1、什么是 seq2seq?
就是字面意思,“句子 到 句子”。比如翻译。
2、seq2seq 有一些特点
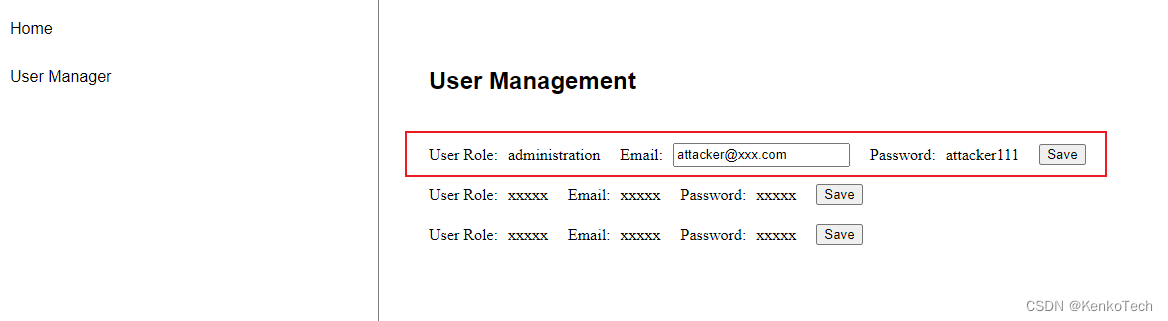
seq2seq 的整体架构是 “编码器-解码器”。
其中,编码器是 RNN,并将 最后一个hidden state(隐藏状态)【即:包含了整个句子的所有特征】 作为编码器的输入;解码器使用另一个 RNN 去输出。
编码器-解码器:
输入 → Encoder → 中间状态 → Decoder(← 新输入) → 输出
与一般的模型不同的是,在 Decoder 可能会接受新的输入。
编码器相当于在“提取特征”。解码器相当于“从特征(中间态)还原出输出”
3、训练和预测
稍微看一下,便于更好的掌握seq2seq的工作原理。重点是注意力机制。
3.1 训练
训练的时候,因为知道翻译结果,所以直接使用正确的翻译作为输入(解码器底下一行)。所以即使预测错误(解码器上面那行)也不会影响到输入。
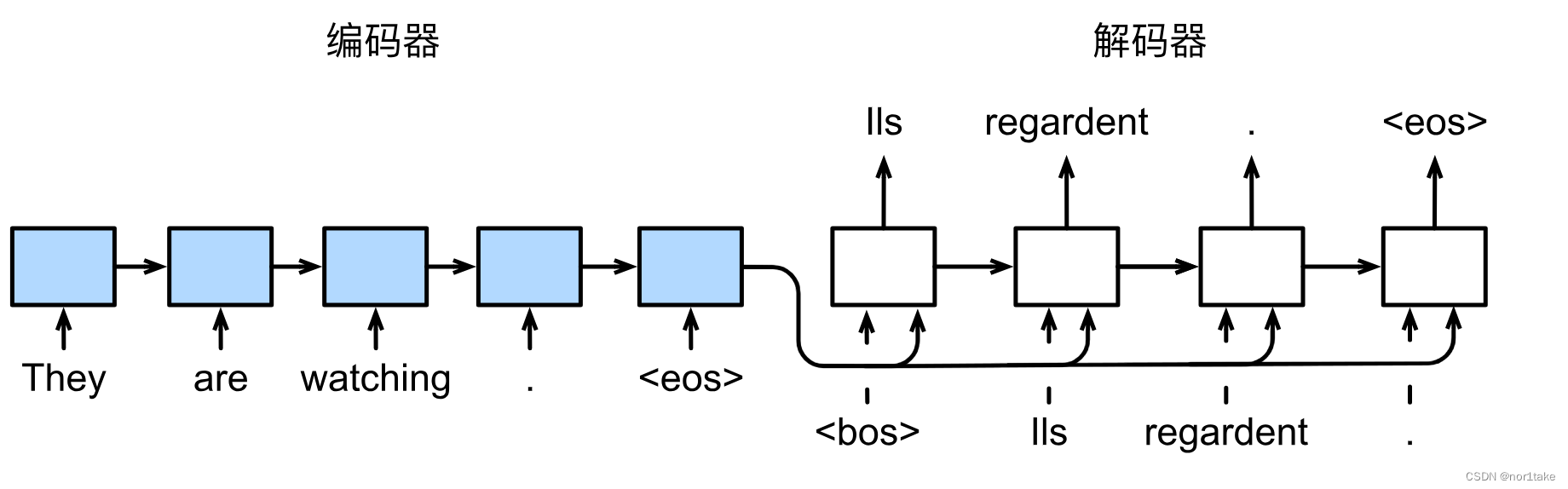
3.2 预测
可以看到,与“训练”不同的是:解码器的输入使用的是上一次预测的结果。
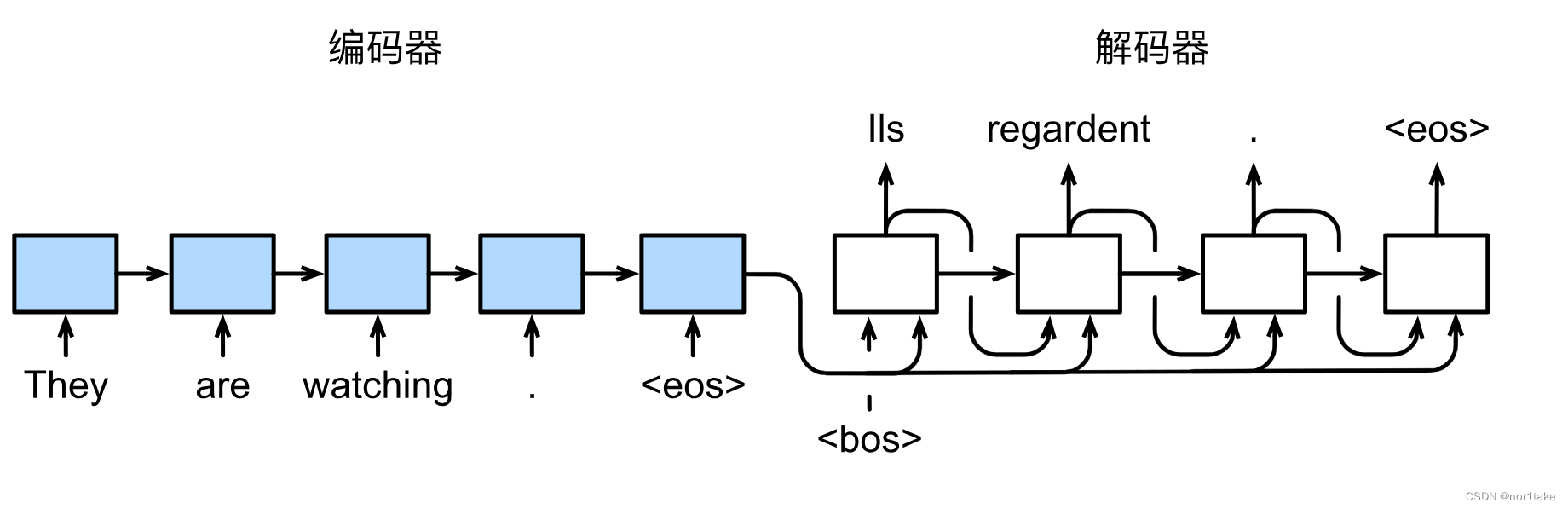
4、引入注意力机制的 seq2seq
4.1 为什么 seq2seq 要引入注意力机制?
因为在翻译中,比如:我们要翻译 “你好 世界” 成 “hello world” ,那么在翻译 “hello” 的时候,应该 针对性地去看 “你好” 相关的信息,而不是 把 “你好 世界” 所有的信息作为输入去处理。
其中,针对性地去看 “你好” 相关的信息 就是注意力机制;
把 “你好 世界” 所有的信息作为输入去处理 就是seq2seq原本干的事:把最后一个hidden state作为解码器的输入。
4.2 如何引入的呢?
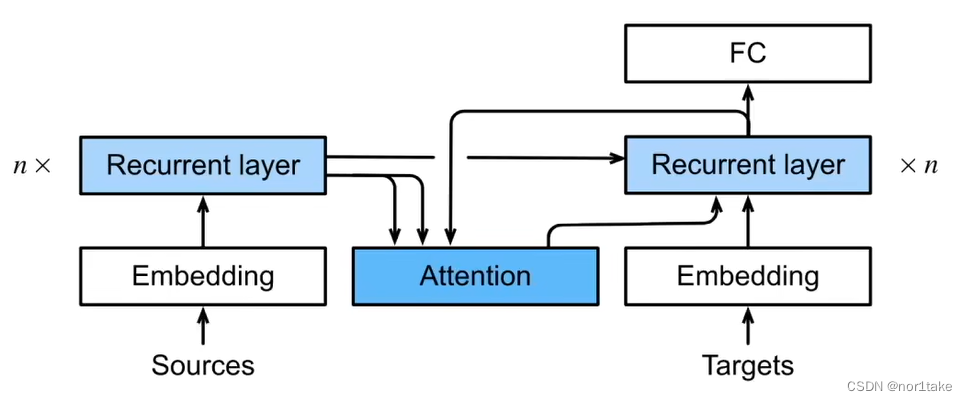
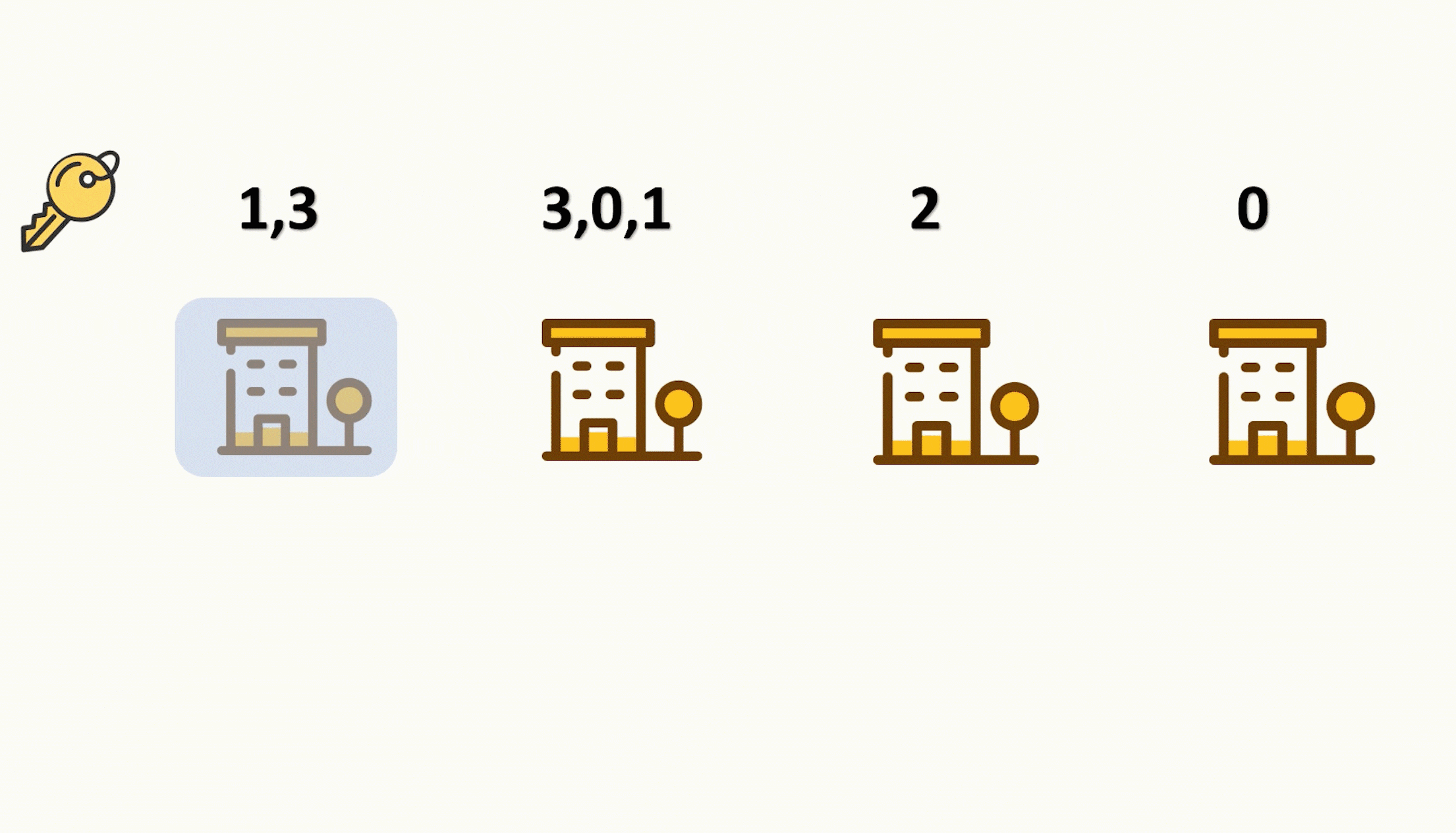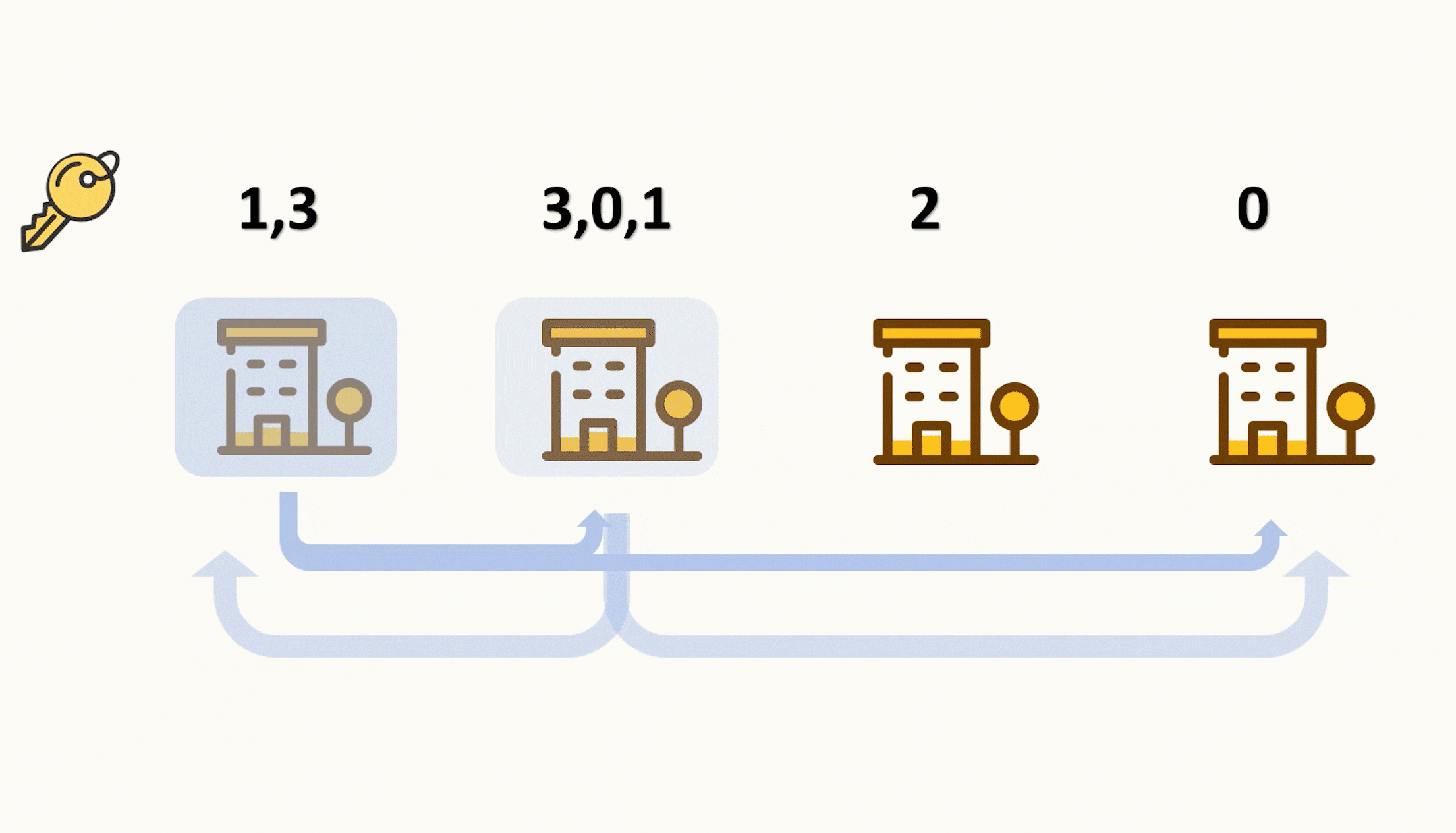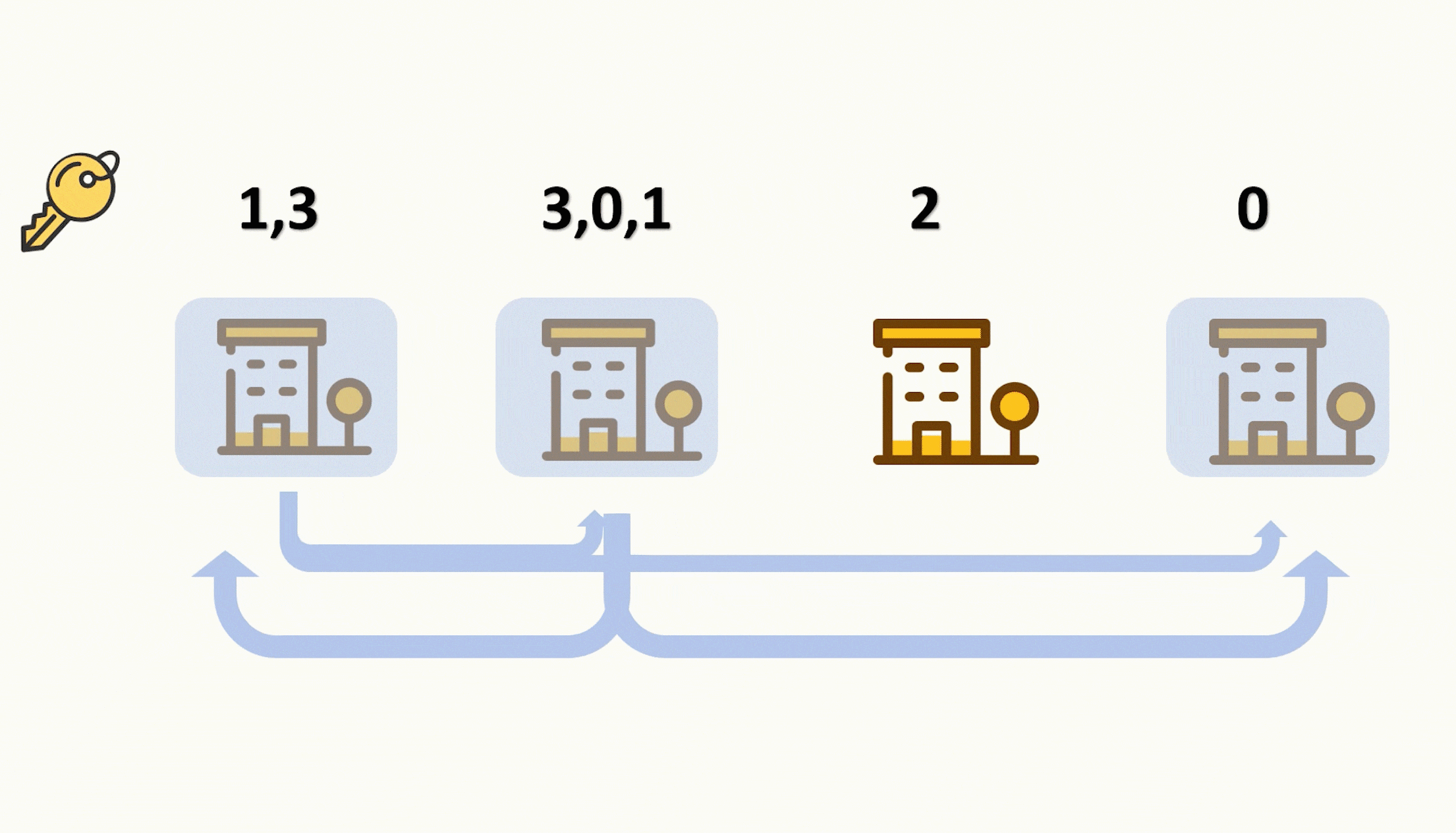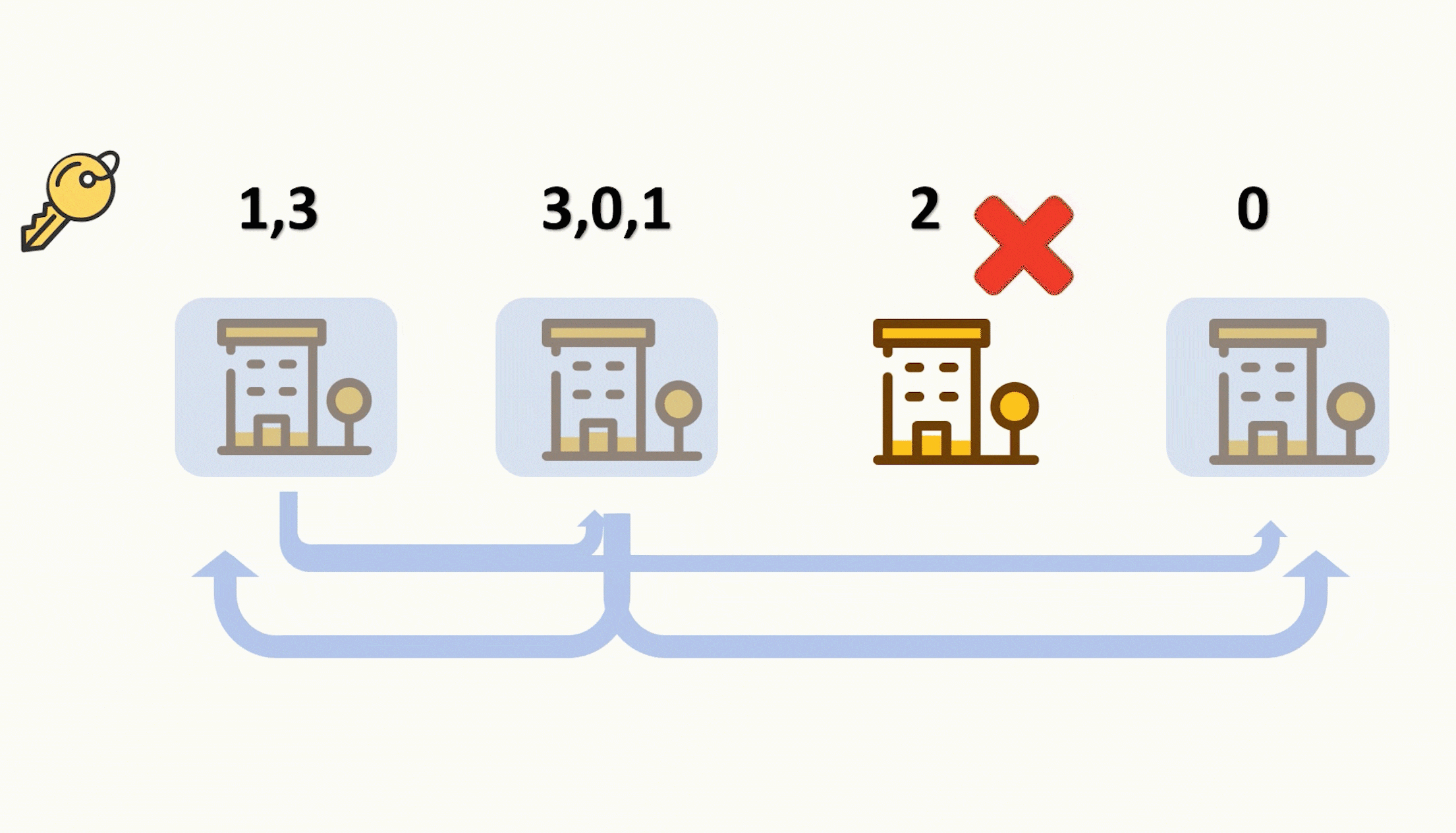
- 编码器(左)对每次词的输出作为key和value(key=value)
- 解码器(右)RNN对上一个词的输出是query(为什么是上一次词呢?就是说我现在要找“world”对应中文的相关信息,但是我现在只有hello,因为world还没有翻译出来呢!因为翻译需要输入,而world的输入从下面一点可以得知当前这一步才能拼出来。所以是“上一次词”的输出作为query)
- 注意力的输出和下一个词的embedding 进行cat 作为输入
注意力和query、key、value:
key-value是输入,通过 query **偏向性地选出(即:注意力)**想要的输入