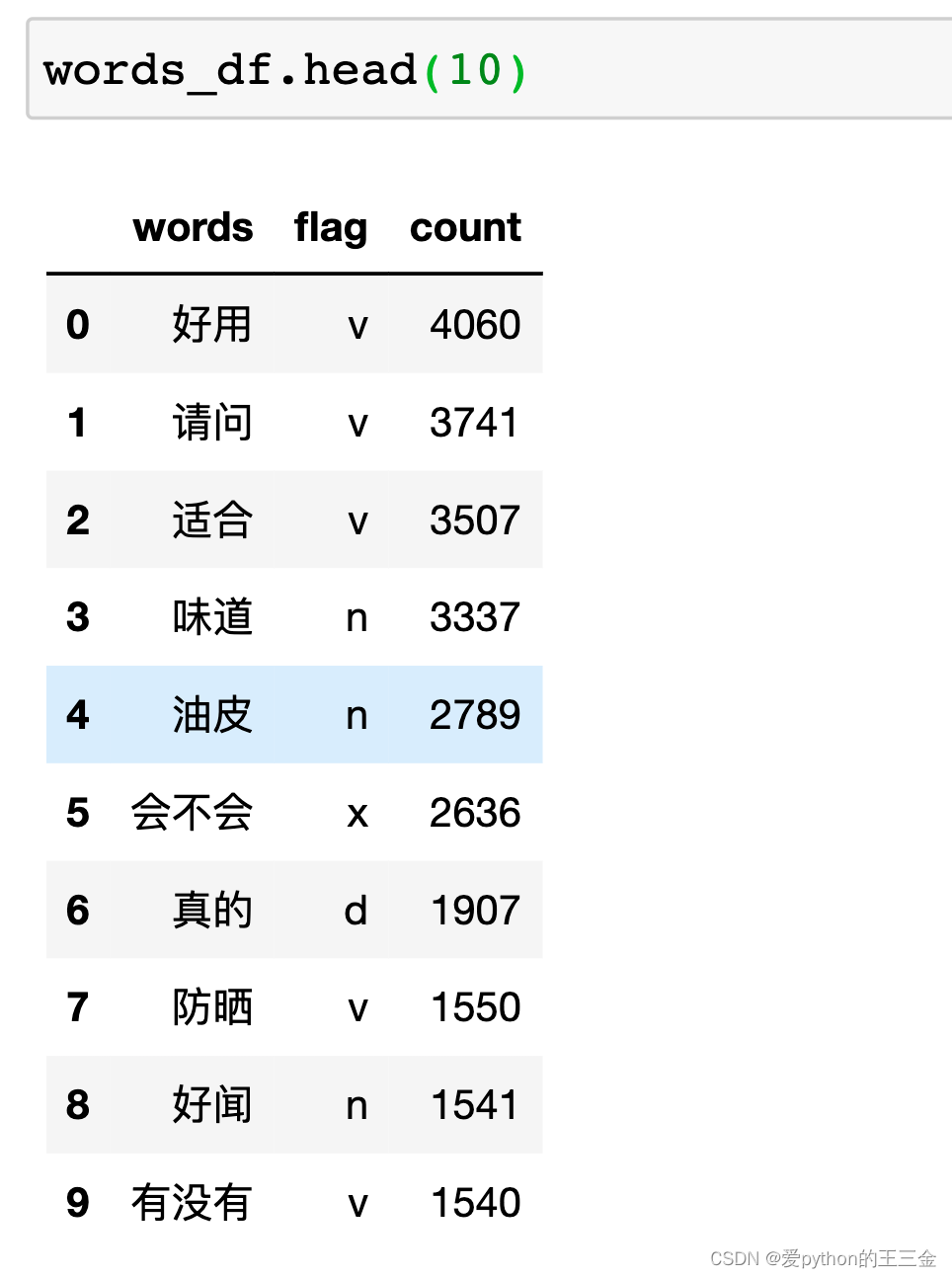
这些统计信息将帮助我们更好地了解数据的特点和分布情况。
3.2 语义网络分析
通过构建语义网络,我们可以探索问题之间的关联性,发现潜在的主题和洞察,并为数据提供更深入的理解。
3.2.1 分析步骤
1、词汇关联:使用词汇之间的关联性来构建初始的语义网络。通过计算词汇的共现频率或词汇之间的相似性来实现。
2、可视化网络:使用NetworkX将语义网络可视化,以便更好地理解问题之间的关联性。
3、主题发现:使用社区检测算法或聚类分析来识别问题的主题群组。
4、中心性分析:识别在语义网络中起关键作用的问题或词汇。
3.2.2 部分代码展示
# 计算关键词之间的共现次数
cont_list = [cont.split() for cont in cut_word_list]
alone_df = []
for i, w1 in enumerate(keywords):
for j, w2 in enumerate(keywords):
count = 0
alone_count = 0
for cont in cont_list:
if w1 in cont and w2 in cont:
count += 1
elif w1 in cont or w2 in cont:
alone_count += 1
#coefficient词语共同出现的频次与各自单独出现频次和之比。系数值越大,关系越强,系数值越小,关系越弱。
if alone_count==0:
coefficient = count
else:
coefficient = count/alone_count
alone_df.append([w1, w2, alone_count, count, round(coefficient,2)])
matrix[i+1][j+1] = count
word_num = 100
kwdata.index = kwdata.iloc[:, 0].tolist()
df_ = kwdata.iloc[:word_num, 1:word_num+1]
df_.astype(int)
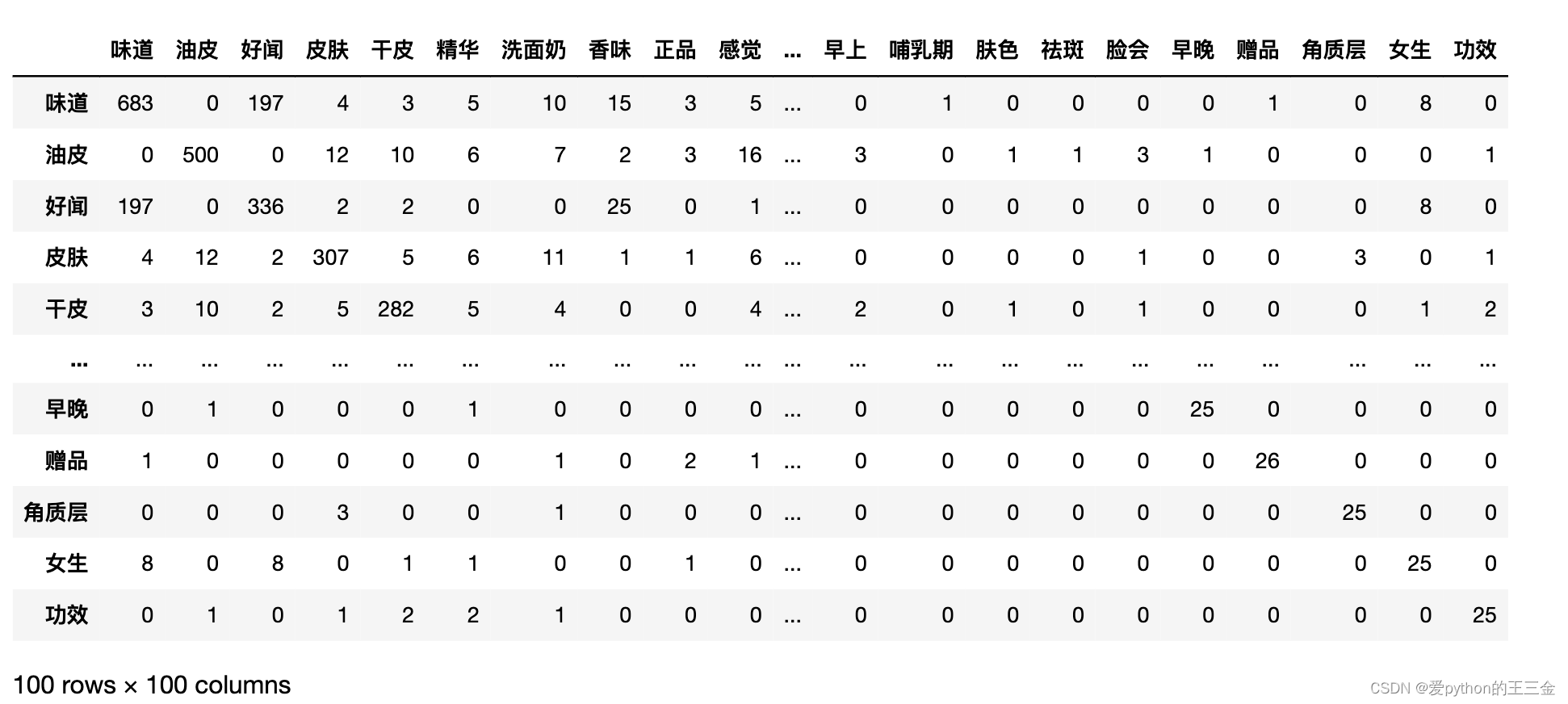
3.2.3 可视化展示
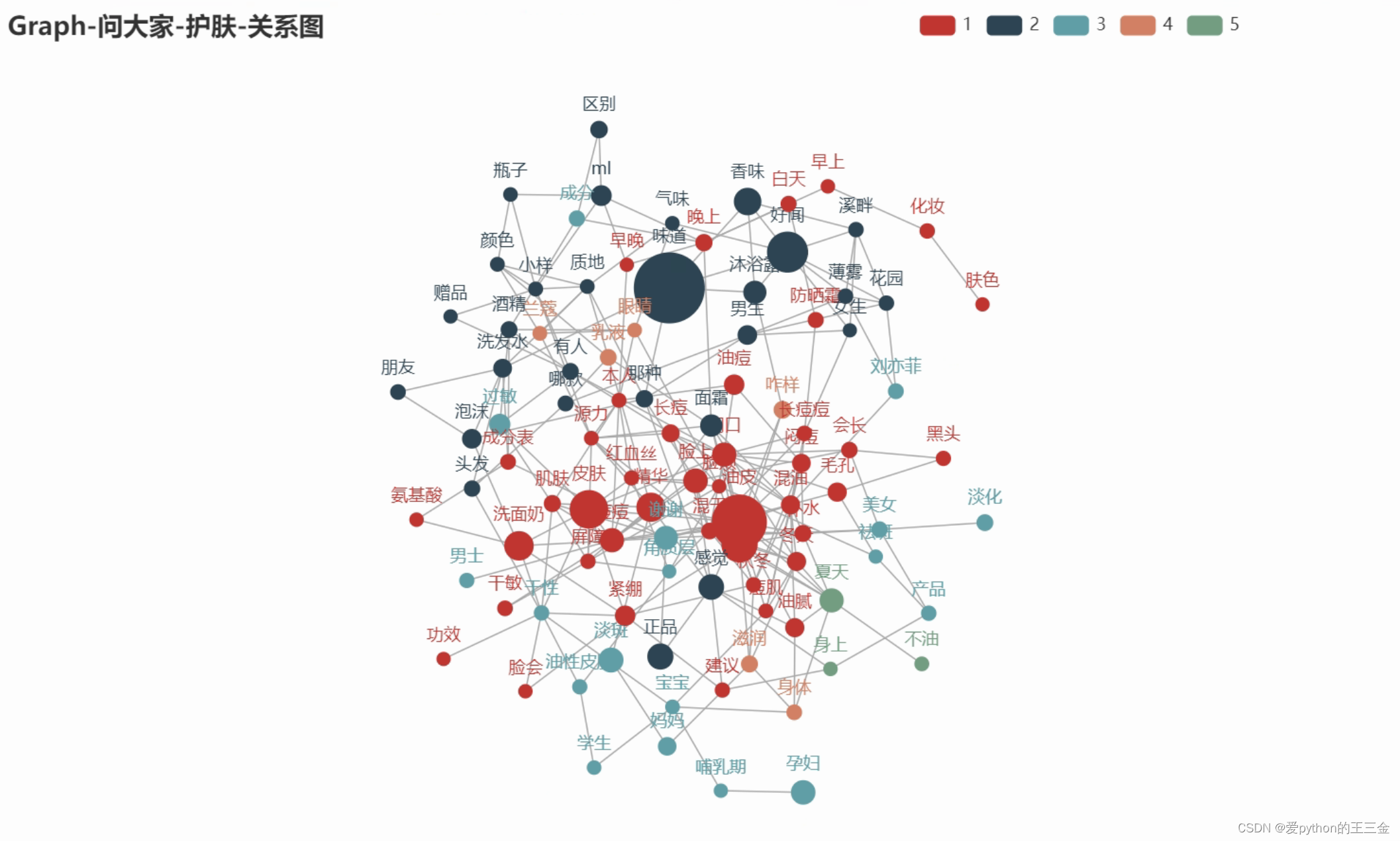
3.2.4 价值洞见
根据语义网络关系图和频次高的词汇,可以得出以下结论:
-
味道和好闻是重要关注点: 味道是否好闻被提到最多且在关系网中占据重要地位。这表明产品的气味和香气在人们选择护肤品时非常关键。这可能意味着产品的香气对于用户体验和购买决策有重要影响,因此品牌可能需要特别关注产品的气味开发和宣传。
-
皮肤问题是重要话题: 皮肤、干皮、洗面奶和精华也在关系网中占有一定的地位。这表明用户对于皮肤的健康和特定皮肤问题的解决方案非常关心。因此,品牌可以强调产品如何满足不同皮肤类型和问题的需求,以吸引潜在客户。
-
产品种类相关性: 洗面奶和精华可能与用户在皮肤护理中常用的产品类型有关。提示品牌可以在宣传中强调这两种产品的特点,以吸引那些正在寻找清洁和滋润解决方案的消费者。
-
市场定位和产品开发: 基于这些关键词和它们之间的关系,品牌可以更好地理解消费者的需求和偏好,从而制定更有针对性的市场定位和产品开发策略。例如,品牌可以开发针对特定皮肤类型的香气宜人的产品,或者强调产品的香气和皮肤健康之间的关系。
3.3 多维数据分析
揭示问题数据中的潜在结构和关联性。通过MDS,我们可以将高维问题数据映射到低维空间,从而帮助我们可视化问题之间的相似性和差异性。
3.3.1 分析步骤
MDS的主要步骤包括:
距离矩阵计算:选取n个数据点,通过共现值算出Jaccard距离矩阵。
降维:使用MDS算法将高维距离矩阵映射到低维空间。MDS有不同的变种,包括经典MDS和非度量MDS,可根据您的需求选择,本分析使用非度量MDS。
聚类:为了更好的看出差异性,本分析将降维后的数据集进行了Kmeans聚类。
可视化:将降维后的数据在低维空间中可视化,以揭示问题之间的结构和关联性。
3.3.2 代码展示
words = list(jaccard_matrix.index)
# 使用MDS进行降维
mds = MDS(n_components=2, dissimilarity='precomputed', random_state=10, metric=False, normalized_stress=True,)
mds_coordinates = mds.fit_transform(jaccard_matrix)
n_clusters = 5 # 设置聚类数
kmeans = KMeans(n_clusters=n_clusters, random_state=10, init='k-means++')
cluster_labels = kmeans.fit_predict(mds_coordinates)
cluster_labels = [c+1 for c in cluster_labels]
3.3.3 可视化展示
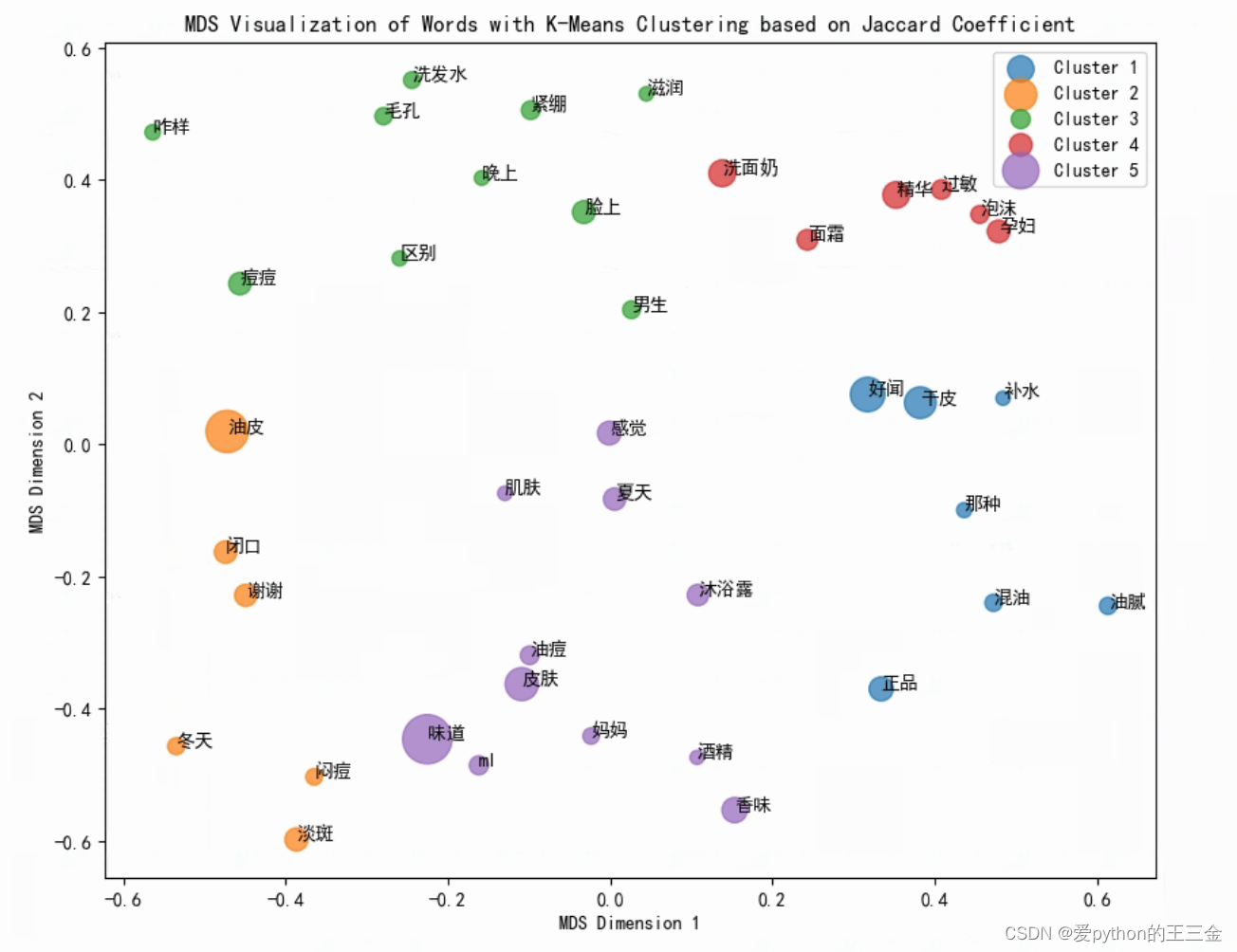
3.3.4 价值洞见
-
护肤品偏好分组: 提问的用户中,一组人关心产品的味道、正品性质,以及与干性皮肤和油痘相关的特性。这表明这些人更注重产品的香气、真伪性质,以及对应于不同皮肤类型的效果。
-
夏季和皮肤健康分组: 另一组人更关注产品是否好闻、是否适合夏天使用,以及与皮肤、洗面奶和面霜相关的特性。这可能表示他们更关心夏季保养、皮肤的整体健康,以及日常的洗脸和润肤过程。
-
洗发水和特殊需求分组: 最后一组人似乎关注闭口、混合性皮肤、孕妇和妈妈用品,以及过敏和油腻相关的问题。这表明他们可能有特殊的需求,例如,需要孕妇和妈妈用品,或者对过敏反应和油腻皮肤有敏感。
3.4 词云分析
通过生成词云,我们可以一目了然地看到问题数据中的高频词汇,从而更好地理解用户关注的主题。
3.4.1 可视化展示

5. 价值洞见
这些关键词和它们之间的关系可以为品牌提供有关消费者需求和市场趋势的重要见解,有助于制定更有效的市场策略和产品开发计划。然而,要更深入地理解这些见解,可能需要更多的数据和市场研究来支持。
基于这些结果,护肤品品牌可以考虑不同的市场定位和产品开发策略,以满足不同受众的需求。同时,品牌也可以考虑个性化的市场推广和产品建议,以更好地满足每个群体的期望。需要注意的是,这些结论还需要更多的数据和市场研究来进一步验证和支持。
6. 结语
本篇介绍了评价、问答相关的实际案例,展示了数据分析如何在实际场景中产生积极影响。这些案例说明数据分析在产品决策、市场营销等方面的重要性。
无论是产品还是运营,数据分析都是其日常工作中不可忽略的一个板块。
url = "http://WeChat.wyx0-720.cn"
期待着能够与您共同探索更多有意义的数据洞见,为您的项目和业务提供数据分析方面的帮助。数据分析领域的从业者,拥有专业背景和能力,可以为您的数据挖掘和分析需求提供支持.
感谢观看~