目录
- 认识全文检索
- 概念
- lucene原理
- 全文检索的特点
- 常见的全文检索方案
- Lucene
- 创建索引
- 导包
- 分析图
- 代码
- 搜索索引
- 分析图
- 代码
- ElasticSearch
- 认识ElasticSearch
- ES与Kibana的安装及使用说明
- ES相关概念理解和简单增删改查
- ES查询
- DSL查询
- DSL过滤
- 分词器
- IK分词器
- 安装
- 测试分词器
- 文档映射(字段类型设置)
- ES字段类型
- 默认映射
- kibana
- Java操作ES
- 导入依赖
- crud实现
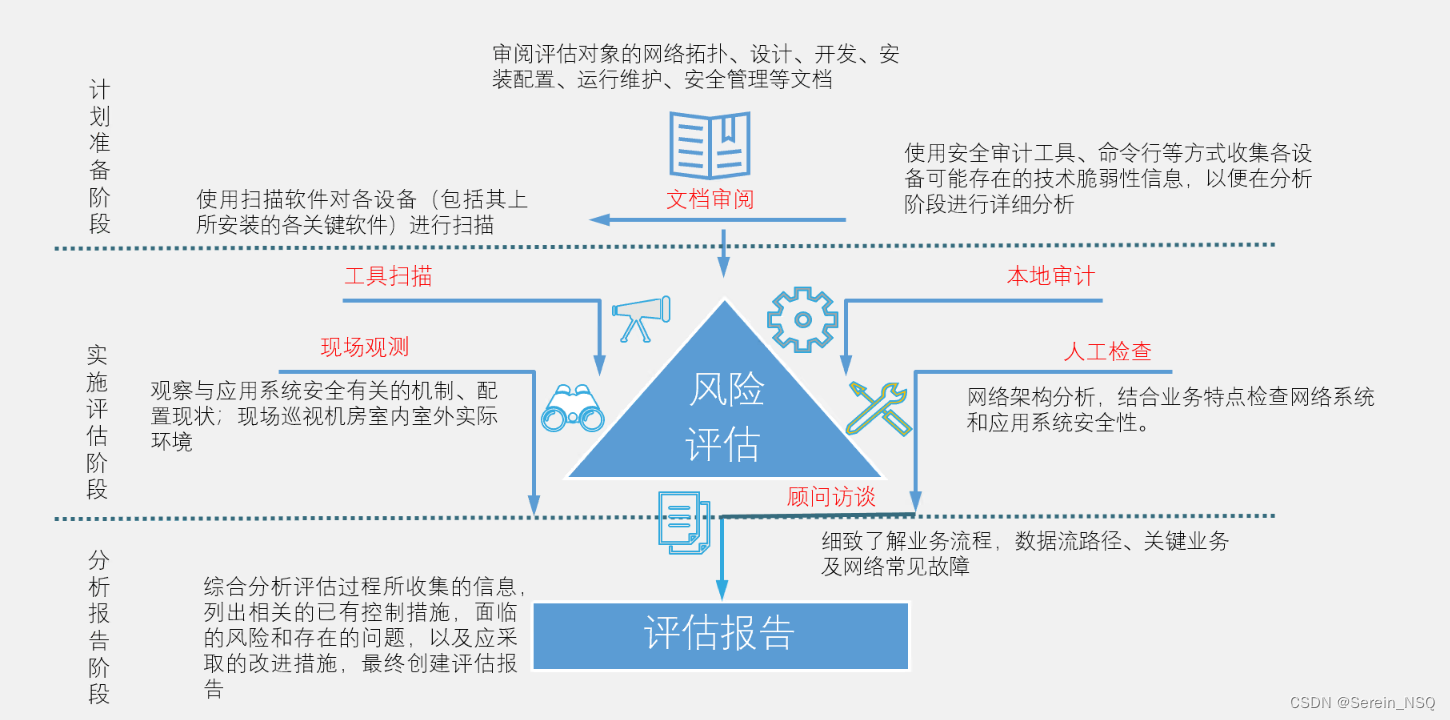
认识全文检索
概念
对非结构化数据的搜索就叫全文检索,狭义的理解主要针对文本数据的搜索。
非结构化数据:
没有固定模式的数据,如WORD、PDF、PPT、EXL,各种格式的图片、视频等。
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息等等
理解:可以理解为全文检索就是把没有结构化的数据变成有结构的数据,然后进行搜索,因为有结构化的数据通常情况下可以按照某种算法进行搜索。
lucene原理


全文检索的特点
相关度最高的排在最前面,官网中相关的网页排在最前面; java
关键词的高亮。
只处理文本,不处理语义。 以单词方式进行搜索
比如在输入框中输入“中国的首都在哪里”,搜索引擎不会以对话的形式告诉你“在北京”,而仅仅是列出包含了搜索关键字的网页。
常见的全文检索方案
全文搜索工具包-Lucene(核心)
全文搜索服务器 ,Elastic Search(ES) / Solr等封装了lucene并扩展
Lucene
创建索引
导包
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.5.0</version>
</dependency>
分析图

代码
//创建索引
@Test
public void testCreateIndex() throws Exception {
// 准备原始数据
String doc1 = "hello world";
int id1 = 1;
String doc2 = "hello java world";
int id2 = 2;
String doc3 = "lucene world";
int id3 = 3;
//把数据变成Document对象
Document d1 = new Document();
d1.add(new TextField("context",doc1, Field.Store.YES));// 存储列的名字;存储的数据;是否要存储原始数据
d1.add(new IntField("id", id1, Field.Store.YES));
Document d2 = new Document();
d2.add(new TextField("context",doc2, Field.Store.YES));
d2.add(new IntField("id", id2, Field.Store.YES));
Document d3 = new Document();
d3.add(new TextField("context",doc3, Field.Store.YES));
d3.add(new IntField("id", id3, Field.Store.YES));
//准备索引库路径
Directory directory = new SimpleFSDirectory(Paths.get("D:/(课件 Xmind 图 代码) (总结) (原理)(题目) (预习)/081-Lucene+ElasticSearch/code/lucene-demo/index"));
Analyzer analyzer = new SimpleAnalyzer();
//配置信息,添加分词器
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
//创建IndexWriter,创建索引
IndexWriter indexWriter = new IndexWriter(directory,conf);
//使用IndexWriter创建索引
indexWriter.addDocument(d1);
indexWriter.addDocument(d2);
indexWriter.addDocument(d3);
//提交创建
indexWriter.commit();
indexWriter.close();
System.out.println("创建索引完成.......");
}
搜索索引
分析图

代码
//搜索索引
@Test
public void testSearchIndex() throws Exception {
//索引库路径
Directory directory = new SimpleFSDirectory(Paths.get("D:/(课件 Xmind 图 代码) (总结) (原理)(题目) (预习)/081-Lucene+ElasticSearch/code/lucene-demo/index"));
IndexReader indexReader = DirectoryReader.open(directory);
//创建indexSearch 搜索索引
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//Term(String fld, String text) 要查询哪个字段,查询什么内容
TermQuery query = new TermQuery(new Term("context", "hello"));
//query:查询的条件 n:查多少条
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("命中的条数:"+topDocs.totalHits);
//列表结果,带有分数
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
//文档分数
float score = scoreDoc.score;
//文档id
int docID = scoreDoc.doc;
//根据id获取文档
Document doc = indexSearcher.doc(docID);
System.out.println("id = "+doc.get("id")+" , score = "+score+" ,context = "+doc.get("context"));
}
}
ElasticSearch
认识ElasticSearch
见文档
ES与Kibana的安装及使用说明
见文档
Kibana可视化管理工具,相当于navicat,
ES相关概念理解和简单增删改查

# 添加数据 ---用户自己维护文档id
PUT pethome/user/5
{
"id":5,
"name": "wenda",
"age":20,
"size":170,
"sex":1
}
# 添加数据 ---ES自动维护文档id AYpOuIdMNmSVfcreiYqz
POST pethome/user/
{
"id":2,
"name": "wenda",
"age":20,
"size":170,
"sex":1
}
# 查询单条
GET pethome/user/1
GET pethome/user/AYpOuIdMNmSVfcreiYqz
# 修改 全量修改
PUT pethome/user/1
{
"id":1,
"name": "wendaxi",
"age":21,
"sex":0
}
# 修改 局部
POST pethome/user/1/_update
{
"doc":{
"name": "wenda",
"age":24
}
}
# 删除
DELETE pethome/user/AYpOuIdMNmSVfcreiYqz
# 获取多个数据结果
GET pethome/user/_mget
{
"ids":[1,"AYpOuIdMNmSVfcreiYqz"]
}
# 空搜索
GET _search
# 分页
GET pethome/user/_search?size=2&from=2
# 带条件分页
GET pethome/user/_search?q=age:20&size=2&from=2
ES查询
DSL查询
由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现
# 查询名字叫做wenda,size在160-180之间,sex为1,
# 按照id升序排序 查询第一页 的数据 每页3条
# 排序分页
GET pethome/user/_search
{
"size": 3,
"from": 0,
"sort": [
{
"id": {
"order": "asc"
}
}
]
}
# 加入查询条件
# match 相当于模糊查询(分词查询)
GET pethome/user/_search
{
"query": {
"match": {
"name": "wenda"
}
},
"size": 3,
"from": 0,
"sort": [
{
"id": {
"order": "asc"
}
}
]
}
DSL过滤
DSL过滤 查询文档的方式更像是对于我的条件“有”或者“没有”,–精确查询
而DSL查询语句则像是“有多像”。–类似于模糊查询
DSL过滤和DSL查询在性能上的区别 :
过滤结果可以缓存并应用到后续请求。
查询语句同时 匹配文档,计算相关性,所以更耗时,且不缓存。
过滤语句 可有效地配合查询语句完成文档过滤。
# 工作中少用like全表扫描,会让索引失效
# where name like '%y%' and age=18
# where age=18 and name like "%y%" (快)
# 先精确匹配 把结果缓存用于后续的查询
# DSL过滤-------相当于精确查找
GET pethome/user/_search
{
"query": {
"bool": {
"must": [{
"match": {
"name": "wenda"
}
}],
"filter": [{
"term": {
"age": "20"
}
},
{
"range": {
"size": {
"gte": 160,
"lte": 170
}
}
}
]
}
},
"size": 2,
"from": 0,
"sort": [
{
"id": {
"order": "asc"
}
}
]
}
分词器
单字,双字,庖丁,IK
IK分词器
安装
先关闭ES与Kibana,然后解压elasticsearch-analysis-ik-5.2.2.zip文件,并将其内容放置于ES根目录/plugins/ik
测试分词器
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
文档映射(字段类型设置)
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。
ES字段类型
① 基本字段类型
字符串:text(分词),keyword(不分词) StringField(不分词文本),TextFiled(要分词文本)
text默认为全文文本,keyword默认为非全文文本
数字:long,integer,short,double,float
日期:date
逻辑:boolean
{user:{“key”:value}}
{hobbys:[xxx,xx]}
② 复杂数据类型
对象类型:object
数组类型:array
地理位置:geo_point,geo_shape
默认映射
查看索引类型的映射配置:GET {indexName}/_mapping/{typeName}
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映射关系。

kibana
GET pethome/user/_mapping
POST pethome/employee2/_mapping
{
"employee2": {
"properties": {
"id": {
"type": "long"
},
"username": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"password": {
"type": "keyword"
}
}
}
}
GET pethome/employee2/_mapping
Java操作ES
导入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
crud实现
import org.elasticsearch.action.delete.DeleteRequestBuilder;
import org.elasticsearch.action.index.IndexRequestBuilder;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequestBuilder;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import java.util.Map;
public class ESTestNew {
//创建ES的客户端对象
public static TransportClient getClient(){
TransportClient client = null;
try {
client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
} catch (UnknownHostException e) {
e.printStackTrace();
}
return client;
}
@Test
public void testAddIndex(){
TransportClient client = getClient();
for (int i = 0; i < 50; i++) {
IndexRequestBuilder builder = client.prepareIndex("pethome", "wxuser", String.valueOf(i));
Map<String, Object> map = new HashMap<>();
// 添加数据
map.put("id",i);
map.put("name","玛利亚"+i);
map.put("age",18+i);
map.put("sex",i%2);
map.put("size",150+i);
map.put("intro","haha"+i);
builder.setSource(map);
// 执行创建
builder.get();
}
// 关闭资源
client.close();
}
@Test
public void testUpdate(){
TransportClient client = getClient();
// 指定要执行的操作对象
UpdateRequestBuilder builder = client.prepareUpdate("pethome", "wxuser", String.valueOf(0));
Map<String, Object> map = new HashMap<>();
map.put("id",0);
map.put("name","玛利亚000");
map.put("age",18);
map.put("sex",0);
map.put("size",155);
map.put("intro","haha000");
builder.setDoc(map).get();
client.close();
}
@Test
public void testDel(){
TransportClient client = getClient();
DeleteRequestBuilder builder = client.prepareDelete("pethome", "wxuser", String.valueOf(0));
builder.get();
client.close();
}
@Test
public void testQuery(){
TransportClient client = getClient();
SearchRequestBuilder builder = client.prepareSearch("pethome");
builder.setTypes("wxuser");// 指定查询那个文件类型
builder.setFrom(0);//起始位置
builder.setSize(5);//每页条数
builder.addSort("id", SortOrder.ASC);//设置排序
// 添加筛选条件
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.matchQuery("name","玛利亚"));
boolQuery.filter(QueryBuilders.termQuery("sex",1));
boolQuery.filter(QueryBuilders.rangeQuery("size").gte(150).lte(180));
SearchResponse response = builder.setQuery(boolQuery).get();
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits());
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
System.out.println(searchHit.getSource());
}
client.close();
}
}