set和map
- 1. 预备知识
- 2. set
- 2.1 set的概念
- 2.2 set的常见接口
- 3. multiset
- 4. map
- 4.1 map的概念
- 4.2 map的常见接口
- 5. multimap
- 6. 练习
1. 预备知识
- set和map是关联式容器,里面存储的不是元素本身,存储的是<key,value>结构的键值对,比vector、list、deque这些底层为线性序列的序列式容器,在数据检索时效率更高。
- 关联性容器有两种不同的结构:树形结构和哈希结构。set和map的底层结构是树形结构。使用平衡搜索树(即红黑树)作为底层结构,容器中的元素是一个有序的序列。
- 键值对一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
2. set
2.1 set的概念

- set存储的是具有一定次序(升序和降序)的元素。
- set存储的元素被const修饰,不可更改。为什么?因为set的底层是用二叉搜索树实现的,改变了元素会影响次序。
- 用迭代器遍历set,可以得到有序序列。
- set中的元素是唯一的,因此使用set会去重。
- set看起来存放的只有key值,实际底层存放的是<value,value>键值对。
2.2 set的常见接口
- 构造
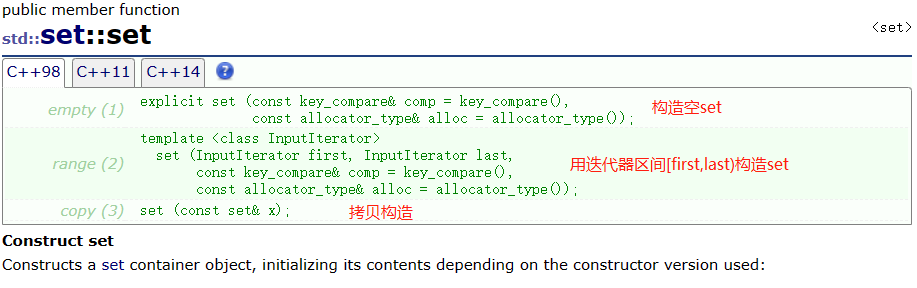
- 迭代器

void test1()
{
//构造空set
set<int> s1;
s1.insert(3);
s1.insert(2);
s1.insert(4);
s1.insert(5);
s1.insert(1);
auto it = s1.begin();
//用迭代器遍历set,可以得到有序序列。
while (it != s1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
//用迭代器构造set
set<int>s2(s1.begin(), s1.end());
for (auto e : s2)
{
cout << e << " ";
}
cout << endl;
//拷贝构造
set<int>s3(s2);
for (auto e : s3)
{
cout << e << " ";
}
cout << endl;
}
- 容量

- 增加
set中插入元素时,只需要插入value即可,不需要构造键值对。

- 删除

若删除的参数是键值,键值存在就删除,不存在也不会报错。若删除的参数是迭代器,迭代器是end(),就会报错。
void test2()
{
set<int> s1;
s1.insert(3);
s1.insert(2);
s1.insert(4);
s1.insert(5);
s1.insert(1);
auto it = s1.find(6);
s1.erase(6);//✔
//s1.erase(it);//❌
}
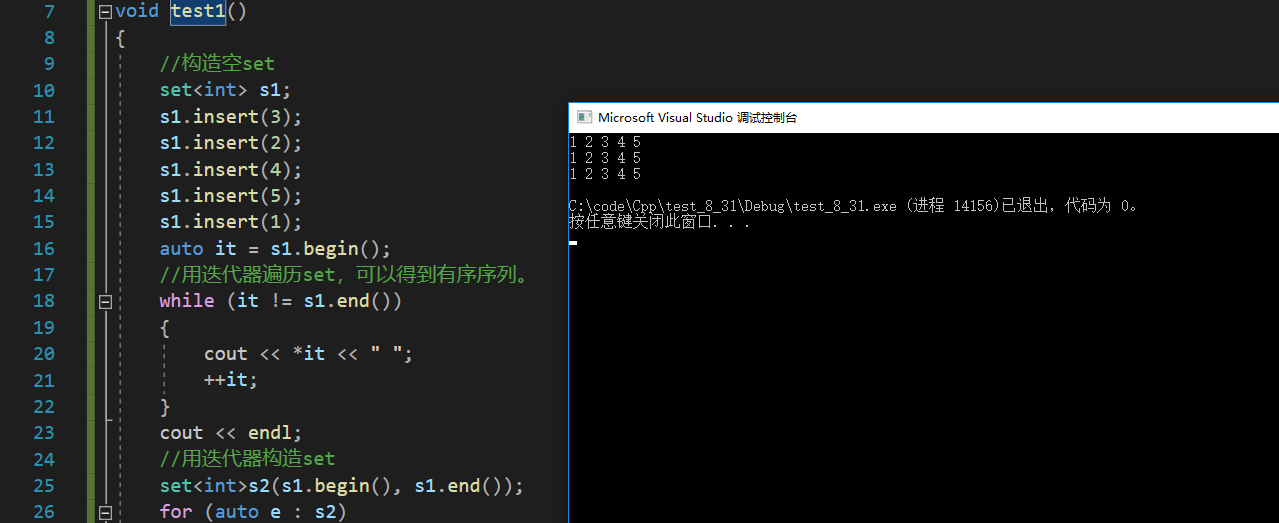
- 交换

- 清理

void test3()
{
set<int> s1;
s1.insert(3);
s1.insert(2);
s1.insert(4);
s1.insert(5);
s1.insert(1);
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
set<int>s2(arr, arr + sizeof(arr) / sizeof(arr[0]));
//交换s1和s2
s1.swap(s2);
cout << "s1的元素:" ;
for (auto e : s1)
{
cout << e << " ";
}
cout << endl;
cout << "s2的元素:";
for (auto e : s2)
{
cout << e << " ";
}
cout << endl;
//清理s1
s1.clear();
cout <<"s1大小为:" << s1.size() << endl;
cout << "s1是否为空:" << s1.empty() << endl;
}
- 查找

(1)查找键值为val的元素,找到了返回该元素在set中的迭代器,找不到返回end()的迭代器。
(2)库里的find和set的find有区别。库里的find是暴力查找,时间复杂度是O(N),set的find是大于查找元素就往左找,小于查找元素就往右找。
- 计数

返回set中与val相等的元素个数。由于set会去重 ,元素都是唯一,所以count只能返回0或者1,所以count也可以用来判断元素是否在set中。
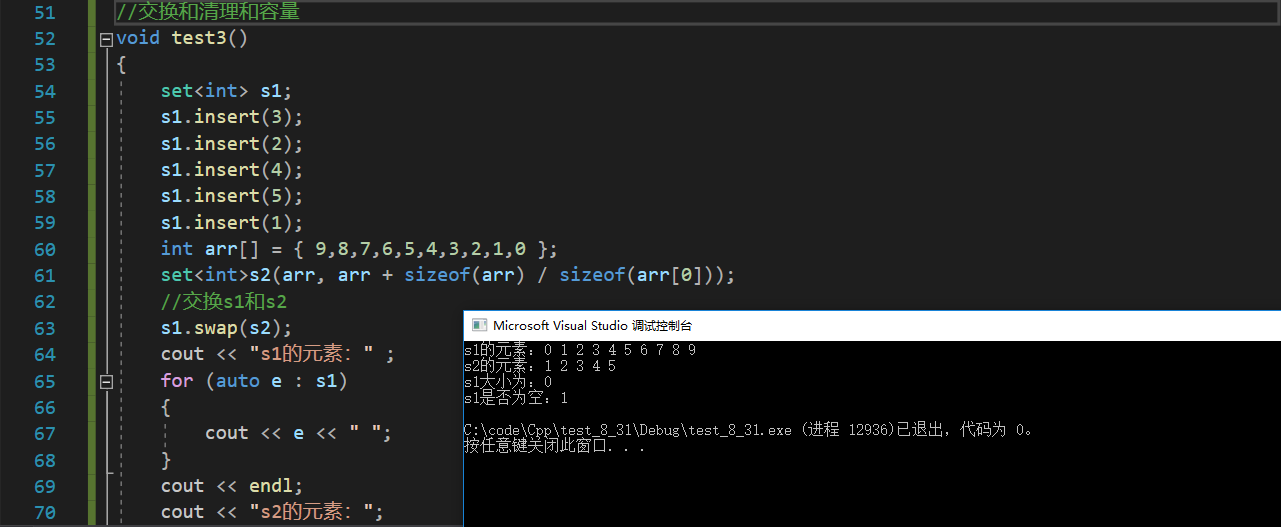
- 获得迭代器区间

(1)lower_bound找到>=参数的元素的迭代器,upper_bound找到>参数的最小元素的迭代器。配合使用,可以获得左闭右开的区间。
(2)若两个函数的参数相同,则区间内的元素都是相同的,但set的元素是唯一的,所以这两函数用处不大,可以用于multiset。
(3)若参数在set中找不到,则返回set的end()的迭代器。
void test4()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
set<int>s1(arr, arr + sizeof(arr) / sizeof(arr[0]));
auto begin = s1.lower_bound(5);
auto end = s1.upper_bound(10);
while (begin != end)
{
cout << *begin << " ";
++begin;
}
cout << endl;
}
- 获得相同元素的迭代器区间
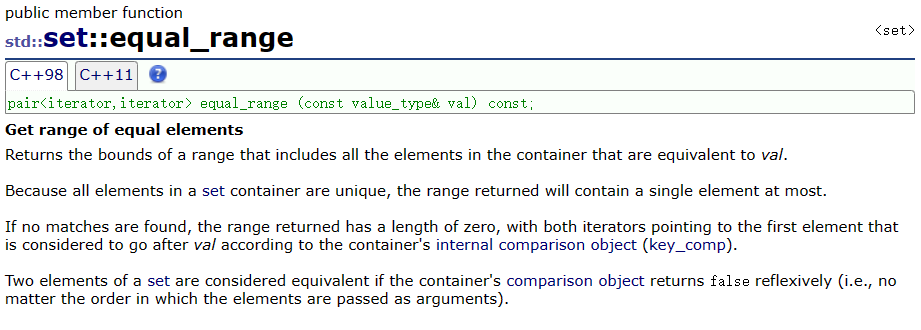
(1)在set中查找相同元素的区间,返回左闭右开的区间。
(2)返回键值对,键值对的第一个迭代器是set中val的位置,第二个迭代器是set中大于val的最小元素的位置。
(3)对于set来说,用处不大,因为set不能有重复的元素,但对multiset就有用处。
(4)若参数不存在于set,返回类似于[参数,参数)这样不存在的区间。
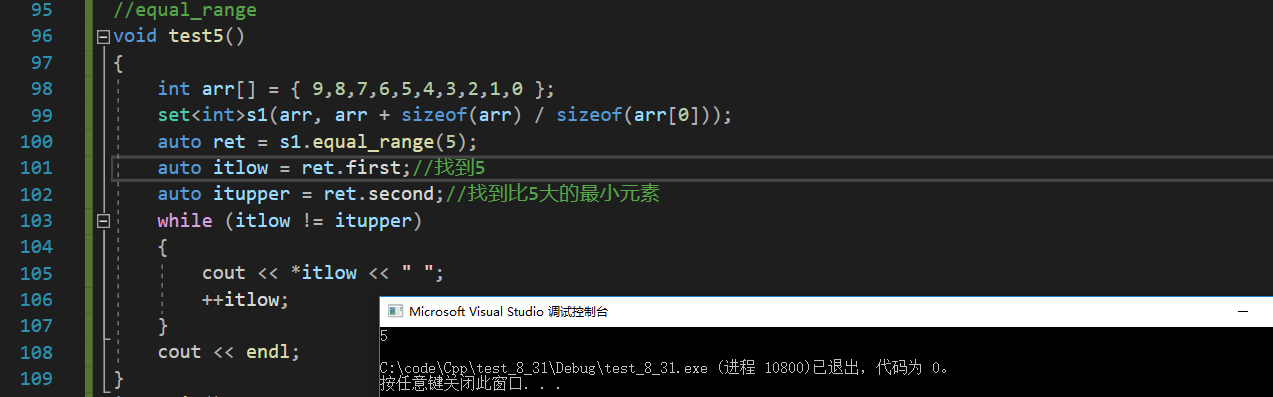
void test5()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
set<int>s1(arr, arr + sizeof(arr) / sizeof(arr[0]));
auto ret = s1.equal_range(5);
auto itlow = ret.first;//找到5
auto itupper = ret.second;//找到比5大的最小元素
while (itlow != itupper)
{
cout << *itlow << " ";
++itlow;
}
cout << endl;
}
3. multiset
- multiset是在set的基础上,加上可以插入重复元素的功能。multiset依旧是按照一定次序(升序和降序)存储元素,通过迭代器遍历元素可以得到有序序列。multiset的元素可以重复,不能修改。
- equal_range和count对于multiset用处更大,更有意义。
void test6()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 ,1,2,3,4,5,6,7,8,9 };
multiset<int> ms(arr,arr+sizeof(arr)/sizeof(arr[0]));
cout << "multiset的元素:";
for (auto& e : ms)
{
cout << e << " ";
}
cout << endl;
cout<<"9出现的次数:"<<ms.count(9)<<endl;
auto range = ms.equal_range(5);
auto low_range = range.first;
auto upper_range = range.second;
while (low_range != upper_range)
{
cout << *low_range << " ";
++low_range;
}
cout << endl;
}

4. map
4.1 map的概念
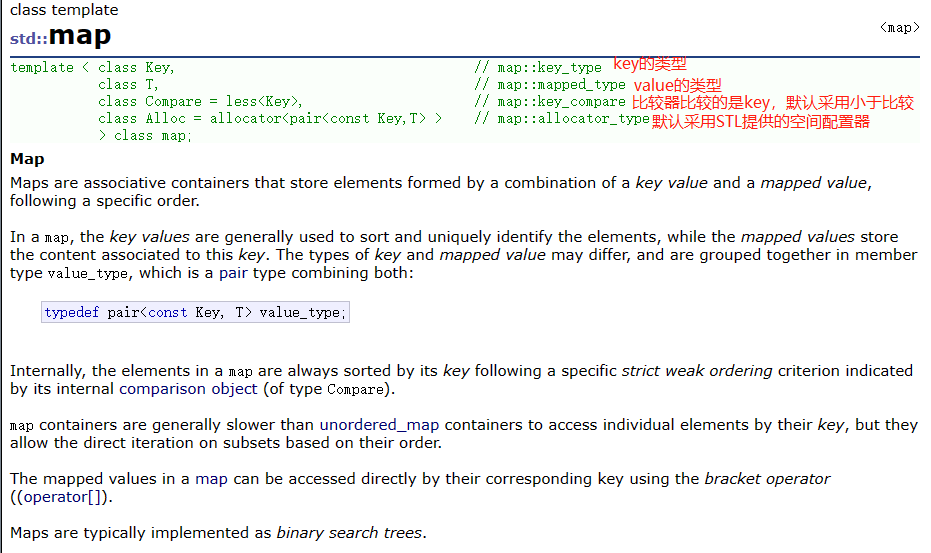
- map也是关联式容器,存储的是具有一定次序(升序和降序)的元素。
- map中存放的是<key,value>键值对,key代表键值,value表示与key对应的信息。map中元素的次序就是根据key进行排序的,因此key不能修改,且key在map中唯一,value则不一定唯一。
//键值对的定义
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};
- map通过迭代器遍历元素,可以得到有序序列。
- 特点:map支持[]访问,通过[key]可以找到对应的value。operator[]中实际进行插入查找。
4.2 map的常见接口
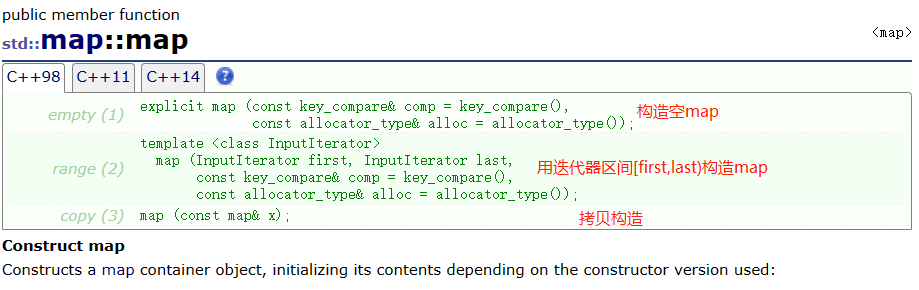
- 构造
- 迭代器
set的迭代器都是const迭代器,因此它的key不能修改,map的迭代器和const迭代器分明,key不可修改,value可以修改。
//例子
void test()
{
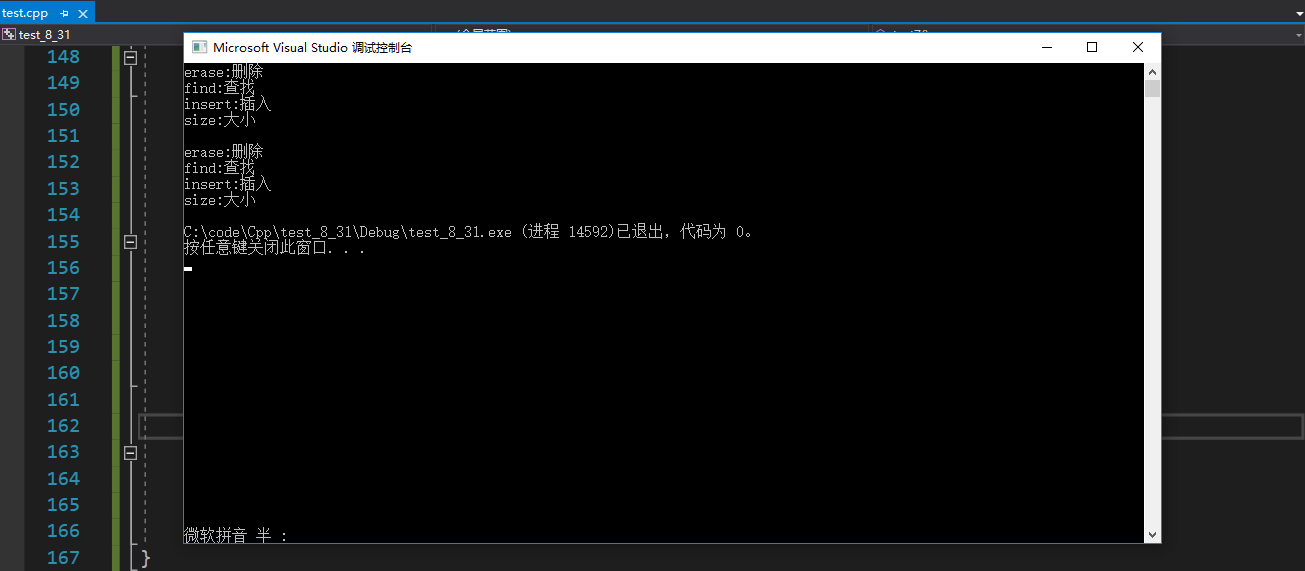
map<string,string> dict;//词典
//插入键值对
dict.insert({"insert", "插入"});
dict.insert({"erase", "删除"});
dict.insert({"size", "大小"});
dict.insert({"find","查找"});
//为什么要将key和value封装?因为C++不支持返回两个值,但支持返回一个结构体
auto it = dict.begin();
while (it != dict.end())
{
//cout << *it << " ";//❌,pair不支持流插入
cout << it->first << ":" << it->second << endl;
++it;
}
cout << endl;
//范围for
for (auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
}
- 插入
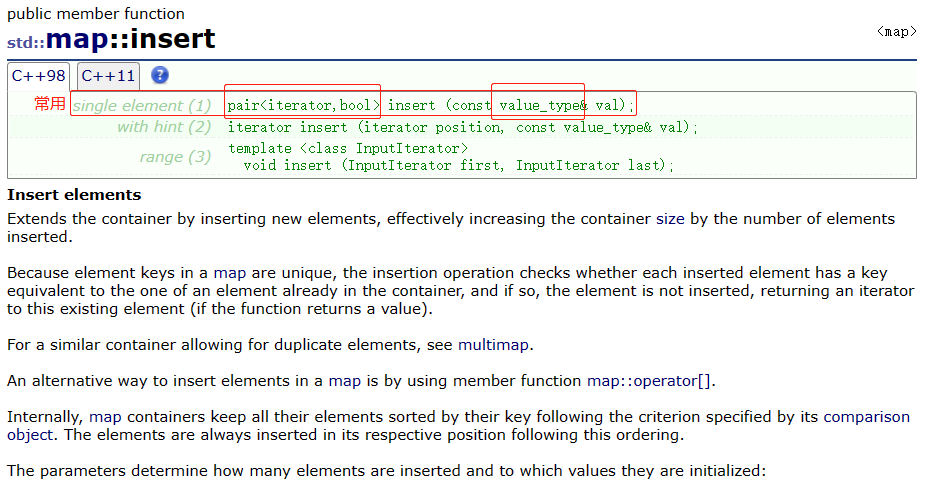
(1)key与value通过成员类型value_type绑定在一起,为其取别名称为pair:typedef pair<const key, T> value_type;。
(2)不同于set,map插入的是键值对,不是单独的value。返回的也是键值对,插入成功,iterator是新插入节点的位置,bool是true;发现map已有相同的key,插入失败,iterator是map中key的位置,bool是false。
(3)如何插入键值对
//map
void test7()
{
map<string,string> dict;//词典
//法1
//pair也是一个类模板
pair<string, string>word1("insert", "插入");
dict.insert(word1);
//法2
//先调用构造,再调用拷贝构造,编译器会优化为构造
dict.insert(pair<string, string>("erase", "删除"));
//法3
//make_pair是模板函数,可以构造键值对
dict.insert(make_pair("size", "大小"));
//法4
//C++11支持多参数的构造函数隐式类型转换,C++98支持单参数的构造函数隐式类型转换
dict.insert({ "find","查找" });
//等价于pair<string,string> word2 = {"find","查找"},然后dict.insert(word2);
}

最常用的是法3和法4。
- []下标访问
//例子:统计次数
//常规做法
void test9()
{
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countMap;
for (auto e : arr)
{
auto it = countMap.find(e);
if (it == countMap.end())
{
countMap.insert(make_pair(e, 1));
}
else
{
it->second++;
}
}
for (const auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
}
//优化
void test9()
{
// 统计次数
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countMap;
for (auto e : arr)
{
countMap[e]++;
}
for (const auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
}
把key放入[]中,就可以得到相应的value,可问题是还没插入怎么++?[]下标访问,先试着插入key,如果key已经存在,则返回key对应的value,此时就可以对value操作。如果key不存在,先插入key,再返回对应的value。
//底层类似这样定义
T& operator[](cosnt K& key)
{
pair<iterator,bool>ret = insert(make_pair(key,T()));//因为value可能是其他类型,所以不能单纯用int。
//(1)key已在map里面,返回pair<map中key所在节点的位置,false>
//(2)key不在map里面,返回pair<新插入key所在节点的位置,true>
return ret->first->second;
}
练习
有效的括号
class Solution {
public:
//将左括号入栈,遇到右括号出栈,判断是否相同,不相等就return false,
bool isValid(string s) {
stack<char> st;
map<char,char> m;
m['('] = ')';
m['['] = ']';
m['{'] = '}';
for(auto e:s)
{
//如果e等于左括号,返回1,就入栈
if(m.count(e))
{
st.push(e);
}
//遇到右括号,就出栈,判断是否相等
else
{
if(st.empty())
{
return false;
}
char tmp = st.top();
st.pop();
if(m[tmp]!=e)
{
return false;
}
}
}
if(st.empty())
{
return true;
}
return false;
}
};
5. multimap
multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以重复的。因此multimap不支持[]下标访问。
6. 练习
- 两个数组的交集
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
//先将两个数组放进set中,可以帮助去重
//法1:遍历一个set中所有元素,判断在不在另一个set中,在就加到交集中
//法2:从头开始,比较两个set中的元素,相等就是加到交集,然后同时++,小的就指向下一个元素,继续比较
set<int>s1(nums1.begin(),nums1.end());
set<int>s2(nums2.begin(),nums2.end());
vector<int>v;//存放交集
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1!=s1.end()&&it2!=s2.end())
if(*it1==*it2)
{
v.push_back(*it1);
++it1;
++it2;
}
else if(*it1>*it2)
{
++it2;
}
else
{
++it1;
}
return v;
}
};
- 前k个高频单词
class Solution {
public:
struct Greater
{
bool operator()(const pair<string,int>& p1,const pair<string,int>&p2)
{
return p1.second>p2.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
//法一:先将words的单词map中,可以起到去重和计数的作用
map<string,int> m;
for(auto& e:words)
{
m[e]++;
}
//此时map已经按照字典序排好了
//再按照单词出现频率排序,使用sort进行排序,但是sort不能对map排序,因为map的迭代器是双向的,双向迭代器不能使用随机迭代器的函数。所以将map的键值对加到vector中,就可以用sort。
vector<pair<string,int>> v(m.begin(),m.end());
//但是sort底层是快排,快排不稳定,排序结束后,出现频率相同的单词的字典序可能被破坏,所以得用另一个函数stable_sort,stable_sort不会破坏字典序。
//又因为是排降序,得自己写仿函数
stable_sort(v.begin(),v.end(),Greater());
//排序后需要将前K个string取出,放入vector
vector<string> ret;
for(int i = 0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};
class Solution {
public:
//法2:如果偏要用sort排序,怎么办?修改仿函数,在频率相同的情况下不改变字典序。
struct Greater
{
bool operator()(const pair<string,int>& p1,const pair<string,int>&p2)
{
return (p1.second>p2.second) ||(p1.second==p2.second&&p1.first<p2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> m;
for(auto& e:words)
{
m[e]++;
}
vector<pair<string,int>> v(m.begin(),m.end());
sort(v.begin(),v.end(),Greater());
vector<string> ret;
for(int i = 0;i<k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};
class Solution {
public:
//法3:用map按字典序排序,用multimap再按频率排序,multimap排序是稳定的,不会破坏字典序。
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> m;
for(auto& e:words)
{
m[e]++;
}
multimap<int,string,greater<int>>mm;
for(auto&e:m)
{
mm.insert(make_pair(e.second,e.first));
}
vector<string>ret;
auto it = mm.begin();
while(k--)
{
ret.push_back(it->second);
++it;
}
return ret;
}
};