AIGC 发展历程
如果说 2021 年是元宇宙元年,那么 2022 年绝对可以称作 AIGC 元年。自从 Accomplice 于 2021 年 10 月推出 Disco Diffusion 以来,AIGC 受到了前所未有的关注,相关产品和技术更是以井喷之势快速更新迭代。
AIGC(Artificial Intelligence Generated Content)即人工智能生成内容。指通过使用人工智能技术,让计算机自动生成文字、图像或音频等内容的过程。AI 生成的内容通常被用于许多不同的领域,包括新闻报道、广告创意、电影剧本编写等。可以预见的是,AIGC 将给创作领域带来前所未有的改变,它使得人们能够节省时间和精力,专注于更重要的事情(创新想法)。
在 Disco Diffusion 推出之前,AIGC 领域最热门的技术是生成对抗网络(GAN),它的核心是两个神经网络,一个称为生成器的神经网络生成新的数据实例,而另一个称为鉴别器的神经网络评估它们的真实性,两个神经网络彼此对立,最终生成全新的“合成数据”。但是GAN不够稳定、出图时间长、训练内容也有所限制,所以以 GAN 为基础的人工智能生成应用并没有受到除学术界以外的关注。
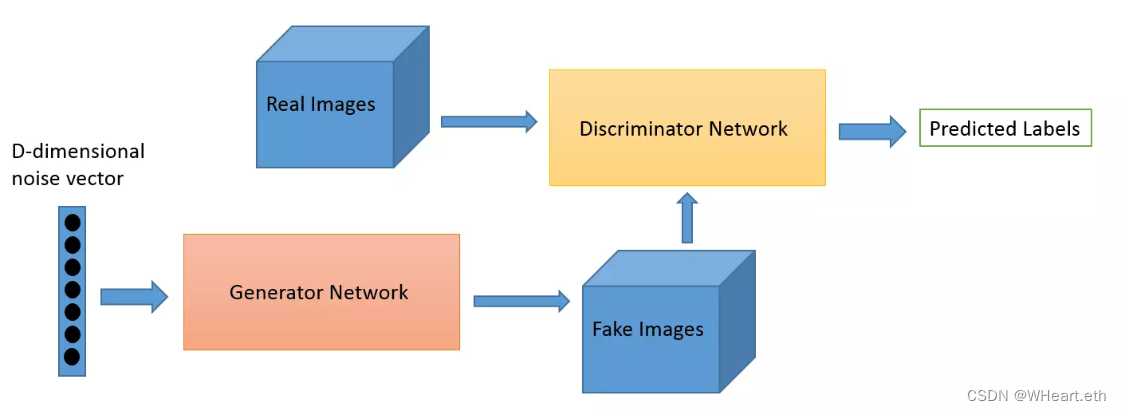
GAN 图像生成
直到 Disco Diffusion 出现,AIGC 才真正可以构建产品级应用。Disco Diffusion 使用了 CLIP 和 Guided Diffusion两项技术,其中 Diffusion 对图片进行迭代去噪处理,而 CLIP 为 Diffusion 指引正确的迭代方向, 使图片向文本描述方向收敛,进而输出一个符合输入文本的图片。
Disco Diffusion 擅长对场景的刻画,输出图片内容恢弘大气,但是缺点也很明显:作图速度慢,输出一张1024*1024的图大概需要10分钟左右;对细节刻画不足;难以输出人像等。
Disco Diffusion 点燃了 AIGC 领域的火种,后续的 DALL-E、Stable Diffusion 和 Midjourney 更是把 AIGC 推向了高潮。Stable Diffusion 的核心是 Latent Diffusion Models,此模型在潜在表示空间中迭代“去噪”数据来生成图像,它降低了对显卡的需求,更是把出图时间缩短至十秒之内,出图精细程度上升了一个量级,而 Midjourney v4 模型的作图质量更是比 Stable Diffusion 更高。

出图效果,左→右:Disco Diffusion、stable diffusion midjourney
国内 AIGC 相关产品
除了作图工具之外,近期 chatGPT 又带起了一波语言模型的热潮,由于种种原因,国内用户并不能直接使用这些工具,所以很多国内项目也在开发更适用于国内用户的 AIGC 产品,但是从效果来看,很多产品的用户体验都比较差,并且功能不够完善,更多的只是直接把国外的开源模型拿来用。
纵观国内相关项目方的产品广度、深度、技术水平和实际测评,昆仑万维或许是唯一一个可以类比 OpenAI 的存在。
近期,昆仑万维与奇点智源共同推出 AIGC 系列产品“昆仑天工”,其模型涵盖领域包括图像、音乐、编程和文本四个领域,是国内目前为止模型最丰富的的 AIGC 工具。昆仑天工基本上可以作为国内替代 Stable Diffusion + chatGPT 的产品。下面就主要以昆仑天工为案例说一下对应赛道。
文本模型
昆仑天工的文本模型拥有多样的下游能力,包括续写,对话,中英翻译,内容风格生成,推理,诗词对联等,并在各项专业性领域的任务中(例如分类、匹配、填空、识别)表现突出,在实际测评结果上与现有大模型相比具有多方面优势。
现在市场上大部分文本模型都是直接接入 GPT,但是由于 GPT 本身对于中文的支持并不十分友好,所以对于国内用户使用还是存在一些障碍,**而昆仑天工系列产品针对中文领域构建了千亿级别的高质量数据案,包含数百张A100 GPU显卡的超算集群,训练得到百亿参数量的 GPT-3 生成模型。**现在在产品分为基础版和增强版,基础 GPT-3 模型被称为天枢,增强版称为瑶光,瑶光是相对能力最强大的模型, 适用于各种任务,而天枢是在模型的速度上做了极致的优化。
输入一些文本作为提示,模型将生成一个文本补全,补全功能几乎可用于任何任务,包括内容或代码生成、总结、扩展、对话、创意写作、风格转换等,示例如下:
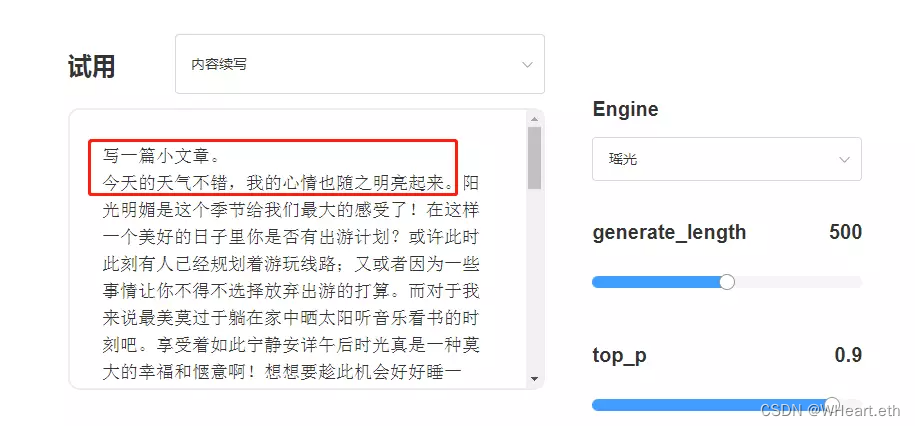
文本模型测试
同时该模型提供了便捷的API支持,使用 Python 调用API示例如下:
import requests
import time
import hashlib
import json
url = 'https://openapi.singularity-ai.com/api/v2/generateByKey'
api_key = 'YOUR_API_KEY' # 这里需要替换你的APIKey
api_secret = 'YOUR_API_SECRET' # 这里需要替换你的APISecret
timestamp = str(int(time.time()))
prompt = '中国是一个伟大的国家'
model_version = 'benetnasch_common_gpt3'
sign_content = api_key + api_secret + model_version + prompt + timestamp
sign_result = hashlib.md5(sign_content.encode('utf-8')).hexdigest()
headers={
"App-Key": "Bearer " + api_key,
"timestamp": timestamp,
"sign": sign_result,
"Content-Type" : "application/json"
}
data = {
"data": {
"prompt": prompt,
"model_version": model_version,
"param": {
"generate_length": 200,
"top_p": 1,
"top_k": 5,
"repetition_penalty": 1.0,
"length_penalty": 1.0,
"min_len": 5,
"bad_words": [],
"end_words": ["[EOS]", "\n", "\t" ],
"temperature": 1.0
}
}
}
try:
response = requests.post(url, json=data, headers=headers)
print(json.loads(response.text))
except Exception as e:
print(e)
经过测试,瑶光的各项指标均处于同类模型前列:
| 任务类型 | 续写 | 扩写 | 摘要 | ||||
|---|---|---|---|---|---|---|---|
| 测评数据集 | 人民日报 | LOT-Outgen | CEPSUM | ||||
| 评估指标 | bleu | bleu | coverage | order | rouge-l | ||
| 模型 | 机构 | 参数量 | |||||
| 孟子 | 澜舟科技 | 10亿 | 0 | 0 | 0 | 0 | 16.37 |
| 闻仲 | IDEA | 35亿 | 10.5 | 9.75 | 36.49 | 42.4 | 2.76 |
| GLM | 智谱华章 | 100亿 | 4.94 | 1.01 | 10.73 | 29.24 | 18.2 |
| CPM-2 | 智源悟道 | 110亿 | 0.31 | 0 | 1.19 | 22.75 | 0 |
| 瑶光 | 奇点智源 | 140亿 | 9.8 | 17.27 | 47.41 | 46.52 | 18.47 |
文本生成图片
文本生成图片是 AIGC 领域需求量最大的服务,昆仑天工在出图效果、精确度和速度上在同类产品中处于领先地位,其在增加中文提示词输入能力的同时兼容原版stable diffusion的英文提示词模型,之前用户积累的英文提示词手册依然可以在我们的模型上使用。
在中英文匹配方面,昆仑使用1.5亿级别的平行语料优化提示词模型实现中英文对照,不仅涉及翻译任务语料,还包括了用户使用频率高的提示词中英语料,古诗词中英语料字慕语料,百科语料,图片文字描述语料等多场景多任务的海量语料集合,这类中文适应模型能力对于国内用户来说是迫切需求。
在模型训练方面,昆仑在训练时采用模型蒸馏方案和双语对齐方案,使用教师模型对学生模型蒸馏的同时辅以解码器语言对齐任务辅助模型训练,使得出图效果可以更加精确。

生成效果图
经过评测,其出图时间在10秒之内,成图率大于80%,采用 Chinese-CLIP(CN CLIP) 测试数据在同类模型中也处于领先水平。
下表为使用 Flickr30K-CN 的 test 数据集的评测结果,括号中为论文数据,最后两行为昆仑天工测试数据,整过过程先根据模型的 encode r得到 text 和 image 的 embedding,再经过统一的 KNN 检索,Recall,从而计算出检索任务的Recall@1/5/10和mean recall:
| Dataset | Method | Text-to-Image | Image-to-Text | MR | ||||
| Zero-shot | Zero-shot | |||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| Flickr30K-CN | Taiyi-CLIP-Roberta-large-326M-Chinese | 53.84(53.7) | 79.9(79.8) | 86.56(86.6) | 64.0(63.8) | 90.4(90.5) | 96.1(95.9) | 78.47(78.39) |
| Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese | 55.3(58.32) | 81.58(82.96) | 88.5(89.40) | 67.2() | 92.7() | 96.9() | 80.37() | |
| Wukong ViT-L/14 | 51.86(51.7) | 78.6(78.9) | 85.88(86.3) | 75(76.1) | 94.4(94.8) | 97.7(97.5) | 80.57(80.89) | |
| R2D2 ViT-L/14 | 42.6(60.9) | 69.46(86.8) | 78.64(92.7) | 63.0(77.6) | 90.10(96.7) | 96.40(98.9) | 73.37(85.6) | |
| CN-CLIP ViT-L/14 | 68.08(68.0) | 89.66(89.7) | 94.46(94.4) | 80.2(80.2) | 96.6(96.6) | 98.2(98.2) | 87.87(87.85) | |
| AltCLIP-XLMR-L(AltCLIP) | 50.66(69.8) | 75.42(89.9) | 83.14(94.7) | 73.4(84.8) | 92.8(97.4) | 96.90(98.8) | 78.72(89.24) | |
| prev_online(ours) | 61.52 | 84.72 | 90.62 | 76.7 | 95.6 | 98.7 | 84.64 | |
| hide77_gpt2(online)(ours) | 58.82 | 82.62 | 89.58 | 78.8 | 96.1 | 98.3 | 84.04 | |
代码模型
昆仑天工旗下的 SkyCode 支持多种主流代码语言(java,javascript,c,c++,python,go,shell)的续写,根据代码注释写代码(解题),支持根据中文注释来序列代码,这个功能也是最受程序员关注的,Sky-code 可以直接集成到编辑器中,无缝衔接在开发环境,在键入代码的同时,智能高效补全代码,提升工作效率,节省开发时间。
实际工作示例如下:
如图,Sky-code 会从当前光标处进行代码的智能补全,灰色部分的代码提示通过键盘的 “Tab” 按键,会补全为代码内容

补全后结果为:
SkyCode 的代码模型质量还是很高的,支持中文注释,在速度上,每秒输出百字代码以上,比chatGPT 发布的版本速度还要快。对于代码模型来说,最重要的能力衡量指标是代码通过率,针对数据集中的问题,模型生成的代码需要通过单元测试才被认为生成正确。根据运行次数的不同,指标分为单次运行通过率(k=1),十次运行通过率(k=10)和百次运行通过率(k=100)等,通过测评,SkyCode 在多项指标都超过了GPT-J。
| Dataset | Method | Text-to-Image | 函数级代码生成任务的数据集 | |||||||
| Human-Eval 164(open ai发布) | 40Simples(40个贴近实际场景的简单case,奇点内部编纂) | |||||||||
| k=1 | k=10 | k=100 | ED | k=1 | k=10 | k=100 | 编辑距离 | |||
| GPT-J | EleutherAI | 60亿 | 11.62% | 15.74% | 27.74% | 35.83 | 27.00%(t0.2) | 57.06%(t0.6) | 80.00%(t0.6) | 44.31 |
| SKY-CODE | 奇点智源 | 26亿 | 10.37%(t0.2) | 18.52%(t0.6) | 30.69%(t0.6) | 37.32 | 35.45%(t0.2) | 60.38(t0.6) | 84.77%(t0.6) | 51.1 |
总结
AIGC 技术的发展会极大程度上改变创作领域的格局,它降低了创作的门槛,让普通人可以做出原本专业人士才可以创作的作品,这是生产工具的变革,也是生产力的解放,一个新的时代即将到来。